Хочу рассказать о том, как начать работать с вашими данными без опыта программирования. При этом необязательно ограничиваться только логами – мы рассмотрим подход, с помощью которого можно обрабатывать абсолютно любые данные: банковские выписки, выгрузки из внешних систем, текстовые файлы и многое другое.
Эволюция мониторинга
Начнем с того, как в компаниях обычно развивается мониторинг – какие задачи он решает параллельно с ростом ИТ и самой компании.
-
На начальном этапе все довольно просто: мы заходим на сервер и смотрим диспетчер задач – оцениваем текущее состояние, загрузку ресурсов и основные метрики.
-
Со временем инфраструктура и нагрузка растут, и у нас возникает потребность хранить метрики во времени, чтобы анализировать исторические данные и разбирать инциденты – понимать, что происходило с системой в прошлом.
-
Когда серверов становится много, появляется потребность хранить метрики централизованно. Вручную подключаться на каждый сервер неудобно, поэтому нужные нам показатели начинают передаваться в единую систему – обычно это Zabbix, Prometheus и другие аналоги.
-
Но со временем и этого становится мало. Мы начинаем задумываться о том, откуда бы еще получить полезную информацию о состоянии системы. И как раз приходим к мысли о централизованном хранении и обработке логов. В логах содержится огромное количество полезной информации о том, как «живет» система: какие процессы в ней выполняются, и какие ошибки возникают.
Какие логи есть у 1С-систем
А системы 1С действительно могут предоставлять нам самые разнообразные логи:
-
В первую очередь – привычный нам журнал регистрации, где отражаются действия пользователей: создание и проведение документов, открытие форм и другие операции. Вы наверняка с этим давно знакомы и умеете работать.
-
Следующий пласт логов, которые генерирует 1С-система – технологический журнал, где мы можем отслеживать внутренние события платформы, запросы к СУБД и работу серверных компонентов.
-
Кроме логов самой 1С, можно собирать логи с СУБД – PostgreSQL и MS SQL Server ведут собственные логи, и мы их тоже можем анализировать. Особенно важно отслеживать DDL-события: создание таблиц и удаление индексов, сопутствующие изменению структуры базы. Иногда такие операции выполняются без ведома администраторов и за этим обязательно нужно наблюдать.
-
Отдельный источник информации – это логи операционной системы, где можно отследить действия системных утилит, удаления файлов и аварийные завершения процессов. Эти данные тоже полезно централизованно собирать и хранить.
-
Ну и наше ИТ не стоит на месте – мы идем в ногу со временем, и в наших 1С-системах неожиданно появляются docker-контейнеры, а у них тоже есть собственные логи.
-
Современную 1С-систему практически невозможно представить себе без веб-сервера – Apache или IIS. В логи веб-сервера тоже иногда полезно смотреть, потому что он может возвращать ответы, которые не ожидает другая система, и без логов в этом будет сложно разобраться.
-
И, конечно же, интеграционные решения – например, 1С:Шина. Это отдельный программный продукт, но через него происходят обмены в экосистеме 1С. И если данные теряются – как это расследовать? Поэтому собираем логи и смотрим.
-
Сюда же относятся и брокеры сообщений, которые часто используются для обмена между системами 1С – они тоже генерируют собственные логи.
Получается, что работа наших систем 1С зависит от большого количества различных компонентов, и все они пишут логи. Отсюда следует ряд проблем:
-
Разные форматы. Одни системы пишут логи в JSON, другие – в XML, третьи используют собственные форматы, как, например, в 1С. Это создает дополнительные сложности при обработке и анализе данных.
-
Разные системы для хранения логов. Часть логов мы можем анализировать через полнотекстовый поиск, а другие логи, наоборот, строго структурированы – по ним удобно строить четкие фильтры, и под такие данные часто выбираются совсем другие хранилища.
-
Большой объем данных. У нас генерируется огромное количество логов – некоторые системы могут даже не справляться с таким объемом потока данных.
-
Большие требования к производительности. Разбор логов, их транспортировка и обработка – все это требует ресурсов и времени. Поэтому крайне важно стараться на этом экономить.
Vector. Что это такое и какие проблемы решает
Именно здесь на сцену выходит инструмент, который позволяет решить большинство этих задач – Vector.
-
Vector – это open-source решение. Его можно свободно использовать как в личных, так и в коммерческих проектах.
-
Vector отличается высокой производительностью: благодаря тому, что он написан на Rust, по многим бенчмаркам он превосходит аналоги и при этом экономно расходует ресурсы.
-
Vector обладает большим количеством возможностей – в нем реализовано множество различных блоков и сценариев обработки данных.
-
А еще он легко масштабируется и гибко настраивается.
Подробнее обо всем этом мы сейчас и поговорим.

В качестве сквозного примера для использования Vector мы будем рассматривать разбор логов синтаксической проверки SonarQube – у нас есть набор логов, из которых нужно получить отдельные блоки, выделенные на слайде зеленым цветом. Эти блоки часто повторяются, и наша задача – понять, на какие операции уходит больше всего времени.
В каждой такой записи нас интересуют:
-
время начала события;
-
уровень логирования;
-
название события – что именно выполнялось;
-
и самое интересное – длительность этого события (time).
Рассмотрим, как этот пример логов можно разобрать с помощью Vector.

Начнем с источников данных. Vector умеет получать данные из множества различных источников – у него 45 механик получения данных.
-
Самый базовый вариант – чтение из файла. Логи чаще всего пишутся именно в файлы: в формате JSON или любом другом текстовом виде. Vector отслеживает изменения в файлах и понимает, какие записи уже были прочитаны и обработаны, а какие появились недавно – подходит к обработке экономно и анализирует только новые данные.
-
Следующий механизм – Exec. Вы можете выполнить любую абсолютно команду в системе, и передать результат ее выполнения на вход Vector’у. Частый пример использования – запуск утилиты rac, которая подключается к кластеру 1С и получает данные по количеству сеансов, а Vector при необходимости эти данные обрабатывает и отправляет дальше. Разумеется, вместо rac здесь может использоваться и любая другая команда.
-
Vector может также выступать в роли HTTP-клиента: он отправляет запрос к HTTP-сервису и использует ответ как входные данные. Либо, наоборот, работать как HTTP-сервер – принимать данные от других систем через вебхуки, настроенные на стороне отправителя с определенной периодичностью.
-
Отдельно стоит отметить возможность передачи данных от одного Vector к другому. К этому сценарию мы еще вернемся позже – он особенно полезен при масштабировании.
-
Кроме того, Vector умеет работать с Kafka – забирать данные из очереди, обрабатывать и отправлять куда-то дальше. Дальше расскажу подробнее, как это можно использовать на практике.
-
Точно так же Vector может работать с очередями брокеров сообщений AMQP.
-
И еще один распространенный источник – Syslog, стандартный механизм логирования в Unix-системах.
Обо всех остальных механизмах получения данных вы можете прочитать в документации Vector. На сегодняшний день доступно 45 способов, и с каждым годом их становится еще больше.

Давайте разберем получение данных на нашем примере. Напомню, мы работаем с логами SonarQube.
Первым шагом нам нужно прочитать данные. Для этого мы описываем блок source:
-
говорим, что источник данных – файл
type: "file" -
просим читать файл с самого начала
read_from: "beginning" -
и в параметре include задаем путь к файлу, откуда будут читаться логи – причем в этом пути можно использовать маски и переменные.
Всю эту информацию мы оборачиваем в произвольное имя источника – в данном случае, в блок my_sonar_logs. Это наименование можно выбрать любым и затем использовать дальше при построении пайплайна обработки. В дальнейшем я как раз покажу, как мы к нему обращаемся.

После того как данные получены, с ними нужно что-то сделать – просто так читать логи, как правило, бессмысленно. У Vector есть 59 механик отправки данных:
-
Самый простой вариант – вывод в консоль. Обычно этот вариант используется для отладки: Vector читает данные из файла, обрабатывает их и выводит результат в консоль. На продуктиве это почти не применяется, но для отладки – очень удобно.
-
Самый распространенный вариант для продуктива – это запись в другой файл. Vector может трансформировать данные и сохранять их в другом формате: JSON, CSV, XML и многие другие форматы «из коробки». Никаких сложных настроек не требуется – достаточно просто указать, куда записывать.
-
Еще Vector может отправить данные через HTTP-запрос. Это особенно удобно, если нужно интегрироваться с системой, для которой нет готового коннектора – в этом случае можно просто отправить в нее результаты предыдущих этапов обработки HTTP-запросом. Примеры такого использования я тоже покажу.
-
Vector может отправить полученные данные в другой Vector – это логично, раз может получить из другого Vector, значит, отправить тоже может.
-
И, конечно, Vector поддерживает отправку данных в стандартные хранилища логов – такие, как Clickhouse, Elasticsearch, OpenSearch, Loki и другие популярные решения.
-
А еще Vector может отправить данные в Kafka – мы уже говорили, что он может прочитать данные из очереди, и отправить в очередь тоже может.
В документации Vector вы можете прочитать про все доступные 59 механик отправки подробнее.

Итак, после того как мы данные получили, разобрали и хотим отправить, добавляем блок sinks – именно он отвечает за отправку данных:
-
Оборачиваем настройки отправки в блок с произвольным названием – в данном случае, my_console_debug.
-
Указываем, что будем выводить результаты в консоль, чтобы отладить и посмотреть, что он там вообще выдает
type: "console" -
В параметре inputs указываем результаты предыдущего блока
inputs: ["my_sonar_logs"]
Таким способом можно строить очень глубокие сложные пайплайны – добавлять неограниченное число этих блоков и на вход одного блока подавать результаты предыдущего блока. -
И в качестве кодека энкодинга указываем JSON – чтобы вывод был в человекочитаемом формате.
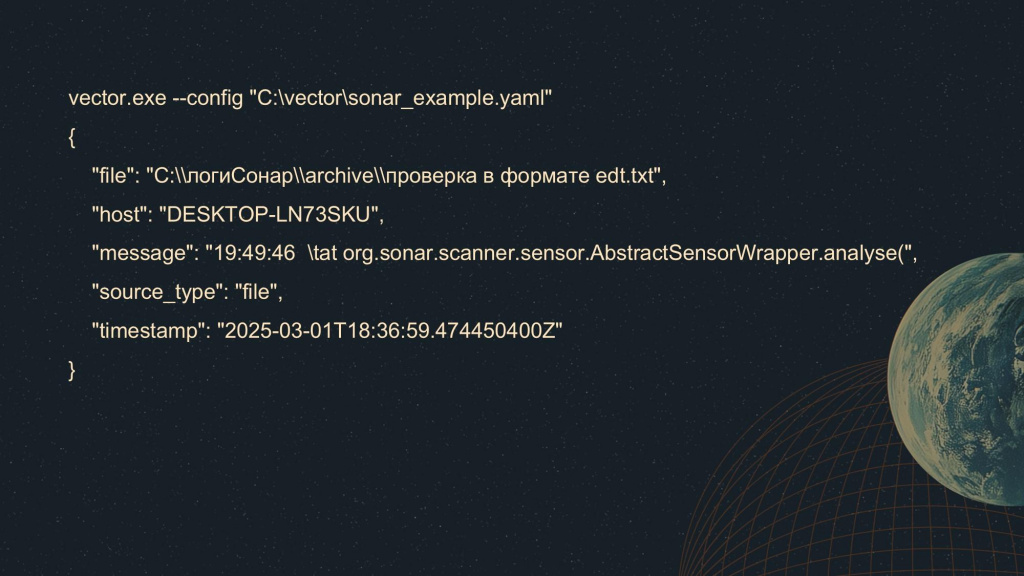
После этого запускаем Vector, передав ему путь к конфигурационному файлу, который мы сформировали выше.
В результате мы увидим в консоли JSON с базовым набором полей, которые Vector формирует автоматически:
-
file – файл, откуда были прочитаны данные;
-
host – имя компьютера, на котором запускался Vector;
-
message – само сообщение, которое он прочитал;
-
source_type – тип источника, в данном случае видно, что мы читали данные из файла;
-
timestamp – момент, когда данные были считаны.
Однако такого набора нам, как правило, недостаточно. Нам нужно разобрать поле message – извлечь из него полезную информацию, и уже в таком виде отправлять данные дальше.

Для этого у Vector предусмотрено 15 механик трансформации. На первый взгляд может показаться, что это немного по сравнению с количеством механик получения и отправки данных, но на практике – более чем достаточно.
-
В самом простом варианте мы добавляем блок с типом «remap», внутри которого можно использовать инструкции на специальном языке VRL (Vector Remap Language). В этом языке предусмотрено множество встроенных функций, которые работают очень быстро, поскольку реализованы на Rust. С их помощью можно выполнять разбор строк по регулярным выражениям, группировать данные, преобразовывать поля, выполнять различные логические операции и многое другое. Если какой-то функциональности вам не хватает, ее можно запросить у разработчиков Vector – новые возможности довольно оперативно добавляются и также реализуются на Rust.
-
Если же все-таки ждать обновлений не хочется, Vector поддерживает для трансформации использование языка Lua. Это уже совсем другой уровень гибкости: можно писать собственные функции, процедуры, реализовывать сложную логику обработки строк, использовать кэширование и создавать действительно нестандартные сценарии трансформации данных.
-
Еще из часто используемых механизмов трансформации можно отметить блок с типом «filter» – с помощью этого блока вы можете отфильтровать полученные данные по какому-то условию.
-
С помощью блока «aggregate» можно сагрегировать какие-то данные – суммировать для них числовые значения и отправить результат.
-
А с помощью блока «dedupe» – отсечь уже прочитанные данные, чтобы избежать дублирования данных. Это возможно благодаря тому, что Vector хранит в памяти уже обработанные записи и может не отправлять их повторно.
-
А с помощью блоков трансформации «log_to_metric» (из логов в метрики) и наоборот, «metric_to_log» (из метрик в логи) мы можем работать с метриками.
Все доступные механизмы трансформации описаны в документации Vector.

Вернемся к нашему сквозному примеру. Блоки source и sinks мы оставляем без изменений – они отвечают за получение и отправку данных. Самое интересное появляется в блоке transforms.
Здесь мы создаем блок «my_sonar_remap», где описываем настройки трансформации:
-
В качестве параметра «inputs» мы берем результаты предыдущего блока.
-
Указываем тип remap – это самый базовый и быстрый механизм трансформации, реализованный на Rust.
-
И внутри параметра «source» используем функцию «parse_regex» – это функция, которая производит выборку данных с помощью регулярного выражения.
-
На вход функции «parse_regex» мы передаем поле message (исходную строку лога) и в формате, похожем на grok, описываем, какие данные из него нужно получить – например, datetime, type и time.
-
Эти результаты будут помещены в поле «structure».
-
Если в результате выполнения этого регулярного выражения возникла ошибка, она запишется в поле «err». Если ошибки не было, в поле «err» останется null.
Дальше мы добавляем еще один блок – «my_sonar_filter».
-
В параметре «inputs» мы также подаем ему на вход результаты предыдущего блока.
-
Указываем тип – filter, просим отфильтровать
-
И в качестве условия (condition) задаем «err==null». Таким образом, в результат этого блока фильтрации попадут только те строки, которые подошли под наше регулярное выражение.

И на выходе мы получаем уже аккуратную и структурированную информацию – практически именно те данные, которые нам были нужны:
-
datetime, который мы хотели извлечь;
-
message, который перезаписался в результате выполнения регулярного выражения;
-
time;
-
и т.д.
И дальше мы можем вывести эту информацию не в консоль, а в файл – например, сохранить в формате CSV, чтобы дальше поработать с этим в Excel. Или сагрегировать, настроить отборы, трансформации и понять, где у нас была проблема.
Архитектурные схемы
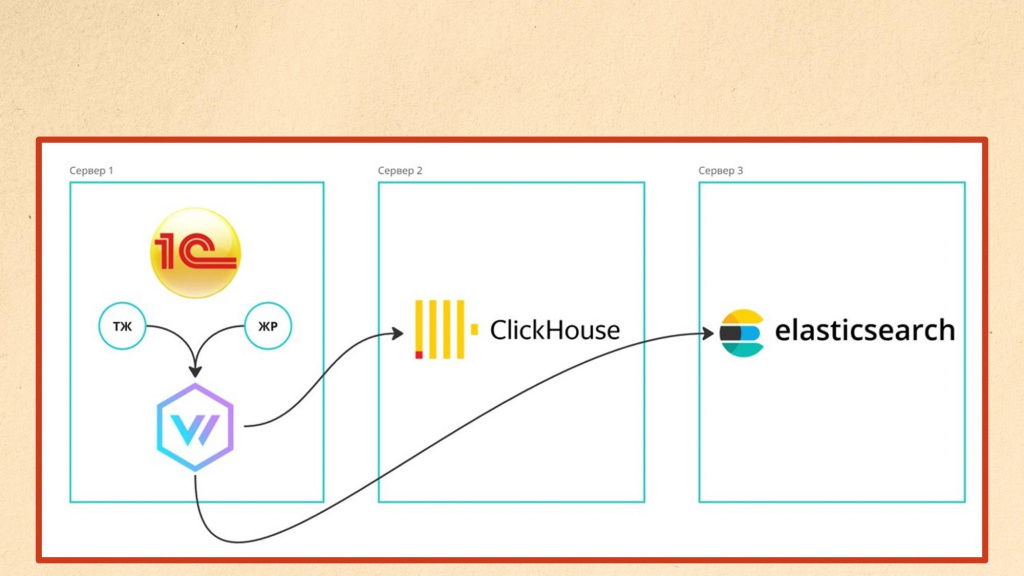
Давайте теперь рассмотрим варианты реализации архитектуры.
В самом простом и базовом сценарии – когда у нас нет экстремальной нагрузки и больших объемов логов – мы разворачиваем Vector непосредственно на той же машине, где находится сервер 1С. Указываем ему, где лежат журнал регистрации и технологический журнал, описываем правила обработки и говорим, куда отправлять данные. Это может быть Clickhouse, ElasticSearch или любая другая система для хранения логов. При необходимости можно отправлять данные сразу в несколько систем. Такая схема максимально простая и понятная.
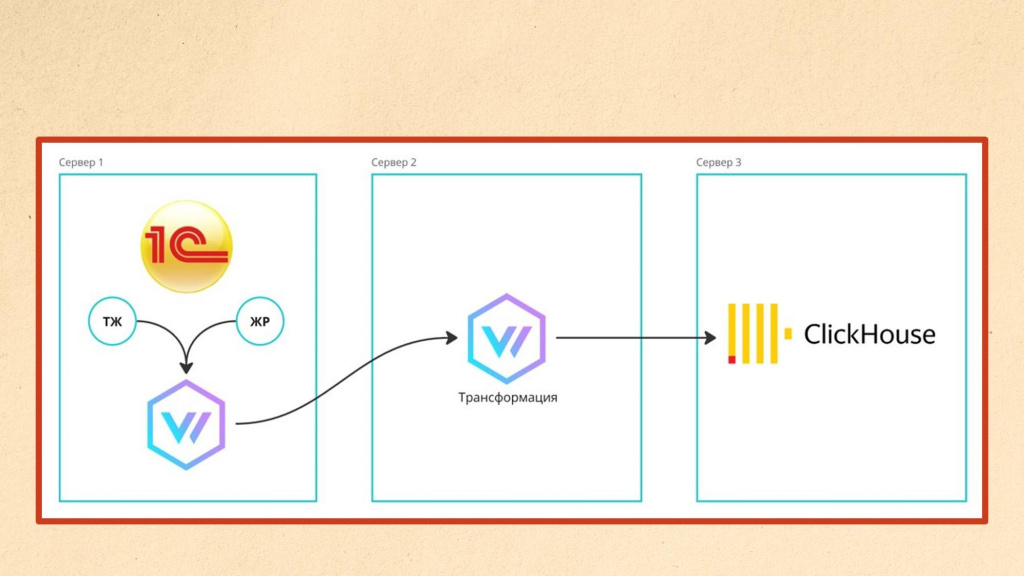
Если же трансформации становятся сложнее и начинают требовать заметных ресурсов, Vector позволяет легко масштабироваться.
Мы можем дополнительно добавить сервер трансформации и тоже развернуть на нем Vector, чтобы принимать данные от другого Vector’а, установленного на сервере приложения 1С.
При этом Vector на сервере приложения 1С выполняет максимально простую задачу – читает строки из логов и сразу отправляет их дальше. Такой режим работы очень быстрый, практически не нагружает CPU и не создает ощутимой нагрузки на сервер приложения. Вся тяжелая обработка логов переносится на сервер трансформации, где данные разбираются, а затем отправляются, например, в ClickHouse.
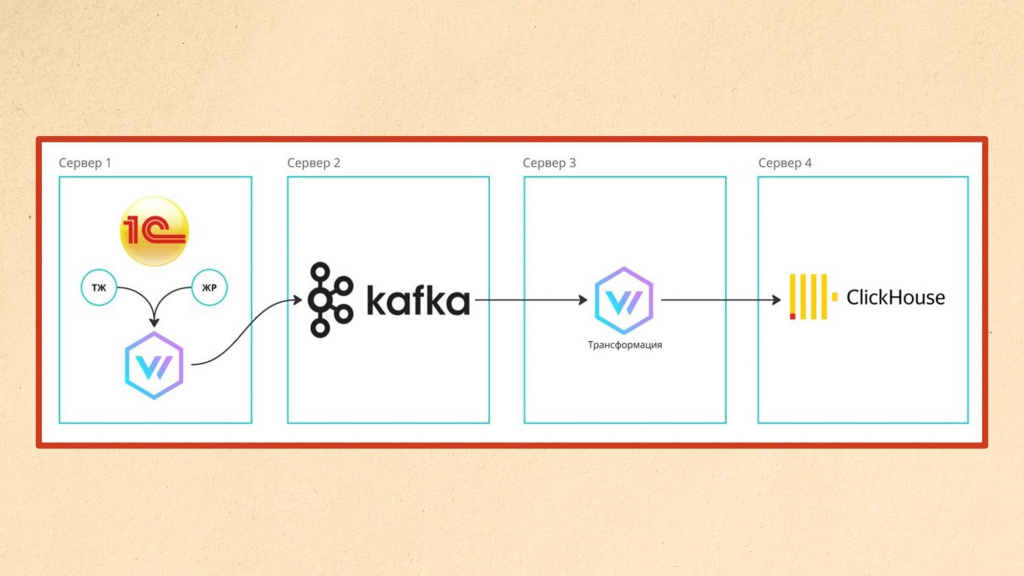
Если и этого оказывается недостаточно – например, источников логов становится слишком много, и даже сервер трансформации не успевает обрабатывать поток данных, появляются пропуски или троттлинг сообщений с логами, архитектуру можно масштабировать дальше. В этом случае добавляется еще один уровень – очередь.
Чтобы организовать очередь сообщений, на отдельный сервер устанавливается Kafka, которая очень быстро записывает и накапливает в себе данные. А отдельный сервер трансформации Vector эти сообщения оттуда потихоньку «выгребает» – с той скоростью, с которой он способен их обработать.
Если одного Vector не хватает, можно добавить еще один или несколько – они будут забирать данные из Kafka параллельно, увеличивая пропускную способность системы.

Отдельно стоит отметить, что Vector – кроссплатформенный инструмент. Его можно запускать практически везде: на Linux, Windows, macOS, в контейнерах, в Kubernetes, даже на «малинке» (Raspberry Pi) – все это поддерживается без проблем.
Особенно удобно, что Vector поставляется в виде одного исполняемого файла (single binary), который можно просто скопировать на нужную машину и сразу запустить без сложной установки и зависимостей.
Кейсы применения
В завершение хочу рассказать о практических кейсах использования Vector – приведу несколько интересных примеров.

Первый пример – разбор логов в формате JSON.
Большинство современных систем (например, PostgreSQL и даже платформа 1С с версии 8.3.25) могут писать свои логи в формате JSON.
На парсинг таких логов тратится минимальное количество ресурсов – мы просто указываем в блоке трансформации тип «remap» и в поле «source» используем метод «parse_json». В результате сразу получаем JSON как объект и можем дальше работать с его полями и отправлять данные, куда захотим.

Еще один пример – использование для получения данных механизма «exec». Он позволяет выполнять в системе произвольные команды, а результат их выполнения передавать на вход следующих шагов в Vector.
На слайде показан простейший пример – команда echo. Мы можем настроить расписание для ее периодического выполнения (по умолчанию интервал – 60 секунд), по истечении заданного времени команда будет запускаться, а ее результат – обрабатываться на следующих шагах пайплайна.

Еще один сценарий, который мы у себя довольно часто используем – это сохранение данных в CSV. Он тоже реализуется довольно просто:
-
указываем
type: file -
говорим, что на вход будем получать результаты предыдущего блока
inputs: [demo_logs] -
настраиваем вывод в CSV
encoding:
codec: 'csv' -
обязательно перечисляем поля, которые должны попасть в этот CSV
csv:
fields: [text, host] -
и указываем каталог, куда надо записать эти данные
path: '~\logs_to_file.csv'
После этого данные автоматически сохранятся в CSV и готовы для дальнейшего анализа, например, в Excel.

Далее – отправка данных в хранилище. Например, в ClickHouse. Здесь настройки следующие:
-
указываем тип
type: "clickhouse" -
задаем адрес нашего хранилища – обязательно с портом
endpoint: "http://clickhouse1c:8123" -
указываем базу данных, в которую будем отправлять результаты предыдущего блока, и таблицу, куда будет производиться запись
database: "logs"
table: "pg_json" -
при необходимости указываем параметры записи – пропуск полей и настройки даты
skip_unknown_fields: true
date_time_best_effort: true
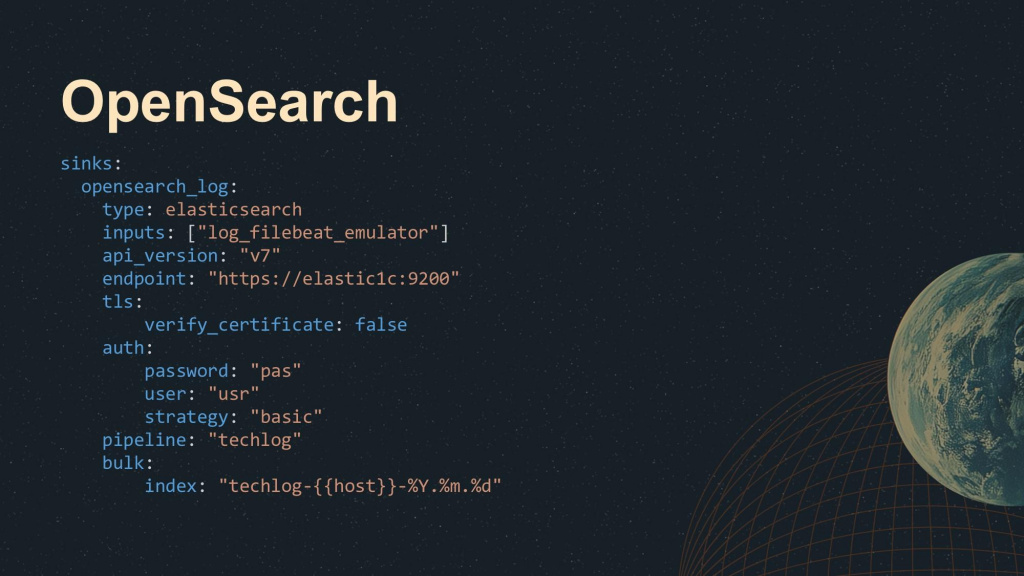
Для ElasticSearch и OpenSearch конфигурация тоже достаточно стандартная:
-
если вы используете OpenSearch, обязательно укажите седьмую версию API, иначе отправка данных в OpenSearch работать не будет
api_version: "v7" -
указываем адрес, куда будет отправляться запрос
endpoint: "https://elastic:9200" -
указываем параметры SSL-сертификата (доверять самоподписанному или нет)
tls:
verify_certificate: false -
указываем параметры аутентификации – для примера здесь указана базовая, но можно использовать любую другую
auth:
password: "pas"
user: "usr"
strategy: "basic" -
указываем имя пайплайна, который будет обрабатывать отправленные данные
pipeline: "techlog" -
и шаблон индекса, куда будут записываться эти данные
bulk:
index: "techlog-{{host}}-%Y.%m.%d"

Еще один популярный пример – отправка данных напрямую в Telegram:
-
для этого используем стандартный тип http
type: http -
предварительно стоит немного обогатить отправляемые данные, добавив в блоке transforms параметры чат-бота, который будет принимать информацию:
source: |
.chat_id=123456789
.bot_token="TOKEN" -
тогда мы можем использовать ранее определенные значения полей в URL запроса
url: "http://api.telegram.org/bot{{bot_token}}/sendMessage?chat_id={{chat_id}}"
Такой подход позволяет управлять отправкой уведомлений динамически – например, использовать разные чаты или группы.
Интересный вариант применения – можно разбирать логи EDT и отслеживать ход обновления проекта, получать об этом уведомления в Telegram.

И последний кейс, который я хочу показать – отправка ошибок в Sentry. Вы читаете журнал регистрации, получаете информацию об ошибках и сразу же через Vector отправляете их в Sentry.
Здесь тоже используется стандартный блок http, просто чуть сложнее настраивается тело запроса. Но в целом можно немного поэкспериментировать с комбинациями наборов полей и разобраться.
Vector – это производительно, просто, функционально
Хочу подытожить:
-
Vector – это производительно. Он написан на Rust, и встроенные методы языка трансформаций работают очень быстро. Рекомендуется в первую очередь использовать именно их. Если вам этого недостаточно, можете подключить Lua. Но не забудьте написать разработчикам – они быстро реализуют то, что вам нужно.
-
Vector – это просто. В большинстве случаев достаточно двух, трех или четырех блоков. Освоив их, вы сможете закрыть 98% типовых задач и счастливо с этим работать.
-
Vector – это функционально. Там 59 механик отправки и 45 механик получения, которые работают очень быстро. С помощью них можно реализовать много чего полезного.
Скачать настройки
В завершение делюсь с вами ссылкой на репозиторий, где представлены конфигурационные файлы для решения с помощью Vector следующих задач:
-
Отправки ТЖ < 8.3.25 в OpenSearch (в старом формате)
-
Отправки ТЖ в ClickHouse (в новом формате)
-
Отправки логов PostgreSQL в ClickHouse
Все это в готовом виде – копируйте, устанавливайте, используйте.
Вопросы и ответы
Вы сказали, что отправляете технологический журнал в OpenSearch в старом формате, и его текстовые строки парсятся через Vector. А почему не используете для сбора технологического журнала новый формат JSON – сейчас же можно получать логи из ibcmd через stdout сразу в JSON?
Для OpenSearch мы сознательно не стали переделывать пайплайн для поддержки нового формата, потому что у технологического журнала в виде JSON есть нюансы: например, довольно часто дублируются атрибуты.
Вообще вариант через JSON пробовали, сравнивали производительность – Vector оказался быстрее. И в случае использования ibcmd появляется два разных решения, которые по сути делают одно и то же: одно трансформирует, второе все равно подхватывается Vector’ом и отправляется дальше. Зачем усложнять, если все можно сделать в одном месте?
По поводу блока с трансформацией. Правильно ли я понимаю, что в Vector все конфигурационные настройки описываются в формате YAML, и сама трансформация тоже описывается в виде кода в этом же YAML-файле? Есть ли возможность вынести трансформацию отдельно, чтобы не «засорять» основной конфиг-файл?
Да, трансформацию можно вынести в отдельные файлы этого же формата и просто подключать их в основном конфиге.
Если выносить отдельный Vector в зону трансформации, какие ресурсы нужно заложить под его хост или виртуальную машину? Как вы определяете, сколько ресурсов нужно Vector’у для нормальной работы, если у нас, допустим есть один высоконагруженный сервер, с которого нужно забирать журнал регистрации и технологический журнал объемом порядка 100 ГБ в сутки?
Зависит от множества факторов. У нас сейчас колоссальный объем логов – больше 100 ГБ в сутки, система очень большая и высоконагруженная. Но машина, где развернут сервер приложений 1С, справляется – парсинг и трансформации у нас очень простые, нам хватает VRL, Lua не применяли. Все это работает очень быстро, и заметной нагрузки мы не видим. Конечно, мы рассматриваем варианты развития – добавление серверов-посредников, очередей и так далее – но на текущий момент в этом нет необходимости.
Вы мониторите сам Vector?
Нет. Он, конечно, это умеет: у него есть эндпоинт для мониторинга состояния, но мы пока до этого не дошли.
Почему-то в репозитории Vector актуальная версия до сих пор 0.х. Он все еще в бете или это у них такая политика версионирования?
Да, на GitHub действительно версия 0.x. Скорее всего, это просто их подход. Он уже давно на рынке, не думаю, что это реальная бета.
Если использовать два Vector’а так, чтобы один передавал данные в другой – насколько будет надежна эта передача? Теряются ли данные при проблемах? Я слышал, что он может троттлить и отбрасывать данные.
Да, такое бывает. У нас в компании даже есть коллеги, которые используют Vector не только в 1С-стеке – у них действительно возникал троттлинг.
Как раз для таких случаев и подходит вариант с отдельным сервером трансформации: чтобы быстро читать, трансформировать и отправлять дальше. Но чтобы Vector начал что-то терять, нагрузка должна быть действительно экстремальной.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт