В этой статье я хотела бы на примере кейсов отразить две самые главные темы любого проекта. Это, во-первых, продумывание функциональной модели учета, выстраиваемого в ERP, с заделом на будущее – учитывая то, что производство заказчика будет расти, объем базы тоже будет расти.
И вторая немаловажная тема – как найти баланс между сохранением типового функционала, поведением типового функционала, доработками ERP по требованию заказчика и при этом не пожертвовать производительностью и удобством работы пользователей.
Кейс 1: Оптимизация доработки при работе с большими объемами данных
Первый кейс относится к теме баланса между гибкостью и производительностью. Он касается непосредственно нашей доработки. Заказчику нужно было заполнять достаточно крупные заказы поставщику на основании разузлованных спецификаций по готовой продукции. И у нас эти заказы выросли в ряде случаев до 90 тысяч строк и более. Такая разузловка производилась крайне медленно, порядка часа. Конечно, заказчика это не устраивало.
Мы начали анализировать, почему наша доработка так долго работает. И выяснили, что мы попытались излишне сохранить гибкость в этой обработке: сохранили обращение к типовому пути ценообразования, расчета НДС. Как только мы это убрали, время обработки на документе 90 тысяч строк и более сократилось с часа практически до 40 секунд.
Кейс 2: Оптимизация расчета себестоимости в ERP на PostgreSQL
Рассмотрим кейс сокращения времени расчета себестоимости в 1С, которая развернута на PostgreSQL. Им я хочу подтвердить основной тезис моей статьи – производительность 1С:ERP зависит не только от технического обеспечения, но и от выбора реализации методологии учета в этом продукте.
Здесь есть определенные тонкости, без которых время расчета переваливает далеко за сутки. Разумеется, ни один заказчик такого расчета ждать не захочет.
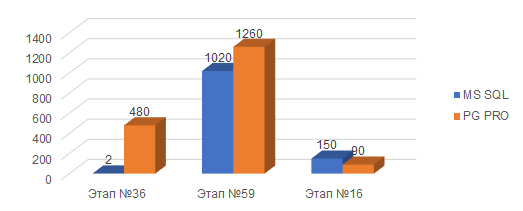
Этап №36. Подготовка данных для решения СЛУ. Дополнительные Расходы
Этап №59. Подготовка данных для решения СЛУ. Постатейные Расходы
Этап №16. Заполнение партий в регистре себестоимость товаров
На этом графике представлена картина нашей первой части работ по оптимизации расчета себестоимости.
С этой задачей мы столкнулись в конце 2023 года. На графике вы видите ТОП-3 на тот момент самых долгих этапов расчета, а также их сравнение по длительности в минутах в двух базах:
-
Одна из которых развернута на Microsoft SQL,
-
Другая на Postgre Pro (на тот момент 14-й версии).
Как видите, Postgre уступает очень сильно.
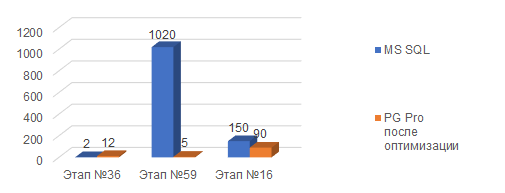
Этап №36. Подготовка данных для решения СЛУ. Дополнительные Расходы
Этап №59. Подготовка данных для решения СЛУ. Постатейные Расходы
Этап №16. Заполнение партий в регистре себестоимость товаров
А на этом графике вы видите результат нашей оптимизации в сравнении с той же самой базой, развернутой на Microsoft SQL.
По сути, вся работа по оптимизации сводилась к анализу технологического журнала, вылавливанию наиболее долгих запросов и их оптимизации, переписыванию в самой ERP. Что конкретно мы делали и с какой целью, я поясню далее.
По итогам оптимизации расчета для Postgre у нас было получено приемлемое для заказчика время закрытия, время расчета себестоимости. На тот момент мы остановили работы по оптимизации, а вернулись к ним через год.
Анализ роста объема данных и повторная оптимизация
Через год у нас была вот такая картина:
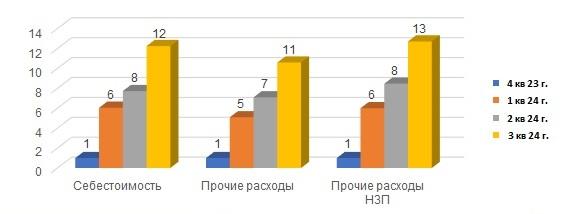
У заказчика скачкообразно вырос объем выпуска. В результате в базе ERP в 12 раз выросло количество записей в регистре себестоимости, в 11 раз – количество записей в прочих расходах и в 13 раз – в прочих расходах НЗП. Но теперь у нас самые длительные этапы расчета – это не распределение постатейки, как раньше. Появилась проблема с заполнением партий, а в этот этап входят именно записи регистра себестоимости: чем он больше, тем дольше будет длиться расчет этого этапа.
Конечно, мы пытаемся повторить старую схему оптимизации, идем в техжурнал, смотрим запросы, находим всего лишь два явно деградировавших запроса, их оптимизируем, значительного прироста не получаем.
Также из перечня работ, которые были выполнены – проверка настроек виртуализации и выделение отдельного физического сервера под СУБД. Но все равно на требуемое время расчета мы не выходим.
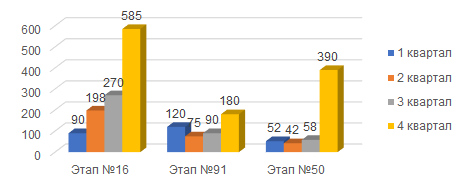
Этап №16. Заполнение партий В регистре себестоимость товаров
Этап №91. Записать сформированные движения
Этап №50. Распределить доли производственных расходов
Сравнение с временем выполнения данных самых длительных этапов с данными предыдущего года отображены на диаграмме выше. Мы видим, что расчет этапа заполнения партии в регистре себестоимости вырос более чем в 5 раз. Именно его мы пытаемся оптимизировать.
Технические аспекты оптимизации запросов в ERP
Теперь переходим к тому, что именно в запросах в расчете себестоимости мы пытаемся оптимизировать.
Во-первых, мы явно видим, что ломается статистика в Postgre и планировщик не может адекватно построить план запроса. Отлавливаем те самые долгие запросы, вычленяем их контекст, переносим подзапросы во временные таблицы и обязательно делаем индексы не только по полям связи, но и по полям, по которым будет идти группировка, и по полям, где далее идет выборка и объединение в запросах с операцией «Объединить все» и «Объединить».
Потому что нам критично получить в плане запроса не только Hash Join на соединениях – на больших объемах критично избавиться от операций Group Aggregate и Sort. Именно они на больших объемах крайне непроизводительны. Лучше, чтобы планировщик выбрал Hash Aggregate, именно для этого нам нужны индексы на этих полях.
Запросы оптимизировали, но нужного времени мы не получили. Значит, копаем дальше.
Поиск решений для сокращения объема записей в регистре себестоимости
Исходя из того, что у нас выросли не только записи в регистре себестоимости, но и записи в прочих расходах, мы делаем вывод, что стоит сравнить время выполнения этапов распределения постатейных затрат и заполнение партии.
Распределение постатейных затрат выросло некритично, там даже до 30 минут не доходит. А вот заполнение партии выросло в разы и измеряется часами, если не десятками часов. Значит, нам нужно каким-то образом сократить количество записей в регистре себестоимости. И, внимание, при этом нам надо не поломать тот учет, который уже выстроен у заказчика, перечень аналитик, который уже получал заказчик на протяжении года. Нам не хотелось бы резать переделы, не хотелось бы их сокращать и не хотелось бы сокращать перечень аналитик, по которому мы получаем данные.
Возможные решения, посредством которых мы можем сократить количество записей в регистре себестоимости, представлены в таблице:

Нами было выбрано два решения. В приоритете последнее – конвертация материальных затрат в постатейные.
Реализация и результаты выбранных решений по оптимизации
Мы смоделировали отражение расходов материалов на статью с аналитикой «Партия выпуска». Соответственно, избавились из документа «Передача материала в производство». При условии, что производство позаказное, оно отражается этапом производства. Материалы отражаются не в самом этапе, а в документе списания внутреннего потребления на статью с указанной аналитикой. То есть в регистре себестоимости количество записей значительно сокращается, постатейка распределяется быстро.
В итоге прирост в расчете себестоимости у нас составил более 50%. Это предварительные данные по проведенному нами моделированию.
Следующий способ, который был нами применен – это сворачивание перемещений товаров в рамках каждой пары склад-источник и склад-приемник в рамках одного дня.
Поскольку эти документы приходят из оперативного контура каждые 2-3-5 минут, у нас их просто бешеное количество в базе. При сверке этих документов мы получаем сокращение количества документов практически в 20 раз, также уменьшается количество записей в регистре себестоимости.
Мы отдельно промоделировали использование данного способа уменьшения количества записей на отдельной базе, и именно он дал прирост скорости этапа заполнения партии в расчете себестоимости на 30%.
Проблемы блокировок при интеграции кастомизаций в типовой функционал
Следующий момент очень узкий. Мы на каждой кастомизации пытаемся подстроиться под типовой функционал, это снижает стоимость внедрения. Даже если дело касается кастомизации решения под некую отрасль, мы можем делать свои подсистемы, но все равно придется заводить данные из них далее в типовой функционал. А если слишком часто так или иначе проводиться будут те документы, которые делают движение по складским регистрам и по регистрам, которые отвечают за механизм обеспечения, то от проблем параллельной работы и блокировок никуда не деться. Как раз при большом объеме выпуска и товарооборота, при большой детальности учета возникают конфликты блокировки именно на этих регистрах.
И регистр распределения запасов далеко не единственный, на котором мы поймали конфликт управляемых блокировок.

Конкретно на этом примере очевидно, что не хватает блокировки по полю «Назначение». В случае этого регистра это проблему сняло, но есть еще ряд других регистров, с которыми также пришлось побороться.
Заключение
В статье я хотела только рассказать о нюансах кастомизации, с которыми пришлось столкнуться на конкретном проекте. Надеюсь, она будет полезна и поможет выбрать подход к адаптации типовых решений на разных предприятиях. А возможно, подсветит пути решения проблем, которые уже возникли на тех или иных базах.

Комплексное внедрение 1С:ERP
Помогаем бизнесу сокращать издержки и ускорять производственные процессы
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт