Хочу презентовать фреймворк собственной разработки, открытый и свободно распространяемый, который реализован на технологиях REST, JSON и использует функционал исключительно платформы 1С. Данный фреймворк мы используем практически во всех интеграциях, где это технически возможно. Также расскажу о технических, архитектурных и методических подходах, которые мы используем, и которые могут быть вам полезны при решении задач интеграции. При этом я ограничусь исключительно обменами между системами 1С и вопросами, которые возникают скорее у небольших IT команд.
Анализ существующих решений на рынке
Если посмотреть описания существующих распространенных решений для интеграции, то можно увидеть, что основной упор делается на сугубо технические вопросы – транспорт сообщений, гарантии доставки, мониторинг, централизованное администрирование.
Но интеграция – это не про передачу каких-то данных из системы А в Б, мы с помощью интеграции решаем какие-то задачи бизнеса, обеспечиваем какой-то функционал.
На самом деле такая ситуация имеет объяснение: у крупных ИТ-команд, интеграторов, крупного консалтинга выделены инженеры на интеграцию. Они полностью обеспечивают уровень транспорта данных между системами, и именно на них интеграционные решения и ориентируются.
Но мир 1С не ограничивается такими командами. Большая часть мира 1С – это команды из десяти, пяти, иногда даже из одного человека, который в одно лицо выполняет и поддержку существующих решений, и их развитие, внедрение новых решений. Читая эти описания, он не понимает, как данные решения упростят выполнение задач, которые перед ним ставятся.
Интегрируемые системы обеспечивают для заказчика некую бизнес-логику, и вопрос интеграции – это интеграция этой бизнес-логики в единый бизнес-процесс.
История создания фреймворка
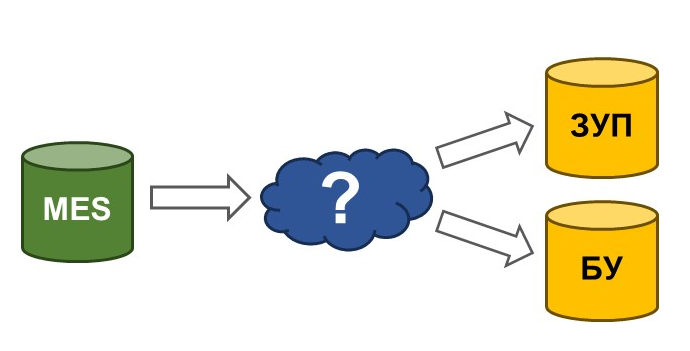
Все началось с того, что у нас был проект по внедрению системы производственного управления MES и, в частности, была задача по интеграции MES с ЗУП и Бухгалтерским учетом. Нужно было передавать, что мы выпустили, и кто сколько сделал.
Встал вопрос, чем интегрироваться. Этот проект был примерно семь лет назад. Посмотрев, что мы раньше использовали, что есть на рынке, я увидел очень много минусов: где-то по срокам, где-то по надежности. И мы решили попробовать реализовать обмен через HTTP-сервис, который в тот момент уже предоставлялся платформой.
В итоге на примере с интеграцией ЗУП у нас получилось очень простое и эффективное решение.
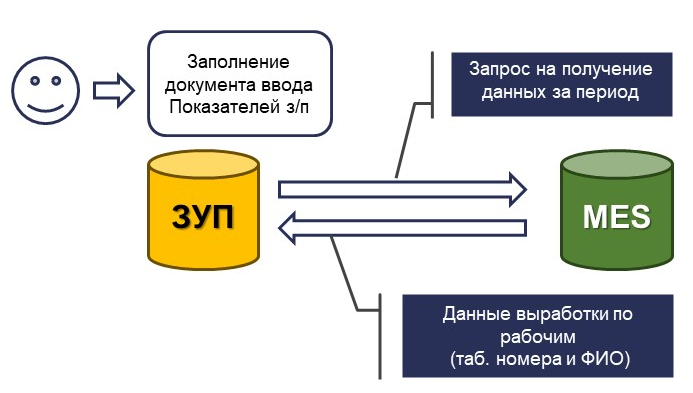
Пользователь, заходя в типовой документ ввода показателей заработной платы и указывая, за какой период и с каких подразделений и сотрудников нужно собрать данные, нажимал кнопку «Заполнить». Система отправляла HTTP-запрос в систему MES, которая возвращала результат – данные по сотрудникам в виде табельного номера и ФИО. При этом интеграция справочников не требовалась.
Пользователь, во-первых, выполняет обмен тогда, когда ему нужно, а не по какому-то условному регламенту – он нажимает кнопку, что вызывает обмен. Во-вторых, он сразу видит, если происходят какие-то ошибки, и может контролировать полученный результат. Например, если у нас табельный номер не сошелся с ФИО – система выдает ошибку, пользователь понимает, почему обмен не работает и может сам эту ошибку обработать тем или иным образом, не звоня в службу поддержки 1С.
В результате обмен показал себя настолько быстрым, удобным, эффективным, что мы такие подходы и в целом HTTP-сервисы начали пытаться применять в остальных проектах, что в итоге привело нас к реализации своего фреймворка.
Ключевой тезис, который я хотел отметить: интеграция должна быть простой, надежной и интуитивно понятной как для разработчика, так и для пользователя.
Концепт фреймворка
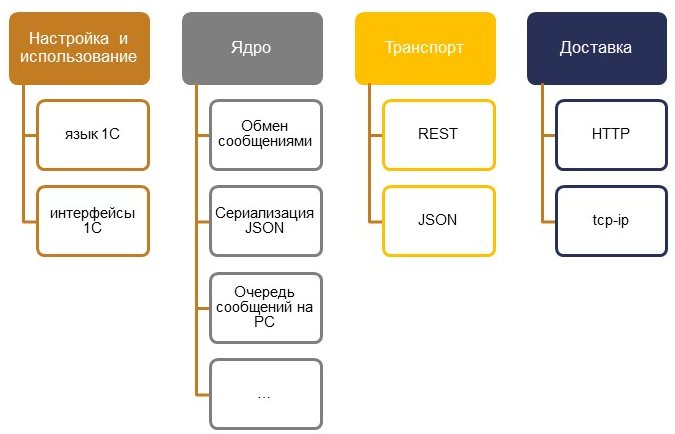
Уровень транспорта и доставки, гарантии доставки у нас обеспечивают уже реализованные технологии – это REST и HTTP. Они в нашей практике оказываются более чем достаточными. Ядро решения обеспечивает непосредственно обмен сообщениями, сериализацию с JSON и множество другого функционала. Настройки под конкретную интеграцию выполняются в программном коде на языке 1С. Настройка в виде программного кода дает множество плюсов, начиная с того, что мы говорим про интеграцию бизнес-логики, которую в системе обеспечивает разработчик через ее реализацию в программном коде.
Методические и технические решения
Во-первых, хотелось бы отметить важность онлайн-обмена данными. Все изменения, происходящие в одной базе, которые необходимо передать в другие системы, должны транслироваться в режиме реального времени. Это:
-
Повышает прозрачность для пользователя и службы поддержки.
-
Исключает необходимость регламентации процесса обмена данными. Пользователь не должен задумываться, что обмен должен произойти ночью или раз в полчаса, и надо подождать.
-
Упрощает взаимодействие между пользователями в разных системах.
-
Исключает проблемы коллизий.
-
Повышает ощущение надежности интеграции у пользователей.
Разные подходы к интеграции
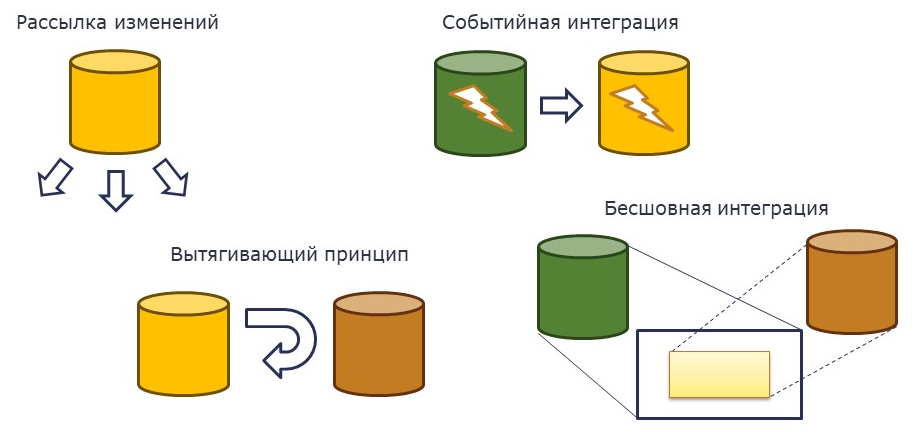
Классический подход – это рассылка изменений. Это то, что знают все: изменения происходят в одной системе, мы их рассылаем в интегрированные.
Вытягивающий принцип. Его демонстрирует пример MES, который я привел ранее, когда пользователь сам запрашивает необходимые ему данные нажатием условной кнопки.
Событийная интеграция. Событийной интеграцией обычно называют то, что я называю онлайн-обменом: когда при записи данных все рассылается в остальные системы. С моей точки зрения, событийная интеграция – это не рассылка данных, а отправка информации о произошедшем событии. Допустим, закрывается период бухгалтерского учета, информация об этом событии передается в систему, например, экономического анализа, которая уже может с этой информацией что-то делать. Или изменили какие-то данные в закрытом периоде – об этом также оповещаются нужные системы.
Но самое интересное – бесшовная интеграция. Это интеграция, при которой мы можем реализовывать какие-то алгоритмы и интерфейсы в системе A, используя данные проинтегрированных систем B, C и т.д.
