Я поделюсь опытом разгона PostgreSQL под 1С:Предприятие в том виде, как это делаем мы и наши клиенты. В сфере ИТ я с 2010 года и за это время администрировал разные СУБД: Oracle, MS SQL, PostgreSQL. В свое время в одной из компаний я даже выступал инициатором перевода стенда с 1С:Предприятие на MS SQL, поскольку там действовал стандарт работы с Oracle, а с 1С:Предприятие он показывал себя не лучшим образом.
С 2021 года я работаю в СберТехе, в команде СУБД Platform V Pangolin DB. Это реляционная система управления базами данных, которая основана на свободно распространяемой версии PostgreSQL и содержит ряд доработок, позволяющих обеспечить соответствие повышенным требованиям к надежности, производительности, удобству эксплуатации и безопасности хранимых данных. СУБД применяется в высоконагруженных системах, в том числе массово используется с продуктами 1С. Эта статья о том, как благодаря глубокой оптимизации ядра, инструментам вроде Platform V Kintsugi (графическая консоль для сопровождения, разработки и диагностики СУБД) и flame graph, а также доработкам под 1С нам удалось добиться стабильной работы СУБД при нагрузке от 2400 одновременных пользователей. А также о том, как адаптировать систему под ключевые конфигурации 1С, и какие инструменты помогают находить и устранять узкие места в реальном времени.
В чем заключалась задача
В 2019 году в СберТехе появился собственный центр экспертизы и разработки, перед которым была поставлена задача создать независимую СУБД корпоративного уровня.
Команда выбрала PostgreSQL в качестве базового решения. За первый год мы доработали его до необходимого уровня кибербезопасности, внедрив новые функциональные возможности — прозрачное шифрование, защиту от привилегированных пользователей, парольные политики, — и приступили к дальнейшему развитию продукта и распространению в экосистеме Сбера.
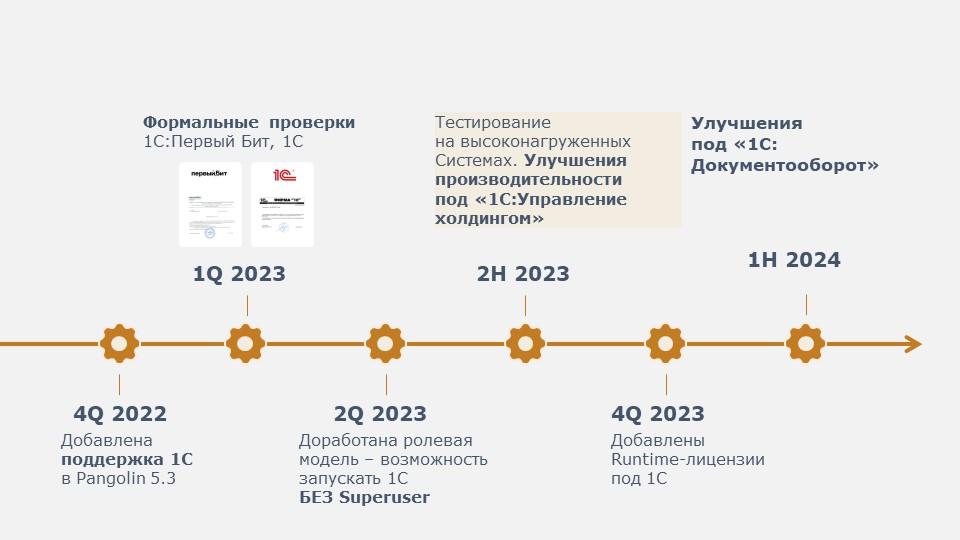
В какой-то момент стало очевидно, что нужно также поддерживать работу с 1С:Предприятие. С 2022 года эта поддержка появилась в СУБД Platform V Pangolin, а в 2023-м мы прошли первые формальные проверки совместимости с платформой, в том числе с компанией «Первый Бит». Подтвердили у «большого» 1С, что он нас поддерживает, и появились на странице системных требований 1С:Предприятия 8.
Мы продолжили развивать свою СУБД и отказались от суперпользователей. Это было важно для «гигиены безопасности» Сбера, так как суперпользовательских учетных записей в прикладных системах не должно быть в принципе. Мы также выполнили разделение привилегий. А когда начали проводить нагрузочное тестирование и реальные запуски, стало понятно, что существуют определенные сложности, вызванные особенностями работы платформы 1С:Предприятие, и связанные с этим узкие места в ядре PostgreSQL. Мы их последовательно локализовывали и оптимизировали.
Тестовый стенд и инструментарий для анализа производительности

Все инженеры любят конкретику, поэтому немного о стенде. Его помогала строить команда ИТ-экспертизы. Мы взяли достаточно мощный физический сервер из тех, что тогда были доступны в наших облаках. Развернули ферму из восьми серверов 1С и терминальные сервера.
Сначала казалось, что терминалы не нужны и можно обойтись скриптами, но быстро выяснилось, что 1С без них не работает, — приложения должны запускаться именно в терминальной среде. Таким образом, на выходе у нас получилось, что терминальные и 1С-сервера вполне корректно функционируют в виртуальной среде. Сервер баз данных при этом остался «железным». Так мы и начали работать.
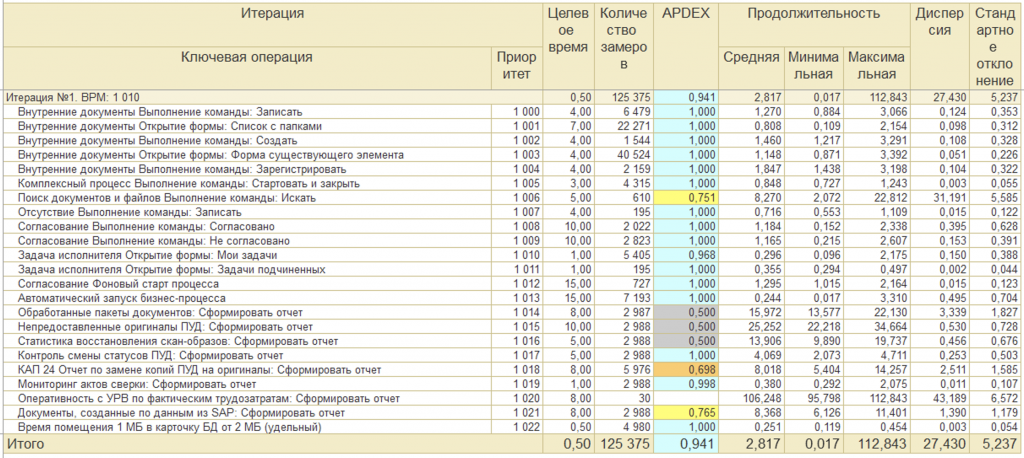
На прикладном уровне мы решили использовать тот же инструмент, что и клиенты, чтобы говорить с ними на одном языке. Таким инструментом оказался тест-центр одного из пакетов 1С, при работе с которым мы столкнулись с непонятным поначалу явлением под названием APDEX. Разобравшись, что это такое, мы выбрали наиболее объективный способ сравнения — среднее время выполнения операций и их среднее количество за единицу времени. Эти метрики удобны тем, что не зависят от исходных ожиданий касаемо времени выполнения и позволяют получить максимально объективную картину.

На уровне СУБД мы использовали целый набор инструментов. В первую очередь — расширение pg_profile, в которое мы внесли собственные доработки. Наверняка, те, кто работал с PostgreSQL, его знают.
Дополнительно применялись такие средства, как Performance Insights, трассировка сессий (аналог Profiler), а также традиционные встроенные механизмы вроде log_min_duration_statement и других аналогов для снятия нагрузки и анализа выполняемых операций.
Со временем мы написали собственный набор скриптов для мониторинга, так как сравнение с «ванильным» PostgreSQL и другими приложениями показало: стандартных инструментов нам недостаточно.
На самом низком уровне для анализа проблем в ядре мы использовали системные средства Perf и Flame Graph (на картинках это «оранжевые столбики»).
И, наконец, в какой-то момент у нас появился собственный инструмент Platform V Kintsugi — графическая консоль для управления СУБД, а также были добавлены возможности, позволяющие существенно сократить время на анализ аномального поведения продукта.
Возможности Platform V Kintsugi
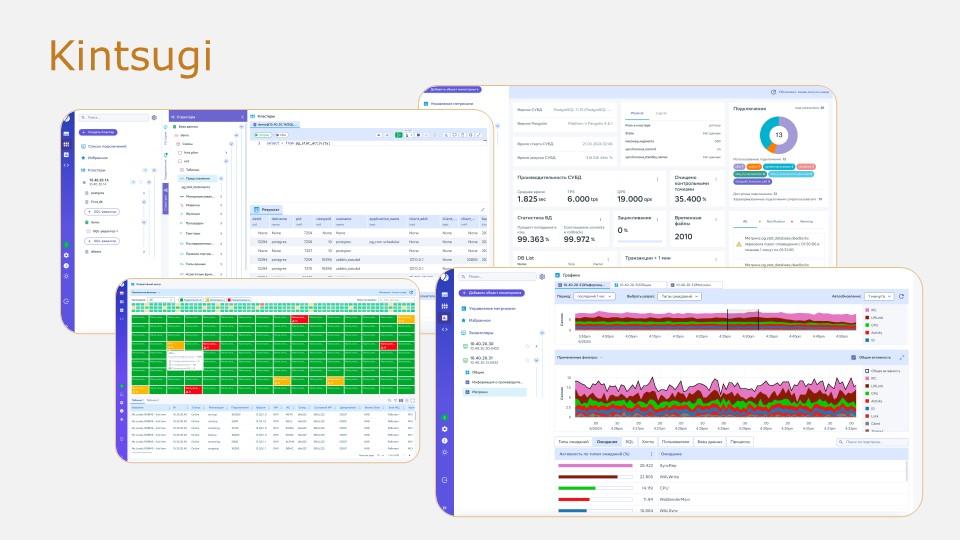
Platform V Kintsugi позволяет в реальном времени отслеживать текущую нагрузку на всю СУБД по кластерам и видеть, что именно происходит, например, с ожиданиями. При необходимости можно «провалиться» глубже: использовать фильтры по сессиям, блокировкам или хостам.
Кроме того, в Platform V Kintsugi есть функциональность, которая может заменить классического клиента, например, такие инструменты, как DBeaver или pgAdmin.
Инструмент масштабируемый: он поддерживает работу с любым количеством СУБД — от сотен до десятков тысяч. При этом инструмент не оказывает никакого влияния на работу самой СУБД.
Первые шаги по адаптации ядра под 1С
Теперь расскажу о том пути, который мы прошли.
-
Создание единого дистрибутива СУБД optimize_for_1c = 'on'
В первую очередь мы добавили поддержку на уровне ядра. Выяснилось, что патчи, публикуемые 1С, изменяют поведение PostgreSQL. Наша же изначальная задача заключалась в сохранении обратной совместимости, так как система предназначена не только для 1С, но и для замены «ванильного» PostgreSQL, а также Oracle и MS SQL. Поэтому изменения для 1С мы вынесли отдельно и реализовали их под специальным флагом optimize_for_1c.
-
Отказ от Superuser
Второе, что мы сделали, — отказались от использования суперпользователя. Оказалось, что в базовом варианте 1С:Предприятие не умеет без него работать: есть ряд привилегий, без которых система просто не запускается и даже не создает базы данных. Мы выделили необходимые права в отдельную роль, и это позволило безопасно эксплуатировать решение.
-
Настройка русской локали initdb --locale ru_RU.UTF-8
Следующая проблема, с которой мы столкнулись, оказалась для нас неожиданной. Несмотря на то, что приложение требует русскую локаль для своей работы, оно не умеет задавать ее при создании баз данных. Никакие настройки и обходные пути не помогли, поэтому в итоге мы пришли к простому решению — задавать нужную локаль сразу при инициализации кластера баз данных.
Мы взяли рекомендации от 1С, опубликованные на сайте разработчика. Они оказались достаточно релевантными: любые отклонения в ту или иную сторону не давали заметного прироста производительности. В итоге мы просто оставили настройки в том виде, в котором они были предложены.
Рекомендации от 1С:
shared_preload_libraries = 'plantuner'
plantuner.fix_empty_table = on
temp_buffers = 256MB
work_mem = 128MB
max_locks_per_transaction = 1000
max_files_per_process = 8000
random_page_cost = 1.1
geqo = 'on'
geqo_threshold = 12
row_security = 'off'
standard_conforming_strings = 'off'
escape_string_warning = 'off'
В то же время мы внесли ряд изменений в параметры, отклонившись от рекомендованных настроек.
Во-первых, оказалось, что 1С не умеет работать с безопасными методами аутентификации (например, SCRAM-SHA-256) без дополнительной настройки и приседаний, поэтому мы явно выставили MD5.
Во-вторых, параметры вроде collapse_limit в нашей конфигурации не имели смысла: при выставленных ГИКО thresholds = 12 значения больше 11 были избыточны, поэтому мы их просто убрали — для удобства и лучшего восприятия конфига.
И наконец, чтобы корректно обрабатывать большое количество соединений, мы увеличили параметр max_connections.
Дополнительно:
password_encryption = 'md5'
from_collapse_limit = 11 (20)
join_collapse_limit = 11 (20)
max_connections = 2500
Далее расскажу о тестах, которые мы провели и под которые впоследствии оптимизировали работу.
Тест 1: Управление холдингом и оптимизация работы с временными объектами
Первый тест был связан с 1С:Управление холдингом. На тест-центре коллеги из ИТ-экспертизы помогли построить сценарий продолжительностью около 8 часов с имитацией работы примерно 2400 одновременных сессий.
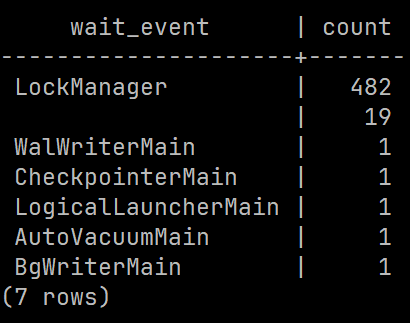
Первое, с чем мы столкнулись, — это высокая конкуренция при обращении к структуре LockManager. Со стороны клиентов 1С это проявлялось как ошибки: сессии не успевали получить блокировки, завершались по тайм-ауту и в итоге падали. Поэтому весь тест стабильно заканчивался сбоем и не мог считаться пройденным. Фактически это был фейл.
Мы начали разбираться и выяснили, что причиной стало огромное количество обращений к временным объектам: создавались временные таблицы, индексы, выполнялись сканы, наполнение, анализ и так далее. Оказалось, что ядро PostgreSQL не оптимизировано под столь интенсивную работу с временными объектами, и нам пришлось устранять эти узкие места.
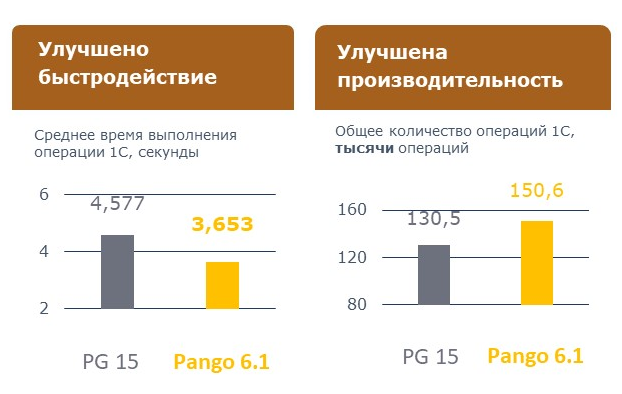
Мы оптимизировали работу с временными объектами и внесли изменения в ядро, так как добиться этого параметрами было невозможно. Любые попытки регулировать размер кэшей не давали результата.
В итоге мы получили хорошие показатели: на первых тестах улучшения составили более 50%. Позднее 1С включила часть подобных изменений в свои патчи для ядра, мы их подтянули и перепроверили. Эффект оказался чуть меньше, но все равно заметный. К тому же при дальнейшем росте количества одновременных обращений система не упиралась в потолок, и ее можно было продолжать масштабировать. То есть сейчас при увеличении числа ядер и пользователей мы не достигаем предельных значений.
Тест 2: Документооборот и борьба с блокировками при высокой нагрузке
Второй кейс, о котором я хочу рассказать, связан с 1С:Документооборот. Он оказался проще предыдущего. Тест проводился также в тест-центре, продолжительность составила около трех часов.
В базовом сценарии, аналогичном тому, что использует клиент, запускалась примерно тысяча одновременных соединений. Затем мы постепенно повышали нагрузку, проверяя пределы системы: 1500, 1800, 2000 и до 2500 соединений. При увеличении нагрузки свыше полутора тысяч соединений (примерно на уровне 1800) мы столкнулись с тем, что тесты на всех доступных нам форках, включая Platform V Pangolin DB в тот момент, завершались с ошибками и упирались в блокировки на уровне СУБД. Фактически происходило «ожидание блокировок на блокировки», что приводило к общему зависанию.
По результатам анализа flame graph выяснилось, что основная причина заключалась в конкуренции при разборе большого количества многоузловых запросов (механика этого процесса довольно сложная, не буду о ней подробно рассказывать) и интенсивного I/O.
В этом кейсе нам удалось получить несколько наглядных скриншотов из Platform V Kintsugi. Мы активно использовали этот инструмент, чтобы визуально контролировать процесс, в том числе ретроспективно. Это оказалось особенно полезно, ведь трехчасовой тест сложно разбирать только по логам.
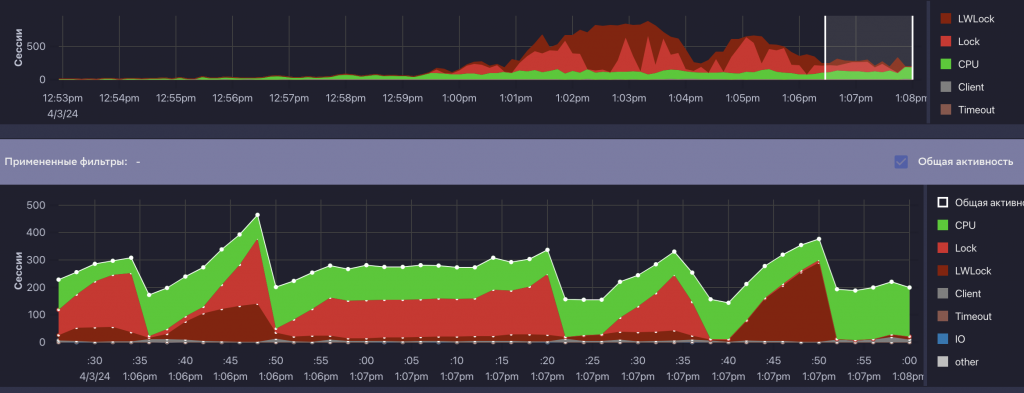
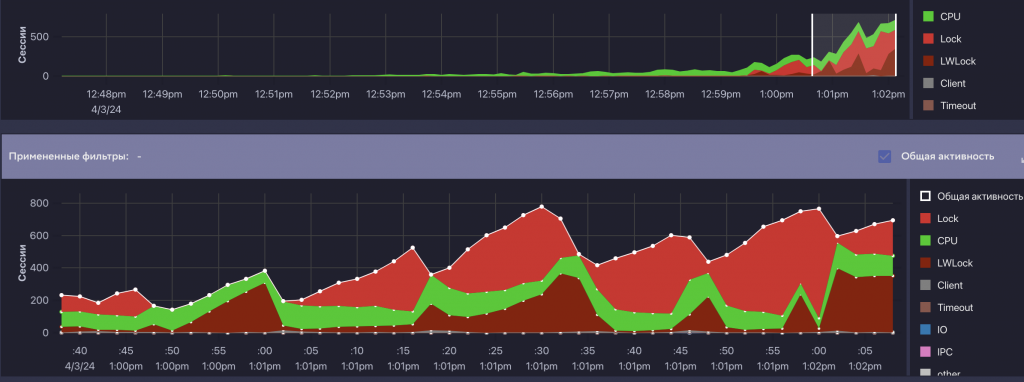
Мы изменили управляемость структурами памяти, отвечающими за работу с блокировками. Это позволило подобрать такой набор параметров, при котором система перестала упираться в потолок. В итоге мы получили то, что коллеги называют «зеленая травка»: процессор работает стабильно, есть небольшое количество операций чтения и лишь редкие всплески блокировок. Для нас это уже очень хороший результат.
Дальнейшие проверки с увеличением числа одновременных сессий при той же интенсивности показали, что система продолжает масштабироваться и не ограничивается предельными значениями.
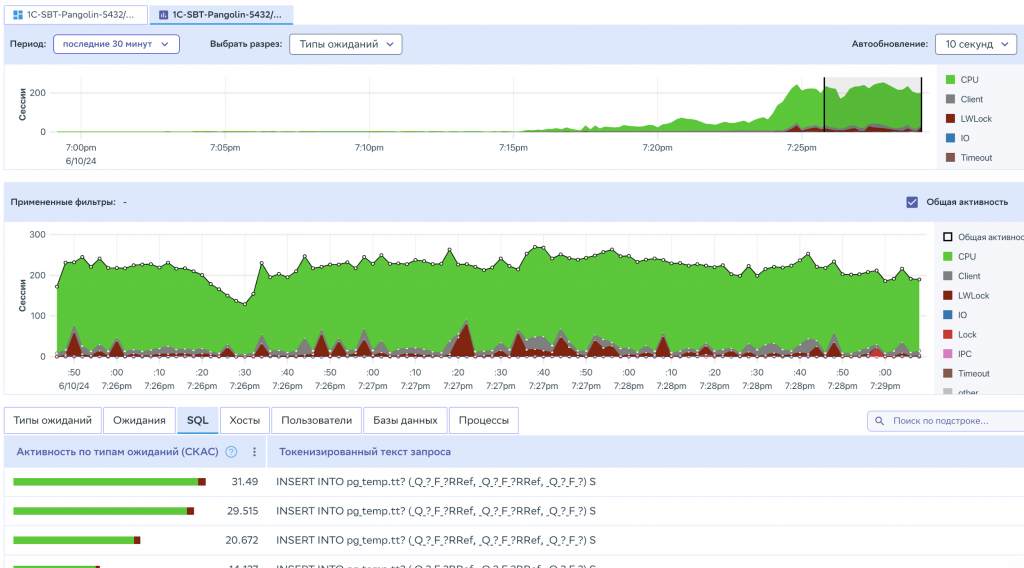
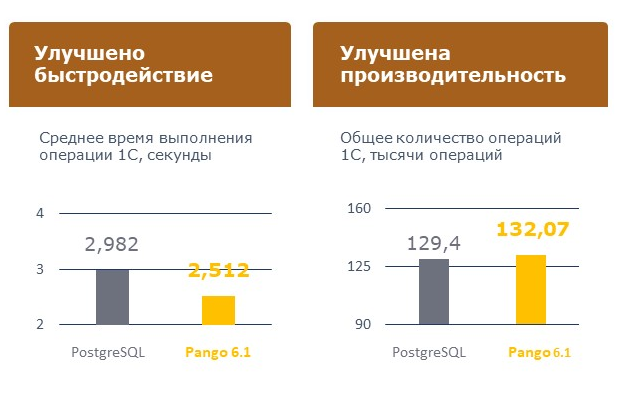
В результате нам удалось улучшить показатели производительности по сравнению с «ванильным» PostgreSQL и конкурентами.
Напомню, что мы ориентировались не только и не столько на APDEX, который является относительной величиной, а в первую очередь на абсолютные метрики — среднее время выполнения операций и их общее количество за определенный промежуток времени.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт