Меня зовут Александр Насонкин. Я работаю с 1С уже 14 лет, практически с первого курса университета, мне даже довелось писать код на 1С 7.7. На текущий момент являюсь главным разработчиком в Центре экспертизы 1С компании Magnit Tech.
В последние два года у нас проводится проект по импортозамещению, где мы переводим серверы приложений 1С с Windows на операционную систему Linux, а базы данных 1С – с MS SQL на PostgreSQL. В рамках этого проекта возникла задача – позволить разработчикам максимально быстро получать актуальные копии базы 1С объемом 5 ТБ на СУБД PostgreSQL.
И сегодня мы с вами выясним, как дать каждому разработчику полноразмерную копию базы, и не потратить при этом весь бюджет компании и тысячи часов на развертывание тестового окружения. Расскажу, какой инструмент можно использовать для того, чтобы получать полноразмерные копии боевой базы за считанные секунды.
Привычные способы организации контура разработки и тестирования

Но сначала давайте рассмотрим, какие вообще бывают подходы к разработке и тестированию.
Самый простой, но довольно редко уже используемый подход – когда у каждого разработчика есть только своя локальная база 1С, которая похожа на боевую лишь конфигурацией. В этой базе только самый минимальный тестовый набор данных, и то не всегда – зачастую разработчику приходится самостоятельно генерировать данные для тестов.
А теперь представьте: сидит разработчик на ноутбуке со своей маленькой базой, а ему требуется разработать отчет, обрабатывающий огромный объем данных. Отчет он написал, но полноценно его протестировать не может.
И хорошо, если у этого разработчика нет доступа на прод. Потому что иначе велика вероятность, что он захочет проверить, быстро ли формируется его отчет, и «положит» им рабочую базу.
Даже если перед помещением в релиз проводится код-ревью, проверяющие все равно могут что-то упустить, а ошибки на продуктиве стоят очень дорого.
Тестирование на реальных данных позволило бы выявить проблему и устранить ее еще на этапе разработки.

Следующий, уже более распространенный подход – когда на команду разработки выделяется общий тестовый стенд с копией боевой базы.
Здесь тоже не все так гладко.
-
Разработчики не могут приступить к тестированию сразу, потому что сначала их доработки должны попасть в общую базу, а обновление производится только в согласованное регламентное окно (обычно каждую ночь). Придется ждать еще сутки, и тестировать только на следующий день.
-
При этом конфигурация тестовой базы не соответствует конфигурации боевой базы.
-
Так как база общая и разработчиков, которые помещают туда свои изменения, много, могут возникать и конфликты. Наверняка те, кто использует данный подход, встречались с ситуацией, когда в тестовой базе «случайно» пропадал чужой код. Или один из разработчиков помещал в тестовую базу код с ошибкой, и всем приходилось ждать, пока выполнится внеплановое обновление.
-
При проведении тестирования могут возникать ситуации, когда одни и те же объекты требуются сразу нескольким разработчикам – в этом случае одному из них приходится ждать, пока другой закончит свои тесты. Хорошо, если после этих экспериментов данные еще останутся, иначе придется их подготавливать самостоятельно. И не факт, что эти данные будут сопоставимы с теми, что на проде, потому что некоторые ошибки можно выловить только на продуктивном наборе данных или максимально приближенном к нему.

Кажется, что выход очевиден – нужно просто выдать каждому разработчику по полноценной копии боевой базы. Тогда у каждого будет полная свобода действий – никто никому не помешает.
Но что делать, если разработчиков много, а боевая база измеряется десятками или сотнями терабайт? И как быть, если каждому разработчику таких баз для тестирования нужно несколько, а не одна?
Тут возникает другой вопрос – где же взять столько денег на диски, чтобы их хватило для размещения всех копий? Да и времени на развертывания копий, объем которых измеряется терабайтами, будет уходить очень много.
Технология «Копирование при записи» или «Тонкое клонирование»

К счастью, уже есть технологии, которые позволяют экономить дисковое пространство и не тратить часы на копирование большого объема данных. Я сейчас говорю о технологии Copy-On-Write (копирование при записи) или так называемом «тонком клонировании».
Если не углубляться в технические детали, суть подхода Copy-On-Write в том, что для чтения используется общий снимок данных. И только при добавлении или изменении информации, разница от исходного состояния записывается на диск.
В нашем случае мы на основании данных боевой базы 1С делаем снимок, доступный только для чтения. И уже на основе полученного снимка создаем редактируемые снимки или «клоны», которые представляют собой полноценные копии 1С.
Важно, что эти «клоны» не будут занимать места на диске до тех пор, пока разработчики не начнут туда вносить свои изменения.
А благодаря тому, что в файловых системах, поддерживающих технологию «Копирование при записи» используются алгоритмы сжатия данных, копирование происходит практически мгновенно.

Благодаря «тонкому клонированию» мы можем получать полноценные копии за считанные секунды, независимо от размера базы данных.
При этом десятки независимых клонов могут работать на одном и том же сервере, обеспечивая разработку и тестирование без увеличения затрат на железо.
Но даже в этом случае разработчики 1С зависимы от администраторов, которые занимаются развертыванием копий. Потому что вряд ли кто-то даст всем разработчикам доступ на сервер с административными правами, чтобы они сами создавали себе снимки, клоны, поднимали кластер PostgreSQL.
Тут можно пойти в сторону автоматизации – написать свое решение (конечно же, на 1С), чтобы пользователи оттуда могли заходить, создавать себе копии и управлять ими.
Но зачем изобретать велосипед?

Не нужно тратить время и ресурсы на собственную разработку, когда уже существует готовое решение с открытым исходным кодом.
Речь о Database Lab – инструменте, который призван упростить получение копий и дать возможность разработчикам самостоятельно этими копиями управлять.

Database Lab распространяется компанией postgres.ai под лицензией Apache 2.0 – его исходный код выложен на GitLab.
-
Основная часть кода написана на Go, компоненты веб-интерфейса – на TypeScript, а скрипты – на Shell.
-
Поддерживаются не только основные версии СУБД PostgreSQL (начиная с 9.6), но и те, которые основаны на нем – в нашем случае это Postgres Pro, Tantor, Pangolin.
-
Реализована работа с файловыми системами с технологией Copy-on-Write: ZFS (используется по умолчанию) и LVM.
-
Конечно же, не обошлось без использования популярной технологии контейнеризации, потому что все компоненты Database Lab работают в отдельных контейнерах. К таким контейнерам относится:
-
Основной контейнер, который содержит настройки и предоставляет командной утилите доступ к API. Именно основной контейнер управляет созданием снимков и клонами, которые точно так же запускаются в отдельных контейнерах.
-
Контейнер репликации.
-
Для удобства пользователей предусмотрен отдельный контейнер веб-интерфейса, с помощью которого можно управлять клонами, смотреть статистику. Доступ к веб-интерфейсу осуществляется по токену, и при необходимости можно ограничить список хостов, с которых разрешено подключение (по умолчанию доступ разрешен только с локальной машины).
-
Вообще возможностей у Database Lab много, и далее мы их подробно рассмотрим.
Настройка Database Lab для работы с базами 1С на PostgreSQL

Расскажу, как все это дело запустить для 1С.
Мы используем для копий отдельный выделенный сервер на базе виртуальной машины с операционной системой Debian 12.
На сервере обязательно должен быть установлен Docker, так как мы уже выяснили, что все компоненты DBLab работают в отдельных контейнерах.
Также в файловой системе сервера необходимо создать отдельный пул ZFS или LVM (желательно на отдельном SSD диске) – именно туда будут помещаться данные копий, снимков и клонов.
В целом подготовка сервера занимает немного времени – в официальной инструкции этот процесс описывает буквально 10 команд.
При настройке операционной системы нужно обратить внимание на лимит максимально-допустимого числа открытых файлов. Если вы за этот лимит выйдете, то получите ошибку «Too many open files in system», которая приведена на слайде. Когда у нас в один прекрасный день перестала обновляться реплика, которая поддерживалась встроенными средствами PostgreSQL, оказалось, что стандартный для ОС Debian лимит недостаточен, и нам пришлось увеличить его в несколько раз (до 250 000). Это можно сделать командами:
sudo nano /etc/sysctl.conf #изменить fs.file-max
sudo sysctl -p #применить изменения
cat /proc/sys/fs/file-max #проверить лимит

Поскольку для работы 1С используется не стандартная (ванильная) версия СУБД PostgreSQL, а специфическая с дополнениями, которые необходимы для корректной работы платформы 1С:Предприятия, и все базы создаются с русской локалью, необходимо переопределить образ docker-контейнера, который будет использоваться для запуска получаемых копий 1С.
В качестве основы можно взять Dockerfile из официального репозитория и изменить его – добавить русскую локаль и требуемую версию СУБД – в нашем случае мы используем поставку PostgreSQL от фирмы 1С.
Если вы работаете с другой СУБД – Postgres Pro, Pangolin или Tantor, помещаете в образ ее версию.
После того как образ создан, его имя нужно будет прописать в конфигурационном файле Database Lab (~/dblab/engine/configs/server.yml) – этот файл по умолчанию располагается в каталоге пользователя, от имени которого будет запускаться сервис. Там необходимо изменить значение параметра dockerImage, указав имя созданного вами образа:
databaseContainer: &db_container
dockerImage: "pg-1с:15.4.1" # образ для запуска копий 1С
Архитектура решения, используемые технологии и варианты получения полноценных копий базы 1С
Расскажу, какую схему работы с Database Lab мы используем.

Чтобы разработчики могли в любой момент получить актуальную копию боевой базы, у нас на сервере с Database Lab поднята ее реплика, которая поддерживается встроенными средствами PostgreSQL. Через выделенный слот репликации с боевой базы на облачное объектное хранилище S3 отправляются WAL-файлы (журналы предзаписи), а реплика оттуда их забирает и накатывает. То есть никакого прямого доступа сервера с копиями к продуктиву нет.
По факту это единственный момент, когда нам требуется привлечь к работе администраторов СУБД – для настройки реплики. В дальнейшем мы их больше не тревожим и справляемся самостоятельно.

Причем реплика уже сразу располагается на диске, который поддерживает сжатие с файловой системой ZFS. Таким образом база весит не 5 ТБ, а в 10 раз меньше – всего 500 ГБ.
Конечно, степень сжатия будет зависеть от типа данных, которые хранятся в вашей базе.

Стоит отметить, что Database Lab из коробки предоставляет два способа, которые позволяют скопировать боевую базу и на ее основании получать снимки:
-
Физический способ – можно скопировать каталог кластера или восстановить архив, если у вас используются инструменты для физического резервного копирования. Преимущество этого подхода в том, что Database Lab может автоматически поддерживать асинхронную реплику в отдельном контейнере, постоянно накатывая новые WAL-файлы (журналы предзаписи).
-
Логический способ – это создание дампа и его восстановление в виде копии. Этот способ поддерживает частичное восстановление, т.е. если у вас в кластере PostgreSQL много баз, то, используя логический способ, вы можете восстановить только конкретную базу данных, которая вам требуется.
В репозитории Database Lab есть готовые примеры конфигурационных файлов для каждого из способов, а в документации подробно описаны все эти задания и их параметры.

По умолчанию при старте сервиса Database Lab сразу запускается создание снимка с реплики, но это поведение можно изменить, и в дальнейшем снимки будут создаваться уже в соответствии с расписанием, которое вы указали.
При создании нового снимка Database Lab проверяет – были ли изменения в реплике с последнего созданного снимка, чтобы снимки не дублировались. Технически это реализовано через получение даты и времени из самого старого журнала предзаписи (первого WAL-файла) – если уже есть снимок с такой датой и временем, новый снимок не будет создан.
Причем Database Lab также может автоматически управлять всеми снимками, регулярно удаляя старые и неиспользуемые.
Наверняка у некоторых, кто сейчас смотрит на приведенную на слайде схему, возникает вопрос: а что с конфиденциальными и персональными данными?
Можно использовать готовые расширения PostgreSQL для анонимизации – например, PostgreSQL Anonymizer.

Либо воспользоваться возможностью выполнять перед созданием снимка произвольные SQL-запросы или скрипты, в которые вложена логика удаления или маскирования конфиденциальной информации.
Как вы уже, наверное, обратили внимание, абсолютно все настройки хранятся в одном конфигурационном файле (~/.dblab/engine/configs/server.yml) – помимо прочего, здесь задается расписание для создания новых снимков, а также максимальное количество снимков, которые необходимо хранить.
В нашем случае новый снимок создается каждую ночь, но можно указать и чаще – например, раз в час. В этом случае необходимо будет уменьшить объем хранимых журналов предзаписи, WAL-файлов (параметр wal_keep_size). Мы храним 20 ГБ WAL файлов, чтобы создавать снимки ежедневно.
Если ежедневно создавать новый снимок и в настройках указать, что нужно оставлять пять последних снимков, то у разработчиков будет возможность создать копию на любой из последних пяти дней. Это может быть полезно для сравнения – чтобы посмотреть, что было до обновления и как стало после.

Все созданные снимки отображаются в веб-интерфейсе. Здесь видно:
-
дату и время, на которое они зафиксированы;
-
сколько копий поднято на основании каждого из снимков;
-
и их физический размер – это разница между снимком и репликой, которая всегда бежит вперед. По нашим экспериментам, когда мы оставляли снимок для базы в 5 ТБ на пять месяцев, его размер за это время вырос до 50 ГБ.
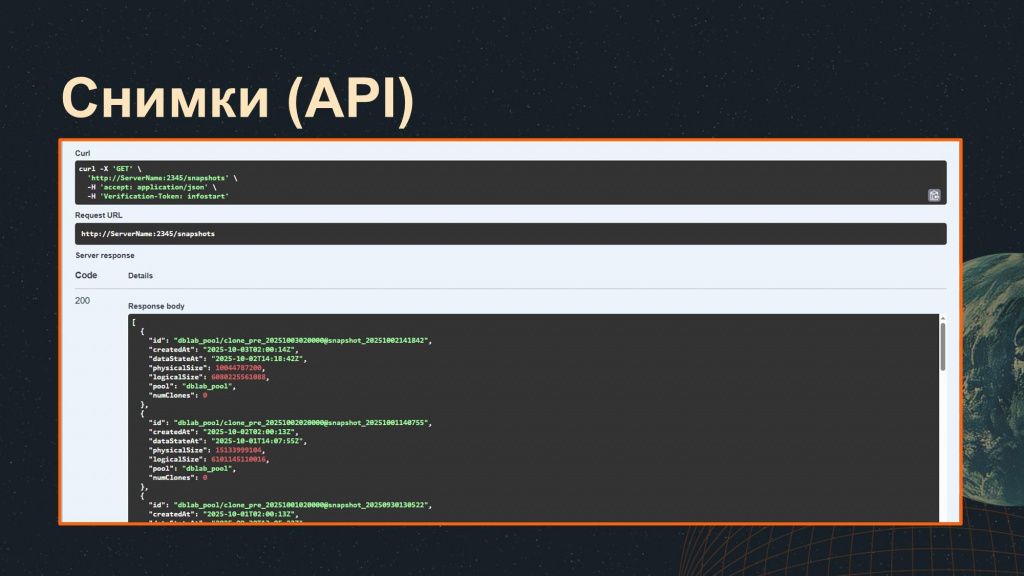
API и командная утилита, которые поставляются в Database Lab «из коробки», также позволяют получать всю необходимую информацию о созданных снимках.
Отмечу, что в релизе 3.5 снимок создавался при старте сервиса или по расписанию, а в новой версии 4.0, вышедшей в 2025 году, появилась возможность создавать снимки в любой момент – это дает свои преимущества, о которых я расскажу чуть позже.

На основании снимков разработчики могут создавать себе «клоны» – одну или несколько редактируемых копий.
Клон – это по факту новый кластер PostgreSQL, работающий в Docker-контейнере на отдельном порту. Порты выделяются автоматически из диапазона, который можно также изменить в конфигурационном файле. При старте контейнера автоматически запускается и служба PostgreSQL, что гарантирует, что при внезапной перезагрузке сервера данные копий никуда не пропадут.
Неиспользуемые клоны точно так же, как и снимки, могут удаляться автоматически. Неиспользование клонов определяется по отсутствию соединений и отсутствию активности – для этого анализируется pg_stat_activity.

Вот так выглядит создание клона (копии 1С) из веб-интерфейса.
Разработчик может выбрать себе снимок, на основании которого будет создана копия 1С – по умолчанию там всегда стоит самый последний актуальный снимок.

Также у разработчиков появляется возможность самостоятельно задать логин и пароль для доступа к кластеру PostgreSQL с копией.
Во-первых, это гарантирует, что никто другой даже случайно не попадет в вашу копию и не сделает там ничего.
С другой стороны, это позволяет разработчику подключаться к кластеру PostgreSQL через pgAdmin, чтобы:
-
посмотреть текущие соединения к СУБД и при необходимости удалить зависшие;
-
посмотреть, какие запросы выполняются в данный момент в базе;
-
посмотреть план запроса – предварительный или фактический;
-
покрутить настройки кластера, что может пригодиться для оптимизации.

Каждую копию можно пометить как защищенную, и тогда она не будет удаляться автоматически, даже если с ней уже никто давно не работает.
Но тут необходимо учитывать, что если клон помечается как защищенный, то соответственно и снимок, на основании которого создан клон, не будет автоматически удаляться. А это может привести к тому, что свободное место на диске будет постепенно заканчиваться.
По нашей статистике размер одного клона редко когда превышает 5 ГБ, ведь после выполнения задачи разработчики актуализируют клон или просто удаляют его.
На слайде также видно исходный размер базы реплики и ожидаемое время создания копии – в нашем случае клонирование базы занимает менее двух секунд.

А вот так выгладит веб-интерфейс для управления созданным клоном.
При использовании тонкого клонирования у разработчиков появляется право на ошибку. Они могут в любой момент за считанные секунда сбросить свою копию к первоначальному состоянию. При этом даже не обязательно закрывать 1С. Восстановление настолько быстрое, что соединение не успевает потеряться.
Еще очень удобно, что с любого клона копии тоже можно сделать снимок и на его основании поднимать новые клоны.
После всех экспериментов, когда копия уже не требуется, разработчик может ее самостоятельно удалить.
Обратите внимание, что в правой части интерфейса выводятся команды, которые можно использовать для управления клонами через командную утилиту.

API также предоставляет возможность управлять клонами. Здесь можно:
-
создать новый клон;
-
переопределить снимок, на основании которого он был создан;
-
сбросить к первоначальному состоянию;
-
получить информацию о клоне;
-
или удалить его.

Добавление клона базы 1С на сервер приложений ничем не отличается от добавления обычной базы 1С – за исключением того, что каждый клон работает на своем собственном порту, и этот порт необходимо указывать в поле «Сервер баз данных» после имени сервера.
Важно также сделать следующее:
-
На сервере приложений 1С – открыть для клонов сетевой доступ к портам (6000-6099).
-
В конфигурационном файле Database Lab – указать в значении параметра cloneAccessAddresses имя или IP-адрес вашего сервера приложений 1С, чтобы разрешить ему подключение к кластерам PostgreSQL с копиями баз 1С.

Состояние сервиса Database Lab можно мониторить с помощью веб-интерфейса.
На главной странице можно видеть:
-
Список всех созданных клонов – их размер, кто их создал, когда создал, порт, на котором они работают.
-
Состояние сервиса.
-
Дисковое пространство – сколько всего места выделено для ZFS pool, сколько уже места использовано и сколько еще осталось.
-
Количество созданных снимков – отображается дата самого старого снимка и актуального снимка. Благодаря этому мы можем увидеть, например, что у нас не создаются новые снимки, хотя должны каждый день создаваться.
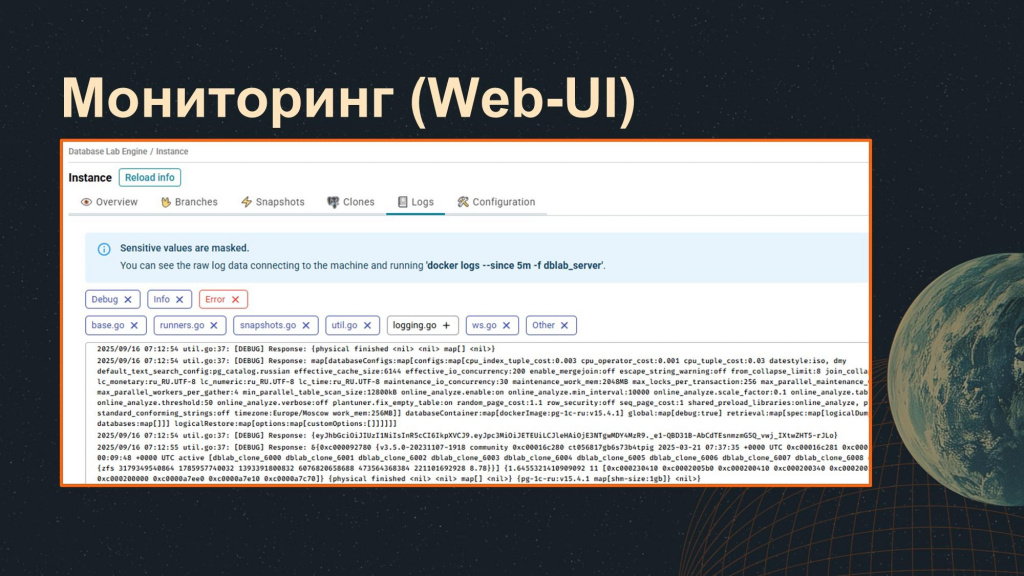
На странице Logs выводятся все логи основного контейнера. Конечно, можно и в консоли написать команду
docker logs <имя контейнера>
Но здесь удобнее – можно поставить фильтры (допустим, посмотреть только ошибки) и получить всю необходимую информацию.
Точно так же информацию о состоянии Database Lab можно получать через API и командную утилиту.

А для автоматизированного мониторинга Database Lab в режиме реального времени можно использовать уже готовый плагин к приложению Netdata – инструкция по подключению плагина также выложена на GitLab.
Плагин содержит уже готовые дашборды и оповещения (их список приведен на слайде), которые при желании можно изменить или дополнить.
Удобно еще то, что приложение NetData, как и DataBaseLab можно запускать в отдельном docker-контейнере – при этом никаких зависимостей на сервер тащить не надо.
Варианты применения технологии тонкого клонирования

При использовании Database Lab появляется ряд дополнительных возможностей.
Например, оптимизация запросов – я уже упомянул, что разработчики могут подключаться к кластеру PostgreSQL напрямую и смотреть планы запросов. Чтобы план запроса в копиях показывал те же значения, что и на оригинальной базе, нужно настроить параметры PostgreSQL для клонов такими же, как и в оригинальной базе. Для этого с помощью запроса (взят из официальной документации) получаем параметры, которые влияют на выполнение запросов и помещаем их в секцию databaseConfigs конфигурационного файла Database Lab.
После этого при создании каждой новой копии указанные параметры будут автоматически применяться к кластеру.

Помимо того, благодаря тонкому клонированию:
-
Можно ускорить процесс дымового или сценарного тестирования за счет получения копий за считанные секунды вместо ожидания восстановления базы из архива (dt-файла) или копирования эталонной базы для тестов.
-
Можно в любой момент времени получить актуальную копию базы, что позволяет разработчику быстро разбирать инциденты или отлаживать ошибки (ведь вряд ли кто-то на продуктиве даст вам включить отладку). Причем копия делается так быстро, что у вас сразу несколько разработчиков или команд могут заняться решением проблемы, если она настолько критична и важна.
-
Можно организовать нагрузочное тестирование. Но здесь важно учитывать, что оценка времени не будет достоверной, потому что для полноценного нагрузочного теста нужен выделенный сервер, сопоставимый по характеристикам с боевым. А если у вас на одной машине одновременно несколько клонов, результаты не будут сопоставимы.
Преимущества, которые мы получили после внедрения Database Lab

Итак, что же мы получили в конечном итоге, когда внедрили и начали использовать Database Lab:
-
Эффективное использование бюджета. Десятки независимых копий могут работать на одной машине и не требуют много места. Например, для 11 копий базы на 5 ТБ хватает одного диска на 3 ТБ, при этом с запасом.
-
Экономия времени на подготовку тестового окружения. Теперь разработчикам не требуется идти с запросами по актуализации копий к администраторам или сопровождению – снимки создаются автоматически. У разработчиков есть инструмент, который позволяет работать с копиями баз самостоятельно, а неиспользуемые снимки и копии удаляются автоматически.
-
У каждого разработчика теперь столько копий, сколько ему требуется. Тем самым мы избавляемся от проблем и конфликтов, возникающих, когда все тестируют на одной общей базе. У разработчиков появляется полная свобода действий – можно самостоятельно в любой момент вернуть копию к первоначальному состоянию, создать себе новую, сделать несколько копий или проводить эксперименты на копии клона.
-
Риск переноса ошибок в продуктив минимизируется, благодаря тому, что мы теперь ведем разработку на актуальной конфигурации с реальными данными.
-
Тестирование на полноценных данных позволяет нам быстро выявлять проблемы и устранять их еще на этапе разработки.
Делайте среду разработки и тестирования удобной для себя!
Вопросы и ответы
Существуют ли ограничения для клонов – например, по размеру или масштабным изменениям структуры базы? Могут ли клоны замедлять работу тестового сервера и влиять на других разработчиков?
Согласно нашей статистике, размер клона редко превышает 5-10 ГБ. Даже если вы сделаете полную реструктуризацию, при наличии достаточного свободного места на сервере никаких ограничений нет.
Обычно разработчик завершает задачу, сбрасывает клон в исходное состояние или удаляет его и создает новый. А поскольку одновременно у нас работает примерно десять разработчиков, нагрузка минимальна.
Если количество разработчиков вырастет, лучше добавлять новые серверы, а не увеличивать число клонов на одном.
Технология Copy-on-Write предполагает, что большое количество снимков увеличивает нагрузку на систему. Поэтому оптимально распределять команды по отдельным серверам. Но фактически ограничения определяются только характеристиками вашего сервера и тем, какой объем дискового пространства вы на него можете выделить.
Может ли производительность клона ухудшаться, если он существует долгое время?
Да, со временем производительность может снижаться, поэтому мы стараемся делать клоны, которые живут недолгий период времени. Для этого есть автоматическое удаление неиспользуемых клонов: если в течение недели с клоном никто не работал, он будет удален автоматически.
Есть ли опыт использования подобного подхода с MS SQL?
Теоретически, начиная с версии 2017 MS SQL можно развернуть на Linux и использовать технологию Copy-on-Write. Так же существует коммерческий продукт Delphix.
Что произойдет, если контейнер с управляющим ПО Database Lab выйдет из строя?
Для репликации используются встроенные средства PostgreSQL, которые передают данные в облачное хранилище, поэтому сами данные не исчезнут. Даже если управляющий контейнер временно недоступен, уже развернутые базы продолжат работать. И даже после внезапной перезагрузки сервера все контейнеры с копиями поднимутся автоматически.
Вы сказали, что клоны обычно занимают около 5 ГБ. Будет ли расти их размер, если изменять данные и конфигурацию?
Да, клон увеличивается пропорционально объему внесенных изменений. Работа ведется по принципу диффов: все, что отличается от исходного снимка, увеличивает объем клона. Добавили одного пользователя – клон вырос на данные об одном пользователе. Полностью обновили ERP, провели реструктуризацию – клон увеличится на соответствующий объем.
Обычно разработчикам нужно несколько копий баз. При этом они работают с исходниками конфигурации через хранилище или Git. Но если каждый день создаются новые снимки и разработчики запускают множество копий, не будет ли это создавать сложности с синхронизацией?
Разработчик создает клон уже с актуальной конфигурацией и реальными данными. Далее он накатывает свои изменения, обновляет конфигурацию, проводит тесты. Если позже появляется новый снимок, старые клоны автоматически не обновляются. Но разработчик может вручную сбросить свой клон - пересоздать его от нового снимка.
Система поддерживает несколько «голдов», и разработчик сам выбирает, на основе какого из них создать клон. Пока этот голд жив, его клон жив.
Пробовали ли вы экспериментировать с CI/CD? Например, при создании ветки в GitLab автоматически разворачивать окружение на основе клона?
Пока мы управляем этим вручную, но концептуально для дымовых или сценарных тестов через Jenkins или GitLab CI это легко автоматизировать.
Вы говорили, что вы моментально делаете слепок конфигурации от основного сервера, а потом через хранилище натягиваете на него ту конфигурацию, которая у нас сейчас захвачена. Но вам же приходится в этот момент переподключаться к хранилищу, а это не быстро – к нашей базе в 2 терабайта хранилище подключается больше часа. Как вы это решаете?
Здесь принцип тот же, что и при развертывании базы из бэкапа. Сама база создается мгновенно, но вся последующая работа (подключение к хранилищу, сравнение конфигураций и т.д.) выполняется так же, как и при обычном развертывании.
Разница в том, что благодаря ZFS и технологии копирования при записи вместо нескольких копий по 5 ТБ вы фактически имеете одну полную копию и набор диффов.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.
Вступайте в нашу телеграмм-группу Инфостарт
