Текущее состояние автоматизируемой системы
Для начала - несколько слов о системе и нагрузке на неё (*по состоянию на сентябрь 2014):
- База – самописная.
- Платформа – 8.2.
- На текущий момент у нас в базе работает более 3000 пользователей. На слайде - количество работающих пользователей с учетом COM- и веб-соединений:

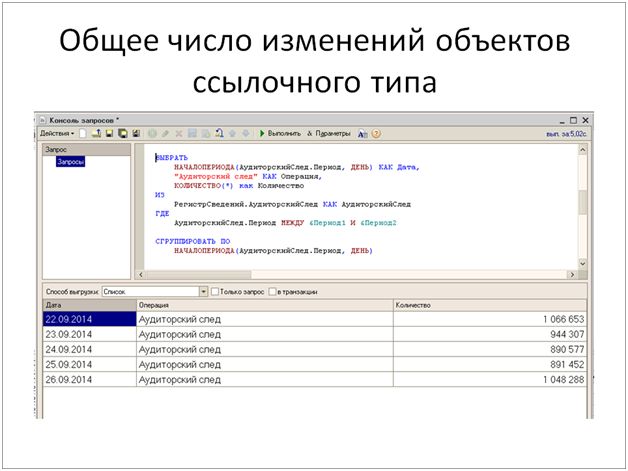
- Суммарно за сутки записывается порядка миллиона объектов ссылочного типа. Из них:
- 700 тысяч – это документы (перепроведение существующих и запись новых).
- 300 тысяч – это справочники (также модификация существующих и запись новых).
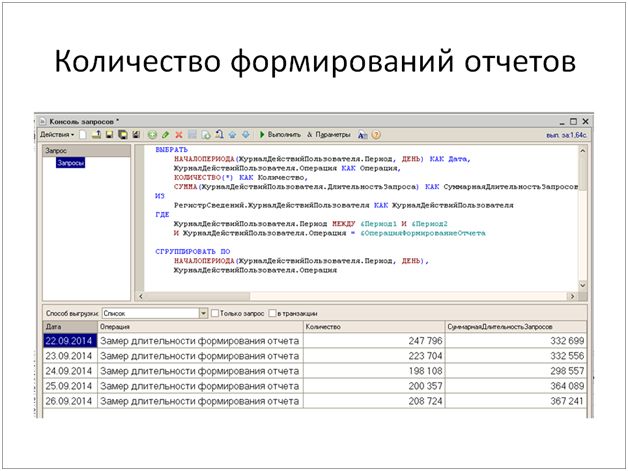
- Количество формирований отчетов в сутки составляет порядка 250 тысяч. Это многочисленные оперативные и аналитические отчеты.
- Суммарная длительность запросов, выполняемых пользователями в базе за сутки, превышает 330 тысяч секунд (92 часа) – достаточно интенсивная нагрузка.
При этом компания продолжает развиваться, открываются новые подразделения, привлекаются новые сотрудники, новые клиенты.
Есть постоянная потребность по разработке и внедрению новых подсистем, по автоматизации бизнес процессов, по решению различных интеграционных вопросов.
Поэтому у нас и большой отдел разработки - более 40 человек программистов, а также аналитики, тестировщики, архитекторы, эксперты. В общей сложности более 100 человек.
Процесс оптимизации. Начало.
Вопрос необходимости оптимизации возник несколько лет назад, когда в процессе бурного роста нашей компании постоянно увеличивалось количество пользователей информационной базы и, соответственно, значительно возрос объем обрабатываемых ими данных. При этом архитектура базы не была готова к такой интенсивной работе, поскольку она рождалась достаточно давно (еще на 7.7) и не была на это рассчитана, а вопросами SQL-сервера занимался программист 1С.
Начальные условия:
- Платформа 8.1
- Число пользователей в базе: 1000
- Режим блокировок: атоматические
- APDEX - отсутствует
- Нагрузка ЦПУ сервера СУБД достигает 98%
- Постоянные жалобы пользователей на "подвисания"
- Количество разработчиков: 10
- Обновления конфигурации БД: еженедельно
Основная задача, которую надо было решить – снизить загрузку CPU сервера SQL и обеспечить принципиальную работоспособность. Решали её разными способами, начиная с самого легкого – upgrade железа. Пока было куда "апгрэйдить" это помогало. Когда и топовое железо перестало помогать, тогда и началась оптимизация.
Что сделали на первом этапе:
- Разработали план регламентных работ по перестроению и дефрагментации индексов.
- Установили ЦУП и принялись за оптимизацию запросов.
- Перешли на управляемые блокировки.
- Внедрили APDEX (на мой взгляд – это обязательная штука, если, конечно, вы хотите знать что происходит с вашей базой).
На первое место в статистике ЦУПа вышли запросы обновления форм списков пары основных документов и справочника Контрагентов. Переделали их на формы поиска.
Основная суть – статичный список формируемый запросом (ПостроительОтчета), на форме блок предустановленных фильтров. Пользователь указывает отборы, жмет «Найти» и получает нужные данные. Это позволяет контролировать обязательные для заполнения поля поиска, избавиться от запросов при обновлении формы и скроллинге, а так же ограничить объем выводимой информации. Например, если мы хотим выводить не более 100 элементов, пишем в запросе "выбрать первые 101" и если запрос возвращает ровно 101 элемент, то пользователя просят уточнить отборы.
Конечно запросы из форм списков были не единственными, мы переписали досточно много запросов, а где то и архитектуру. Эта работа дала результат. Раньше, например, нагрузка на систему в понедельник и пятницу могла быть настолько высока, что приходилось отпускать домой некоторые отделы (менеджеров, колл-центр). А в результате проведенной оптимизации получилось снизить нагрузку в пятницу – проблем больше не было. Да и в понедельник мы тоже, со скрипом, но работали.
Второй этап оптимизации. "Разделяй и властвуй"
Тем не менее, мы прекрасно понимали, что расслабляться нельзя, надо действовать дальше, потому что количество пользователей к тому моменту опять выросло: их стало почти 2000. Штат разработчиков вырос до 20 человек, функционал наращивался очень быстро. И здесь нам помог случай и неудачный переход на 8.2 (8.2.13). Про переход на 8.2 можно многое рассказать, но так как тот опыт удачным не был, отмечу основную ошибку - не был проведен полноценный нагрузочный тест на 2000 рабочих мест.
Итак, не впадая в историзмы, у нас развивался свой сайт и от него поступал достаточно большой трафик запросов, которые "стучались" в боевую базу. Но эти запросы не требовали он-лайн данных и могли бы, например, подключаться к копии с актуальностью минус сутки. И у нас была подсистема репликации на планах обмена, которая разрабатывалась специально для перехода на 8.2 (на случай отката с 8.2 обратно на 8.1). Эта подсистема, используя план обмена, позволяет поддерживать в актуальном состоянии копию рабочей базы. Вот в эту копию мы и перенаправили часть соединений вэб сервисов. И заметили снижение нагрузки. Да, было понятно, что нагрузка должна несколько снизиться, но мы не рассчитывали, что ее падение будет настолько существенным. Сами запросы от сайта были достаточно маленькие, просто их поток был очень большим.
Возник вопрос: нельзя ли то же самое сделать с отчетами? Первое, что приходит в голову – это запустить для пользователя две базы: первую использовать только для ввода данных, а вывод отчетов там запретить, а во второй разрешить формировать отчеты, но запретить ввод данных. С точки зрения юзабилити это негативный сценарий, пользователь должен работать в одной базе, но при этом запрос надо выполнять в копии. Поэтому пошли другим путем:
- Провели пару экспериментов, убедились, что и результат запроса и табличный документы отлично сериализуются. В табличном документе, переданном по COM посредством сериализации/десериализации, работают даже расшифровки.
- Разработали шаблон отчета, который позволяет передавать настройки отчета и получать его результат по СОМ соединению.
- Улучшили подсистему репликации и добились актуальности данных в 2 – 3 минуты, что значительно расширило список перенаправляемых отчетов. Доработки в основном были нужны потому, что стандартный метод "ВыбратьИзменения" планов обмена создает большое колличество блокировок.
- Переписали кучу отчетов, приведя их к единому стандарту.
Так образом, хоть и с оговорками и условностями, мы разделили базу на OLAP и OLTP:
- OLTP – это рабочая база, где вносят первичку.
- OLAP –это база, где формируются отчеты и куда перенаправляются запросы веб-сервисов. Или, например, в эту базу можно зайти разработчику, чтобы протестировать какой-то отчет, как он будет себя вести в боевой системе.
Через пол года примерно, мы без "отчетной" базы уже не могли нормально работать. На слайде ниже показан эффект от разделения базы на рабочую и отчетную. Голубыми вертикальными линиями выделен момент, когда нам пришлось перевести формирование отчетов обратно в боевую базу.
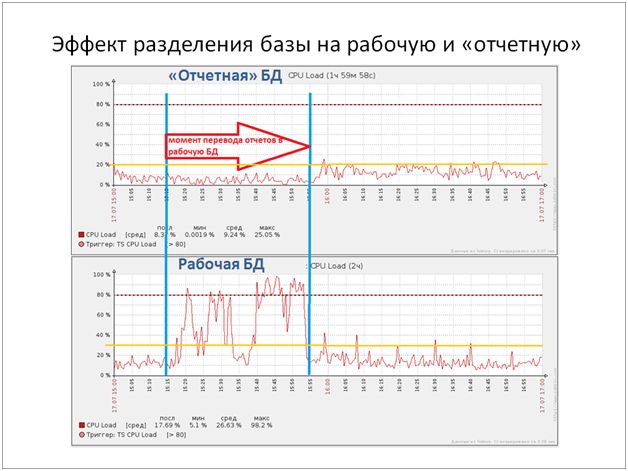
Нагрузка на CPU в этот период достигала 98%. Так же обращаю внимание на не линейный рост нагрузки, грубо говоря, 20%+30%=100%.
Очередное развитие отчетная база получила, когда вышел SQL Server 2012 и появилась технология AlwaysOn, которая позволяет средствами самой СУБД создавать и поддерживать несколько копий БД в актуальном состоянии (теперь у нас задержки всего лишь несколько миллисекунд). Сама по себе технология позволяет отказаться от репликации средствами 1С, но переписывать отчеты все равно придется.
Этот запас прочности помог нам начать большой проект по переходу на 8.2 с поддержкой ЦКТП от 1С. В прошлом году (*декабрь 2013) этот проект был удачно завершен, и этой весной (*весна 2014) мы перешли на релиз 8.2.19.
О ЦКТП осталось положительное впечатление. Советую всем, у кого "большая база": если вы планируете перейти на другую платформу либо хотите понять что будет, например, при двух кратном увеличении числа пользователей – обращайтесь в 1С, в рамках проектов ЦКТП достаточно оперативно устраняются и ошибки платформы и выявляются "узкие" места БД.
Инструменты для мониторинга и обнаружения проблем производительности.
Основные инструменты у нас:
- ЦУП;
- PerfExpert от SoftPoint;
- zabbix;
- Статистика SQLServer.
Статистика SQL сервера.
Расскажу подробно про статистику SQL, мы её активно используем.
- dm_exec_query_stats - статистика производительности для кэшированных планов запросов.
Ниже один из запросов, который позволяет на основании кэшированных планов запросов определить их топовый список по нагрузке. Соответственно, вы можете фильтровать этот список по нагрузке на процессор, по логическим чтениям – максимально, минимально – очень большой спектр возможностей для просмотра. При этом сразу же можете увидеть план запроса, что очень важно.
SELECT TOP 100
db.name,
SUBSTRING(text,(statement_start_offset/2)+1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(text)
ELSE statement_end_offset
END - statement_start_offset)/2)+ 1) AS [Текст запроса],
execution_count [Количество выполнений],
total_elapsed_time/1000000 [Длительность, сек],
total_worker_time/1000000 [Процессорное время, сек],
total_logical_reads [Логических чтений],
total_physical_reads [Физических чтений],
qp.query_plan [XML план запроса]
FROM sys.dm_exec_query_stats
OUTER APPLY sys.dm_exec_sql_text(sql_handle) dm_text
left join sys.databasesdb on dm_text.dbid = db.database_id
OUTER APPLY sys.dm_exec_query_plan(plan_handle) AS qp
WHERE
last_execution_time>=DATEADD(minute,-180,getdate())
ORDER BY
total_worker_time DESC--сортировка по нагрузке на процессор
--total_logical_reads DESC --сортировка по логическим чтениям
--execution_count desc --сортировка по количеству выполнений
- dm_exec_requests это второе часто используемое динамическое представление - сведения о выполняемых в текущий момент запросах.
SELECT
db.name,
a.session_id,
a.blocking_session_id,
a.transaction_id,
a.cpu_time,
a.reads,
a.writes,
a.logical_reads,
a.start_time,
a.[status],
case a.transaction_isolation_level
when 1 then'ReadUncomitted'
when 2 then'ReadCommitted'
when 3 then'Repeatable'
when 4 then'Serializable'
when 5 then'Snapshot'
end УровеньИзоляции,
a.wait_time,
a.wait_type,
a.last_wait_type,
a.wait_resource,
a.total_elapsed_time,
st.text,
qp.query_plan,
p.loginame [loginame сессии вызвавшей блокировку],
p.program_name [Приложение сессии вызвавшей блокировку],
p.login_time [Время входа сессии вызвавшей блокировку],
p.last_batch [Время последнего запроса сессии вызвавшей блокировку],
p.hostname [Host Name сессии вызвавшей блокировку],
stblock.text [Текущий(!) запрос сессии вызвавшей блокировку]
FROM sys.dm_exec_requests a
OUTER APPLY sys.dm_exec_sql_text(a.sql_handle) AS st
OUTER APPLY sys.dm_exec_query_plan(a.plan_handle) AS qp
LEFT JOIN sys.sysprocesses p
OUTER APPLY sys.dm_exec_sql_text(p.sql_handle) AS stblock
on a.blocking_session_id > 0 and a.blocking_session_id = p.spid
LEFT JOIN sys.databases db
ON a.database_id = db.database_id
WHERE not a.status in('background','sleeping')
ORDER BY a.cpu_time DESC
Сейчас, для определения причин высокой нагрузки на процессор, нам в 90% случаев хватает именно этих двух запросов к динамическим представлениям.
На слайде - недавний случай:
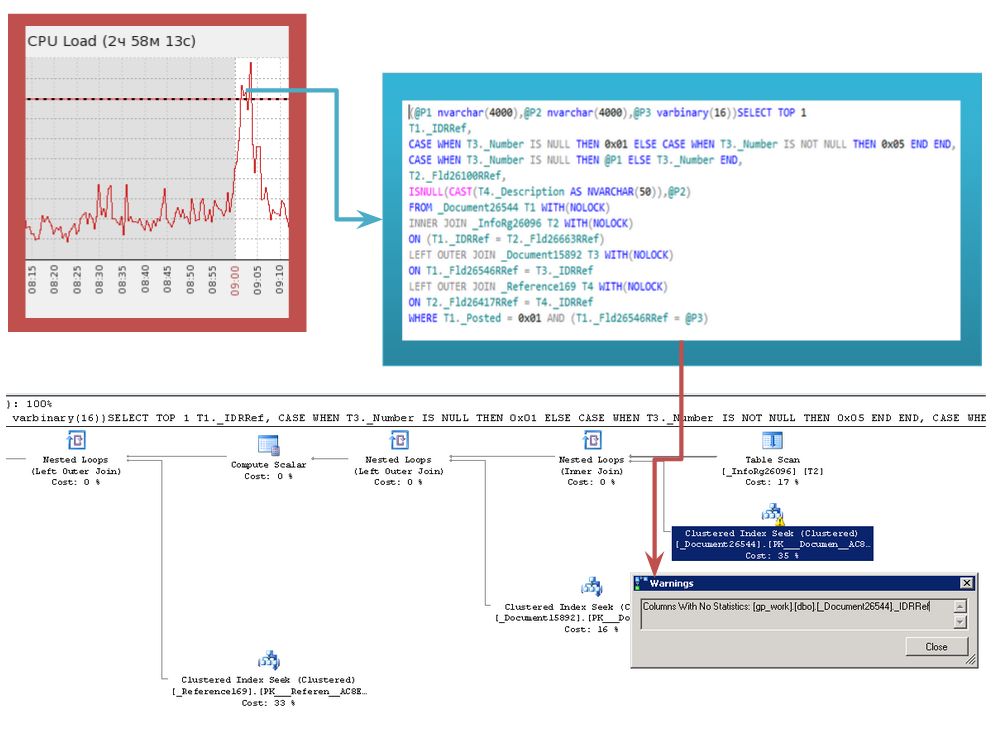
Резкое повышение нагрузки в 9 утра – народ пришел на работу. Посмотрев статистику кэшированных запросов обратили внимание на лидера по количеству логических чтений и план этого запроса. Причина была в отсутствии статистик для индексов документа. Выполнив обновление статистик этого документа проблему достаточно оперативно устранили.
По динамическим представлениям есть один нюанс, связанный с не повторяемостью текстов запросов использующих временные таблицы. Например, три одинаковых запроса, отличающихся только именем временной таблицы:

Проблема не так мала, как может показаться.
Во-первых, это накладные расходы на сервер т.к. СУБД воспринимает их как разные запросы и для каждого будет заново строить план запроса.
Во-вторых, сложнее пользоваться статистикой самого СУБД. Динамические представления, о которых шла речь выше, не группируют эти запросы и увидеть их суммарное влияние становится проблематично.
По заявлениям 1С данная проблема решена в 8.3, хотя по нашим тестам, получить подобный набор запросов достаточно просто. Проблему можно легко решить - дать возможность программисту самому назначить имя временной таблицы, но разработчики платформы нам с вами не доверяют принимать столь ответственное решение.
- dm_db_index_usage_stats, dm_db_missing_index_groups, dm_db_missing_index_group_stats - сведения об отсутствующих индексах и частоте использования существующих индексов.
Запрос, выводящий 10 самых востребованных из отсутствующих индексов по мнению SQL:
SELECT TOP 10
[ИмяТаблицы] = OBJECT_NAME(sys_indexes.object_id),
[ИздержкиОтсутствия] = ROUND(migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans),0),
[СреднийПроцентВыигрыша] = migs.avg_user_impact,
[Поиск] = migs.user_seeks,
[Просмотр] = migs.user_scans,
[Использование] = (migs.user_seeks + migs.user_scans),
[ДатаПоследнегоПоиска] = ISNULL(migs.last_user_seek, CAST('1900-01-01 00:0:00' AS datetime)),
[ДатаПоследнегоПросмотра] = ISNULL(migs.last_user_scan, CAST('1900-01-01 00:0:00' AS datetime)),
[ЧислоКомпиляций] = migs.unique_compiles,
[СредняяСтоимость] = migs.avg_total_user_cost,
[ОсновныеПоляИндекса] = CASE
WHEN sys_indexes.equality_columns IS NULL
AND sys_indexes.inequality_columns IS NULL THEN ''
WHEN sys_indexes.inequality_columns IS NULL THEN sys_indexes.equality_columns
WHEN sys_indexes.equality_columns IS NULL THEN sys_indexes.inequality_columns
ELSE sys_indexes.equality_columns + ', ' + sys_indexes.inequality_columns
END,
[ДополнительныеПоляИндекса] = ISNULL(sys_indexes.included_columns,'')
FROM sys.dm_db_missing_index_groups AS mig
JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
JOIN sys.dm_db_missing_index_details AS sys_indexes
ON mig.index_handle = sys_indexes.index_handle
ORDER BY [ИздержкиОтсутствия] Desc
(!)Обращаю внимание, что эта информация носит рекомендательный характер и бездумное её применение может навредить системе. Например, если вы удумаете создать индекс напрямую в СУБД и той структуры, которую выводит статистика, то помимо нарушения лицензионного согласения с 1С вы можете столкнуться с блокировками. Второй момент, который надо обязательно знать, на одну и ту же конструкцию запроса SQL может "захотеть" несколько вариантов индекса и слепо следуя совету вы насоздаете много лишнего.
Запрос, отображающий статистику по существующим индексам:
SELECT TOP 100
[КоэффициентЗаполнения] = sys_indexes.fill_factor,
[ИмяТаблицы] = OBJECT_NAME(sys_indexes.object_id),
[ИмяИндекса] = sys_indexes.name,
[Поиск] = (ISNULL(user_seeks,0) + ISNULL(user_lookups,0)),
[Просмотр] = ISNULL(user_scans,0),
[Использование] = (ISNULL(user_seeks, 0) + ISNULL(user_scans, 0) + ISNULL(user_lookups, 0)),
[Издержки] = (user_updates + system_updates),
[КоэффициентИспользования] = CASE WHEN (user_updates + system_updates) = 0 THEN (ISNULL(user_seeks, 0) + ISNULL(user_scans, 0) + ISNULL(user_lookups, 0)) ELSE CAST((ISNULL(user_seeks, 0) + ISNULL(user_scans, 0) + ISNULL(user_lookups, 0)) AS NUMERIC(15,3))/CAST((user_updates + system_updates) AS NUMERIC(15,3)) END,
[ДатаПоследнегоПоиска] = ISNULL(index_stats.last_user_seek , CAST('1900-01-01 00:0:00' AS datetime)),
[ДатаПоследнегоПросмотра] = ISNULL(index_stats.last_user_scan , CAST('1900-01-01 00:0:00' AS datetime)),
[ДатаПоследнегоПовторногоПоиска] = ISNULL(index_stats.last_user_lookup , CAST('1900-01-01 00:0:00' AS datetime)),
[ДатаПоследнегоИспользования] = CASE WHEN ISNULL(index_stats.last_user_seek, CAST('1900-01-01 00:0:00' AS datetime)) >= ISNULL(index_stats.last_user_scan, CAST('1900-01-01 00:0:00' AS datetime)) THEN ISNULL(index_stats.last_user_seek, CAST('1900-01-01 00:0:00' AS datetime)) ELSE ISNULL(index_stats.last_user_scan, CAST('1900-01-01 00:0:00' AS datetime)) END,
[ДатаПоследнегоUserОбновления] = ISNULL(index_stats.last_user_update , CAST('1900-01-01 00:0:00' AS datetime)),
[ДатаПоследнегоСистемногоОбновления]= ISNULL(index_stats.last_system_update , CAST('1900-01-01 00:0:00' AS datetime)),
[Фрагментация] = (sys_indexes_physical_stats.avg_fragmentation_in_percent),
[РазмерИндекса] = (avg_record_size_in_bytes * record_count / 1024 / 1024),
[КоличествоСтрок] = sys_indexes_physical_stats.record_count,
[СреднийРазмерЗаписиБайт] = sys_indexes_physical_stats.avg_record_size_in_bytes,
[СистемныйТипИндекса] = sys_indexes.type_desc,
[ЧислоФрагментов] = sys_indexes_physical_stats.fragment_count,
[ЧислоСтраниц] = sys_indexes_physical_stats.page_count,
[ЗаполненностьСтраниц] = sys_indexes_physical_stats.avg_page_space_used_in_percent,
[СреднееЧислоСтраницФрагмента] = sys_indexes_physical_stats.avg_fragment_size_in_pages
FROM
sys.indexes AS sys_indexes
LEFT JOIN sys.dm_db_index_usage_stats AS index_stats
ON sys_indexes.object_id = index_stats.object_id
AND sys_indexes.index_id = index_stats.index_id
LEFT JOIN sys.dm_db_index_physical_stats(null, null, null, null, 'LIMITED') AS sys_indexes_physical_stats /*для отображения размера индекса и количества строк значение 'LIMITED' надо заменить на 'DETAILED', запрос будет выполняться дольше*/
ON sys_indexes.object_id = sys_indexes_physical_stats.object_id
AND sys_indexes.index_id = sys_indexes_physical_stats.index_id
AND sys_indexes_physical_stats.index_level = 0
AND sys_indexes_physical_stats.alloc_unit_type_desc = 'IN_ROW_DATA'
WHERE
sys_indexes.name IS NOT NULL -- Ignore HEAP indexes
AND OBJECTPROPERTY(sys_indexes.object_id, 'IsMsShipped') = 0
ORDER BY
[Использование],
[Издержки] DESC
С помощью него можно определить какие индексы не используются, какие используются редко и имеют высокие издержки содержания.
Для наглядности покажу на примере обработки, в которую сведена информация из обоих запросов:
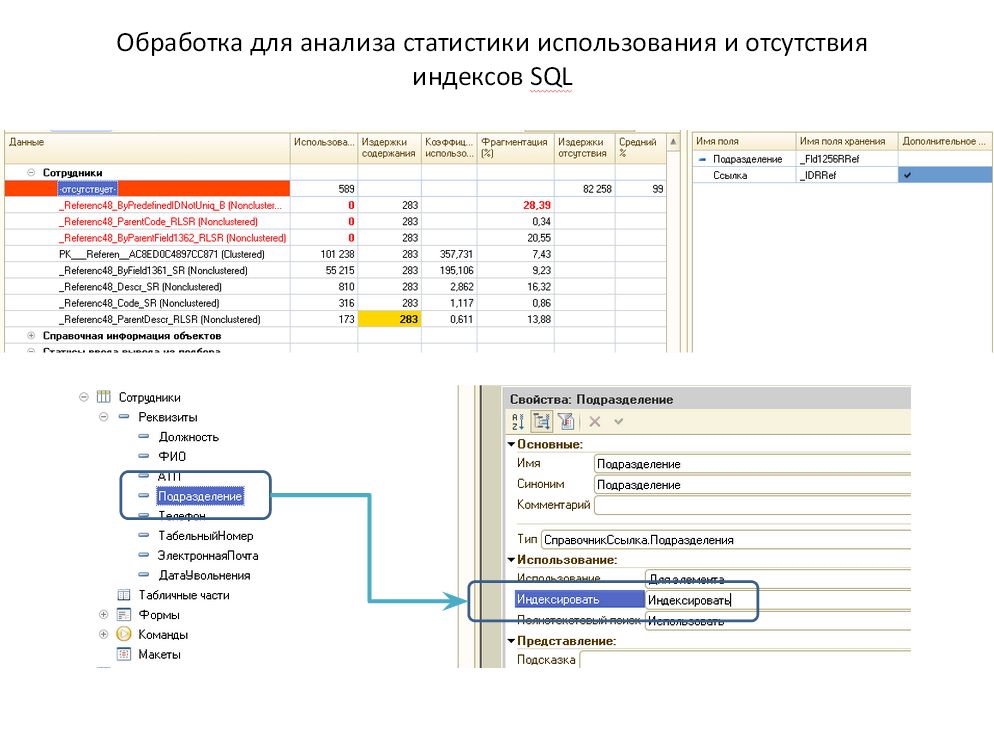
В справочнике «Сотрудники» SQL "хочет" индекс по полю «Подразделение». Издержки отсутствия достаточно высокие, а значит было много запросов, при составлении плана выполнения которых, SQL искал подобный индекс. Этот индекс легко создать – достаточно в конфигураторе, у соответствующего реквизита, установить свойство «Индексировать».
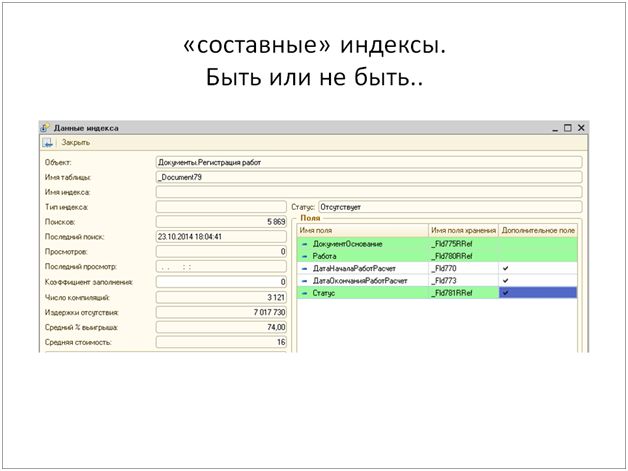
Второй пример несколько сложнее. SQL нужен индекс, состоящий из 2 основных полей «ДокументОснование», «Работа». И трёх реквизитов в качестве дополнительных полей. При этом реквизиты «ДокументОснование» и «Работа» уже проиндексированы сами по себе (проиндексированные поля подсвечиваются зеленым), но нужен именно составной индекс. Создать штатно это индекс нельзя. Создать непосредственно в СУБД - нарушение лицензионного соглашения.
Позиция 1С достаточно проста – если вам нужен составной индекс, значит надо переписать или доработать архитектуру.
Мое мнение, есть множество ситуаций, когда составной индекс дешевле обходится системе вместо архитектурных нагромождений. Дешевле как с точки зрения потребления дискового пространства, оперативной памяти так и временем транзакции при записи. Поэтому, если уважаемые разработчики платформы прислушаются и предоставят подобную возможность - это будет очень здорово.
ЦУП.
Центр управления производительностью из Корпоративного Инструментального Пакета от 1С. Его многие знают или, как минимум, слышали про него.
Назначение - сбор данных о ресурсоемких запросах, блокировках и deadlock.
Источник данных - технологический журнал, для анализа дэдлоков ЦУП - трассировки СУБД.
С ЦУПа мы начали, используем его и сейчас. Правда его пришлось самого оптимизировать и выделить для него мощный сервер.
Недостатки:
- ресурсоемкость запроса определяется только на основании времени его выполнения;
- требует доработок;
Достоинства:
- есть полный контекст выполнения.
PerfExpert.
Назначение - сбор данных о ресурсоемких запросах, блокировках и дедлоках; накопление и отображение данных о состоянии системы.
Источник данных - трассировки СУБД, Perfomance Monitor.
Основное отличие – статистика по запросам накапливается из трассировок к СУБД и делится на 2 категории – запросы с длительностью более 5 секунд и запросы с количеством чтений больше 50000. При этом тексты запросов группируются корректно и разные имена временных таблиц не мешают этому. Консолидирует и отображает информацию по большому количеству счетчиков Perfomance Monitor, так же есть возможность подключать в качестве счетчика прямой запрос к СУБД, что позволяет, например, выводить график APDEX.
Недостатки:
- нет полного контекста выполнения;
- нельзя купить лицензию на бессрочное использование.
Достоинства:
- наглядное отображение текущего состояния системы;
- подробная информация о нагрузке на СУБД.
Zabbix.
Назначение - накопление и отображение данных о состоянии системы; уведомление о превышении показателя пороговых значений.
Используется как универсальное средство для различного рода уведомлений и сигнализаций. Например о высокой нагрузке на CPU, о снижении АПДЕКСа. О состоянии важных бизнес процессов, например уведомление о превышении порогового количества электронных писем в очереди на отправку.
В отличии от перечисленных выше инструментов не является помощником в оптимизации и востребован, в основном, отделом технической поддержки пользователей.
Этот материал я дополнил той информацией, которую планировал рассказать на конференции, но не успел.
Спасибо за внимание!
*Доклад не корректировался с учетом "временного сдвига", в частности информация о числе пользователей, количестве записываемых объектов и т.п. уже изменилась (в большую сторону).
UPDATE по вопросам из комментариев
Размер БД. На текущий момент файл данных > 5Тб
Железо. Тут не экономим. СХД - перешли не так давно на SSD ибо на наших объемах становится критична скорость регламентных операций СУБД, время реструктуризации. Все железо очень близко описано в конфигурации тестового стенда проекта по ЦКТП: http://v8.1c.ru/expert/cts/cts-218-001.htm
Кластер 1С. В кластере один центральный сервер и 3 дополнительных. Сервера не виртуальные. Из "особенностей" только то, что у центрального сервера нет rphost'ов. Резервирование кластера настраивали, получили проблемы и письмо от ЦКТП с просьбой не экспериментировать (цитата: "Прошу подтвердить, что больше эксперименты с отказоустойчивостью на рабочей базе на версии платформы 8.2 проводится НЕ будут", во как))).
Отказоустойчивость. У нас всегда есть две "горячих" копии базы - отчетная база, куда данные попадают по обмену через СОМ, и база - реплика средствами AlwaysOn. Все три базы располагаются физически на разных серверах. Таким образом, при разрушении боевой базы достаточно изменить имя сервера СУБД в свойствах базы на кластере 1С и продолжить работу.
Вид интерфейса и форм. Изначально база разрабатывалась на 8.0, потом перешли на 8.1, соответственно работали в обычном режиме и на обычных формах. На 8.1 число одновременно работающих пользователей составляло 3000 сеансов, проблем с поведением кластера не испытывали. На текущий момент (после перехода на 8.2) стали появляться управляемые формы, режим работы по прежнему обычный и вряд ли изменится в ближайшей перспективе (уже проще написать с нуля).
Доставка приложения. Пользователи работают на терминальных серверах. Терминалки виртуализированы. На рабочих местах пользователей - тонкие клиенты (железки).
Текущие релизы: 8.2.19.130 и 8.3.6.2076. 8.3 используется для других баз на управляемом интерфейсе, работает стабильно.
Зачем одна большая БД. Единая система или распределенная - вопрос холиварный. Всегда будут доводы как за, так и против. Основной (и не единственный) аргумент за распределенку - несколько маленьких баз легче обслуживать, требуется менее дорогое железо, выше отказоустойчивость (разрушение единой базы много критичнее разрушения одного узла в связке). Т.е. основной профит будет, если в системе не будет ни одного большого узла. Самое простое - разделить территориально "по офисам продаж", но в этом случае мы не получаем нужный профит т.к. центральный узел все равно будет нужен в силу существования потребностей в сводной информации. Причем важна и скорость появления данных в этом едином узле (функциональное требование - минута,две). На выходе получим ровно такую критичность и ресурсоемкость работы центрального узла как и текущей БД, только появится "бонус" - грядка баз поменьше. Таким образом делить "по точкам продаж" можно ради освоения бюджета, не более. Но у нас есть понимание и желание поделить БД по функционалу, разрезав её на отдельные сервисы. Это реально и это уже происходит, но удовольствие дорогое и окончание разделения дело не ближайшей перспективы.
Обновления. Регламент примерно таков - обновление конфигурации раз в две недели, предварительно неделя тестов и code rewiev. Объемы доработок достаточно большие. Обновления делаются ночью, временное окно - 2ч. Если реструктуризация не успевает (замер по тестам) - разделяем обновление, если и после этого не успевает - либо согласуем большее время, либо переносим обновление на праздничные дни. В истории с реструктуризацией удивляет поведение платформы - большинство СУБД умеет добавлять (про удаление вообще молчу) колонку в существующую таблицу с данными, надо только указать значение по умолчанию и тогда тип колонки не будет содержать NULL. Вместо этого 1С направило силы на создание "шариковой ручки для космоса" и сделали фоновое обновление... В общем СУБД умеет делать быстро, а платформа - нет.
Регламентные операции СУБД. Изначально делали каждую ночь ребилд/дефраг индексов (естественно не всех, смотрим на процент фрагментации и число измененных строк) - постепенно перестали успевать плюс много негатива от ночных смен и подразделений дальнего востока. Перешли на схему: в рабочие дни каждую ночь обновление статистики с полным сканированием + ребилд особо важных таблиц (пара штук). В выходные - перестроение/дефрагментация индексов.
СУБД. Сейчас обновились до Microsoft SQL Server Enterprise 2014. В свойствах БД установлен уровень совместимости SQL 2012. Параллелизм отключен.
Обмен с отчетной базой. Выгрузка распараллелена по объектам метаданных - самые часто изменяющиеся типы вынесены в отдельные потоки, остальные - одним общим потоком. Схема обмена в общих чертах - план обмена (не РИБ) с авторегистрацией объектов. При выгрузке - запросом делаем выборку первых N (настраивается, сейчас N=20) записей из таблицы изменений, пробегаем выборку и устанавливаем разделяемые управляемые блокировки на элементы, которые планируем прочитать. Читаем сами объекты, сериализуем их и передаем по СОМ в базу приемник. В приемнике десериализуем и записываем. Если все успешно - в источнике очищаем регистрацию изменений и фиксируем транзакцию. В приемнике блокировки не устанавливаются т.к. никто кроме обменов данные в ней не модифицирует.
****************
Приглашаем вас на новую конференцию INFOSTART EVENT 2019 INCEPTION.

Вступайте в нашу телеграмм-группу Инфостарт