Эволюция сложности систем 1С
Меня зовут Григорий Шатров. Я прошeл путь от стажeра до тимлида и проектного архитектора. Более 11 лет я не прекращал программировать и видел множество паттернов и антипаттернов разработчиков, о которых хочу рассказать.
Более 30 лет назад, когда зарождалась платформа 1С, системы представляли собой достаточно простые конструкции, состоящие из нескольких «кирпичиков». Однако даже тогда они вызывали живой интерес и воодушевление, казались чем-то необычным и значительно помогали пользователям.
Со временем эти «кирпичики» превратились в большие мегаполисы с развитой инфраструктурой, множеством «небоскрeбов», сложными большими данными. Требования к скорости работы систем становились очень высокими, число пользователей росло, и платформа 1С завоевала доверие практически каждого пользователя.
Несмотря на то, что современные системы представляют собой сложные высокотехнологичные сооружения, я наблюдаю, что большинство разработчиков до сих пор используют подходы, актуальные ещe 10 лет назад. Это естественно, ведь эти «небоскрeбы» по-прежнему строятся из тех же «кирпичиков». Все разработчики по инерции и привычке используют знакомые, удобные и понятные методы.
Раньше, чтобы подняться на верхние этажи здания, достаточно было лестницы. Но теперь, когда появились небоскрeбы, одной лестницы уже недостаточно. Нужны скоростные лифты. В этой статье я как раз хочу рассказать о таких «скоростных лифтах» – подходах и методах разработки, которые совершенно не сложны в применении и могут быть использованы уже завтра при построении новых систем, подсистем и работе с типовыми корпоративными конфигурациями.
Хочу сразу отметить, что все эти подходы применимы в случаях, когда стандартные методы уже не справляются: когда в системах миллионы записей в регистрах и тысячи строк в табличных частях.
Подход 1: Оптимизация тяжелых форм
Наверняка вы видели такие формы, куда «засунуто» абсолютно всe: тысячи реквизитов, сотни вкладок, собраны все возможные действия.
Например, очень часто встречаются карточки контрагентов. Туда тянут все данные: информацию о контрагенте, записи АТС, события CRM, всe, что накопилось в базе, договоры, состояние ЭДО, какие-нибудь обмены, отчеты, дебиторская задолженность – всe, что может понадобиться всем пользователям, которые сталкиваются с контрагентами в наших учетных системах. Хорошо, когда таких пользователей один-два, но когда их становится много, а данных – просто куча, такие формы начинают сильно тормозить при открытии.

Как можно решить эти проблемы? Первым делом необходимо разделить данные по сценариям использования, то есть учитывать, какие данные кому конкретно нужны в этой форме.
Например, если это оператор, показываем ему только данные по контрагенту и последние события из CRM. Если это бухгалтер, то это будет задолженность и состояние договоров. Таким образом, по ролям мы разделяем формы, создаем разные формы или разное поведение одной формы, и не тянем все данные сразу. В итоге получаем данные порциями.

Второй момент: даже если вы разделили данные по сценариям, но объем информации всe равно большой и еe нужно показать, что можно сделать? Первое – это не получать все данные сразу, а получать их асинхронно.
При открытии формы вы показываете только то, что нужно на первой вкладке. По-настоящему пользователь в 99% случаев использует первую вкладку этой большой формы, а какая-нибудь четвертая вкладка используется, скажем, в 1–2% случаев (статистика «теплоты использования»). Такие данные можно получать асинхронно.
Например, есть вариант получать их после определенного пользовательского действия. Это может быть переключение вкладок, нажатие на сворачиваемые группы, отдельные команды, отчеты и тому подобное. Также все эти данные можно получать не сразу при открытии формы, а чуть позже, с помощью различных механизмов. Это может быть подключение обработчика ожидания – самый классический, старый метод. С помощью фонового задания мы возвращаемся с сервера на клиент и показываем недостающие данные.
То же самое можно реализовать с помощью системы взаимодействия. Сейчас таких реализаций уже очень много. А также, начиная с 26-й платформы, появился новый объект – менеджер уведомления клиента, который дает возможность передавать все необходимые данные с сервера на клиент и отображать нужную информацию (вкладки) постфактум, то есть после первоначальной загрузки формы, для каждого пользователя.
Подход 2: Оптимизация динамических списков
Наша платформа 1С – это большой и крутой инструмент, который облегчает жизнь практически любому разработчику и пользователю. Она предоставляет множество универсальных возможностей «из коробки», как настоящий университет.

Можно вытащить практически из любой формы динамического списка любые поля через несколько кликов. Можно вытаскивать характеристики, сортировать по любой колонке, использовать полнотекстовый поиск (он выводится на форме в зависимости от версии платформы, если вы его отдельно не отключили). И все эти универсальные механизмы, если их использовать в списках со сложными запросами, будут вызывать максимальные тормоза и отпугивать пользователей от списков и системы в целом. Что делать?
Необходимо тщательно выбрать, какие именно инструменты действительно нужны, отключив всю универсальность. Это могут быть конкретные поля, по которым разрешена сортировка и которые индексированы в запросе списка. Это могут быть конкретные сортировки, которые по галочкам в форме разрешают выполнять определенные, заранее просчитанные правильные действия, чтобы все эти запросы были максимально быстрыми.

Возможны два варианта поиска необходимых инструментов. Либо мы отключаем всe, выпускаем в прод, ждем обращений в сервис-деск, получаем необходимые задачи и потом дорабатываем. Второй вариант – всe-таки заранее изучить и получить нужные задачи, которые будут решать наши универсальные инструменты, и реализовать нужные действия. Но, как мы знаем, заказчики обычно не знают до конца, чего именно они хотят, поэтому это будет достаточно сложно, и, возможно, первый вариант будет более приемлемым.
Также, думаю все знают, основную боль при использовании полнотекстового поиска – у нас могут сформироваться очень сложные запросы, которые максимально затормозят отсортированный список.
Поле полнотекстового поиска по умолчанию выводится в платформе. Многие разработчики забывают, где оно находится и как отключается. На рисунке показан сам элемент, который отключается – это полнотекстовый поиск, и мы можем оставить только Ctrl-F и поиск по конкретной колонке.
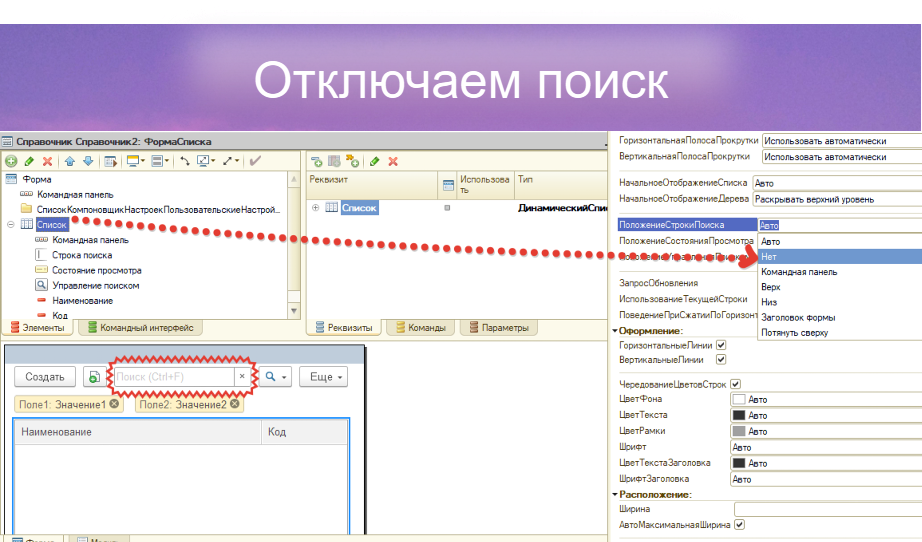
Начиная с 26-й платформы, у нас появилась возможность программно отключать и взаимодействовать с этим полем поиска, отключив его для конкретных списков не только интерактивно в конфигураторе или другой среде, но и непосредственно в коде для всех списков. Вы можете управлять этим.
Также в процессе оптимизации не стоит забывать – если у динамического списка достаточно простой запрос с использованием соединений, есть возможность отключить обязательность использования конкретной таблицы.
При ее отключении, если мы не будем использовать поля из этих таблиц, платформа сможет оптимизировать такие запросы и просто не выполнит соединение.
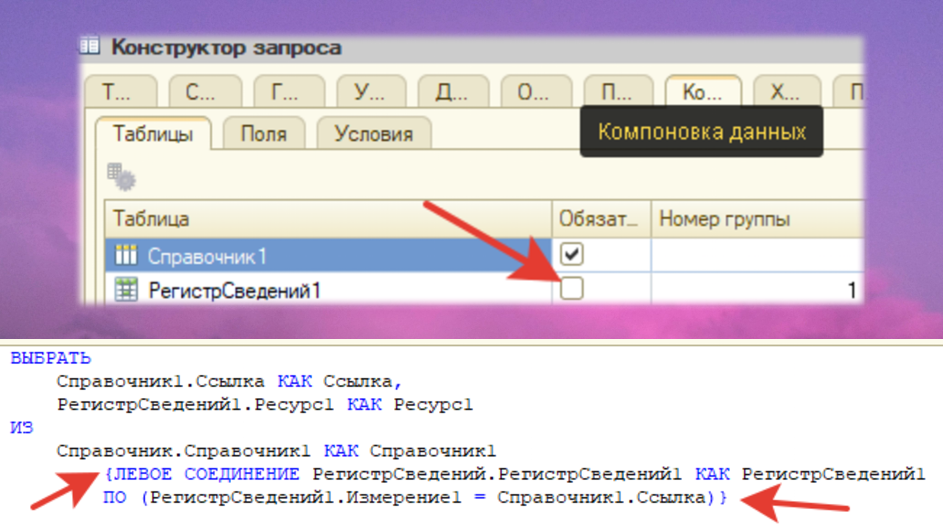
Если же у нас достаточно сложные запросы, почему-то все забывают про одно событие, хотя ему уже десятки лет, я люблю популяризировать его среди разработчиков. Это событие «ПриПолученииДанныхНаСервере», то есть на элементе динамического списка. По ссылке https://its.1c.ru/db/v8325doc/bookmark/dev/TI000000391 есть примеры на ИТС, где это используется, и показано, что оно делает.
Если у нас, допустим, 10 вложенных запросов, временных таблиц и тому подобного, перебор типа FIFO и другие сложные алгоритмы, мы можем взять, например, 60 строк, которые попали на экран в динамическом списке, получить эти строки и только для них вычислить эти сложные расчeты. Тем самым мы ускоряем работу и очень быстро отдаем результат пользователю.
Подход 3: Работа с индексами

Допустим, мы спроектировали новую систему, создали конкретные регистры с измерениями и ресурсами. Все это получилось.
Но когда у нас достаточно сложная система, бывает так, что мы заранее не знаем, как именно будет использоваться этот регистр – по каким ключевым полям будут формироваться отчеты, списки, отборы и тому подобное. Что же делать? Предлагаю включить индексы по всем полям, отдать систему в эксплуатацию на несколько недель или месяц и посмотреть статистику использования этих индексов в СУБД.
После того как мы увидим, что, например, из пяти созданных индексов один используется в 90% случаев, другой – в 8%, а оставшиеся – в 2%, мы индивидуально принимаем решение об удалении неиспользуемых индексов и продолжаем наблюдение. Таким образом мы можем периодически актуализировать индексы.
Мы знаем, что индексы большие, для их создания и поддержки при записи может требоваться много времени, и они могут занимать больше места, чем сами данные. У индексов есть ограничения. Так, в кортеже индексов не может быть больше 16 полей. При создании индексов в платформе каждое следующее проиндексированное поле включается в кортеж.
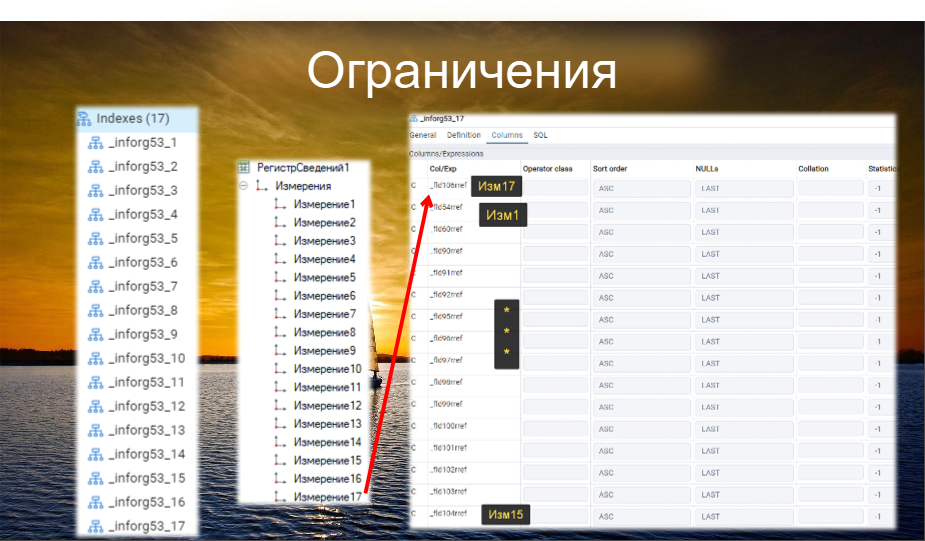
Если полей больше 16, например, 17 измерений в регистре сведений. Мы индексируем 16 измерений, а 17-е не индексируем. Получается 16 индексов, где каждое поле поочередно становится первым, а остальные поля включаются в кортеж сверху вниз по порядку. Если добавляется 17-е поле, оно становится первым, а поля с первого по пятнадцатое участвуют в кортеже.
Хотя такое ограничение достаточно объемное, фирма 1С пошла нам навстречу в 26-й платформе. На тестовом стенде с Postgres были получены определенные изменения. Они заключаются в том, что у нас появилась возможность для объектов, их табличных частей и виртуальных таблиц создавать индексы непосредственно в самом объекте.
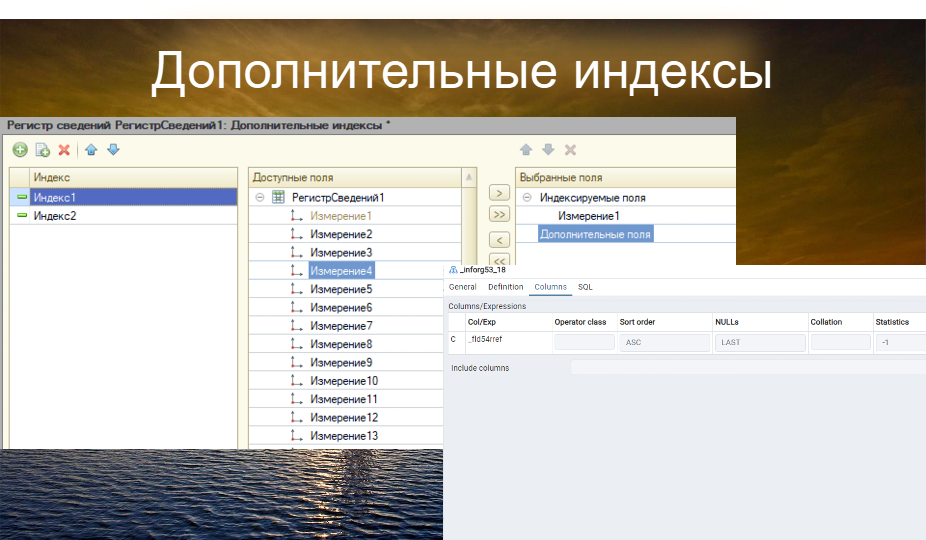
Допустим, мы хотим добавить одно поле (измерение) в индекс. Всего одно поле, без каких-либо условий – были ли другие поля проиндексированы или нет. То есть мы сокращаем размеры и увеличиваем скорость записи. Также, если мы захотим добавить в индекс не проиндексированное поле из регистра, абсолютно любое поле, которое не было проиндексировано в метаданных, мы тоже сможем его добавить, и оно образует новый индекс. Всe отлично, но есть одно «но» – всe это доступно только с корпоративной лицензией 1С.
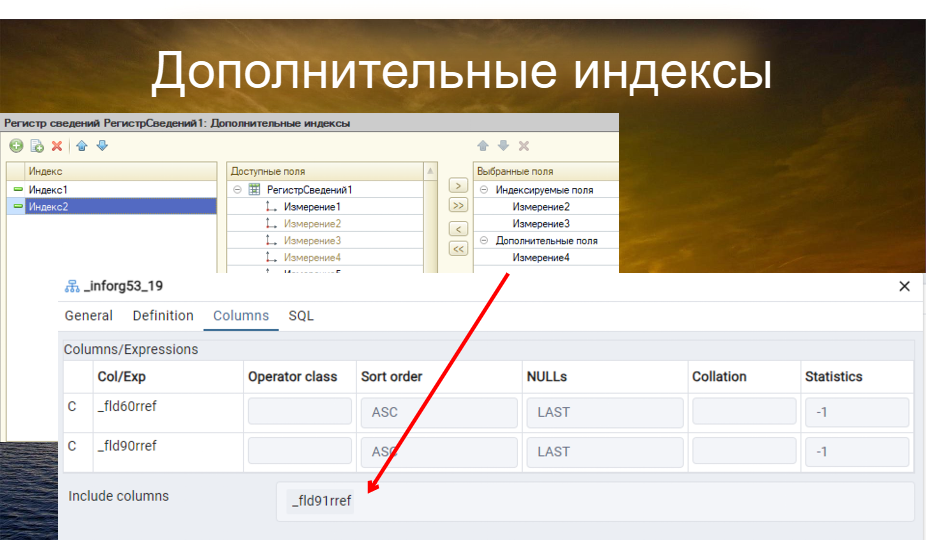
Если мы захотим добавить еще полей в индекс, есть дополнительная функция, которая называется «дополнительные поля индекса». Туда мы можем включать неключевые (include) поля, чтобы избежать дополнительных обращений к таблице после обращения к самому индексу. Мы помещаем туда нужные поля, которые потребуются в результате запроса, и система сама их отдаст. Это называется include columns. Если мы захотим поменять порядок полей в этих дополнительных индексах, мы сможем это сделать без изменения метаданных самого регистра.
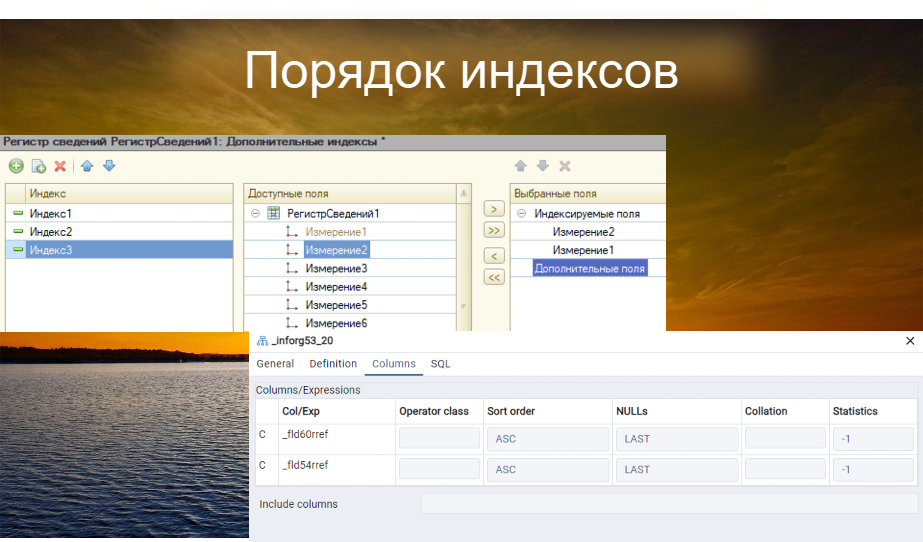
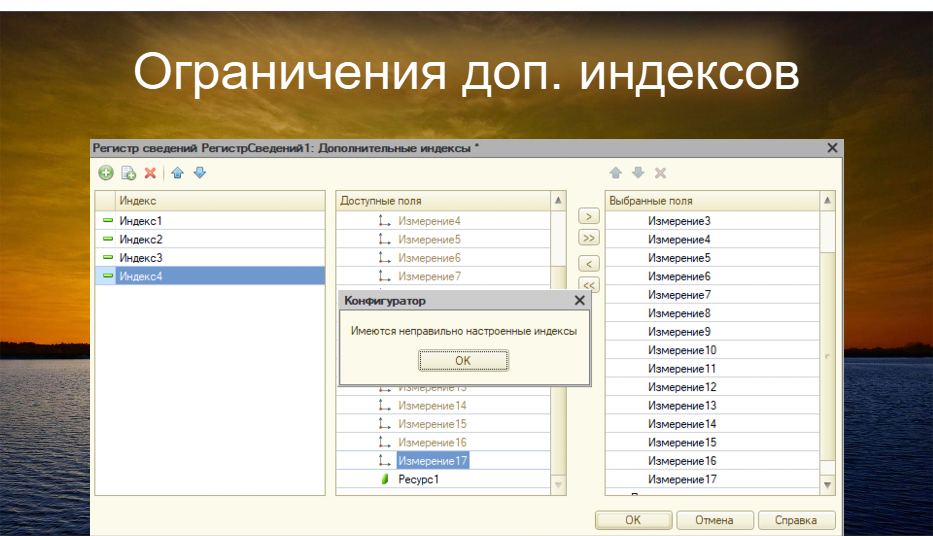
Мы теперь не привязаны к порядку полей внутри регистра для формирования кортежа индекса, а можем сделать это непосредственно в функциональности дополнительных индексов. Вот такое классное нововведение от платформы 1С. Но и тут не обошлось без ограничений – в один кортеж мы не можем включить больше 16 полей. При попытке добавления мы получим ошибку от самой платформы 1С.
Подход 4: Оптимизация блокировок
Часто по нашим мониторингам мы видим, что в топ операций по времени попадает блокировка данных, а именно оператор «Заблокировать()». Расследуем дальше, смотрим: вроде как написан код для конкретной табличной части, по конкретному источнику данных, для простого документа. Но почему-то всe равно время блокировки достаточно большое, при этом параллельных операций нет.
Смотрим дальше: а это объект с большим количеством записей в табличных частях. Их может быть 10 000. И эти 10 000, помещаясь в менеджер сервиса управления блокировками, просто тормозят процесс помещения, а потом и извлечение этих записей может занимать достаточно длительное время.

Для оптимизации предлагается блокировать весь регистр, но исключительно для определенных операций. Всегда блокировать весь регистр мы, конечно же, не сможем. Мы должны понимать, что параллельно это сделать нельзя, если данный регистр используется другими операциями. Нужно это делать, когда есть технологическое окно у нашего бизнеса.
Тут придется поговорить с бизнесом, либо просто прикинуть. Это можно сделать, когда мы переходим с одной системы на другую. У нас точно нет других параллельных операций. Мы непосредственно делаем блокировку всего регистра и тем самым можем быстрее получать данные из менеджера сервиса управления блокировками и блокировать все записи. Еще более актуально – это может быть ночью, когда у нас есть какой-нибудь расчет себестоимости и никого нет.
Нужно изучить конкретное использование этого регистра: параллельно кто-то еще работает или нет, можем ли мы все-таки заблокировать его для ускорения данной операции. Еще актуальнее этот метод оптимизации становится, когда в 27-й версии платформы появляется возможность увеличивать количество строк в табличной части.
Сейчас у нас лимит 99999, то есть 10 в пятой степени минус 1. Платформа дает возможность увеличивать этот лимит на уровне разработчиков, и они будут увеличивать его до 10 в девятой степени, то есть миллиард строк в документе будут попадать под блокировку и тормозить еще сильнее.
Подход 5: Повторное использование
Я думаю, все знают, что повторное использование часто применяют для оптимизации.
Когда к нам попадает какая-то процедура, которая используется, допустим, десятки тысяч раз в нашем мониторинге, мы должны обратить внимание на эту функцию и достаточно быстро проверить, можно ли еe оптимизировать за счет повторного использования, какие параметры в неe попадают и повторяются ли они. Таким образом, эту процедуру, попавшую в наш мониторинг, следует рассматривать как «темно-серый ящик» – не совсем черный, потому что всe же придется немного проанализировать еe работу.
Вызывает ли она сама себя – то есть, является ли она рекурсивной? Используются ли в этой процедуре данные из базы данных, которые могут измениться за время выполнения этих тысяч итераций? Это достаточно быстро проверяется, поэтому такой метод можно применять, чтобы быстро попытаться реализовать повторное использование.

В оптимизации главное – не сломать текущий бизнес-процесс. После нашей оптимизации все данные и сценарии, которые мы оптимизировали, должны выполняться точно так же, как и до нее.
Подход 6: Замена Отмены проведения
Часто для розничных клиентов встречается такая операция, как закрытие кассовой смены. Это когда для одной конкретной кассовой смены (измерения) отменяют проведение или удаляют тысячи документов (чеков) в зависимости от настроек. Удаляются все их движения, и после этого данные переносятся в отчет о розничных продажах.

Это кейс реальной оптимизации. Мы заменяем одну очень простую процедуру (где отменяются все чеки), на два простых действия.
-
Непосредственно в самом регистре удаляем нужные записи регистра, по которым формируют движения все эти чеки, предварительно проанализировав по нужным измерениям.
-
После этого устанавливаем у каждого документа признак проведения (истина/ложь) или пометку на удаление с помощью механизма обмена данными. Глобально весь этот большой сценарий становится быстрее – с минут до десятков секунд, в зависимости от объема самих чеков.
Подход 7: Тестирование и проектирование интерфейсов
Допустим, мы отлично спроектировали систему и написали подробное ТЗ. Наш цикл разработки прошел супер гладко. Что происходит дальше?
Многие разработчики просто забывают о тестировании. Вы скажете: «Да нет, конечно, всe протестировано – и разработчиком, и аналитиком». Возможно, даже покрыто автотестами. Но все забывают, что нужно тестировать не только то, что просил пользователь, но и то, что он может нажать случайно или неожиданно – проводить негативное сценарное тестирование.
Обычно тестируют только «оптимистичные» сценарии: пользователь сделал именно то, что просили. Да, вы можете убрать ненужные кнопки с формы, но пользователь найдет горячие клавиши, перейдет, например, в мобильный клиент (если доступно), где логика работы может отличаться, и всe равно совершит ошибочные действия. В больших системах такие ошибки становятся гораздо сложнее и опаснее, чем в маленьких или средних.
Чтобы этого избежать, нужно отказываться от форм, рассчитанных на «умных» пользователей. Все наши формы должны превращаться в визарды (мастера). Что это такое? Это формы с 4–5 полями, с максимально простыми заголовками, где понятно, как выбирать значения. При этом заголовки действий должны чeтко отражать их суть.
Например, «Способ записи на прием». Не каждый пользователь поймет, что с этим делать – выбирать, заполнять, создавать? Нужно писать конкретно: «Выберите способ записи на прием». Это важный момент. Казалось бы, элементарно, но часто на интерфейсах об этом забывают, усложняя жизнь пользователям. Также все сообщения об ошибках, возникающих при работе с визардом, должны быть максимально простыми и понятными – чтобы было ясно даже первоклашке.
Как понять, что разработанный визард простой? Очень просто: если вам не нужно писать инструкцию к интерфейсу, если всe максимально понятно – значит, интерфейс хороший. Если какие-то данные уже понятны из контекста авторизации, их нужно просто отображать, а не давать возможность изменять.
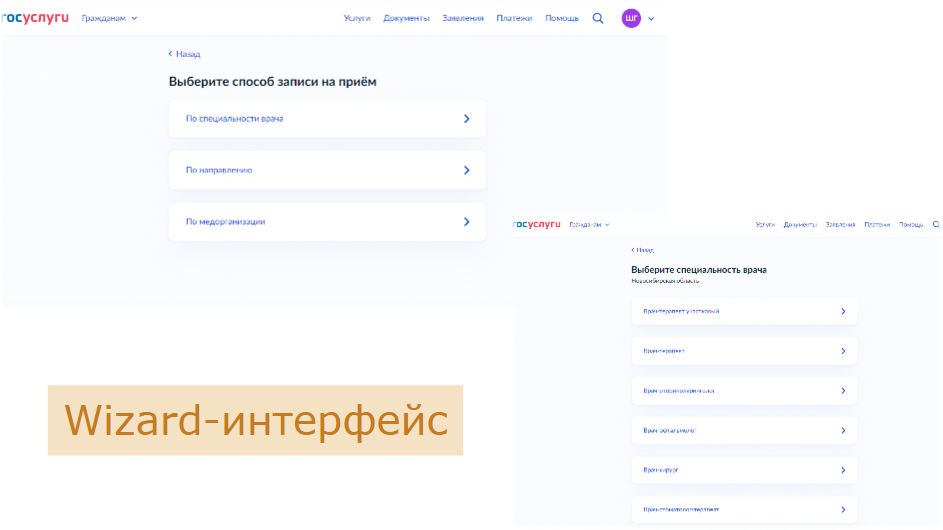
Например, на Госуслугах указана Новосибирская область. Я зашел – система знает, откуда я, и соответственно предлагает запись к врачу только внутри этой области. После выполнения всех шагов, в конце, необходимо показать пользователю сводку всех выбранных действий и конечный результат.
На каждом шаге он что-то выбирал, создавал. Мы показываем ему финальную форму с результатом, и ему остается только подтвердить: правильно/неправильно, либо вернуться и пошагово изменить действия, выполненные неверно.
Система, которую я показал (не случайно взятая с Госуслуг), несмотря на множество мемов, демонстрирует максимальную заботу о пользователях. Думаю, все с ней сталкивались. Эта система – одна из самых высоконагруженных профессиональных систем, используемая абсолютно непрофессиональными пользователями.
Посмотрите, изучите, как создаются подобные интерфейсы, и попробуйте это применить – ваши пользователи скажут вам спасибо.
Подход 8: 1С как внутренний бэкенд
Хочу поделиться одной парадигмой, которая кардинально изменила мой взгляд на разработку.
Все привыкли использовать 1С как бэкенд для внешних систем. Но когда вы поймете, что 1С является полноценным бэкендом внутри самой себя, вы сможете писать списки и запросы еще более оптимально.
Мы должны переходить от работы с объектом самой формы к API-подобным интерфейсам, обеспечивающим пошаговый вывод информации. Если для нашей формы требуется получить три поля из нашего бэкенда (из самой 1С), мы отдаeм только эти три поля. Если нужно получить чуть больше данных – отдаeм только «чуть больше». Если требуется какая-то конкретная выборка, отдаем только еe, а не всe сразу.
Очень часто бывает, что отдают сразу весь объект, весь документ, хотя это не требуется. Тем самым мы увеличиваем объем передаваемых данных, усложняем запросы, а также рискуем допустить дополнительные ошибки даже при интеграциях внутри самой 1С.
Эти дополнительные сложные запросы нам не нужны. Мы должны отдавать максимально простую и минимальную порцию данных, которую требует сам интерфейс, а значит, и сам пользователь.
Буду рад, если при построении всех наших систем, при архитектуре и проектировании этих систем, у вас будет мысль: 1С – это бэкенд абсолютно для всех, и даже для самой себя.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт