Введение
Недавно обсуждали с коллегой использование условия Where … IN( ..list.. ). Пример запроса 1С ниже, но оператор IN( ..list.. ) может использоваться в любом контексте, необязательно виртуальная таблица остатков. Запрос написан для УТ, без ограничения общности. Поведение запроса зависит от СУБД, есть разные варианты.
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
|Остатки.Номенклатура,
|Остатки.ВНаличииОстаток
|ИЗ
|РегистрНакопления.ТоварыНаСкладах.Остатки(, Номенклатура В (&ВсяНоменклатура)) КАК Остатки";
Запрос.УстановитьПараметр("ВсяНоменклатура", ВсяНоменклатура);
РезультатЗапроса = Запрос.Выполнить();
СУБД MS SQL
В документации написано: Явное включение очень большого количества значений (много тысяч значений, разделенных запятыми) в круглые скобки в предложение IN может привести к интенсивному расходованию ресурсов и возврату ошибки 8623 (out of internal resources) или 8632 (An expression services limit has been reached). Чтобы избежать этой проблемы, храните элементы списка IN в таблице и используйте вложенный запрос SELECT в предложении IN.
Пока искал информацию, вспомнил, что Виктор Богачев что-то рассказывал нам об этом операторе, но нигде не смог найти подробности. Награда ждЁт // того, кто найдЁт! (С)
Посмотрим, как обрабатывается код 1С из примера в технологическом журнале logcfg.xml, события DBMSSQL и SDBL для СУБД MS SQL. Сначала выполним запрос для массива &ВсяНоменклатура 150 элементов, потом сделаем тоже для 100 элементов.
При сравнении событий SDBL видим одинаковые фрагменты Fld7882 IN (***СПИСОК ...***) которые соответствуют фрагменту запроса Номенклатура В (&ВсяНоменклатура). Программа 1С:Предприятие передает запрос в СУБД одинаково для массива 100 элементов и массива 150 элементов.
Однако, при сравнении событий DBMSSQL видим изменения:
Для 100 элементов СУБД использует массив
T2._Fld7882RRef IN (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
Для 150 элементов СУБД использует временную таблицу #tt31.
T2._Fld7882RRef IN (SELECT ... FROM #tt31 ...)
Наконец, вспомнил! Виктор Богачев рассказывал нам, что массивы больше 128 элементов преобразуются во временные таблицы. В событии SDBL используется массив, в событии DBMSSQL используется временная таблица для массива 150 элементов. Версия MS SQL Server 2016.
СУБД PostgreSQL
Посмотрим, как обрабатывается код 1С из примера в технологическом журнале logcfg.xml, события DBPOSTGRS. Размер массива 1500 элементов. Версия СУБД postgresql_13.21_1.1C_x64. Пробуйте на других версиях, мне интересно.
Видно, что СУБД PostgreSQL использует массив T2._Fld37189RRef IN ( ***СПИСОК 1500*** ), использует Nested Loop.
СУБД ORACLE
В документации указано внутреннее ограничение Oracle на максимальное значение в 1000 значений в списке.
Заключение
Мы обсудили, как разные СУБД обрабатывают запрос с оператором IN( ..list.. ). Нужно учитывать, что при большом объеме списка проблемой может стать не только выполнение запроса, не использование в плане запроса индекса, но и передача большого объема данных list на сервер СУБД. Использование подзапроса из индексированной таблицы вместо list выглядит более надежным.
Некоторые крутые вещи, которые мы слышим на вебинарах, приходят к сознательному пониманию гораздо позже )).
Дополнение от 02/10/2025
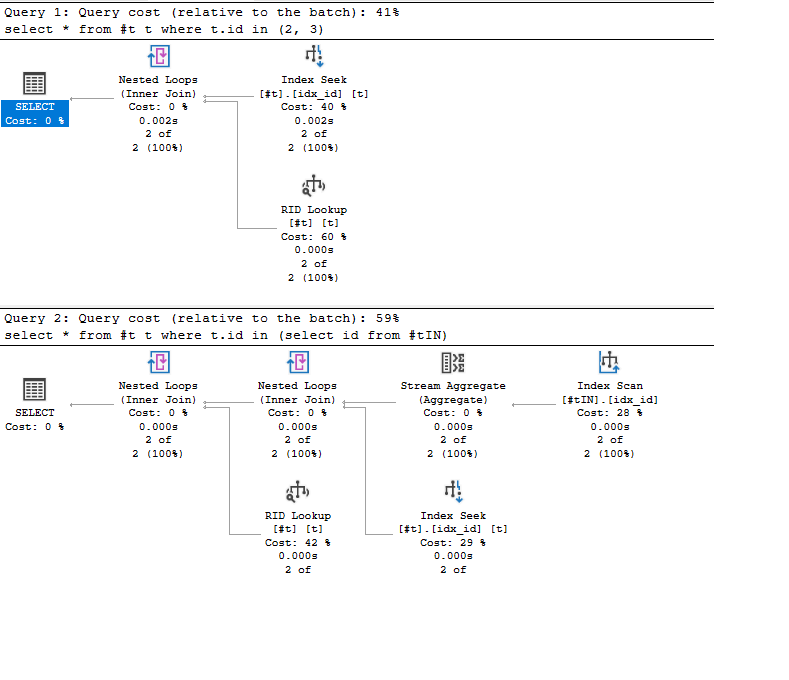
Проверил две гипотезы на примере списка 150 элементов.
(1) Временная таблица #tt1 создана платформой 1С, команда INSERT INTO, метка времени 51:43.656000. Очищена платформой 1С, команда truncate table, метка времени 51:43.719003
(2) Соединение временной таблицы #tt1 (псевдоним T3) с таблицей AccumRgT7888 (псевдоним T2) происходит оператором Nested Loops, без использования индекса. Оператор Stream Aggregate применяется для группировки.
Спасибо всем за толковые комментарии.
Вступайте в нашу телеграмм-группу Инфостарт