









{kind=link}
Трассировка запросов — это процесс сбора и анализа запросов на стороне СУБД, необходимый для диагностики проблем с производительностью в базах данных. С её помощью можно, например:
- понять, почему запрос выполняется медленно, — для этого нужно посмотреть текст запроса на языке SQL и его план;
- определить источник чрезмерной нагрузки на БД (например, ресурсоемкий запрос) и связать его с ответственным пользователем;
- упростить управление рабочими нагрузками приложений за счёт отслеживания конкретных модулей и действий в службе.
Для некоторых СУБД существуют специальные инструменты для трассировки запросов — профайлеры запросов. И начнем мы знакомство с pg_trace с небольшой теории непосредственно про профайлеры.
! Дисклеймер
В компании "Тантор Лабс" я отвечаю за развитие направления 1С, поэтому все примеры я буду рассматривать в связке работы приложения 1С с "СУБД Tantor Special Edition 1C". Однако на месте 1С может быть любое приложение, поэтому весь предоставленный ниже материал универсален и будет полезен каждому слушателю.
Профайлеры запросов
На текущий момент "1С" работает на двух основных системах управления базами данных: MS SQL и форках СУБД PostgreSQL. Как и большинство 1С-ников, я начинал работать с "1С" именно на MS SQL, и в первый раз познакомился с профайлером спустя три года работы. Какой-то функционал стал работать медленно, кто-то из коллег спросил, смотрел ли я долгие запросы профайлером, и вот тогда я стал гуглить, что такое профайлер, как его установить и как пользоваться. Думаю, что при подобных обстоятельствах с профайлерами познакомился не один я.
В MS SQL есть 2 реализации профайлера:
- SQL Server Profiler — отдельное приложение, которое шло в составе дистрибутива отдельно от SQL Server Management Studio.
- Extended Events — компонента внутри SQL Server Management Studio, которая позволяла выполнять все необходимые действия с инстансом в режиме "единого окна".
Оба этих профайлера позволяли легко выполнять поставленную задачу: собирать все запросы и их планы согласно установленным критериям отбора (база, длительность, имя таблицы, участвующей в запросе) и визуально их анализировать. Когда работаешь с такими инструментами, то даже не задумываешься о том, насколько они полезны и упрощают решаемую задачу.
А как с этим обстоят дела в мире PostgreSQL? Там не то чтобы нет подобных удобных графических инструментов, там вообще отсутствует возможность собрать трассировку. Да, какие-то полуварианты есть, и давайте рассмотрим их:
- log_min_duration_statement — настройка позволяет сохранять в лог СУБД все тексты запросов длительностью более, чем указано в данном параметре. Но только тексты, без планов.
- auto_explain — расширение позволяет сохранять в лог СУБД все тексты запросов и их планы, длительностью более чем указано в параметре
auto_explain.log_min_duration. - pg_tracing - расширение, реализующее сборщик телеметрии по протоколу OTEL. Оно больше подходит для наблюдения за системой, чем для сбора трассировки запросов.
Первые два способа неудобны тем, что они пишут данные в общей лог СУБД, где, помимо текстов запросов и их планов, может быть огромный объём информации о том, что происходит на инстансе. Также нельзя установить дополнительные отборы не только по PID'у или тексту запроса, но даже по базе. И, если у вас на инстансе 10 баз, то логироваться запросы будут с них всех. Как среди всего этого найти долгий запрос при проведении документа "Реализация товаров и услуг", который вы проводите в отдельно выделенной для вас базе?
В сообществе 1С была одна попытка доработать auto_explain для этого — 1С и Postgres: первый серьёзный опыт борьбы и противостояния, постигаем open source. Я взглянул на эту статью по-новому, когда стал работать в компании "Тантор Лабс", ведь собрать трассировку согласно простейшим отборам — это именно то, что нужно всем, кто сталкивается с задачей поиска и оптимизации длительных запросов. У коллег тоже был опыт работы с различными профайлерами запросов и желание реализовать нечто подобное и для нашей СУБД Tantor.
pg_trace
Наш путь создания профайлера делится на 2 этапа:
- Создание расширения, которое будет собирать трассировку.
- Создание GUI для удобной работы пользователя, которое позволит в пару кликов настраивать отборы, запускать трассировку и работать с её результатами.
Сегодня мы поговорим о первом этапе — расширении pg_trace, которое является сердцем создаваемого профайлера. Автором расширения является Сергей Соловьев, разработчик "Тантор Лабс". Чтобы разговор был наглядным, рассмотрим работу нашего расширения на сквозном примере из "1С".
Постановка задачи
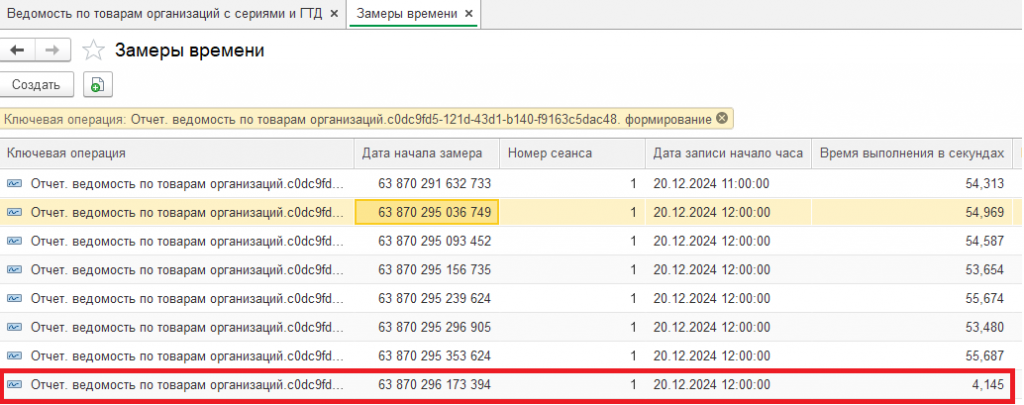
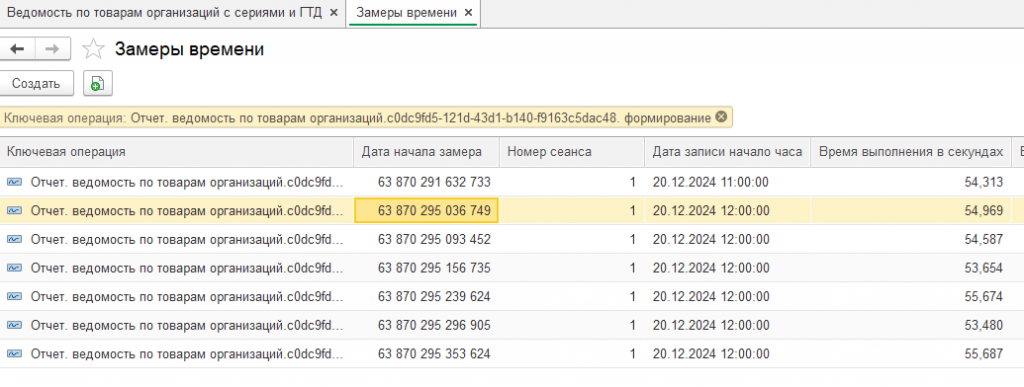
У нас есть отчёт "Ведомость по товарам организаций", который в среднем выполняется 54 секунды. Есть предположение, что основное его время занимает длительный запрос к базе данных, и необходимо подтвердить или опровергнуть это предположение.

Установка pg_trace
Расширение pg_trace идет в составе дистрибутивов следующих редакций СУБД Tantor, начиная с версии 16.6: Certified, Special Edition (SE), Special Edition 1C (SE 1C).
Порядок установки:
1. Добавляем расширение в shared_preload_libraries:
shared_preload_libraries = 'pg_trace'
2. Изменение shared_preload_libraries требует рестарта инстанса:
systemctl restart tantor-se-1c-server-16.service
3. Создадим расширение:
postgres=# CREATE EXTENSION pg_trace;
CREATE EXTENSION
Установка завершена.
Дополнительно мы поменяем формат плана запроса для того, чтобы его проще было визуализировать:
pg_trace.plan_format = 'json'
! Разграничение прав
Трассировка —это функция, которая должна быть доступна только определенной группе пользователей, отвечающих за SRE. Настроить доступы к функциям управления трассировкой (старт/стоп) можно через команды управления доступом GRANT/REVOKE. Например:
REVOKE EXECUTE ON FUNCTION pg_trace_start FROM public;
REVOKE EXECUTE ON FUNCTION pg_trace_stop FROM public;
GRANT EXECUTE ON FUNCTION pg_trace_start TO superuser;
GRANT EXECUTE ON FUNCTION pg_trace_stop TO superuser;
Если у вас нет упомянутых выше редакций СУБД Tantor, то вы можете попробовать функционал расширения на нашей бесплатной редакции Tantor BE.
Сделать это можно следующим образом:
1. Скачиваем установщик расширений и даем на него права:
wget https://public.tantorlabs.ru/db_extension_installer.sh
chmod +x db_extension_installer.sh
export NEXUS_URL="nexus-public.tantorlabs.ru"
2. Устанавливаем расширение:
./db_extension_installer.sh --database-type=tantor --edition=be --database-major-version=16 --extension=pg-trace
Вместе с расширением будет установлена в данном случае Tantor BE 16.
Данная возможность предоставляется для следующих ОС:
- AstraLinux 1.7
- AstraLinux 1.8
- Ubuntu 20
- Ubuntu 22
Сбор трассировки
Старт трассировки осуществляется командой pg_trace_start(). В неё можно передать отборы, с которыми мы хотим собрать трассировку. Для отбора доступны следующие поля:
| Параметр | Тип | Описание |
backend_pid |
int | Номер бекенда. В консоли кластера 1С соответствует полю "Соединение с СУБД" |
user_id |
oid |
|
database_id |
oid |
|
duration |
interval | Длительность выполнения запроса |
query_like |
text | Отбор по шаблону текста запроса |
plan |
boolean | Включение сборки плана запроса |
timeout |
interval | Время, которое будет собираться трассировка. Если не задать этот параметр, то трассировка будет собираться то количество времени, которое указано в параметре pg_trace.trace_timeout (по умолчанию 10 минут) |
Запустим нашу трассировку. Собираем все запросы и их планы длительностью более 1 секунды, также установим отбор по базе:
postgres=# SELECT pg_trace_start(
plan := TRUE, duration := '1000ms', database_id := 707533240
);
pg_trace_start
----------------
t
(1 строка)
По умолчанию трассировка выводится в unix-сокет "/tmp/pg_trace.sock" с помощью собственного протокола. Это позволяет читать события как вручную, так и написать программу для автоматической обработки. Рассмотрим оба варианта.
Вручную читать события можно с помощью команды nc и, например, перенаправить ее вывод в файл следующей командой:
nc -U /tmp/pg_trace.sock > trace_file.txt
Мы будем собирать трассировку с помощью питоновского скрипта, который умеет читать события и выводить их в 2-х форматах: JSON отформатированный и CSV. Сохранять трассировку будем также в файл:
python3 client.py --unix-socket=/tmp/pg_trace.sock --format=json > trace_file.log
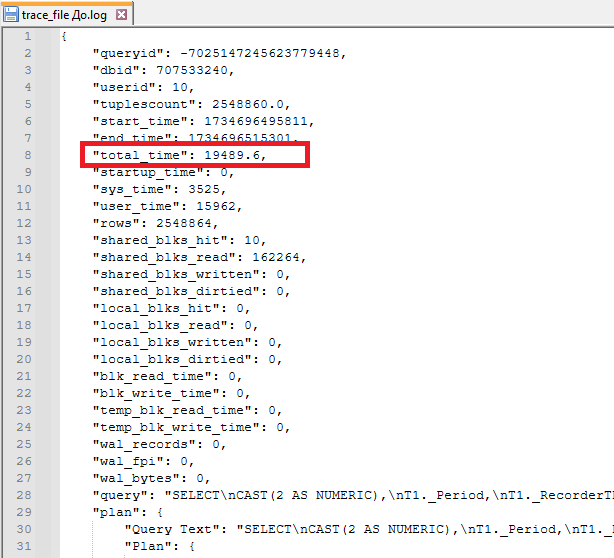
Выполняем наш отчёт в 1С, далее смотрим полученный файл:

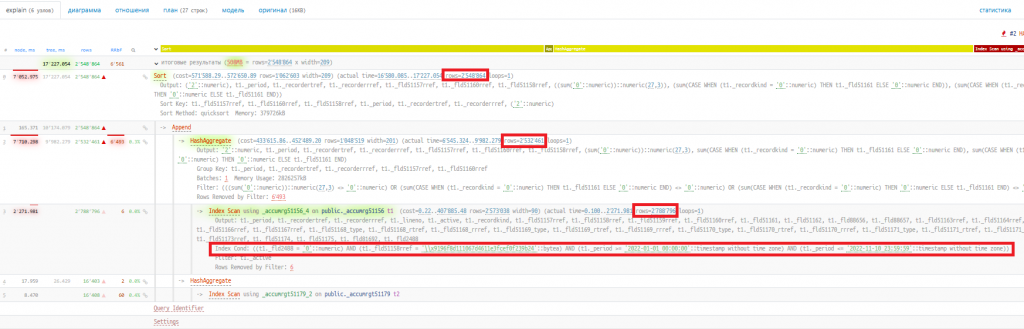
В нём есть один запрос длительностью 19 секунд — "total_time": 19489.6 (описание всех собираемых полей доступно в документации). Можно сделать вывод, что основную часть времени выполнения отчёта занимает не один какой-то запрос, а что-то другое (возможно множество запросов менее 1 секунды или вычисления на стороне сервера приложений 1С). Давайте рассмотрим этот долгий запрос, возьмём его план из трассировки и визуализируем:

Из плана запроса видно, что из таблицы "РегистрНакопления.ТоварыОрганизаций" (_accumrg51156) выбирается более 2-х млн записей, затем они агрегируются, объединяются с другим набором и сортируются. Эти операции долго выполняются из-за того, что им приходится обрабатывать довольно большой объём строк.
Поле _Fld51158RRef — это организация, таким образом из регистра накопления выбираются все записи за выбранный период по одной организации. Давайте попробуем уточнить отборы в отчёте и посмотрим, сколько в таком случае будет выполняться этот запрос. Добавим отбор по полю "НомерГТД" (_Fld51160RRef) и соберём следующую трассировку:
postgres=# SELECT pg_trace_start(
plan := TRUE, database_id := 707533240, query_like := '%_AccumRg51156%'
);
pg_trace_start
----------------
t
(1 строка)
Мы убрали отбор по длительности и добавили отбор по тексту запроса, чтобы поймать все запросы, которые обращаются к таблице _accumrg51156.
Если мы выполняем команду pg_trace_start(), пока активна прошлая трассировка, то она будет переинициализирована с новыми параметрами отбора.
Выполняем отчёт ещё раз, но уже с отбором по полю "НомерГТД", и смотрим полученный файл трассировки: наш долгий запрос теперь выполнился за 1 секунду — "total_time": 1067.32.
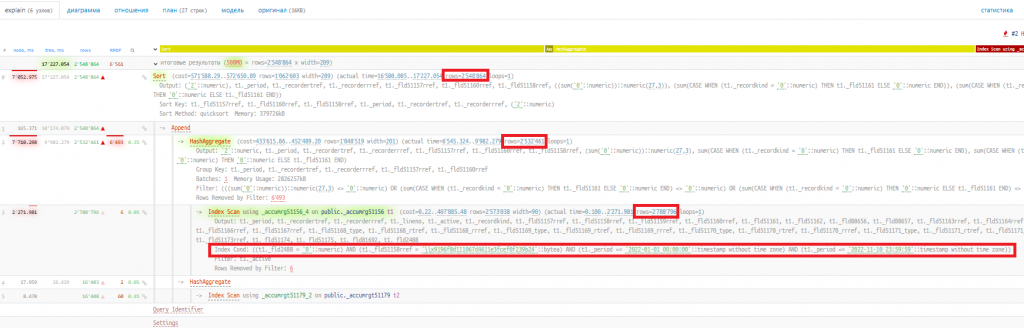
Смотрим его план:

При выборке данных из таблицы "РегистрНакопления.ТоварыОрганизаций" (_accumrg51156) фильтр по полю "НомерГТД" (_Fld51160RRef) позволил значительно сократить выборку: 234 строки вместо 2 788 796. Все последующие операторы за счёт того, что им на вход передавалось небольшое количество строк, отработали значительно быстрее.
Наш отчёт выполнился за 4 секунды:

Остановим трассировку:
postgres=# SELECT pg_trace_stop();
pg_trace_stop
---------------
t
(1 строка)
Если этого не сделать явно, она сама остановится через промежуток времени, который задан в параметре pg_trace.trace_timeout (по умолчанию - 10 минут).
! Автоматическое завершение трассировки
Трассировка — это функция, которая не должна быть включена на постоянной основе в продуктиве, потому что она может влиять на производительность. В MS SQL она будет собираться до тех пор, пока вы ее не остановите или не будет достигнут максимальный размер файла или максимальное количество строк трассировки. С учетом этого опыта мы специально реализовали функцию автоматического завершения трассировки.
Влияние на производительность
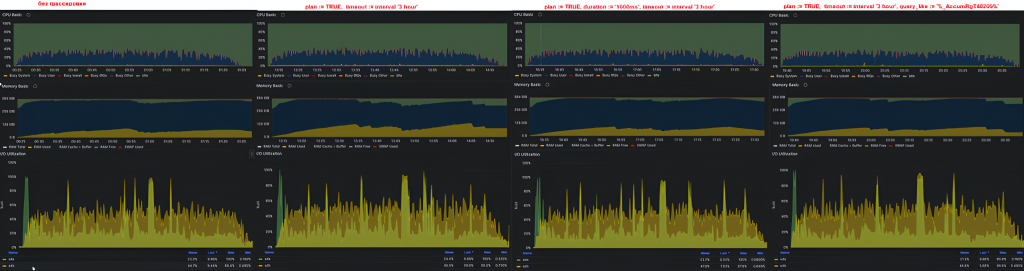
Сбор трассировки полезен как в тестовой зоне (на этапе разработки и оптимизации различных механизмов), так и в продуктиве — именно для того, чтобы быстро найти запрос, из-за которого у пользователей что-либо стало работать медленно. Важно, чтобы сбор трассировки не сделал все еще хуже. Чтобы оценить влияние сбора трассировки на время выполнения ключевых операций, мы провели нагрузочное тестирование.
Тестовый стенд:
- Сервер приложений 1С: ОС Astra Linux 1.7.5, 1С Предприятие 8.3.24.1674 (z), 32 CPU, 126 Гб ОЗУ.
- Сервер СУБД: ОС Astra Linux 1.8.1, Tantor SE 1C 16.6.0, 48 CPU, 378 Гб ОЗУ. Tantor SE 1C настроен согласно нашим рекомендациям.
Нагрузочный тест:
Конфигурация - ERP 2.5, размер базы - 646 Гб.
Эмулируется работа 349 виртуальных пользователей, которые за 1 час выполняют 29 тысяч ключевых операций (8.7 млн запросов к БД).
Профиль нагрузки — смешанный:
- 30% — открытие форм списков и документов;
- 30% — проведение документов;
- 30% — формирование отчетов;
- 10% — работа с обработками.
Результаты:
|
Настройки трассировки |
Среднее время операции (сек.) |
|---|---|
|
Без сбора трассировки |
2,099 |
| plan := TRUE, timeout := interval '3 hour' | 2,179 |
| plan := TRUE, duration := '1000ms', timeout := interval '3 hour' | 2,095 |
| plan := TRUE, timeout := interval '3 hour', query_like := '%_AccumRgT48209%' | 2,084 |
Настройки pg_trace были по умолчанию.
Видим, что сбор трассировки на результатах почти не отразился, только сбор всех планов запросов ухудшил результат всего на несколько процентов. Также сбор всех планов запросов утилизировал больше ОЗУ, чем другие варианты:

Ссылка на изображение в высоком качестве
В остальном все показатели оборудования почти не отличались.
По полученным результатам можно сделать следующие выводы:
- Сбор трассировки при большой нагрузке со стороны приложения происходит успешно, ошибок со стороны СУБД не обнаружено, все тесты завершались успешно.
- Сбор всех запросов с планами запросов без отбора по длительности может несущественно влиять на производительность, но такой сценарий использования в продуктиве использовать не рекомендуем, т.к. полученная трассировка не будет информативной и не упростит поиск проблемных запросов. Также это приводит к повышенной утилизации ОЗУ на сервере СУБД.
- Сбор всех запросов с планами запросов с длительностью более 1 секунды или поиск запроса по конкретному шаблону на производительность влияния не оказывает. Такой вариант трассировки вполне может использоваться в том числе на продуктиве опытными разработчиками и экспертами "1С".
Наша команда разработки очень много времени и внимания уделяет производительности выпускаемых решений, и результаты данного тестирования это наглядно показывают.
Трассировка как инструмент анализа
Трассировка позволяет собирать данные о работе различных компонентов системы, и это помогает в создании сводной информации о её состоянии и производительности. С помощью анализа можно выявить узкие места, оптимизировать ресурсы и улучшить общую эффективность работы системы. Давайте выполним анализ нашей трассировки.
Упомянутый выше скрипт позволяет собрать трассировку в формате CSV, что удобно для последующего статистического анализа всех выполненных запросов.
Я собрал в файл все запросы во время нагрузочного теста ERP. Трассировка была запущена с параметрами: plan := TRUE, timeout := interval '3 hour', т.е. собираем все запросы и их планы.
Сбор трассировки в файл осуществлялся следующей командой:
python3 client.py --format=csv --unix-socket=/tmp/pg_trace.sock > output.csv
На выходе получился файл output.csv размером 125 Гб, который нужно загрузить в БД для последующего анализа.
Создадим базу:
postgres=# CREATE DATABASE traces;
Создадим таблицу, в которую будем загружать полученный файл. Но таблица будет не обычная "хиповая", а оптимизированная под аналитические запросы - columnar:
traces=# CREATE TABLE pg_trace_columnar (
queryid bigint,
dbid integer,
userid integer,
tuplescount numeric,
start_time bigint,
end_time bigint,
total_time float8,
startup_time float8,
sys_time float8,
user_time float8,
rows int8,
shared_blks_hit int8,
shared_blks_read int8,
shared_blks_written int8,
shared_blks_dirtied int8,
local_blks_hit int8,
local_blks_read int8,
local_blks_written int8,
local_blks_dirtied int8,
blk_read_time float8,
blk_write_time float8,
temp_blk_read_time float8,
temp_blk_write_time float8,
wal_records int8,
wal_fpi int8,
wal_bytes numeric,
jit_functions int8,
jit_generation_time float8,
jit_optimization_time float8,
jit_inlining_time float8,
jit_emission_time float8,
query VARCHAR(1500),
plan text
) using columnar;
Загружаем трассировку:
traces=# COPY pg_trace_columnar
FROM '/var/lib/postgresql/output.csv'
WITH (DELIMITER ';',FORMAT csv, HEADER true);
----------------------------
COPY 8792996
Трассировка загружена. Давайте получим метрики нашего нагрузочного теста:
traces=# \timing on
traces=# SELECT
SUM(total_time) AS queries_total_time,
AVG(total_time) AS queries_avg_time,
MAX(total_time) AS queries_max_time,
MIN(total_time) AS queries_min_time,
SUM(shared_blks_hit) AS shared_blks_hit,
SUM(shared_blks_read) AS shared_blks_read ,
SUM(local_blks_hit) AS local_blks_hit,
SUM(local_blks_read) AS local_blks_read
FROM
pg_trace_columnar;
queries_total_time | queries_avg_time | queries_max_time | queries_min_time | shared_blks_hit | shared_blks_read | local_blks_hit | local_blks_read
--------------------+--------------------+------------------+------------------+-----------------+------------------+----------------+-----------------
29614580.94511461 | 3.3679738902547673 | 29347.5 | 0.00075 | 6836559844 | 4328714 | 963126388 | 2704980
(1 строка)
Время: 808,669 мс
Теперь мы, в частности, знаем, что среднее время выполнения запроса составило 3.36 мс, самый долгий был 29 секунд, суммарное время всех запросов было 29614 секунд (чуть более 8 часов) и т.д. А сколько было выполнено запросов длительностью более 1 секунды? Давайте узнаем:
traces=# SELECT
COUNT(1) AS queries_count
FROM
pg_trace_columnar
WHERE total_time > 1000;
queries_count
---------------
2179
(1 строка)
Время: 318,811 мс
Использование колоночного хранения по сравнению с традиционным строковым позволяет в 10-15 раз быстрее выполнять аналитические запросы к базе данных, поэтому оно хорошо подходит для анализа огромных трассировок.
Вступайте в нашу телеграмм-группу Инфостарт