








{kind=link}
- Улучшения, касающиеся сбора статистики
- Улучшения, касающиеся скорости выполнения запросов
- Улучшения, касающиеся временных таблиц
Улучшения, касающиеся сбора статистики
Чем больше база 1С и чем неравномернее в ее таблицах распределение данных, тем больше вероятность, что при default_statistics_target=100 планировщик будет ошибаться в оценке селективности предикатов и кардинальности результатов, и это приведет к выбору неоптимальных планов запросов. Чтобы этого избежать, на больших базах увеличивают точность статистики, но это может снижать производительность работы приложений 1С. Сейчас мы рассмотрим две сопутствующие проблемы и их решение, и закрепим все рассмотрением результатов нагрузочного тестирования.
Ускорение планирования запросов при высоких значениях default_statistics_target
Однажды к нам в «Тантор Лабс» обратился один из клиентов с проблемой неоправданно долгого выполнения простейшего запроса. Запрос и в самом деле был простым, соединение двух таблиц, и из плана этого запроса проблема стала более понятна —неоправданно долго выполнялся сам этап планирования:
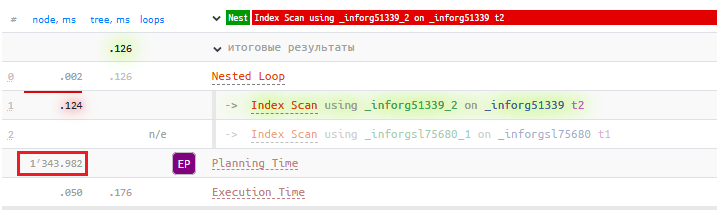
Default_statistics_target был выставлен в 10 000, но если поставить в значение по умолчанию (100), время планирования приходило в норму и составляло не более 1 мс вместо 1343 мс. Мы решили провести на базе 1С:ERP нагрузочное тестирование и собрать некоторую статистику о том, как увеличение default_statistics_target влияет на время выполнения запросов. Получили следующие результаты:
- при значении параметра 1 000 — деградация на 8%;
- при 10 000 —деградация на 75%.
Получается, что если выставить default_statistics_target в максимальное значение, чтобы точность статистики стала высокой, то деградация времени выполнения запросов достигает 75%. Это катастрофическое падение производительности, почему так происходит? Профилирование показало вот что:
- Долгий детоастинг значений из MCV (
most common values— наиболее часто встречающиеся значения); - Долгое сравнение MCV-списков для условий соединения.
Остановимся подробнее на второй проблеме и разберем ее и механизм. Допустим, у нас есть следующий простой запрос:
SELECT *
FROM orders o
JOIN customers c ON o.customer_id = c.id
Планировщик должен оценить, сколько строк вернет этот JOIN, чтобы выбрать оптимальный алгоритм выполнения. Это называется оценкой селективности. Представим, что в таблице orders столбец customer_id имеет MCV: [1, 3, 5, 7...], а в таблице customers столбец id имеет MCV: [1, 2, 5, 8...]. PostgreSQL сравнивает эти списки MCV, чтобы понять:
- Какие значения встречаются в обеих таблицах (пересечение: 1, 5);
- Как часто эти значения встречаются в каждой таблице;
- Сколько строк примерно получится при соединении.
Сравнение списков MCV происходит следующим образом:
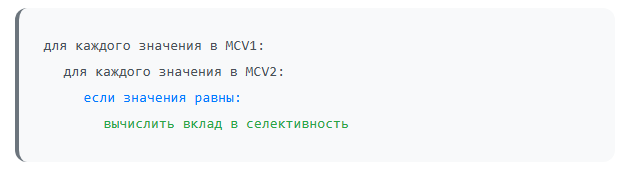
Визуально это можно представить так:

Если значение из MCV1 мы находим в MCV2, цикл прерывается. Если не находим — обходим список MCV2 целиком. Учитывая, что в каждом из списков по 10 тыс. значений, то потенциально может быть 100 млн сравнений, что, конечно же, крайне неоптимально.
Суть оптимизации заключается в том, что если тип данных столбца поддерживает упорядочивание (то есть к нему применимы операторы "меньше" и "больше"), можно применить следующий алгоритм:
- Отсортировать оба списка MCV перед сравнением;
- Применить алгоритм слияния для поиска совпадений.
Визуально это выглядит так:

На данном примере с размером 4 обоих списков MCV количество сравнений уменьшилось у нас с 12 до 6. А на списках MCV с 10 тысячами значений количество сравнений уменьшается с 100 млн примерно до 20 тысяч!
Также помимо тестов 1С мы провели тестирование на JOB-бенчмарке, который подтвердил, что данная проблематика характерна для любой информационной базы, не только на платформе 1С.
Default_statistics_target для временных таблиц
После того, как мы увеличили параметр default_statistics_target, важно понять, какие новые проблемы производительности это может вызвать, особенно в контексте работы платформы 1С с PostgreSQL. Платформа 1С очень любит временные таблицы, давайте рассмотрим их типовой жизненный цикл:
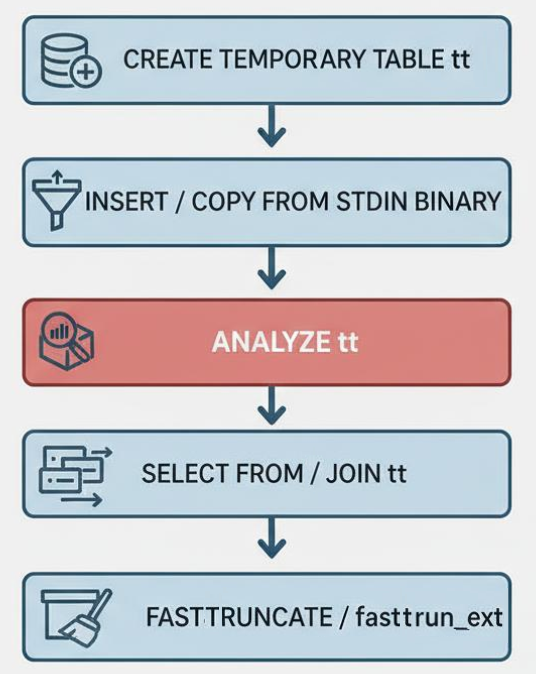
- Создание временной таблицы;
- Наполнение временной таблицы данными. Есть 2 способа заполнения: запросом выборки данных (
INSERT INTO tt SELECT .. FROM) и вставкой из таблицы значений, переданной в запрос в качестве параметра на стороне 1С (COPY FROM STDIN BINARY); - Когда временная таблица будет содержать данные, то перед тем как использовать ее дальше в запросах, необходимо будет рассчитать по ней статистику, чтобы она не являлась для планировщика «черным ящиком»;
- Использование временной таблицы в запросах для различных вычислений;
- Когда временная таблица становится не нужна, она очищается функцией FASTTRUNCATE или
fasttrun_ext(начиная с версии 8.5 платформы 1С). Суть обоих функций одинакова в той части, что происходит очистка временной таблицы (она становится пустой) для того, чтобы платформа 1С в рамках пула временных таблиц могла данную временную таблицу переиспользовать (при переиспользовании жизненный цикл такой же, только нет пункта 1, т.к. временная таблица уже создана).
Почему мы выделили на картинке третий блок красным? Дело в том, что именно здесь кроется принципиальное различие между обычными и временными таблицами:
Обычные таблицы:
- Статистика собирается один раз и используется длительное время;
- Обновление статистики может происходить в фоновом режиме;
- Данные в таких таблицах относительно стабильны между запросами.
Временные таблицы:
- Статистика нужна только в момент выборки из конкретной временной таблицы;
- Сбор статистики должен происходить синхронно и немедленно (она нужна "здесь и сейчас");
- После
fasttruncateпредыдущая статистика становится неактуальной.
Можно сделать вывод, что увеличение default_statistics_target приведет к тому, что запросы с временными таблицами могут начать выполняться медленнее из-за того, что при выполнении запроса также считается статистика по временным таблицам. Для решения этой проблемы мы решили добавить новый параметр default_statistics_target_temp_tables, который в СУБД Tantor Postgres отвечает теперь за точность статистики для временных таблиц. А за обычные таблицы, как и прежде, отвечает default_statistics_target.
Результаты тестирования
Давайте теперь посмотрим, как эти оптимизации позволяют ускорить производительность работы 1С. Измерение проводилось путем проведения нагрузочного теста на базе 1С:ERP размером 650 Гб, количество пользователей — 350, длительность теста — 1 час. Были получены следующие результаты:
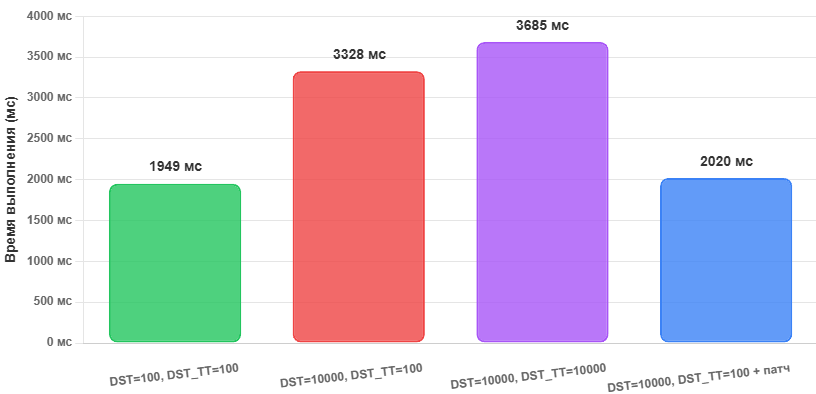
где:
- DST -
default_statistics_target; - DST_TT -
default_statistics_target_temp_tables; - Время выполнения (мс) — среднее время выполнения ключевых операций.
Давайте разберем результаты:
- DST=100, DST_TT=100 — наш эталонный замер, точность статистики установлена по умолчанию (100);
- DST=10000, DST_TT=100 — увеличение
default_statistics_targetдо 10 000 для обычных таблиц приводит к деградации из-за долгого планирования запросов. Производительность падает на 70%. - DST=10000, DST_TT=10000 — увеличение
default_statistics_target_temp_tablesдо 10 000 для временных таблиц еще больше усугубляет результаты, и производительность ухудшается еще на 10%. - DST=10000, DST_TT=100 + патч — применение нашей оптимизации и возможность гибко управлять точностью статистики временных таблиц позволяет достичь результата, аналогичного эталонному времени выполнения ключевых операций.
Улучшения, касающиеся скорости выполнения запросов
Ускорение операторов плана запроса за счет селективности полей условий
В прошлой статье была рассмотрена оптимизация "Ускорение аналитических запросов с агрегацией данных", которая заключалась в изменении порядка сортировки полей исходя из их селективности. Мы взяли эту идею и решили применить ее и для других операторов плана запроса. Допустим, у нас есть 2 таблицы. В таблице ОстаткиТоваров мы храним количественные показатели остатков товара на различных складах:
| Склад | Номенклатура | Серия | Количество |
| Центральный | Кольцо | K000001 | 1 |
| Центральный | Кольцо | K000002 | 1 |
| Центральный | Кольцо | K000003 | 1 |
В таблице СебестоимостьТоваров мы храним рассчитанную при закрытии месяца себестоимость этих товаров:
| Склад | Номенклатура | Серия | Стоимость |
| Центральный | Кольцо | K000001 | 1000 |
| Центральный | Кольцо | K000002 | 1500 |
| Центральный | Кольцо | K000003 | 2000 |
Необходимо соединить эти 2 таблицы по измерениям и получить текущий остаток и себестоимость товаров:
ВЫБРАТЬ
ОстаткиТоваров.Организация КАК Организация,
ОстаткиТоваров.АналитикаУчетаПродукции КАК АналитикаУчетаПродукции,
ОстаткиТоваров.АналитикаУчетаНоменклатуры КАК АналитикаУчетаНоменклатуры,
ОстаткиТоваров.Количество КАК КоличествоОстаток,
СебестоимостьТоваров.Стоимость КАК СтоимостьОстаток
ИЗ
ОстаткиТоваров КАК ОстаткиТоваров
ЛЕВОЕ СОЕДИНЕНИЕ СебестоимостьТоваров КАК СебестоимостьТоваров
ПО (ОстаткиТоваров.Склад = СебестоимостьТоваров.Склад)
И (ОстаткиТоваров.Номенклатура = СебестоимостьТоваров.Номенклатура)
И (ОстаткиТоваров.Серия = СебестоимостьТоваров.Серия)
Для того чтобы выполнить соединение этих двух таблиц, необходимо каждую строку таблицы ОстаткиТоваров сопоставить с каждой строкой таблицы СебестоимостьТоваров. Сравнение строк будет идти в порядке указания предикатов в условиях соединения: сначала сравниваются значения в поле "Склад", затем "Номенклатура" и в конце "Серия". При этом колонки "Склад" и "Номенклатура" содержат одинаковые значения (низкая селективность), а колонка "Серия" — различные (высокая селективность). Получается, что сравнение полей "Склад" и "Номенклатура" будут впустую тратить ресурсы процессора в случаях, когда значения в поле "Серия" не равны, т.к. мы только в конце сравнения понимаем, что строку нужно отфильтровать, если серии не равны.
Суть оптимизации заключается в том, что планировщик при таком сравнении сначала будет сравнивать более селективные поля, т.е. "Серию", чтобы быстрее отфильтровать строку, что, соответственно, позволит ему быстрее выполнить операцию сравнения. Давайте посмотрим, как это работает, на примере из базы 1С:
Если сравним эти планы, мы увидим, что в узле Index scan изменился порядок полей в секции Filter: сравнение происходит в порядке уменьшения селективности полей, что позволяет быстрее выполнять фильтрацию. В данном случае ускорение составляет 15%!

Эта оптимизация будет работать для узлов Index scan, Seq scan, Nested loop.
Оптимизация дизъюнктивных подзапросов
При прохождении нагрузочного теста на 30 тысяч пользователей нам 8000 раз встречался следующий запрос со средней длительностью до 15 секунд (в зависимости от того из какой таблицы шла выборка):

А вот его план:

Из запроса видно, что по одному полю накладывается отбор через условие OR. При этом индекс по этому полю есть, но почему он не используется? Блокирующим фактором является наличие подзапроса. Планировщик мог бы использовать индекс, если бы это было простое условие OR с константами (он бы мог, например, трансформировать их в ANY), но с подзапросом такое сделать нельзя, и пришлось бы постоянно сканировать индекс целиком, поэтому он и выбирает последовательное сканирование.
Давайте упростим тестовый запрос до следующего примера, в котором вышеупомянутая проблематика сохраняется:
ВЫБРАТЬ
ПрочиеРасходы.Регистратор КАК Регистратор
ИЗ
РегистрНакопления.ПрочиеРасходы КАК ПрочиеРасходы
ГДЕ
ПрочиеРасходы.Регистратор В
(ВЫБРАТЬ
Документ.АвансовыйОтчет.Ссылка
ИЗ
Документ.АвансовыйОтчет)
ИЛИ ПрочиеРасходы.Регистратор = &Регистратор
Как оптимизировать такой запрос? Технология тут проста, думаю, что многие с ней сталкивались при оптимизации приложений 1С. Чтобы уйти от конструкции ИЛИ, можно разбить запрос на два и объединить их результаты. В каждом из запросов останется свое условие, которое позволит использовать индекс по полю Регистратор:
ВЫБРАТЬ
ПрочиеРасходы.Регистратор КАК Регистратор
ИЗ
РегистрНакопления.ПрочиеРасходы КАК ПрочиеРасходы
ГДЕ
ПрочиеРасходы.Регистратор = &Регистратор
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
ПрочиеРасходы.Регистратор
ИЗ
РегистрНакопления.ПрочиеРасходы КАК ПрочиеРасходы
ГДЕ
ПрочиеРасходы.Регистратор В
(ВЫБРАТЬ
Документ.АвансовыйОтчет.Ссылка
ИЗ
Документ.АвансовыйОтчет)
И НЕ ПрочиеРасходы.Регистратор = &Регистратор
Когда технология понятна, следующим шагом нужно проверить ее работоспособность. Для этого не понадобилось писать патч для Tantor Postgres, достаточно было вручную переписать проблемный запрос и проверить, что все будет работать. Мы так и сделали, и получили подтверждение, что всё работает, и теперь используется индекс по регистратору. Дополнительное подтверждение правильности нашей идеи нашлось в MS SQL Server и Oracle Database: там была реализована такая же технология, более подробно можно почитать о ней здесь. После этого мы уже реализовали данный механизм и в СУБД Tantor Postgres, и в результате получается следующий план запроса:

Круто ведь, когда запрос ускоряется с 5 секунд до 1 мс?!
Параллелизм VS временные таблицы
В отличие от MS SQL Server, PostgreSQL забывает, что такое параллелизм, если видит в запросе что-то связанное с временными таблицами. При этом, исходя опыта работы с высоконагруженными базами 1С на MS SQL Server, параллелизм позволяет ускорить большое количество запросов, если правильно настроить параметр Cost Threshold for Parallelism. Чтобы в PostgreSQL начать пользоваться преимуществами параллелизма, нужно решить три проблемы:

- Вставка во временную таблицу всегда идет в один поток;
- Если в секции
SELECTнет временных таблиц, но результат такого запроса помещается во временную таблицу, то параллелизм не используется; - Если в секции
SELECTесть временная таблица, параллелизм не может быть использован.
В текущем релизе мы решили вторую проблему и частично третью. Давайте рассмотрим на примерах.
Пример 1. Вставка во временную таблицу.
Простой запрос выборки из регистра накопления выполнялся 6 секунд:

Блокером для использования параллелизма в нем является операция вставки во временную таблицу. В Tantor Postgres этот запрос выполнится втрое быстрее за счет возможности использовать параллелизм:

Пример 2. Использование временной таблицы в секции SELECT.
Здесь помимо вставки во временную таблицу добавляется еще один блокер для использования параллелизма — соединение с временной таблицей. Наш тестовый запрос выполняется 2 секунды:

В Tantor Postgres этот запрос выполнится в 2 раза быстрее за счет возможности использовать параллелизм даже в таком случае:

Здесь, правда, есть пока одно ограничение: параллелизм будет работать только для узлов, в которых нет временных таблиц. Мы продолжаем работать в этом направлении, и в следующих релизах снимем и это ограничение.
Улучшения, касающиеся временных таблиц
Прошедшим летом помимо упомянутого выше нагрузочного теста на 30 тыс. пользователей мы проходили еще один нагрузочный тест, целью которого было найти узкие места СУБД Tantor Postgres при высокоинтенсивной работе пользователей, и он показал нам 2 таких места, связанных с временными таблицами.
Увеличение длины очереди инвалидационных сообщений
PostgreSQL использует механизм инвалидационных сообщений для поддержания консистентности кэшей системного каталога между различными backend-процессами. Когда один процесс изменяет метаданные (например, создает или удаляет таблицу), он отправляет инвалидационные сообщения всем остальным процессам, чтобы они обновили свои кэши. Проблема возникает при повышенной нагрузке DDL-операций с временными таблицами:
-
Очередь инвалидационных сообщений начинает "переполняться";
-
Backend-процессы отстают в обработке сообщений более чем на
MAXNUMMESSAGES; -
Для таких "отстающих" процессов происходит сброс очереди и полная инвалидация кэшей;
-
Это приводит к увеличению ожиданий типа LWLOCK при открытии таблиц системного каталога для наполнения кэшей и значительной деградации производительности.
В Tantor Postgres уже есть оптимизация, которая позволяет не отправлять сообщения, связанные с временными таблицами. Но некоторые сообщения от временных таблиц все-таки приходится отправлять, чтобы не нарушить работу системного каталога. Поэтому в рамках данной оптимизации мы увеличили очередь инвалидационных сообщений с 16384 до 32768.
Несмотря на то, что увеличение размера очереди инвалидационных сообщений решает проблему, у нас также была идея создания "потенциально бесконечной" очереди, но пока отложили этот вариант ввиду последствий отложенной обработки: если позволить накопиться огромному количеству сообщений, то когда для "отстающих" процессов произойдет сброс очереди и полная инвалидация кэшей, это приведет к еще более долгой обработке накопившихся сообщений.
Оптимизация хэш-таблицы статистики
Начиная с 15 версии, в PostgreSQL появилась специальная структура данных (хэш-таблица статистики), которая используется для хранения и быстрого доступа к накопленной статистической информации сервера.
В хэш-таблице статистики хранятся различные виды статистических данных:
-
Статистика по таблицам (количество сканирований, вставок, обновлений, удалений);
-
Статистика по индексам (количество использований индексов);
-
Статистика по функциям (количество вызовов, время выполнения);
-
Статистика по базам данных в целом.
Каждый процесс PostgreSQL собирает статистику локально, а затем обновляет общие данные в этой хэш-таблице. Это позволяет всем процессам иметь доступ к актуальной статистической информации без дорогостоящих межпроцессных коммуникаций.
DDL-команды по временным таблицам также активно пишут в эту хэш-таблицу, создавая избыточную нагрузку на данную структуру, которая в свою очередь приводит к увеличению ожиданий типа LWLOCK и значительной деградации производительности. Но данные из временных таблиц не так важны для этой статистики. Например, Autovacuum не работает на временных таблицах, и платформа 1С сама вызывает расчет статистики на каждой временной таблице после ее наполнения данными. Поэтому мы добавили в Tantor Postgres новый параметр, который позволяет исключить добавление в хэш-таблицу статистики информации по временным таблицам. Помимо решения проблемы ожиданий типа LWLOCK это также снизит конкуренцию за доступ к хэш-таблице статистики.
Другие статьи по данной теме:
СУБД Tantor Postgres 17.5: обзор улучшений для 1С
Александр Симонов
Вступайте в нашу телеграмм-группу Инфостарт