В этой статье поговорим о том, что такое мониторинг, зачем он нужен и каким образом мы можем его использовать в ландшафте 1С.
Итак, для чего мониторинг нужен бизнесу? Есть два показателя.
Первый – это уровень качества предоставляемых услуг (SLA). То есть когда система наблюдается и мониторится, мы можем при непрогнозируемом ее поведении достаточно быстро определить точку, где она начинает вести себя непредсказуемо, и понять, что именно в ней работает не так. А значит, мы можем быстрее исправить проблему и быстрее восстановить работоспособность системы.
Второй аспект – это повышение информационной безопасности (SI). Если мы умеем агрегировать и собирать события, которые происходят внутри нашей информационной системы, то можно построить систему мониторинга с точки зрения появления каких-то непонятных действий, событий в системе, и мы можем увидеть те угрозы, которые возникают при эксплуатации систем.
Определение мониторинга и его компоненты
Давайте определим, что такое мониторинг. Я очень давно пытаюсь подобрать русский синоним слова «мониторинг» и пока не получается.
По определению, мониторинг – это постоянное наблюдение за какими-нибудь процессами для оценки их состояния и прогнозов развития. То есть это некоторое непрерывное наблюдение и сохранение не только текущего состояния. Нам также нужно знать, какое состояние было предшествующее, нужна история.
Что нужно, чтобы построить систему мониторинга?
-
Понять, откуда мы будем брать информацию, то есть поиск источников информации.
-
Решить, где мы будем эту информацию агрегировать и хранить, чтобы ее можно было достаточно легко обработать – сбор, хранение и обработка данных.
-
Сам по себе объем информации нам ничего не даст, он достаточно сложно читается взглядом человека. Поэтому нам нужно каким-либо образом визуализировать поступающую информацию.
-
Дальше можно анализировать и строить прогнозы, повышая качество нашего наблюдения, нашей системы мониторинга, которая в итоге получилась.
Визуализация и оповещение в системе мониторинга
Давайте посмотрим, какие графические способы для визуализации данных мониторинга существуют.
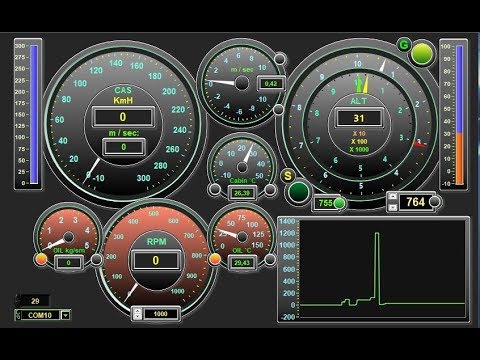
Это визуализация показателей, таких как индикаторы и диаграммы. Мы строим панели визуализации, которые отражают текущее состояние.
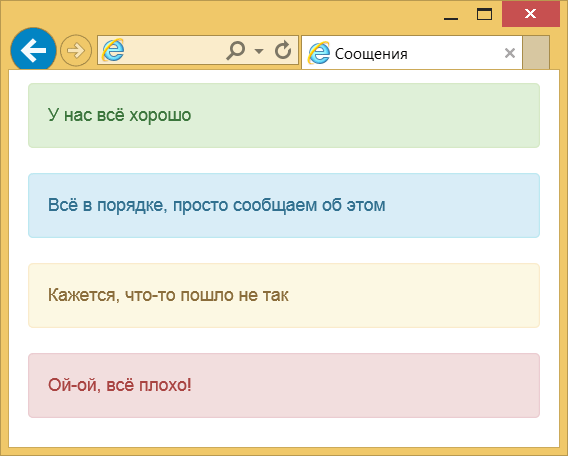
Просто так постоянно смотреть на панель визуализации не очень интересно, да и не получится. Вы не можете посадить человека 24/7, чтобы он смотрел на тысячу показателей. Поэтому нам нужна система оповещения. Хороший мониторинг должен уметь сообщить пользователю о том, что что-то пошло не так или, наоборот, что работоспособность восстановилась.
И нам нужен инструмент, который позволит глубоко проанализировать текущее состояние, сравнить его с ретро-данными и донастроить нашу систему для корректного поведения.
Примеры визуализации мониторинга 1С
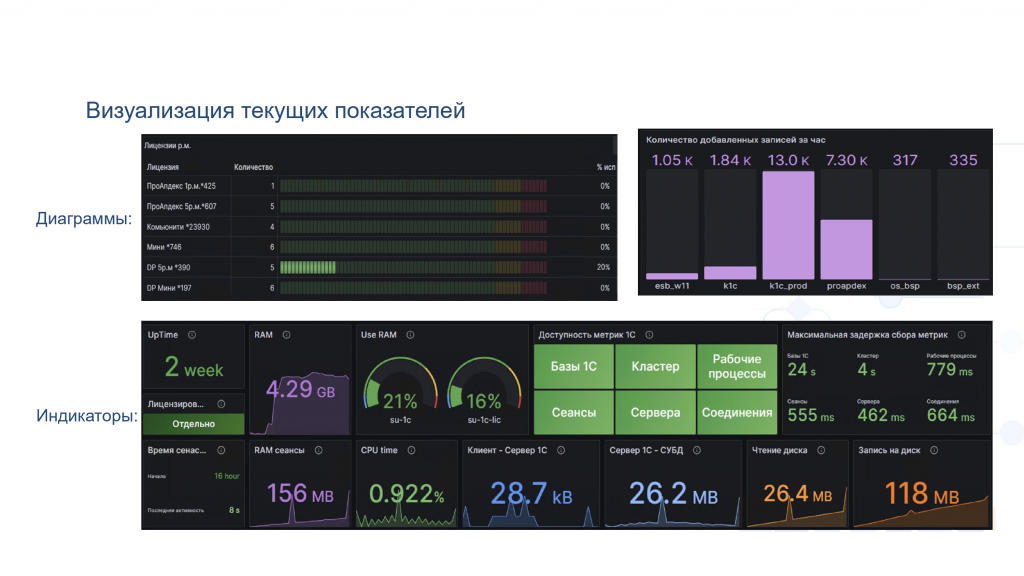
Как могут выглядеть индикаторы текущих показателей? Это может быть какая-то диаграмма. Например, сверху слева – диаграмма утилизации лицензий рабочих мест 1С. Мы видим, что у нас есть восемь ключей, видим их емкость и видим, сколько процентов сейчас используется. Одного взгляда достаточно для того, чтобы понять, что все окей, сейчас ночь, и никто не работает.
Второй показатель – это количество событий, происходящих в разрезе информационных баз. Мы видим ту же самую нагруженную систему, видим, что там все хорошо, и одновременно, что две крайние базы работают очень странно. Мы можем предположить, что там есть какая-то проблема, если обычно событий много, а сейчас их почти нет, и начать смотреть глубже.
Ниже на панели отображаются такие показатели, как использование оперативной памяти, текущая загрузка процессора, количество рабочих процессов и проч. Все это тоже визуализируется.
На этом примере мы видим ситуацию «здесь и сейчас». То есть мы зашли на мониторинг, посмотрели и поняли, что вроде бы все хорошо.
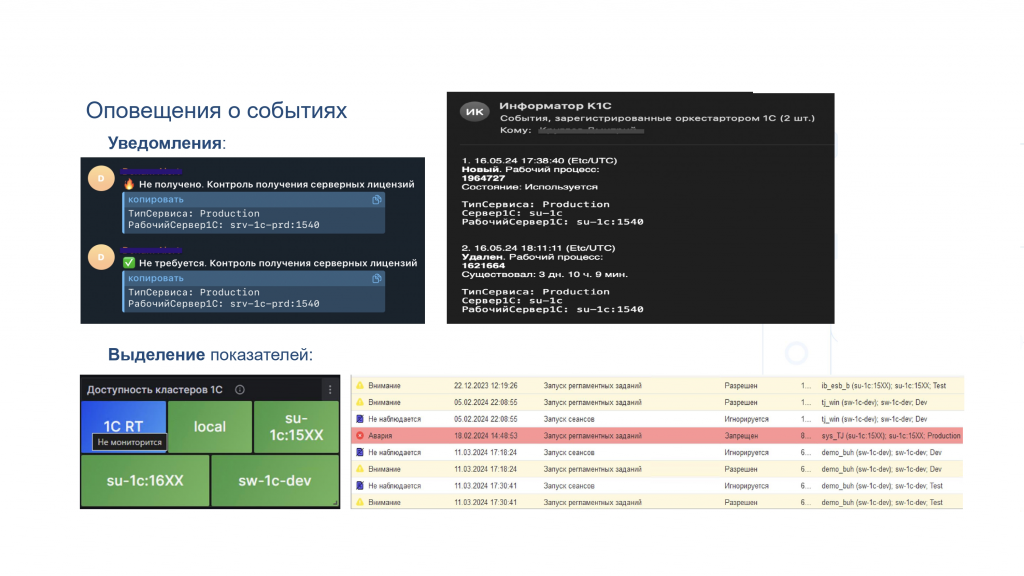
Система оповещений и визуальное выделение проблем
Но этого мало. Если у нас тысяча показателей, нам нужна система оповещений. Система мониторинга наблюдает за событиями, и в случае возникновения каких-то условий – а это, по сути, просто запрос, который определяет заданное условие – происходит срабатывание и формируется уведомление.
Например, уведомление в Telegram-канал и на почту. Причем на почту оно может приходить три раза в день, а в Telegram – в момент возникновения события. То есть почта больше подходит для руководителя: посмотреть, какие события сегодня происходили, а Telegram – для оперативного реагирования.
Помимо вывода информации на панель визуализации можно ее подсвечивать, чтобы акцентировать внимание визуально. Например, у нас есть пять кластеров, из которых четыре наблюдаются, а один – не наблюдается. Если бы на картинке все они были зеленые, было бы не очень понятно. А когда один выделен другим цветом, мы сразу видим, где именно есть проблема.
Анализ с помощью ретроспективных данных
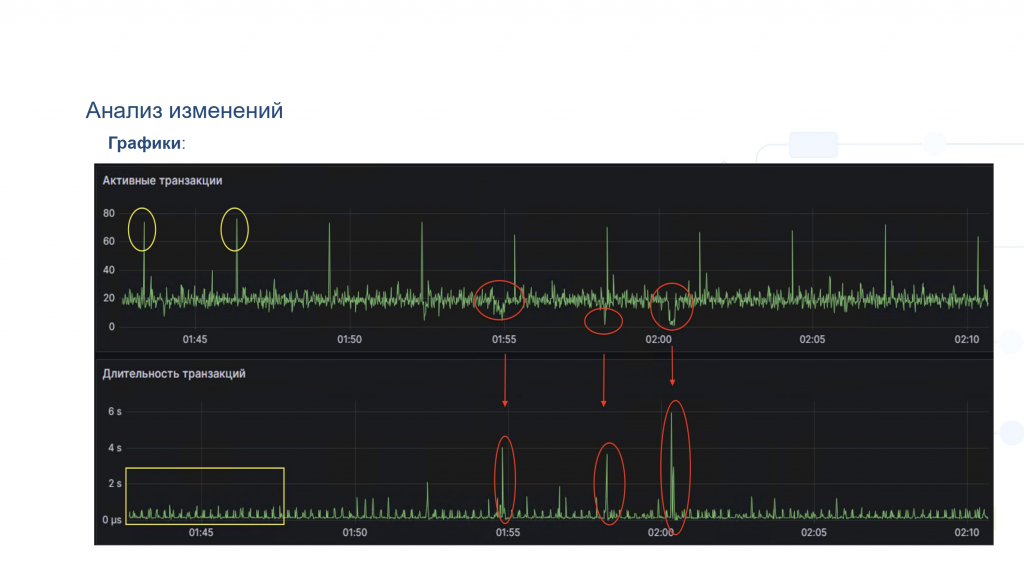
График показывает не только текущее состояние, но и ретро. Что это нам может дать?
На картинке – абсолютно реальный кейс, который был у клиента. Проблема заключалась в том, что происходила деградация производительности: пользователи жаловались, что 1С не работает, все плохо. Причем это «не работает» проявлялось периодически – примерно раз в 2,5 минуты.
Начинаем смотреть. Видим, что есть некоторое регламентное задание. И делаем предположение: наверное, это оно. Оно стартует и все ломает.
Но на самом деле нет. Почему? У нас два графика. Они расположены друг под другом и абсолютно синхронны:
-
Первый – это количество активных транзакций в системе в единицу времени,
-
Второй – это средняя длительность транзакций.
Мы видим, что действительно каждые 5 минут стартует что-то, что кратно повышает количество транзакций. Средняя длительность при этом никак не меняется.
Далее видно, что в 1:50 произошло событие: количество активных транзакций резко ушло вниз, при этом средняя длительность транзакций, наоборот, резко выросла. И здесь мы можем предположить, что возникли ожидания на блокировках. Потому что транзакции частично запустились, часть из них встала в ожидания, длительность увеличилась. Соответственно, последующие транзакции ждут, не стартуют, и общее количество уменьшается.
Буквально одного взгляда на график хватило, чтобы понять, где искать и, главное, во сколько искать. Достаточно было просто посмотреть логи за 1:55 – что именно стартовало в этот промежуток времени.
Агрегация событий с помощью сводных таблиц
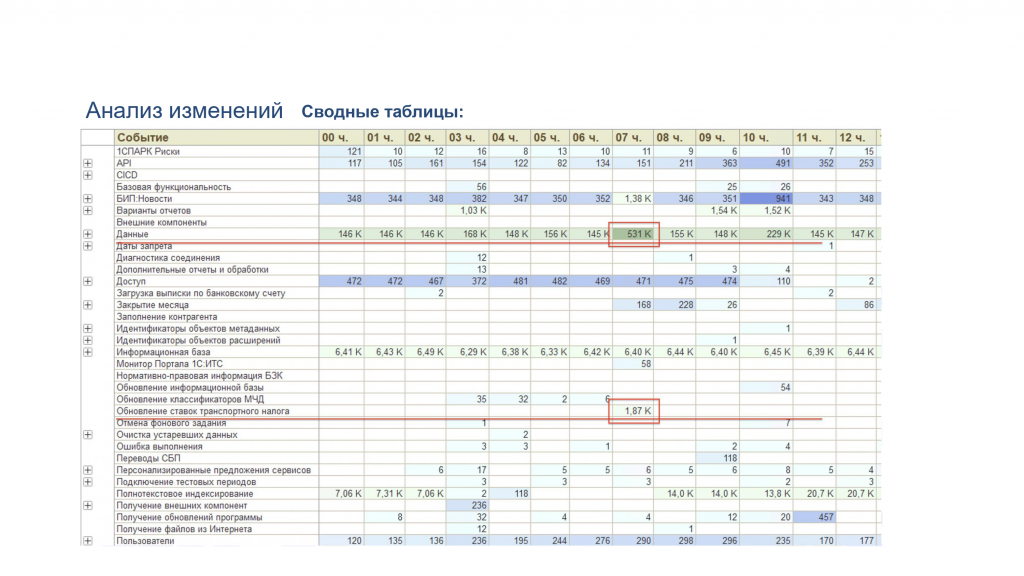
Это сводная таблица. Когда мы агрегируем, у нас отражаются все события журнала регистрации по часам. И сделан вывод, что происходит в системе, допустим, за месяц.
Мы можем наблюдать, что у нас в 7 утра количество событий кратно увеличивается. Обычно это около 150 тысяч, а здесь полмиллиона.
Смотрим, что произошло, и видим, что появляется событие «обновление ставок транспортного налога». Ни в одной другой ячейке этого события нет. Начинаем разбираться и находим: это регламентное задание, которое ежедневно стартует в 7 утра и обновляет ставки транспортного налога в типовой бухгалтерии.
Оно изменяет данные, фактически перезаписывает каждый день. Хотя ставки, наверное, не меняются ежедневно. Если бы из-за этого возникали проблемы, можно было бы это оптимизировать.
В данном случае очень наглядно видно корреляцию между различными событиями и то, как их можно выявить с помощью таких сводных таблиц.
Хранение данных мониторинга: современные подходы
Теперь поговорим о том, где хранить данные мониторинга. В текстовых файлах – уже неактуально. Очень сложно оттуда все добывать.
Часто данные хранят в таблицах обычных SQL-баз: Postgres, MS SQL, MySQL. Но если мы говорим о современных инструментах, то есть два больших блока, где можно хранить данные мониторинга.

Первый – это все NoSQL-базы данных. И в первую очередь – базы, которые называются time series, то есть базы временных рядов: Prometheus, VictoriaMetrics, InfluxDB.
У них есть свои адаптеры, которые могут получить текущее значение – слепок. Они могут сходить на операционную машину и собрать все данные об использовании памяти, процессоров, дисков и прочего. Также они могут сходить в 1С и получить количество текущих сеансов, количество занятых лицензий и т.п. Графики, которые я показывал выше, как раз построены на такой базе.
Они получают слепок и фиксируют: сегодня, вот сейчас, в эту минуту они получили данные и сохранили у себя. Через 15 секунд или через минуту – в зависимости от того, какой интервал вы настроите, – они их снова получат и снова сохранят. Этих слепков накапливается огромное количество, что и позволяет нам анализировать и визуализировать эти данные.
Второй большой блок NoSQL-баз – это документарные базы: ClickHouse, Elasticsearch. ClickHouse – это столбцовая база данных, но это не суть важно. Главное то, что туда можно сохранить логи, конкретные записи. Например: пользователь Иванов зашел на 17 минут – и мы эту запись сохранили. Можно посмотреть всю хронологию событий.
С помощью этих СУБД можно агрегировать данные. Построить, например, сводную табличку, которая была показана выше. Она была построена на данных ClickHouse, агрегированных по событиям, по времени суток и по количеству.
Мы можем «провалиться» и посмотреть: что это за 121 событие в 1С, какой объект, какой риск, какой пользователь это сделал и так далее. Это как раз то, что сейчас используется большинством девопсов для построения мониторинга своих систем. Но у нас 1С, и у нас путь немного другой.
Источники данных для мониторинга в 1С. Утилита администрирования серверов
Давайте посмотрим, какие источники могут быть для построения системы мониторинга в 1С-ландшафте.
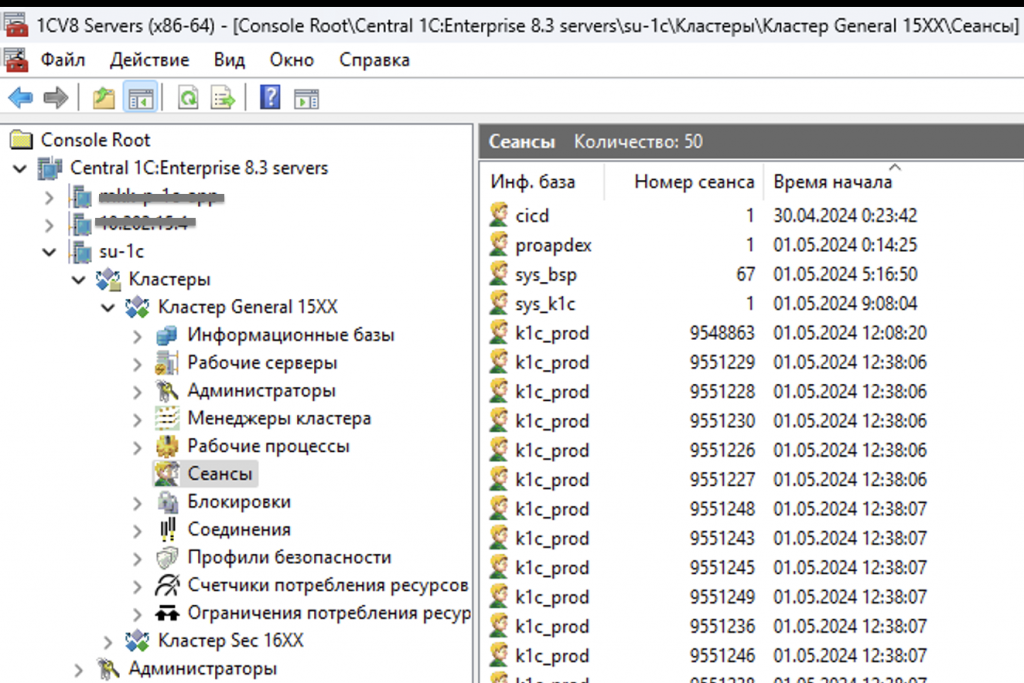
Это всем известная утилита администрирования серверов, которая работает только на Windows.
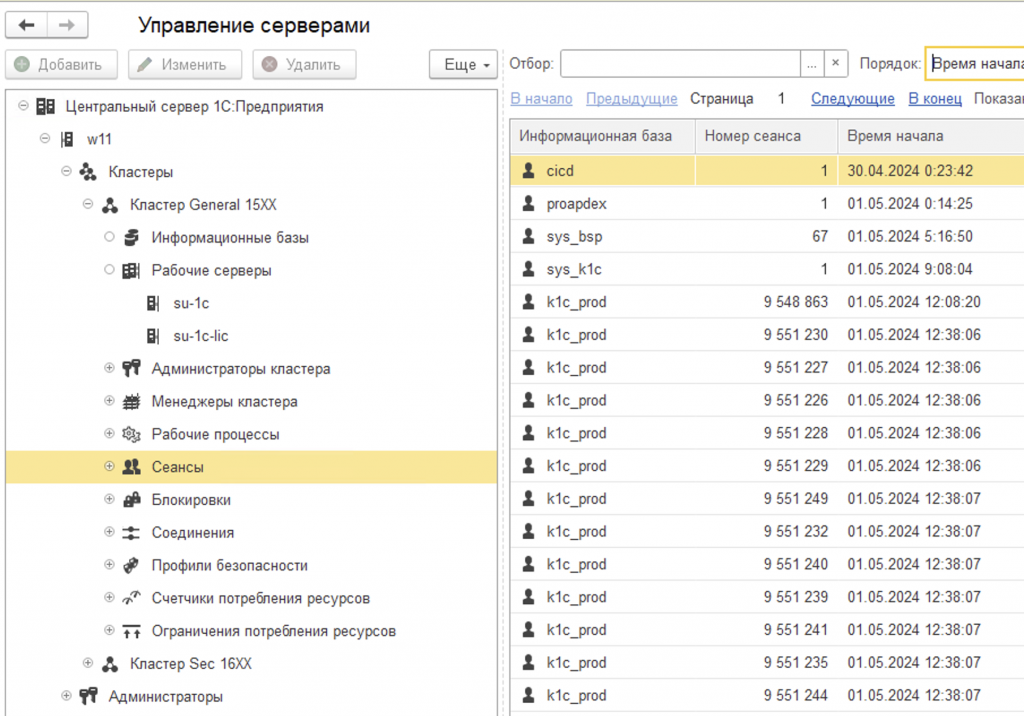
Появилась также возможность из режима предприятия открыть «Управление серверами», если выбрать режим технического специалиста.
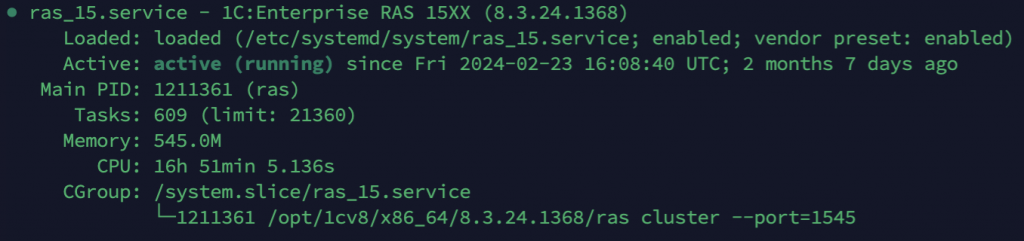
Третий вариант – больше для разработчиков: поднять службу RAS (Remote Administration Server) и с ее помощью получать метрики. Можно получать данные прямо в 1С с помощью объекта «Администрирование сервера».
Почему нельзя сказать, что у нас есть утилита и это уже мониторинг?
-
Она не хранит данные. Система мониторинга должна хранить предыдущие данные, чтобы можно было сравнивать текущее состояние с прошлыми значениями.
-
Требуется интерпретация. Это «портянка» из кучи цифр, не всегда понятно, как ее читать.
-
RAS, как и утилита администрирования, вообще не умеет никого уведомлять. То есть он показывает информацию только тогда, когда вы туда заходите. А если вы туда не смотрите, он ничего и не делает.
Также требуется полное совпадение версий платформы, вплоть до минорных.
Журнал регистрации как источник данных
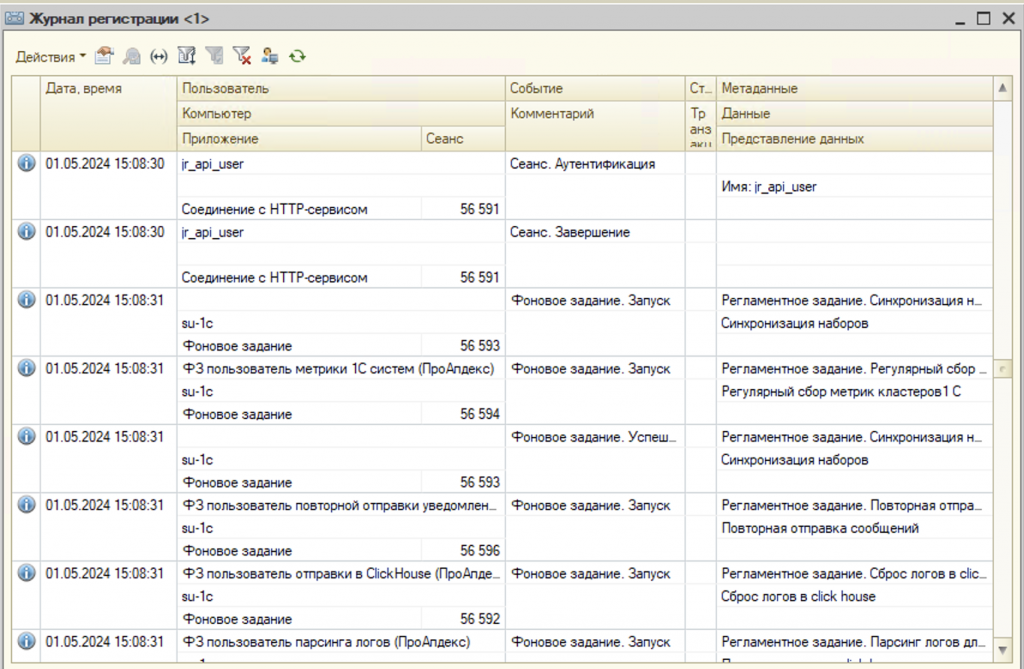
Второй источник – это всем известный журнал регистрации. Когда мы по умолчанию разворачиваем базу, он сразу активен. Мы можем туда зайти и посмотреть, что пользователь зашел, документ изменился, регистр записался.
Но когда у нас появится тысяча пользователей и база поработает полгода, при попытке зайти в журнал регистрации все будет плохо. Можно будет дня два пить кофе, пока найдем только одно событие.
Так происходит, потому что журнал регистрации – это файловая база. Раньше была реализация на SQLite, но это не особо спасало. Это файловая, текстовая, практически не индексируемая система. Искать в ней что-то можно очень долго, и точно нельзя сказать, что это полноценная система мониторинга.
Еще один момент: журнал вообще никак не ротируется. То есть рано или поздно он просто забьет диск. Если вы ничего не будете с ним делать и база будет долго работать, то рано или поздно 1С остановится из-за того, что она не сможет записать журнал регистрации.
Технологический журнал: возможности и ограничения

Третий источник – это технологический журнал. Он настраивается разработчиками или специалистами службы эксплуатации, настраивается достаточно гибко. Туда можно вынести различные события, можно все записывать. Но если писать туда абсолютно все на нагруженной системе, то нам нужны очень производительные диски и очень много места – туда могут литься гигабайты в секунду.
Почему мы не можем сказать, что это полноценная система мониторинга? Потому что он никуда ничего не пишет, кроме как в свои собственные текстовые файлы. Каждый час он создает новый текстовый файл для каждого процесса. На нагруженной системе это может быть порядка 100–200 тысяч новых файлов в час.
Да, он умеет ротироваться – например, каждые 4 часа может удалять свой хвост. Но каким образом быстро понять, что у вас реально происходит в системе, если надо сагрегировать эти сотни тысяч файлов и попытаться их прочитать? Это очень нетривиальная задача. Особенно если учесть, что внутри эти файлы имеют нетривиальную структуру. Там нет JSON, нет XML, а используется абсолютно свой внутренний формат.
Интеграция 1С с современными системами мониторинга. RAS
Теперь применяем то, что мы говорили выше о современных инструментах, к 1С-ландшафту.
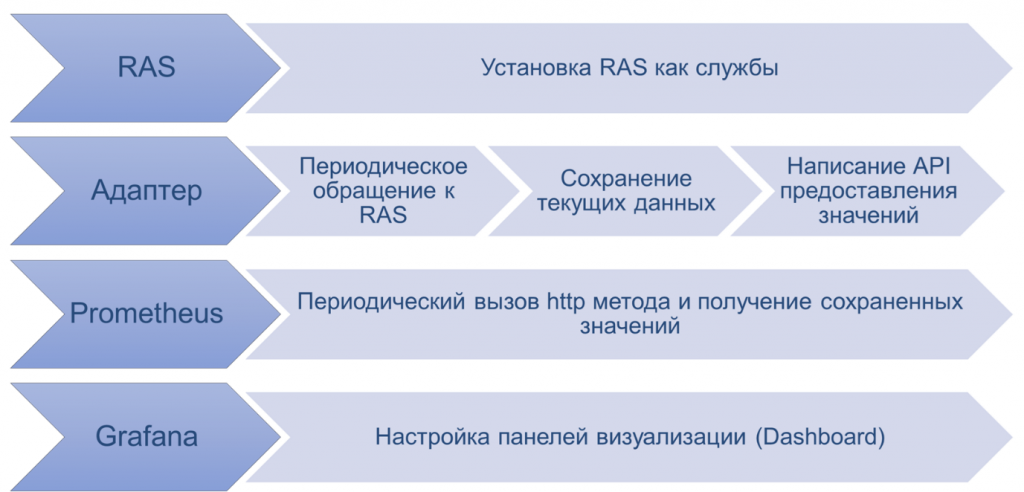
Нам достаточно установить RAS (Remote Administration Server) и написать небольшой адаптер. Его может написать разработчик, программист, девопс или инженер с базовыми навыками разработки. Этот адаптер обращается к RAS, получает от него метрики и готов отдать их в формате, понятном Prometheus.
Prometheus будет обращаться к этому адаптеру, забирать слепки, сохранять у себя. А дальше уже в Grafana мы можем визуализировать и строить красивые дашборды.
25-я платформа дает возможность напрямую подключаться к Prometheus и забирать метрики. То есть 1С идет в сторону современных инструментов.
Парсинг журналов и использование ClickHouse
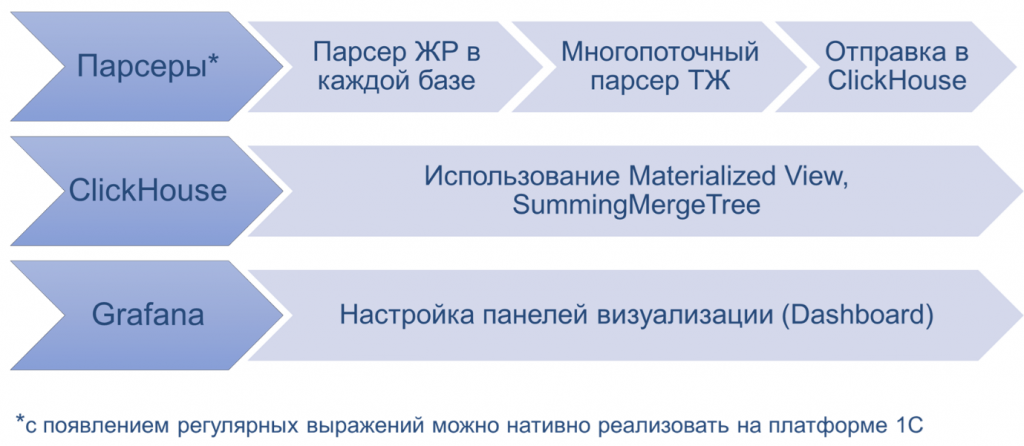
Если мы говорим про разработку мониторинга на основе журналов – журнала регистрации и технологического журнала, – то здесь нам также достаточно написать некий парсер. Он может быть в каждой базе, если речь идет про журнал регистрации, потому что журналы принадлежат конкретной базе. Или это может быть какой-то отдельный парсер для сервера, если мы разбираем технологический журнал, который будет готов отправить данные, например, в ClickHouse.
У ClickHouse есть очень интересные движки и разные типы таблиц. Мы используем много Materialized View – это материализованное представление, которое предагрегирует некоторые события и сохраняет их у себя.
Для того, чтобы построить график, мы можем написать запрос к сырым данным, но такой запрос будет выполняться минуту. А Materialized View позволит получить те же самые цифры буквально за 1-2 секунды.
Есть еще SummingMergeTree – это то же самое, только уже более «физическая» таблица. Если Materialized View – это представление сырых данных, то SummingMergeTree – это непосредственно таблица, которая агрегирует данные.
Grafana может использовать в качестве источника как Prometheus, так и ClickHouse. Мы получаем визуализацию, и все это выглядит красиво и наглядно.
Системы уведомлений и автоматизация
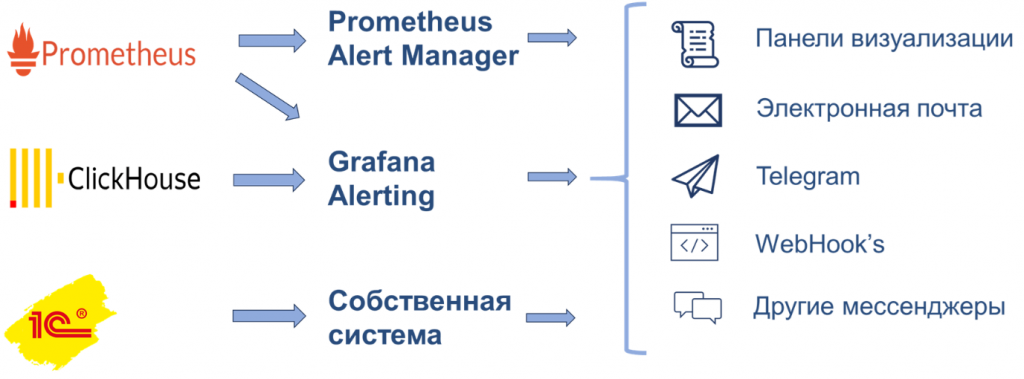
У каждой системы есть своя система уведомлений, плюс никто не мешает нам использовать какое-либо собственное уведомление внутри нашей базы.
Например, у нас есть регламент: каждую ночь должно стартовать задание, которое формирует прайс-листы и отправляет их нашим клиентам. Это предприятие длительное, оно работает около пяти часов, и нам нужно точно знать, что ничего не остановилось и процесс идет корректно. Мы рассчитываем, что в среднем каждый час должно отправляться по 10 тысяч прайс-листов. Ставим счетчик, и если в течение двух часов не отправилось 20 тысяч прайс-листов, мы можем отправить уведомление в Telegram. Это если говорить про собственную систему, про организацию мониторинга внутри базы.
У Prometheus и ClickHouse уже есть встроенные механизмы оповещений, которые можно настроить. У Prometheus это Alert Manager, а данные из ClickHouse можно отслеживать и оповещать с помощью Grafana Alerting.
Как это реализовано: мы пишем запрос, который при наступлении некоторого условия может выполнить какое-то действие. Это может быть, во-первых, визуализация на панели. В самом начале мы говорили, что 10, 20, 30, 50, 100 показателей в одном шрифте и в одном цвете – это непонятно. А вот если выделить их цветом – сразу видно, как система себя ведет.
Кроме того, можно настроить уведомления: в электронной почте, в Telegram, или в корпоративных мессенджерах, если информационная безопасность ограничивает использование внешних.
Дальнейшее развитие системы мониторинга – это уже WebHook’s. При наступлении события система может не только уведомить, но и выполнить действие. Например, перезапустить базу. У нас был случай: в конфигуратор на продовых базах нельзя было заходить дольше, чем на полчаса, особенно в рабочее время. Поэтому система мониторинга просто «отстреливала»: если кто-то заходил в конфигуратор, его выбрасывало.
Преимущества централизованной системы мониторинга
Если мы все это начнем использовать, то у нас выйдет достаточно эффективный мониторинг.
Первое, что мы получаем – централизованное хранение. У нас было 80 кластеров, 200 баз, 10 тысяч пользователей, 200 журналов регистрации и 80 источников технологических журналов. Все это мы можем соединить в единую систему, которая сможет работать даже на относительно медленных дисках, и при этом будет достаточно дешевой в эксплуатации. Доступ к данным при этом становится единообразным.
ClickHouse прекрасно показывает себя в плане сжатия данных: около двух миллиардов записей занимают всего около 100 гигабайт. Это примерно в 30 раз меньше, чем «грязные» данные технологического журнала или журнала регистрации.
Кроме того, у нас появляется возможность агрегировать показатели как угодно, если мы все перетащили в ClickHouse. Мы можем строить любые запросы, и они будут красиво отображаться в виде графиков – в том числе и для бизнес-задач.
У нас есть возможность визуализации, анализа ретро-данных. И есть еще один момент, о котором мы пока не говорили, – это автоматическая ротация.
Мы не хотим хранить логи вечно, нам достаточно года. И чтобы не писать какие-то отдельные скрипты «если дольше, то удали», в современных базах, в том же ClickHouse, есть возможность настройки этого периода. СУБД сама будет удалять хвост и хранить логи только год или меньше.
ClickHouse умеет делать полнотекстовый поиск. И мы реализовали журнал регистрации именно на полнотекстовом поиске. Впишите любое слово или его часть – он достаточно оперативно его найдет.
Оркестратор 1С-систем
Мы занимаемся тем, что разрабатываем систему мониторинга. И один из наших продуктов – это оркестратор 1С-систем, который позволяет построить систему мониторинга, о которой я рассказывал выше.
Его преимущество в том, что он не использует никаких внешних компонентов. Он полностью нативный, все парсеры, которые разбирают данные, написаны на языке 1С. Для того, чтобы начать пользоваться системой мониторинга, не нужно ничего разрабатывать. В конфигуратор вы зайдете только один раз – чтобы создать пользователя. Продукт поддерживается и развивается нами.
Вот все инструменты, о которых я рассказывал:
-
RAS – предоставление значений показателей работы в реальном времени. https://its.1c.ru/db/v8323doc#bookmark:cs:TI000000190
-
Оркестратор 1С – разбор журналов и показателей, передача данных в СУБД. https://k1c.proapdex.ru
-
ClickHouse – хранение записей журналов 1С. https://clickhouse.com
-
Prometheus – хранение значений показателей работы объектов 1С ландшафта. https://prometheus.io
-
Grafana – Визуализация данных. https://grafana.com
RAS – это утилита 1С, которая идет прямо в платформе оркестратора 1С, вы можете использовать его как готовое решение. Но это совсем не обязательно – можно использовать любое другое, в том числе самописное.
Prometheus, ClickHouse и Grafana – это бесплатные open-source решения. Их можно установить как на Linux, так и на Windows. Все, о чем шла речь выше, работает одинаково хорошо и на Windows, и на Linux.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Анализ & Управление в ИТ-проектах.

Вступайте в нашу телеграмм-группу Инфостарт