




Задача возникла при попытках поиска элементов справочника номенклатуры для обновления значений реквизитов. Суть проблемы заключалась в неуникальности реквизитов для поиска (артикул, например) в пределах всего справочника, что приводило к ложной подстановке обновляемых реквизитов.
В итоге, в качестве решения проблемы разработана модель сравнения наименования найденного элемента справочника с наименованием элемента, необходимого для обновления реквизитов. Таким образом, мы отсеиваем полностью несовпадающие по наименованию элементы справочника при неуникальных остальных реквизитах, по которым мы пытаемся спозиционироваться на элемент.
Существуют масса алгоритмов определения степени сходства 2-х текстов, после изучения которых, был выработан следующий алгоритм:
- Вычисляем длины наименований
- Принимаем за эталон наибольшую длину (для организации цикла)
- Принимаем наименование с наибольшей длиной за эталонную строку
- Попарно вычисляем число вхождений в обоих наименованиях каждого символа из эталонной строки
- Удаляем из наименований символы, для которых произведён поиск
- Складываем общее количество вхождений для каждого наименования
- После цикла вычисляем степень сходства по формуле (результат в процентах):
Здесь, "Вхождение1" - общее число вхождений каждого символа эталонной строки в первое наименование, "Вхождение2" - общее число вхождений каждого символа эталонной строки во второе наименование.
Перед вычислением по формуле, в условном операторе, необходимо определить какое из наименований имеет наибольшее число вхождений.
Ниже представлен полученный код для платформы 1С Предприятие 7.7. Принимаются предложения по оптимизации.
//возвращает процент сходства 2-х наименований
Функция СходствоНаименований(Знач Наим1="",Знач Наим2="")
Наим1 = СокрЛП(Наим1);
Наим2 = СокрЛП(Наим2);
Наим1 = СтрЗаменить(Наим1," ",""); //Удаляем двойные пробелы
Наим1 = СтрЗаменить(Наим1," ",""); //Удаляет одинарные пробелы
Наим2 = СтрЗаменить(Наим2," ","");
Наим2 = СтрЗаменить(Наим2," ","");
//проверяем значения на схожесть
Длина1 = СтрДлина(Наим1);
Длина2 = СтрДлина(Наим2);
Если Длина1 > Длина2 Тогда
Длина = Длина1;
Стр = Наим1;
Иначе
Длина = Длина2;
Стр = Наим2;
КонецЕсли;
Сч = 0; Вхождение1 = 0; Вхождение2 = 0;
Пока (Стр<>"") Цикл
Символ = Лев(Стр,1);
Вхождение1 = Вхождение1+СтрЧислоВхождений(Наим1,Символ);
Вхождение2 = Вхождение2+СтрЧислоВхождений(Наим2,Символ);
Наим1 = СтрЗаменить(Наим1,Символ,"");
Наим2 = СтрЗаменить(Наим2,Символ,"");
Стр = Прав(Стр,СтрДлина(Стр)-1);
КонецЦикла;
Возврат ?(Вхождение1>Вхождение2,Окр((Вхождение2/Вхождение1)*100,3,1),Окр((Вхождение1/Вхождение2)*100,3,1));
КонецФункции //СходствоНаименований()
Выявленные преимущества алгоритма:
- Время исполнения кода на очень хорошем уровне (меньше 0.0001 сек.)
- Переносимось алгоритма (не нужно подключать внешние компоненты)
- Выходной показатель (процент степени сходства) соответствует различию входных данных
Выявленные недостатки:
- Чувствительность алгоритма к сильному различию в количестве символов 2-х наименований (показатель степени сходства быстро снижается)
- При простой перестановке символов в разных наименованиях результат будет 100% сходства, что неверно.
Результаты экспериментов
Эксперимент 1:
- Наименование1 = "A0900001N Угольник 1"х1"
- Наименование2 = "CJ 65 V3 Лобзик"
- Результат = 13.636%
Эксперимент 2:
- Наименование1 = "Cъемник рулевых тяг и шаровых опор TOYA"
- Наименование2 = "Cъемник рулевых тяг и шаровых опор 2-х позиционный, зев 20 мм"
- Результат = 56.863%
Эксперимент 3:
- Наименование1 = "MF 800 VE миксер Felisatti"
- Наименование2 = "MF1200/VE2 миксер Felisatti"
- Результат = 84.000%
Возможное решение описанных выше недостатков
Метод написан на базе платформы 1С:8 пользователем DrBlack
Функция ПолучитьПроцентСходстваНаименований_2(Знач НаимСравн="", МассивСлов, ОбщДлинаСлов)
СуммаСовпадений = 0;
Для Каждого ТекСлово Из МассивСлов Цикл
Если СтроковыеФункцииКлиентСервер.ТолькоЦифрыВСтроке(ТекСлово) Тогда
СчНачало = СтрДлина(ТекСлово);
Иначе
СчНачало = Макс(3, СтрДлина(ТекСлово)-4);
КонецЕсли;
МаксСовпадений = 0;
Для Сч = СчНачало По СтрДлина(ТекСлово) Цикл
ТекОтрезокЛево = Лев(ТекСлово, Сч);
ТекОтрезокПрав = Прав(ТекСлово, Сч);
МаксСовпадений = Макс(МаксСовпадений, ?(СтрЧислоВхождений(НаимСравн, ТекОтрезокЛево)>0, Сч, 0), ?(СтрЧислоВхождений(НаимСравн, ТекОтрезокПрав)>0, Сч, 0));
КонецЦикла;
СуммаСовпадений = СуммаСовпадений + МаксСовпадений;
КонецЦикла;
ПроцентСовпадения = Окр(Мин(ОбщДлинаСлов, СуммаСовпадений) / ОбщДлинаСлов * 100, 3, 1);
Возврат ПроцентСовпадения;
КонецФункции
Входные параметры:
НаимСравн - строка, с которой надо сравнить
МассивСлов - эталонная строка, заранее разбитая на составляющие
ОбщДлинаСлов - общая длинна слов в МассивСлов для вычисления коэф. схожести
Суть данного метода - устранить недостатки метода из топика.
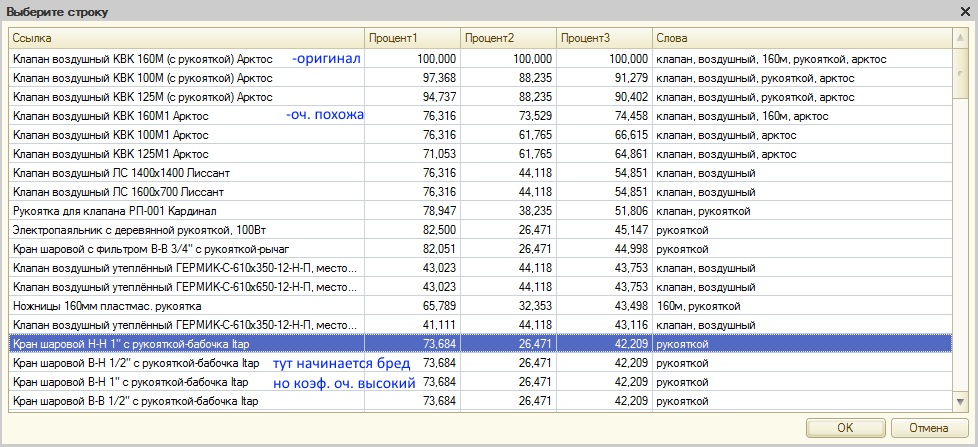
Описание колонок на скрине:
Процент1 - сравнение методом из топика
Процент2 - сравнение методом пользователя DrBlack по вхождению слов (не короче 4х символов)
Процент3 - усредненный коэф (Процент1 + Процент2 х 2) / 3
СПАСИБО ЗА ВНИМАНИЕ!
[Обновление, 15.10.19] Добавлены обработки для 1С7.7 и 1С8.х, реализующие задачу при помощи алгоритмов из публикации.
Вступайте в нашу телеграмм-группу Инфостарт


{kind=link}