Ключевое преимущество бесшовной интеграции
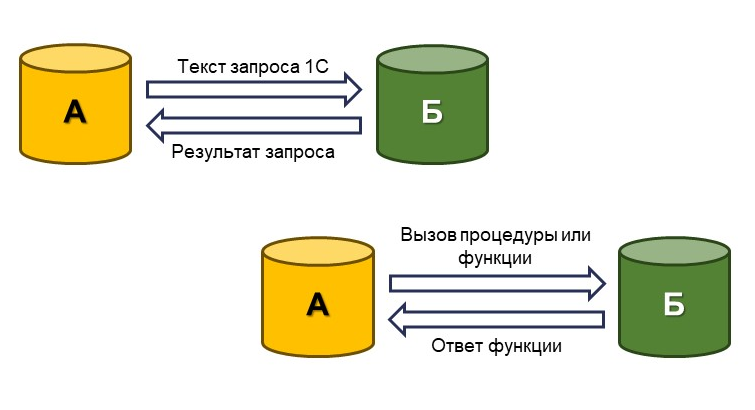
Допустим, разработчик в рамках реализации определенного алгоритма или процесса указывает, какие данные ему нужно получить из системы Б, работая при этом в системе А. Для этого он может сформировать запрос на языке 1С, отправить его в систему Б и затем обработать полученный результат. Либо это может быть не запрос к данным, а вызов процедур и функций, находящихся в системе Б. Таким образом формируется единый непрерывный бизнес-процесс между системой А и системой Б.
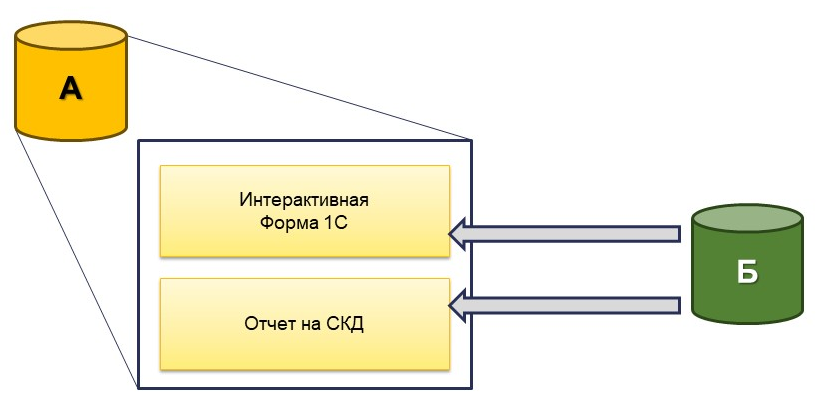
Также в рамках бесшовной интеграции мы часто применяем следующий способ: в системе А реализовываем пользовательские формы, которые используют данные системы Б, не перенося эти данные в систему А. Например, пользователь основное свое рабочее время работает в системе А, но иногда, ему нужно редактировать и отслеживать какой-то классификатор в системе Б. Мы можем сделать этот классификатор в метаданных в системе А и синхронизировать эти данные. Но если эти данные для системы Б не нужны, то можно просто сделать форму 1С, в которой пользователь сможет эти данные просматривать и редактировать, не перенося их из системы А.
Также мы можем поступить с отчетами, данные для которых необходимо получать из других систем. Мы реализовываем отчет на СКД с полноценным функционалом по отбору, сортировке, расшифровке, но при этом на данных, которые могут отсутствовать в системе А. Причем этот отчет может использовать данные системы Б, а может одновременно и Б, и C, то есть нескольких систем одновременно. Это дает огромные возможности.
Регистрация изменений и очередь обмена
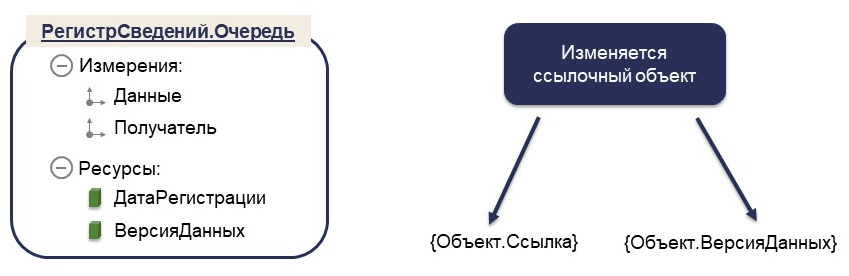
Регистрация изменений у нас реализована через регистр сведений, в котором мы храним сведения о том, какие данные изменились. Измерения в регистре – Данные и Получатель.
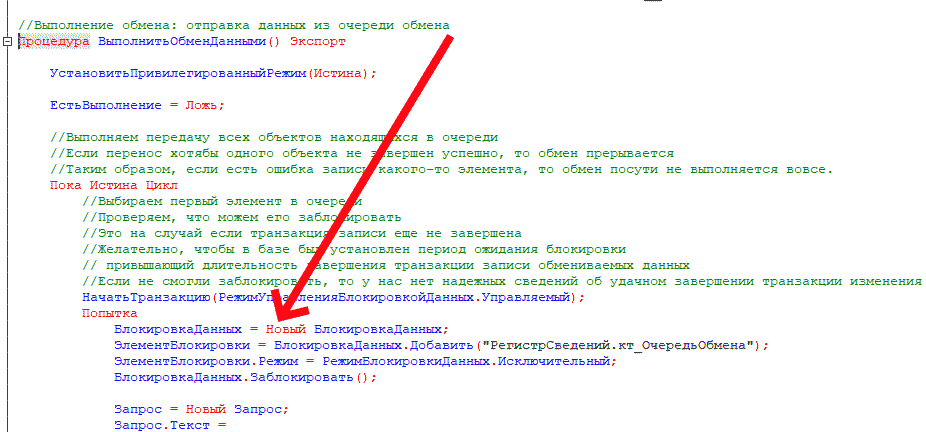
Данные – это всегда ссылка на объект системы. Мы в общем случае не храним само сообщение. Во-первых, это зачастую избыточно в большинстве подходов интеграции. Во-вторых, это позволяет быстрее записывать в регистр за счет того, что в процессе записи, которая должна происходить внутри транзакции, мы не формируем сам текст сообщения, а этот процесс может занимать достаточно длительное время. Мы храним просто ссылку об измененном объекте.
Дата регистрации позволяет нам упорядочить очередь. В нашем случае это универсальная дата в миллисекундах. Да, не очень надежный способ для очереди, но в нашей практике достаточный.
ВерсияДанных соответствует значению одноименного атрибута любого объекта 1С.
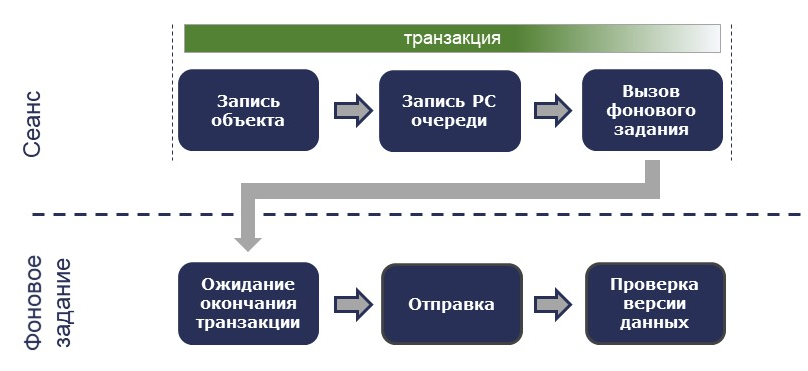
В момент записи объекта внутри транзакции данные заносятся в очередь, после чего сразу запускается фоновое задание на отправку сообщения. Фоновое задание дожидается завершения транзакции и затем выполняет отправку.
Отправка может занимать значительное время. Например, при передаче данных в ERP – когда речь идет о документе Реализация товаров и услуг на пару сотен строк – обработка проведения может длиться 2 минуты и более. За это время данные в исходной системе могут измениться, причем не один раз. Поэтому по завершении отправки система сверяет версии данных. Если отправленная версия совпадает с актуальной в регистре сведений – все в порядке. Если же нет, требуется повторная отправка объекта.
Работа с наборами данных и технический справочник
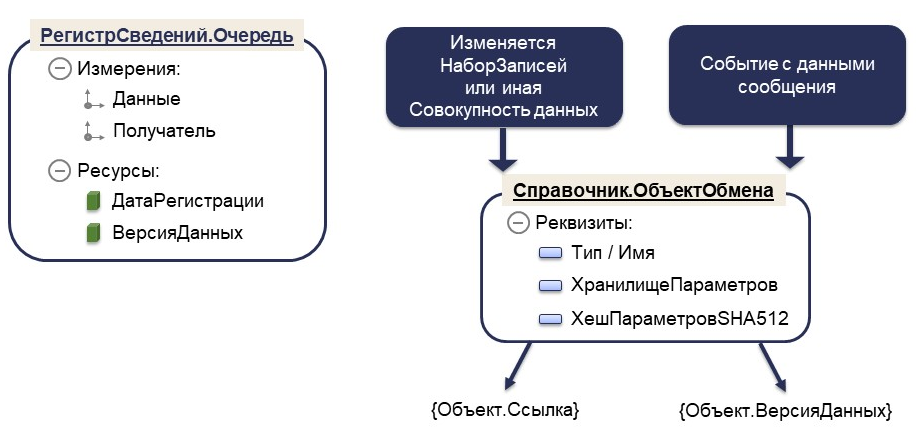
Наборы записей у нас регистрируются через специальный технический справочник ОбъектОбмена, в котором хранятся данные. В нем мы сохраняем значения измерений только для тех записей, которые были изменены.
Например, в регистре курса валют «валюта» и «период» определяют конкретную запись. Мы формируем справочник, передавая в него валюту и период, а затем создаем хэш этих параметров. Это позволяет не создавать каждый раз новый элемент справочника и точно понимать, какая запись была изменена. Этот справочник затем отправляется в регистр сведений.
В ОбъектОбмена можно хранить не только набор записей, но и совокупность любых данных об их изменениях или сообщения о различных событиях.
Настройка интеграции через конфигуратор 1С
Очень часто в существующих решениях, стремясь к централизации настроек, приходится создавать собственную IDE для разработчиков. С моей точки зрения, это не лучший путь. Разработчик должен заниматься интеграцией наравне с реализацией бизнес-логики и функционала. В случае системы 1С разработчик работает в конфигураторе или в EDT.
Если же мы оставим настройку всех правил обмена и всей бизнес-логики интеграции на уровне конфигуратора, то разработчик получает несколько преимуществ: во-первых, ему не нужно осваивать новые инструменты; во-вторых, у него есть привычные средства отладки и удобные инструменты для групповой работы, тот же Git.
И еще один плюс, который не сразу виден, заключается в том, что мы можем полностью алгоритмизировать формирование правил обмена.
Правила = СтруктураПравилВыгрузки(«Документ»);
Правила.ДопустимыеРеквизиты = «Номер,
|Дата,
|Проведен,
|ПометкаУдаления»
Для Каждого ОбъектМета Из Метаданные.Документы Цикл
Если ОбъектМета.Реквизиты.Найти(«Организация») Тогда
Правила = СтруктураПравилВыгрузки(«Документ.»+ ОбъектМета.Имя);
Правила.РеквизитыКонтроля = «Организация»;
Правила.ВыражениеКонтроля = «кт_ОбменПереопределяемый.ПроверитьОрганизацию(Данные)»;
КонецЕсли;
КонецЦикла;
В приведенном примере описаны полноценные правила обмена: мы выгружаем все документы системы, но только ключевые поля – «Номер», «Дата», «Проведен» и «ПометкаУдаления». Если у документа есть реквизит «Организация», мы выгружаем все данные объекта, при этом контролируя, какая организация указана в документе – то есть документы отправляются не для всех организаций.
Это полный код для отправки, например, всех документов из Бухгалтерии в другую систему. Он простой и понятный для разработчика.
Еще один важный плюс – нет необходимости каждый раз обновлять правила при обновлении типового решения. Если появляются новые виды документов или изменяются существующие, правила обновляются автоматически.
Передача ссылок в JSON: эффективный подход
"Организация": {
"Тип": "Справочник",
"Вид": "Организации",
"УИД": "686a3031-4c98-11e1-ac59-003048668de6",
"ИНН": "31543215",
"Наименование": "ТриО"
}
Очень часто в JSON значение ссылочного типа пытаются передавать так же, как в XML – в виде структуры, которая содержит информацию о том, как искать ссылку на стороне приемника. Например, указывают тип объекта, вид, УИД. Если по УИД объект не найден, то можно искать его по другим признакам, например, по ИНН или наименованию организации.
Мы передаем значения ссылочных типов как строки с определенным префиксом. Префикс #ref указывает, что объект нужно искать в конкретной таблице приемника по УИД, а префикс #refbyname – что поиск следует вести по наименованию. При необходимости можно реализовывать собственные префиксы с логикой конкретной интеграции.
"Организация": "#ref:/Справочник/Организации/686a3031-4c98-11e1-ac59-003048668de6"
или
"Организация": "#refbyname:/Справочник/Организации/ТриО"
или
"Организация": "#Organization:/31543215"
Такой подход имеет несколько преимуществ: во-первых, он упрощает код; во-вторых, значительно сокращает объем передаваемого сообщения; и, наконец, устраняется необходимость постобработки данных после десериализации из JSON, что делает процесс более надежным и быстрым.
Соответствие ссылок между системами
Соответствие ссылок – это ключевая составляющая, особенно когда речь идет о бесшовной интеграции. Рассмотрим пример со справочником контрагентов. Возможно, он выдуманный, но достаточно понятный.
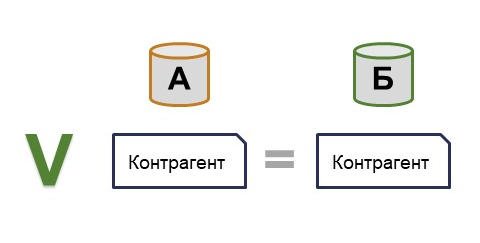
В простейшем случае у нас есть справочник контрагентов как в системе A, так и в системе Б, и один элемент справочника в системе A соответствует одному элементу в системе Б.
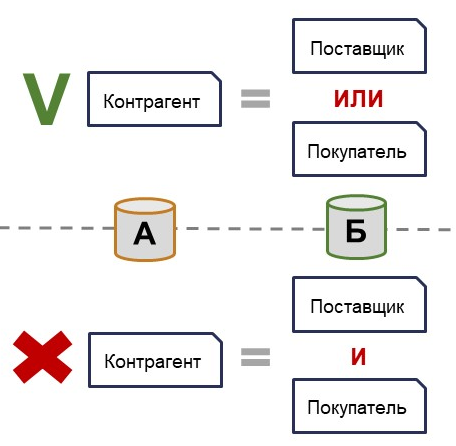
Если в системе Б существуют два справочника, например, «Поставщики» и «Покупатели», и наш контрагент может быть либо поставщиком, либо покупателем, то все просто. Но если контрагент одновременно является и поставщиком, и покупателем, то такая ситуация для обмена данными недопустима.
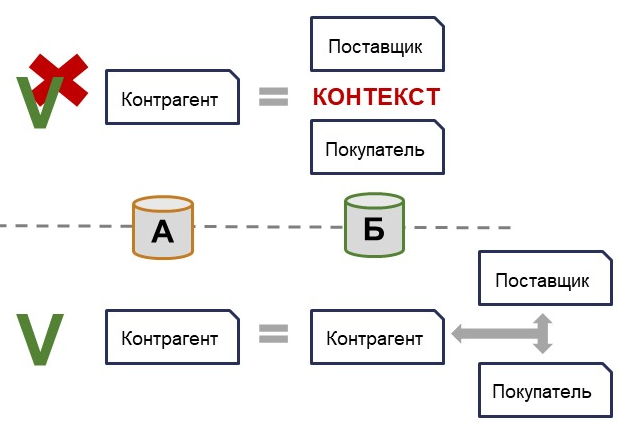
Решить это можно следующим образом: определять, является ли контрагент поставщиком или покупателем, исходя из контекста. Например, при передаче документа о поступлении товаров и услуг контрагент будет поставщиком, а при передаче документа о реализации – покупателем. Для обмена изменениями в данных это вполне подходящее решение, но для бесшовной интеграции оно не совсем подходит, т.к. при работе с данными нескольких систем в одном алгоритме мы не всегда можем определить такой контекст.
Можно реализовать бизнес-логику и архитектуру системы A в системе Б, то есть создать единый справочник контрагентов в системе Б. Пользователи продолжат работать с отдельными справочниками для поставщиков и покупателей, а сам справочник контрагентов будет на техническом уровне. Такой подход эффективен, он упрощает отладку и поддержку интеграции.
Контроль целостности данных при интеграции
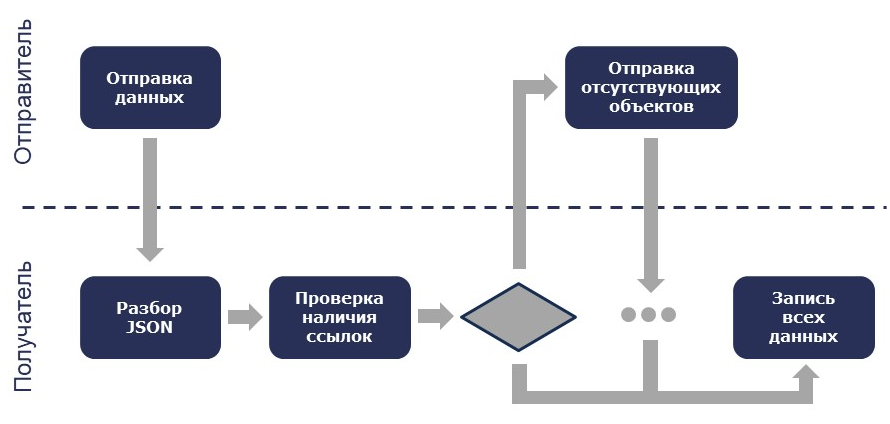
Контроль целостности данных – это важный момент, про который часто забывают в интеграциях. В нашем случае мы решили этот вопрос так: отправитель просто отправляет данные объекта, не задумываясь о том, есть ли все необходимые ссылки у получателя. Мы передаем именно данные объекта, а получатель уже разбирает JSON и проверяет наличие всех нужных ссылок. Если каких-то ссылок не хватает, получатель запрашивает недостающие данные в исходной системе.
После получения всех необходимых данных по связанным ссылкам получатель должен записать их, предпочтительно, в одной транзакции. Мы также не передаем удаление данных, а лишь пометку о необходимости удаления. Реальное удаление может происходить в автоматическом режиме, согласно регламентным заданиям или любым другим механизмам, но с соблюдением контроля целостности.
Описание фреймворка: архитектура и лицензия
-
Фреймворк построен на основе расширений.
-
Полноценно работает с версией 8.3.22, а также может функционировать в режиме совместимости с версии 8.3.10, предоставляя почти 100% функционала.
-
На практике мы пока не пробовали, но теоретически фреймворк должен работать с версии 8.3.6, и даже с версией 8.2.13.
-
Поддерживаются как Обычный, так и Управляемый интерфейсы.
-
Фреймворк распространяется по MIT License, что фактически означает свободное распространение при сохранении авторства.
-
Подходы open-source, в том числе Git, пока не используются, но это возможно в будущем.
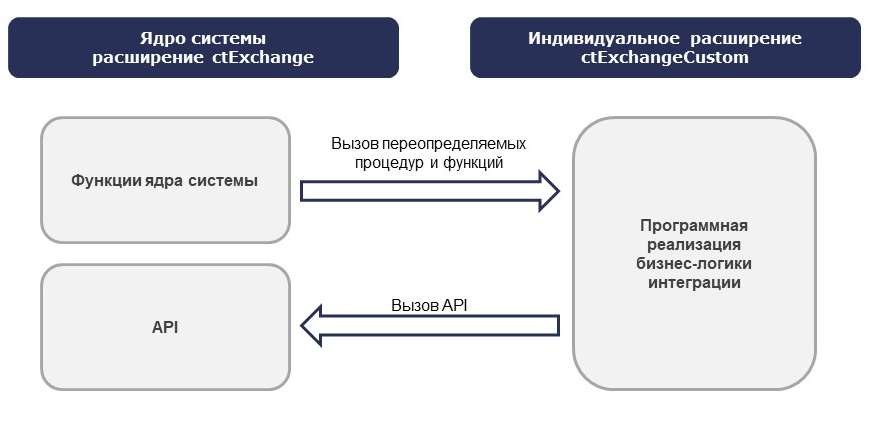
Фреймворк состоит из двух расширений, объединенных в одно ядро системы, и не требует дополнительных доработок. Ядро системы отвечает за весь процесс обмена, обеспечивая техническую сторону. Вся бизнес-логика разрабатывается в индивидуальном расширении ctExchangeCustom, которое реализуется алгоритмически с использованием API ядра системы.
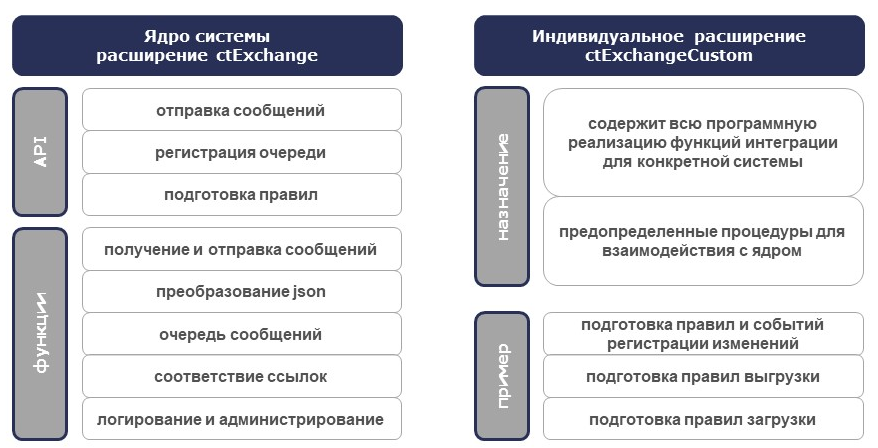
Это означает, что в ядре системы есть инструменты для отправки сообщений, регистрации очередей и подготовки правил. В индивидуальном расширении описываются все правила обмена и алгоритмы подготовки этих правил.
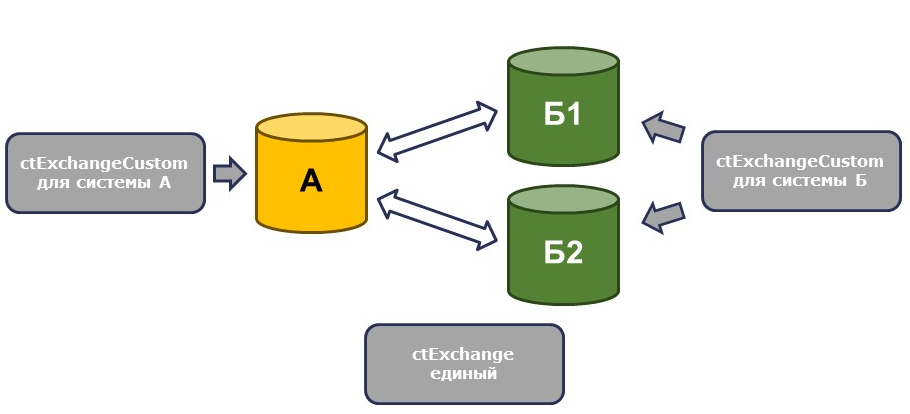
Таким образом, мы можем распространять индивидуальное расширение сразу на несколько информационных баз. Например, при консолидации данных архитектурная логика систем, откуда данные поступают, может быть одинаковой с точки зрения интеграции, даже если технически они отличаются. В таком случае для всех систем будет использоваться одно расширение ядра и индивидуальное расширение для интеграции, например, для консолидированной системы – одно, для всех источников – второе.
Поддерживаемые топологии интеграции
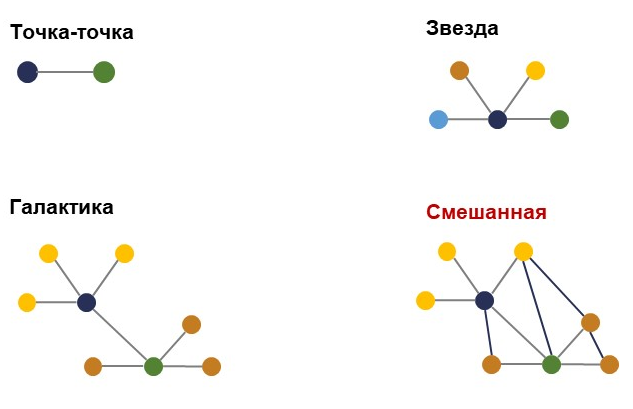
Поддерживаемая топология:
-
«Точка-точка», с которой все начинается,
-
«Звезда»,
-
«Галактика» – объединенные несколько «Звезд»,
-
Смешанная топология, которую часто называют «Спагетти», когда интеграция может быть хаотична. При «Спагетти» не все функции системы полностью поддерживаются, но мы планируем решить этот вопрос.
Процесс запуска фреймворка
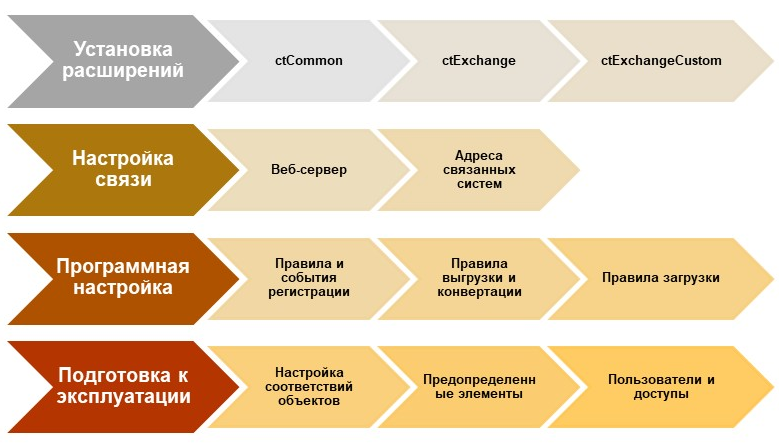
Простой вариант запуска фреймворка:
-
Установка всех необходимых расширений.
-
Настройка связей между интегрированными системами с разверткой веб-сервера.
-
Программная настройка правил и бизнес-логики, правил регистрации, изменений данных, правил выгрузки и конвертации данных, правил загрузки.
-
Подготовка к эксплуатации:
-
настройка соответствия объектов между системами (на примере тех же контрагентов мы сверяем, какие контрагенты в какой системе уже присутствуют),
-
определение, что мы делаем с предопределенными элементами (с этим очень часто возникают вопросы),
-
определение прав доступа.
-
Интерфейсы программирования (API) в фреймворке

Приведу примеры API для отправки сообщений и подготовки правил. Ключевое здесь то, что разработчик, работающий над интеграцией и настройкой правил, не взаимодействует с техническим уровнем системы, например, с принципами передачи ссылок. Он просто указывает, например, что нужно отправить данные конкретного контрагента, вызывает соответствующий API - ОтправитьДанныеПоОбъекту с указанием ссылки на контрагента – и все, вопрос решен.
Кроме того, существует API на стороне клиента, который реализует такие задачи, как, например, интеграция интерфейса.
Пример 1: Централизованное казначейство
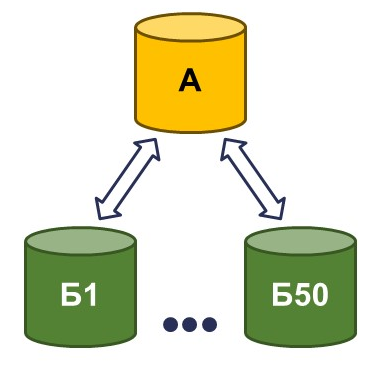
Задача заключалась во внедрении централизованного казначейства с централизацией бухгалтерских данных. У заказчика более 50 юридических лиц, каждое из которых работает в своей базе на основе 1С:Бухгалтерия. Есть отраслевые решения, доработки, различные релизы и версии.
Мы создали центральную систему на базе типовой 1С:Бухгалтерия и интегрировали ее с помощью нашего фреймворка. Внедрение заняло примерно три дня работы одного специалиста. Это решение успешно эксплуатируется уже полтора года.
За весь этот период не потребовалось вносить изменения в правила или бизнес-логику интеграции. Для понимания: за полтора года было множество обновлений, включая обновления в разных базах, разные релизы, отраслевые решения и так далее.
Кроме того, с помощью фреймворка был реализован функционал администрирования, включая рассылку обновлений по казначейскому функционалу, который также реализован на расширениях. В центральной системе мы указываем обновленные расширения, нажимаем кнопку «Разослать», и система через фреймворк автоматически рассылает и устанавливает новые расширения.
По объему данных и скорости работы: каждый месяц формируется порядка 12000 бухгалтерских документов во всех системах. Мы понимаем, что для казначейства онлайн обмен данными критичен. 12000 документов – это не так много, но когда закрывается период и необходимо перепроводить квартальные данные, объем может вырасти до 36000 документов в течении дня.
Пример 2: Производственный заказчик
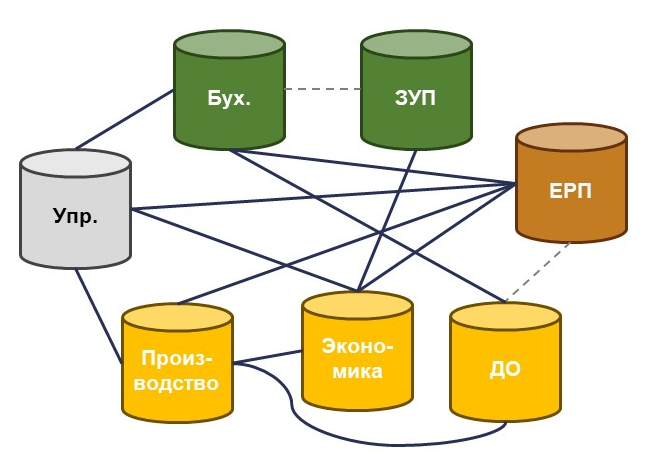
У заказчика несколько разных систем на 1С, но с разными версиями. В их числе, например, управленческая система, основной функционал которой был разработан еще на версии 8.1. С помощью нашего фреймворка была реализована практически вся интеграция. Топология системы напоминает «Спагетти». Фреймворк показывает отличные результаты, особенно в плане поддержки, отладки и стабильности работы.
Планы по развитию фреймворка
-
Описание фреймворка (оно недостаточное, мы будем это исправлять).
-
Развитие инструментов мониторинга и администрирования.
-
Консоль анализа данных, которая позволяет обрабатывать данные сразу нескольких систем в рамках одного запроса. Разработчик работает с ней как с обычной консолью запросов. Это огромное преимущество, которое я не встречал в других решениях. Такой подход удобен не только для разработчиков, но и для аналитиков. Также это упрощает процесс поддержки.
-
Визуализация схемы интеграций.
-
Визуализация правил обмена.

Интеграция 1С без лишних сложностей
Настроим бесшовный обмен данными между 1С и вашими системами
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт