Введение
Часто мы ограничены в ресурсах и не можем сделать все и сразу. Поэтому нам требуется выбирать на оптимизацию проблемы, решение которых принесет наибольшую пользу при сопоставимых или минимальных затратах. Чтобы действовать наиболее эффективно - мы должны выбирать ситуации, которые потребляют достаточно много ресурсов или достаточно часто встречаются в процессе работы пользователей. О поиске "частых" запросов мы с вами и поговорим.
В этой статье на реальном примере разберем, как находить такие часто выполняемые запросы, анализировать их и эффективно исправлять.
План статьи
- Поиск цели: Найдем самый частый и суммарно затратный запрос за неделю.
- Анализ проблемы: Поймем, что делает этот запрос таким «дорогим».
- Поиск решений: Определим причину и возможные пути исправления.
- Внедрение: Реализуем наиболее эффективное решение.
- Результаты: Оценим эффект от оптимизации.
Окружение
- Целевая система: ERP 2.5 (размер БД ~ 1,4+ ТБ)
- Инструмент анализа: «Мониторинг производительности 2.0.9» (открытый проект, репозиторий на GitHub)
- СУБД: PostgreSQL 15
- Платформа 1С: 8.3.23
За штурвалом Владимир Крючков, начинаем)
Шаг 1. Ищем проблему для оптимизации
Работа ведется в конфигурации «Мониторинг производительности», где уже собраны и агрегированы данные. Это избавляет нас от рутинной обработки вручную. Для этого используется специальный плагин, про который мы рассказывали в статье - Поиск часто повторяющихся запросов. Мониторинг производительности.
Действия:
- Открываем список событий.
- Устанавливаем отбор по замеру «Частотный анализ - 1C & POSTGRES».
- Выбираем интервал «Неделя» с датой окончания 14.04.2024.
- Для поиска самых ресурсоемких точек смотрим на две ключевые метрики:
- «Количество совпадений»: сколько раз выполнился запрос.
- «Длительность мкс сумма»: общее время, затраченное на все выполнения.
Для приоритизации сортируем данные по убыванию столбца «Длительность мкс сумма». Запрос на вершине этого списка — наш главный кандидат на оптимизацию.
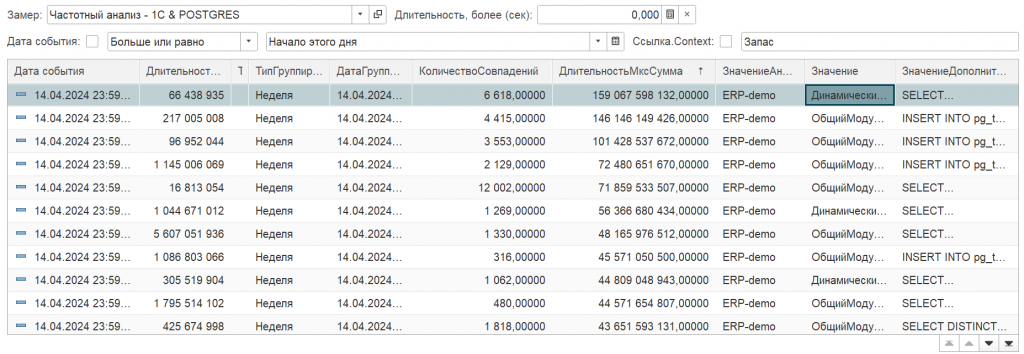
Рис. 1. События замера - Частотный анализ - 1C & POSTGRES
Возьмем первое событие. Откроем контекст и мы увидим, что у нас проблема заключается в динамическом списке - «Входящие ЭД формы текущие дела по ЭДО»:

Рис. Контекст выбранного событиям
Рис. 2. Примерный вид рассматриваемой формы
Шаг 2. Анализ выявленной проблемы
Во многих случаях для понимания причины низкой производительности достаточно изучить текст SQL-запроса, не прибегая к анализу плана выполнения. Именно так мы и поступим.
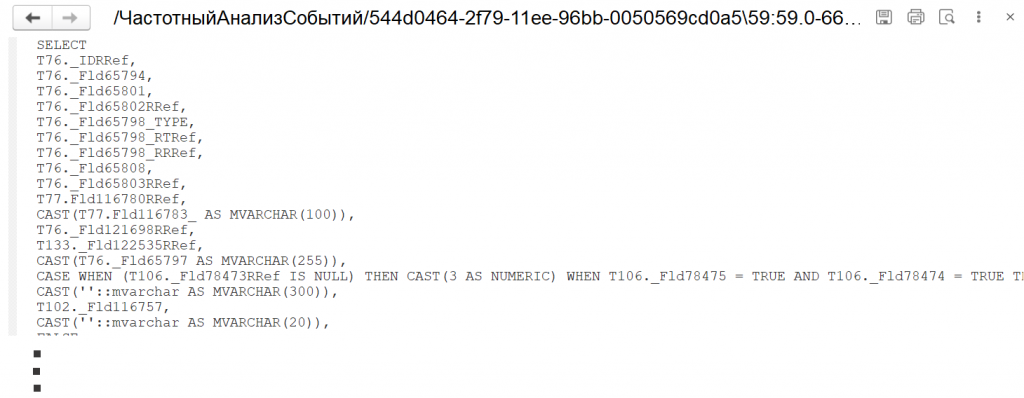
Рис. 3. Исходный текст SQL-запроса
Изучив запрос, мы видим, что не сразу понятна его бизнес-логика — названия таблиц и полей в терминах СУБД неочевидны. Чтобы облегчить анализ, преобразуем запрос в термины метаданных 1С.
Действия:
- Копируем текст SQL-запроса.
- Конвертируем его с помощью специализированного инструмента, который транслирует имена таблиц и полей СУБД в понятные имена объектов 1С.
Результат: После преобразования мы получаем запрос в понятных терминах метаданных 1С, что значительно упрощает дальнейший анализ (см. рис. ниже).
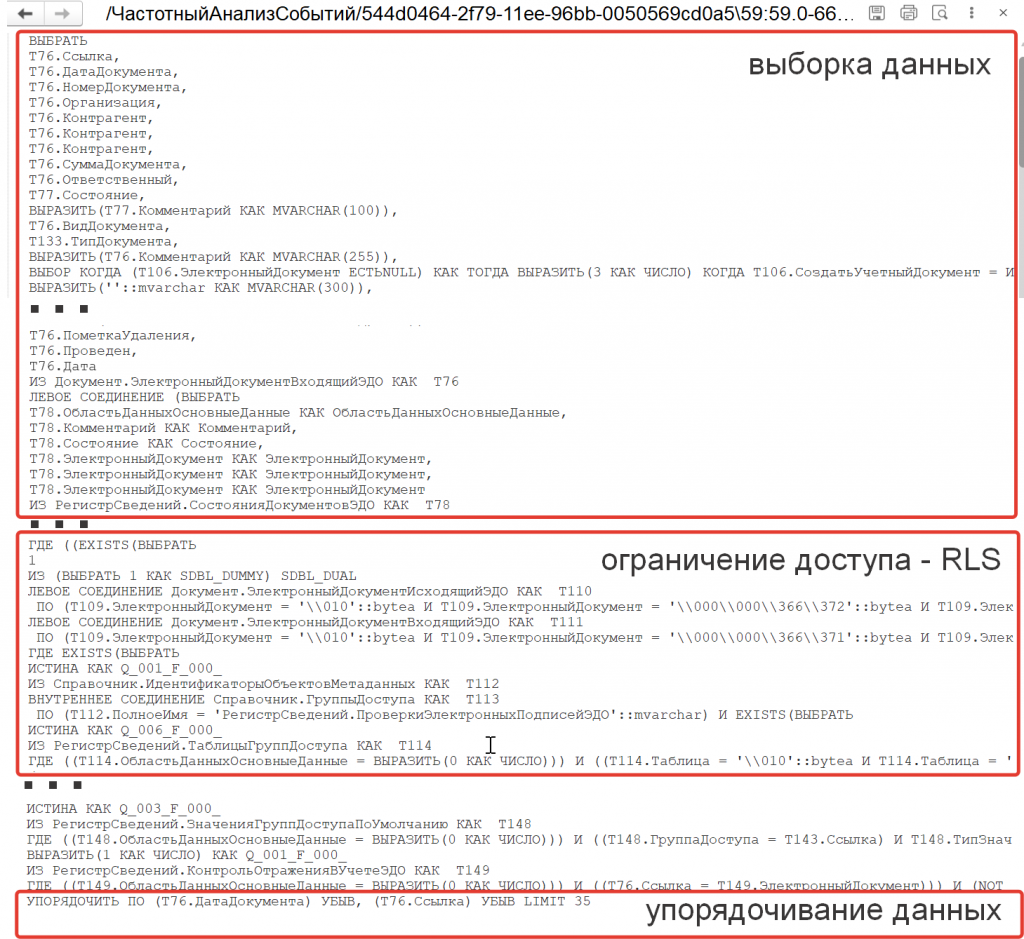
Рис. 4. Текст запроса в терминах метаданных 1С
Даже при беглом анализе текст запроса можно разбить на ключевые функциональные блоки:
- Основная выборка: Данные загружаются из таблицы документа «Электронный документ входящий ЭДО».
- Соединения (JOIN): Ряд присоединений для получения дополнительных связанных сведений.
- Системные ограничения (RLS): Применение ограничений уровня строк, что всегда вносит дополнительную нагрузку.
- Сортировка (ORDER BY): В конце запроса присутствует оператор упорядочивания.
- Фильтрация вывода (LIMIT): В результате выбирается всего 35 записей.
Ключевое наблюдение: Сортировка выполняется по полям «Дата документа» и «Ссылка». Основная проблема с производительностью с высокой вероятностью кроется именно в этой операции.
Далее мы проверим именно эту гипотезу.
Получение плана запроса
Для анализа производительности необходим план выполнения, который строится на основе запроса в языке 1С. Однако получить исходный запрос напрямую из динамического списка программными методами невозможно по двум причинам:
- Запрос динамически формируется в коде и зависит от многочисленных настроек.
- Стандартные функции платформы (ПолучитьИсполняемуюСхемуКомпоновкиДанных, ПолучитьИсполняемыеНастройкиКомпоновкиДанных) не включают в возвращаемый текст оператор ORDER BY, отвечающий за сортировку.
Решение: Мы используем обходной путь, модифицируя уже преобразованный SQL-запрос.
Алгоритм подготовки запроса для анализа плана:
- Берем за основу текст SQL-запроса, ранее сконвертированный в термины метаданных 1С.
- Упрощаем список выборки. Оставляем только ключевые поля (например, Ссылка, ДатаДокумента, НомерДокумента), удаляя все лишние. Для этого вырезаем часть текста от ключевого слова ВЫБОРКА до строки с объявлением основной таблицы Документ.ЭлектронныйДокументВходящийЭДО КАК T76.
- Удаляем блок RLS и нерелевантные соединения. Мы сохраняем только структуру, необходимую для воспроизведения проблемы с сортировкой. Вырезается фрагмент от строки объявления таблицы (...КАК T76) до оператора УПОРЯДОЧИТЬ ПО.
Результат: Мы получаем упрощенный, но репрезентативный запрос, который сохраняет проблемную часть с сортировкой и может быть использован для построения точного плана выполнения.
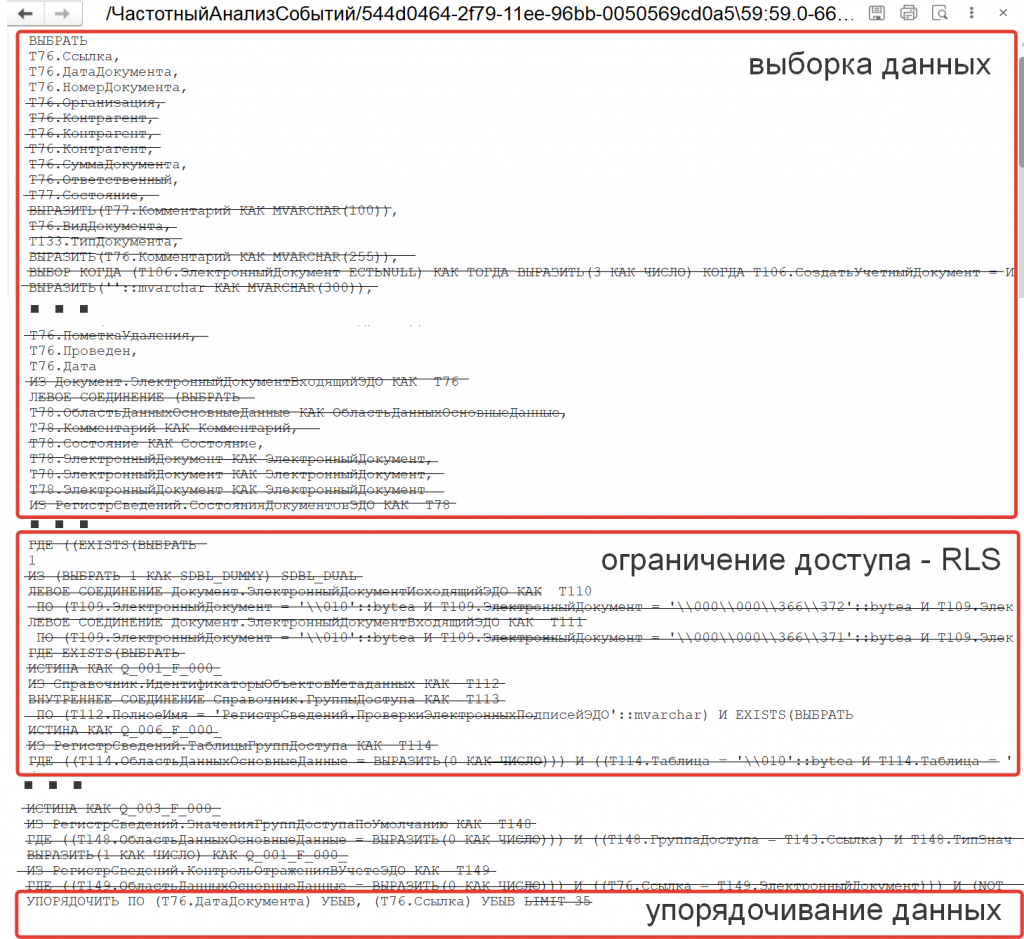
Рис. 5. Удаляем из запроса лишние участки
В результате этого упрощения и небольшой правки вручную мы сможем прийти к следующему тексту запроса на языке 1С:
ВЫБРАТЬ ПЕРВЫЕ 35
T76.Ссылка КАК Ссылка,
T76.ДатаДокумента КАК ДатаДокумента,
T76.НомерДокумента КАК НомерДокумента,
T76.ВидДокумента КАК ВидДокумента,
T76.ПометкаУдаления КАК ПометкаУдаления,
T76.Проведен КАК Проведен,
T76.Дата КАК Дата
ИЗ
Документ.ЭлектронныйДокументВходящийЭДО КАК T76
УПОРЯДОЧИТЬ ПО
T76.ДатаДокумента УБЫВ,
T76.Ссылка УБЫВ
Теперь мы сможем получить план запроса с помощью консоли запросов с ИТС. Можно воспользоваться любой другой, главное, чтобы нам возвращался план запроса.
После выполнения запроса план будет выглядеть следующим образом:

Рис. 6. План запроса в текстовом представлении
Несмотря на относительно быстрое выполнение, запрос содержит фундаментальную проблему в плане выполнения.
Проблема: Для возврата всего 35 строк СУБД вынуждена выполнять последовательное сканирование (Sequential Scan) всей таблицы документа, что отмечено на рисунке ниже красной рамкой (см. рис ниже и выделения красным прямоугольником).
Последствия:
- Такой метод доступа неэффективен, так как требует чтения каждого блока данных таблицы.
- При добавлении ограничений уровня строк (RLS), которые должны применяться к каждой считанной записи, время выполнения возрастет пропорционально размеру таблицы, что приведет к значительной деградации производительности.
Таким образом, операция сортировки, для которой требуется полное сканирование, становится "узким местом" в контексте массовых операций.
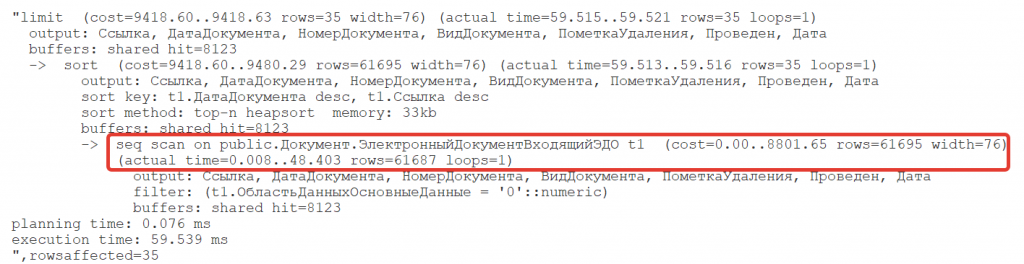
Рис. 7. План запроса - текстовое представление и проблемный участок
Если тяжело разбираться с планом запросов в текстовом формате, то всегда можно преобразовать в графическое представление:
https://explain.tensor.ru/archive/explain/face8f356f354cc0b0751f80b011a9d8:0:2024-04-15#visio
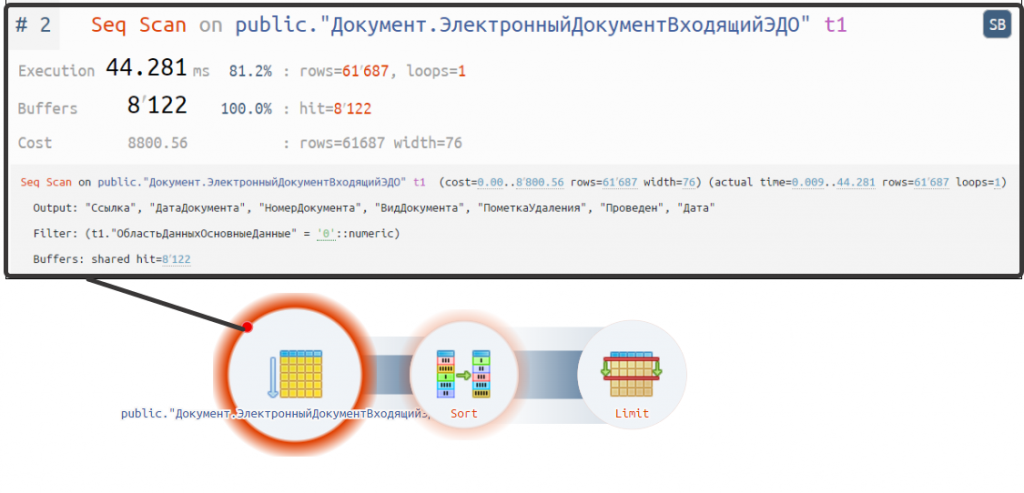
Рис. 8. План запроса в графическом представлении
Прежде чем искать решение, рассмотрим упрощенно, как работает этот запрос и как выполняется сортировка.
Принцип работы сортировки
Разберем, почему операции упорядочивания часто становятся узким местом в производительности.
Пусть у нас есть некоторая таблица с данными строкового типа. Данные в таблице расположены в произвольном порядке. И их требуется отсортировать по алфавиту. Например, “Яма” — может быть сверху, а может и не быть.
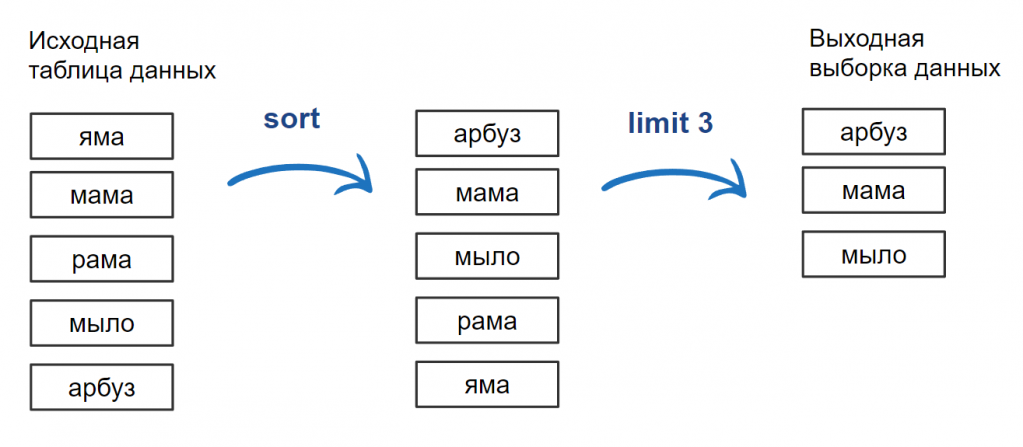
Рис. 9. Исходная таблица с неупорядоченными данными
Упрощенный алгоритм сортировки работает следующим образом:
- Поиск минимального элемента: Выполняется полное сканирование таблицы для нахождения элемента, который должен быть первым согласно порядку сортировки.
- Перенос элемента: Найденная строка переносится в результирующий набор.
- Исключение элемента: Обработанная строка исключается из исходного набора данных.
- Циклическое повторение: Шаги 1-3 повторяются до тех пор, пока все строки не будут перенесены в отсортированном порядке.
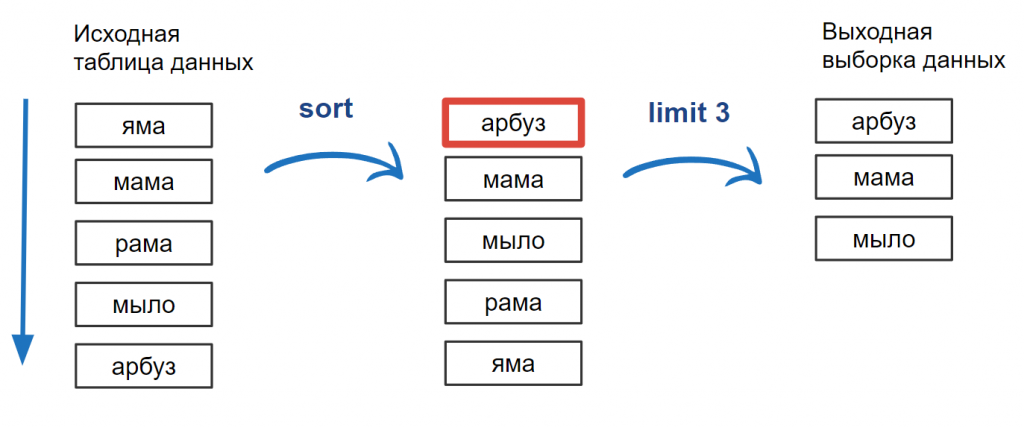
Рис. 10. Визуализация процесса поиска первого элемента
В общем случае вычислительная сложность эффективных алгоритмов сортировки оценивается как
O(n log n), где: n — количество записей в таблице.
Эта операция становится чрезвычайно затратной при больших объемах данных.
Ситуация улучшается, когда необходимо выбрать только первые k записей (например, для постраничного вывода). В этом случае сложность снижается до
O(n log k).
Соответственно, если у нас будет таблица, в которой данные будут заранее упорядочены по строковому полю примера, то ресурсоемкая операция сортировки не потребуется. А чтобы получить такую таблицу, то достаточно создать новый индекс по этому полю (поля входящие в индекс уже отсортированы).
Замечание!
Для оптимизации работы динамические списки в 1С по умолчанию используют автоматическое ограничение на количество данных, выгружаемых на клиентскую сторону. При трансляции на уровень языка SQL для Postgres она добавляет ключевое слово LIMIT (ПЕРВЫЕ). Это означает, что при «тяжелых» сортировках или отборах результат в некоторых случаях может быть сформирован быстрее, так как обрабатывается не весь объем данных.
Ключевую роль здесь играет параметр «Динамическое чтение»:
- Если параметр ВКЛЮЧЕН (рекомендуется): Платформа 1С выполняет запрос на выборку небольшой порции записей (обычно 20-50, в зависимости от размера списка и настроек). Следующие данные подгружаются по мере необходимости (например, при прокрутке пользователем). Это значительно ускоряет первоначальную загрузку формы.
- Если параметр ОТКЛЮЧЕН: Платформа накладывает ограничение в первые 1000 строк. Это может привести к существенному замедлению открытия списка, особенно если для формирования этого начального блока данных требуются сложные вычисления или соединения с большими таблицами.
Разница в производительности между этими двумя настройками может быть колоссальной, особенно при работе с большими таблицами. Объем требуемых вычислений растет нелинейно, поэтому отключение «Динамического чтения» часто приводит к резкому увеличению времени отклика.
Шаг 3. Поиск решения
Вариант 1. Добавление индекса
Проблема: Сортировка выполняется медленно из-за необходимости полного сканирования и упорядочивания всей таблицы.
Решение: Создание индекса по полям, участвующим в сортировке.
Почему это работает? Индекс — это отдельная служебная структура данных, в которой записи уже хранятся в отсортированном порядке. Когда СУБД нужно выполнить ORDER BY по индексированному полю, она может просто последовательно прочитать строки из индекса в нужном порядке, избегая ресурсоемкой операции сортировки "на лету".
Диагностика: Проверяем в Конфигураторе 1С и обнаруживаем, что для поля «Дата документа» свойство «Индексировать» не установлено. Это и есть причина неэффективной сортировки.
Действие: Устанавливаем свойство «Индексировать» для поля «Дата документа».
В результате 1С создаст новый индекс со следующей структурой, который планировщик СУБД сможет использовать при обработке запроса.

Рис. 11. Структура индекса уровни метаданных 1С и СУБД
Любопытное наблюдение!
Разработчики этой формы, видимо, частично озаботились оптимизацией, заблокировав сортировку по некоторым полям через механизм контроля. Однако для поля «Дата документа» это ограничение не было установлено, что и привело к проблеме.
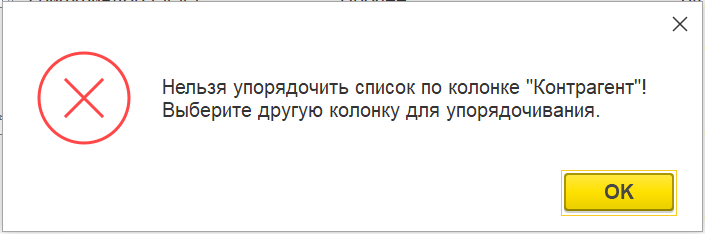
Рис. 12. Сообщение об ошибке при попытке сортировки по заблокированному полю "Контрагент"
Ожидаемый результат: После создания индекса план выполнения запроса должен кардинально измениться. Вместо операций Sort и Seq Scan (последовательное сканирование) СУБД будет использовать Index Scan или Index Only Scan, что значительно быстрее.
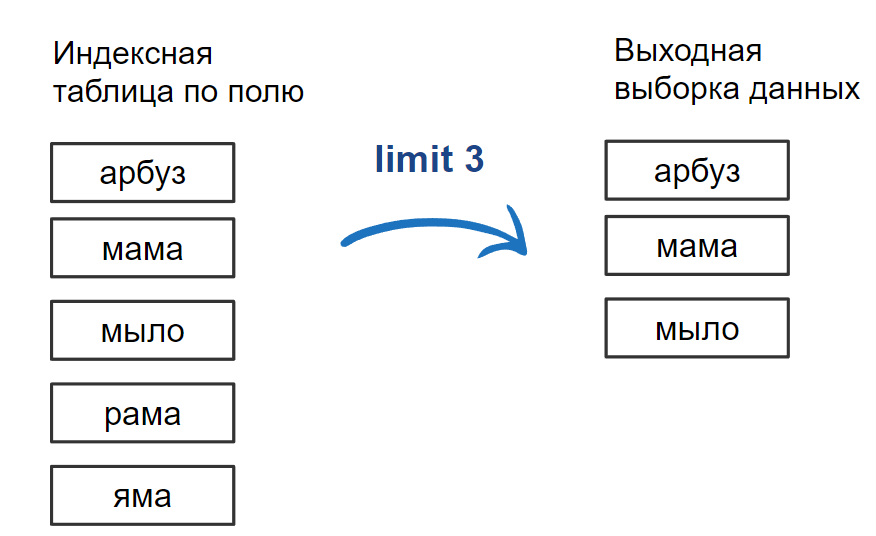
Рис. 13. Схема работы упорядочивания через индекс (Index Scan)
Вариант 2. Отказ от сортировки по неиндексированному полю
Этот подход представляет собой альтернативное решение, которое можно применить, если по каким-либо причинам невозможно создать индекс (например, из-за ограничений режима поддержки конфигурации).
В случае, если мы не хотим снимать конфигурацию с поддержки, то нам необходимо будет отключить сортировку по полю “Дата документа”. Иными словами вам в конфигурации придется самостоятельно искать места, где добавляется сортировка по этому полю и закомментировать подобные изменения через расширения. Мы этот вариант рассматривать не будем.
Шаг 4. Выполнение изменений
Был выбран Вариант 1 (создание индекса), так как заказчик подтвердил возможность снятия конфигурации с поддержки для внесения необходимых изменений.
Порядок действий:
- Открытие конфигурации: Конфигурация была открыта в режиме «Конфигуратор» платформы 1С.
- Снятие с поддержки: Поскольку на текущий момент свойство «Индексировать» недоступно для изменения в расширениях, основная конфигурация была снята с поддержки для прямого редактирования.
- Внесение изменений: В дереве метаданных был найден документ «Электронный документ входящий ЭДО».
- Для его реквизита «Дата документа» свойство «Индексировать» было изменено с значения «Не индексировать» на «Индексировать».
- Сохранение и обновление: Изменения были сохранены, а конфигурация обновлена в базе данных. Это инициировало процесс создания соответствующего индекса на уровне СУБД.
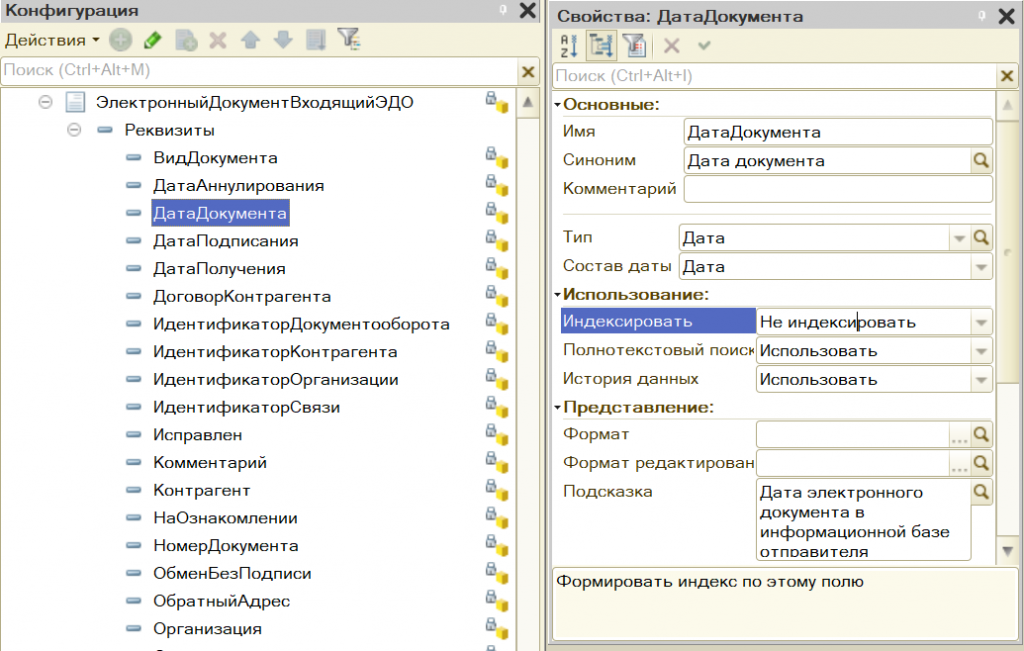
Рис. 14. Вносим изменения в конфигураторе конфигурации
Ожидаем применения изменений и выполняем упрощенный запрос в предприятии. В результате получаем уже другой и более эффективный план запроса. Как вы можете увидеть из изображений ниже, то у нас исчез блок сортировки и значительно уменьшилось количество обрабатываемых данных. Используется получение данных по индексу. И соответственно очень сильно снизилось время выполнения, что является замечательным фактом.

Рис. 15. Текстовый план запроса после оптимизации
Или в графическом представлении
https://explain.tensor.ru/archive/explain/f4975c16ff8ac94a7aa19d6ee6aaf348:0:2025-10-18#visio
Шаг 5. Заключение
Мы получили также план запроса основной таблицы этой формы в изначальном виде до оптимизации и упрощений (около 10 с):
https://explain.tensor.ru/archive/explain/b50723a52c655078709f5fe9e0399bb2:0:2024-04-09#visio
И после оптимизации (около 30 мс):
https://explain.tensor.ru/archive/explain/afcca629dde18ca6eb95ec47043de482:0:2024-04-09#visio
Путем простых математических действий мы можем приблизительно получить общую эффективность проведенных действий:
10 000 мс/ 30 мс ~ 300 раз.
Иными словами данный запрос стал выполняться в 300 раз быстрее. А отсюда общее время выполнения этого запроса в течение недели у нас сократится:
с 160 000 с до 500 с или
с 44 ч до менее чем 10 мин.
В рамках нашего разбора мы успешно провели полный цикл оптимизации производительности подсистемы 1С: от поиска проблемы до внедрения решения и оценки его эффективности.
Ключевые результаты и выводы:
- Эффективный поиск «узких мест»: Мы продемонстрировали методику приоритизации задач для оптимизации, основанную на данных мониторинга. Это позволяет сконцентрировать усилия на тех проблемах, исправление которых даст максимальный эффект.
- Ошеломляющий результат: Внедренное решение — создание индекса по полю сортировки — позволило ускорить выполнение проблемных запросов более чем в 300 раз. Это наглядно показывает потенциал грамотной оптимизации на уровне СУБД.
- Глубокий анализ проблемы: Мы детально разобрали, почему операция ORDER BY без индекса приводит к серьезным потерям производительности из-за необходимости полного сканирования и сортировки данных, и закрепили это наглядным примером.
- Практическая рекомендация для разработки: Подтверждена критическая важность настройки «Динамическое считывание» для динамических списков. Эта настройка значительно снижает нагрузку, ограничивая объем данных, обрабатываемых для отображения на форме.
- Взвешенный подход к инструментам: Мы подчеркиваем, что индексы — это мощный, но не универсальный инструмент. Их создание должно быть обоснованным, так как они несут накладные расходы на операции записи. Выбор решения всегда должен зависеть от конкретного контекста и архитектурных ограничений.

Вступайте в нашу телеграмм-группу Инфостарт