Из недавнего, случай номер раз
После нового года сообщение со склада: «обработка ПеремещениеКонтейнеровГрузчиками тормозит».
Тормозит припадками — то хорошо идет, то «замирает в произвольном месте посреди работы».
Выясняю имя компа, имя пользователя, периоды «когда тормозила» и «когда работала нормально»
Смотрю лог длительных запросов техжурнала :
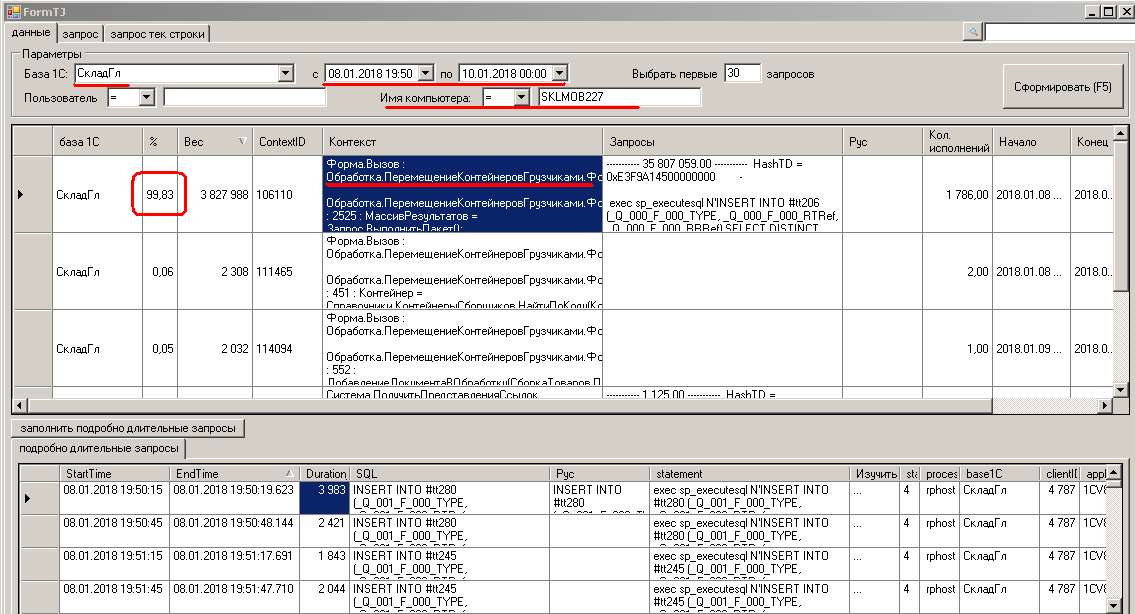
Смотрю лог длительных запросов sql-сервера, фиксируемый сессией XE :

Тоже самое, и тоже на первом месте — даже не надо делать поиск по слову «ПеремещениеКонтейнеровГрузчиками»
Проблема в запросе
Форма.Вызов : Обработка.ПеремещениеКонтейнеровГрузчиками.Форма.Форма.Модуль.ОбновитьИнформациюИзРабот
Обработка.ПеремещениеКонтейнеровГрузчиками.Форма.Форма.Форма : 2525 : МассивРезультатов = Запрос.ВыполнитьПакет();
Запрос простой:
INSERT INTO #tt280 (_Q_001_F_000_TYPE, _Q_001_F_000_RTRef, _Q_001_F_000_RRRef)
SELECT DISTINCT
T2._Документ_TYPE,
T2._Документ_RTRef,
T2._Документ_RRRef
FROM
#tt278 T1 WITH(NOLOCK)
INNER JOIN _Справочник.РаботыПоДокументам T2 WITH(NOLOCK)
ON ((T1._Q_000_F_000 <= T2._Дата) AND (T1._Q_000_F_001 >= T2._Дата))
WHERE
(T2._СотрудникRRef = ?) AND (T2._ВидРаботRRef IN (?, ?))
p_0: 0x82671C6F65D4C9E511E6F4D5B9451D40
p_1: 0x826B902B345B065011E79DD1E6AFA776
p_2: 0x826B902B345B065011E79DD1E6AFA77D
Сам запрос — в процедуре ОбновитьИнформациюИзРабот(), которая повешена на пару кнопок + на обработчик ожидания вот так:
&НаКлиенте
Процедура ПриОткрытии(Отказ)
ПодключитьОбработчикОжидания("ОбновитьИнформациюИзРаботКлиент", 15);
КонецПроцедуры
Показывает какую-то статистику сборщику в нетбуке по его производительности.
Тормозит работу, раздражает (минимум каждые 15 сек подвисание на 2-3 сек)
Не жизненно важно.. оперативно отключили.
Ведущий: «Но оно же работало вот уже кучу времени, как так?».
Разбираемся.
Работало оно так действительно не всегда.
До 07.01.2018 и сведений-то нет по запросу — значит, исполнялся строго менее полсекунды (не попал в трассу длительных rpc_completed eXtended Events), и в логе sys.dm_exec_query_stats тоже нет данных.
Легкий был запрос.
Ночью седьмого он начинает сбоить:
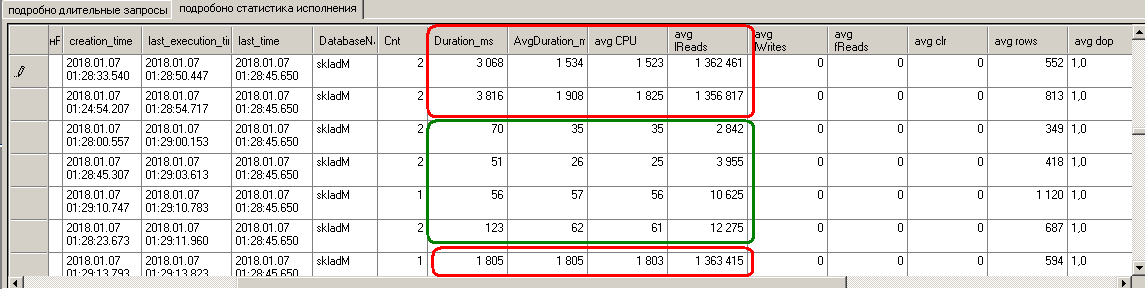
Резко увеличивается как длительность (до 1-3 секунд), увеличивается количество чтений и нагрузка запросом на CPU. При этом avg rows не меняется, да и параметры на входе запроса тоже гарантированно не скачут (это видно из кода).
Значит поменялся план исполнения.
Справочник.РаботыПоДокументам нужен для подсчета сдельной части оплаты труда складского персонала (в основном содержит что-то вроде «5 января - перемещение №23434 - Вася Иванов - перенос тяжестей - 5 кг»)
Он имеет десяток реквизитов, из которых проиндексированы «ВидРабот», «Дата» и «Документ».
Вопрос «а чего это он справочник, а не регистр сведений» уходит корнями год этак в 2007-ой, когда «трава была зеленее, вода мокрее, а база работала на 8.1».. так вот получилось, и легким движением руки - не изменишь.
Планов зафиксировано достаточное количество, чтобы разобраться..
Вот «плохой» план:
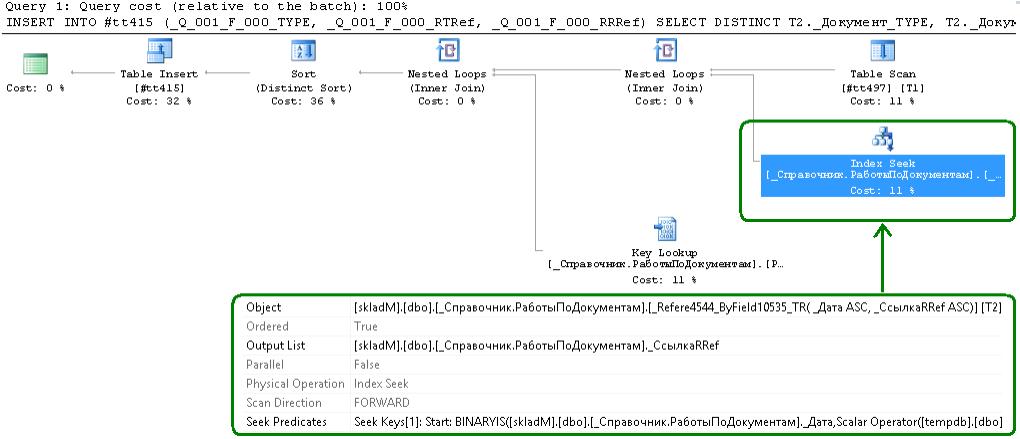
Index Seek, seek predicates содержит отбор по диапазону [_Справочник.РаботыПоДокументам]._Дата.
Т.е. отберем РаботыПоДокументам за период, а потом (во время key lookup к кластерному) глянем — соответствует ли WHERE (T2._СотрудникRRef = ?) AND (T2._ВидРаботRRef IN (?, ?))
Учитывая то, что в рабочей складской бд рождается по несколько десятков документов в секунду, и почти в каждом сдельщина - Index Seek по «Дата в диапазоне» выходит накладным.
Диапазон дат не уменьшить — данные выводятся за текущую смену (несколько временных интервалов во времянке #tt497, суммарно ~8 часов).
А вот «хороший» план:
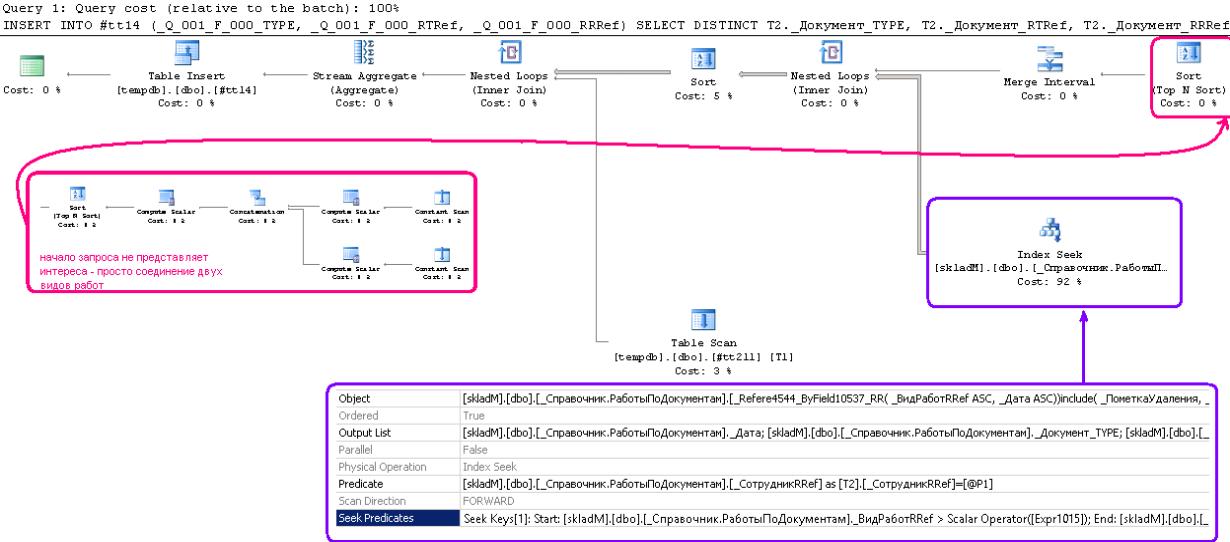
Тут отбираются данные по индексу поля «ВидРабот» (Seek Predicates по ВидРабот > параметр1 И ВидРабот < параметр2), в отобранном отрабатывает фильтр (Predicate) по «T2._СотрудникRRef = ?», и ТОЛЬКО ПОТОМ соединяем с таблицей диапазонов дат.
Т.е. «хороший» план тоже ужасен.
Ну а вдруг таких работ за год будет миллион? Тогда первый index seek грохнется.. а почему, кстати, пока не грохается?
По ходу дела выясняется, что «..оно же работало вот уже кучу времени...» = примерно три месяца. И тогда же были созданы два новых «вида работ».
Пока записей с данными «видами работ» было мало — стратегия «отбираем все записи с этими видами работ, а что получилось — фильтруем по Сотруднику и Дате» работала неплохо.
А вот как их стало поболее — оптимизатор решил «не, индекс по Дате более классный». Хотя это на самом деле _пока_ не так.
Периодический пересчет статистик таблицы _Справочник.РаботыПоДокументам настроен.
UPDATE STATISTICS _Reference4544 — выполняется раз в день, задачей на sql-сервере.
Пробую пересчитать статистику вручную и пробно запустить запрос — нет, план «плохой».
Хорошо, пересчитываю WITH FULLSCAN (тяжелая операция, таблица большая, но что не сделаешь ради истины) – ага, некоторое время план «хороший», потом опять срыв в «плохой».
Итого имеем:
1. Идеальное решение проблемы — выпилить запрос из системы совсем. Не подходит. Пользователи говорят «оно нам надо»..
2. Плохое решение проблемы — включить индексирование поля «Сотрудник». Некоторое время поработает. Но потом таки найдется сотрудник, проработавший в этой обработке полгода — у него посыпется опять.. Да и вообще, как-то неприятно плодить такие.. как оно - «суррогаты»?..
3. Нереальное решение проблемы — переделать со справочника на регистр сведений (внешнюю базу данных, иное — нужное подчеркнуть).. ну да, делов-то на год для трех человек (три конфигурации этой штукой пронизаны насквозь, одних впрямую использующих отчетов — десятка три).
4. Спорное решение проблемы — новый индекс для таблицы _Reference4544 объекта _Справочник.РаботыПоДокументам, по полям _СотрудникRRef, _ВидРаботRRef, _Дата, с include-полями _Документ_TYPE, _Документ_RTRef, _Документ_RRRef.
Но 1С штатно такое делать не умеет.
Вопрос создания новых /модификации стандартных индексов — тема спорная..
Позиция 1С понятна — хочется чтоб работало «как надо» само при правильном выборе типа объекта и порядке реквизитов.. да и неподготовленный новичок может наворотить всякого самописными индексами..
Но с другой стороны, ситуации «очень надо именно вот такое» весьма часты. И думаю, в 1С догадываются, что «они все равно это делают».
Лучше всех, сдается мне, сказал Андрей Бурмистров: «..Надеюсь я доживу до того дня, когда платформа позволит создавать индексы произвольного состава средствами конфигуратора.». Кстати, внимательный читатель может таки уже задать вопрос «а почему в “хорошем” плане нет key lookup к кластерному, и почему проверка T2._СотрудникRRef = ? идет в индексе по “ВидРабот”?»
В данном случае и индекс по полю «Сотрудник» (что штатный простой, что самописный с доп. полями «ВидРабот» и «Дата») - тоже не решение.
Справочник содержит ~500 млн строк, 70 Gb кластерный индекс, порядка 100 Gb прочие индексы..
Создание нового индекса - к бабке не ходи - подвесит работу всего склада блокировками на полчаса минимум.
Это при том, что технологическое окно — 20 мин в сутки, расписано по минутам (крупные реструктуризации — тот еще цирк..).
И весить структура будет гигабайты.
Если более нигде этот индекс не нужен — то веского обоснования создания нет.
А он, как ни странно, не особо нужен:
- в sys.dm_db_missing_index_... хоть и есть похожий, но даже не в первой сотне (за месяц ~100 unique_compiles, ~350 user_seeks).
- в топе тяжелых запросов ничего к Работам, кроме разбираемого случая, не светится
- ведущий говорит, что ему не надо (и я таки после предыдущих пунктов верю)
Рекомендовал попробовать получать ту же информацию, но из других источников (кидать запрос к документам, которые плодит обработка).
Думают..
Из недавнего, случай номер два
Заданий (jobs в SQL Server Agent) по пересчету статистик на главном sql-сервере — всего два.
Одно раз в три часа отрабатывает, в нем все наиболее динамически меняющиеся объекты (таблица итогов регистра остатков, резервов, шапки основных документов вроде расх. накл. и т. п.). С десяток объектов.
Второе отрабатывает раз в сутки, объекты туда попадают по факту наличия сбоев (слетел план запроса по регистру такому-то — убедились, что пересчет статистик помог, добавили в джоб строчку «UPDATE STATISTICS _AccumRgT...» с комментарием «смотри задача нумер такой-то»).
Переместили пересчет статистик таблицы итогов остаточного регистра «РезервТоваров» из первого во второе (как так вышло - дело десятое..).
Как результат — спустя неделю задача вида «один из важных процессов склада периодически идет критически медленно».
Пользователя и период его «медленной» работы предоставили.
Смотрю статистику по пользователю (длительные dbmssql в тежурнале)
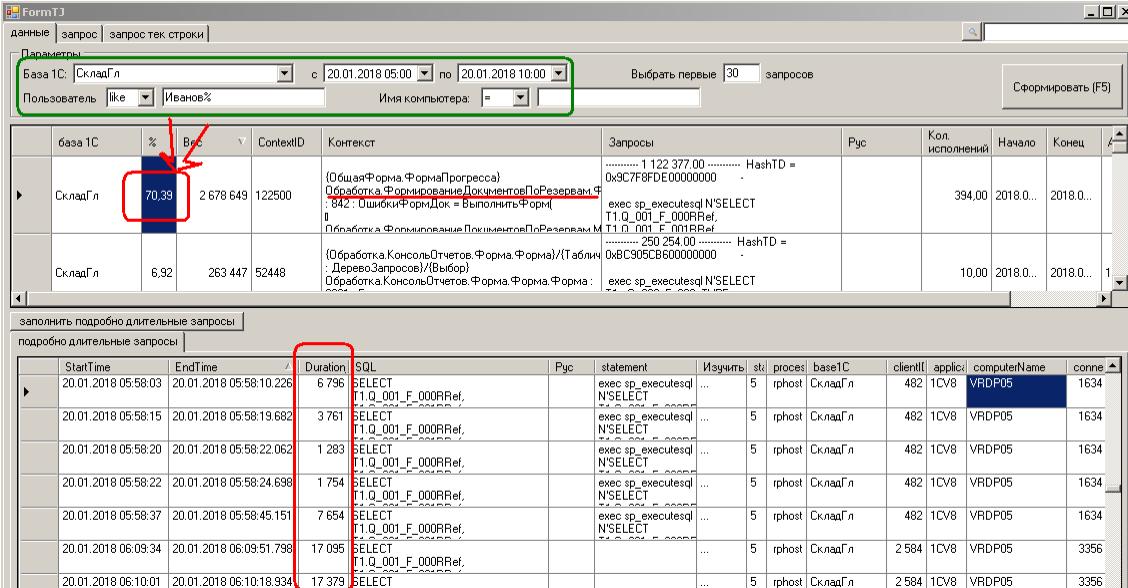
Запрос простенький
SELECT
...
FROM
(SELECT DISTINCT T2._Q_000_F_000RRef AS Q_001_F_000RRef, T2._Q_000_F_001RRef AS Q_001_F_001RRef FROM #tt967 T2 WITH(NOLOCK)) T1
LEFT OUTER JOIN
(SELECT
T4._ТоварRRef AS ТоварRRef,
...
CAST(SUM(T4._Количество) AS NUMERIC(32, 8)) AS КоличествоBalance_
FROM
_РегистрНакопления.РезервТоваров(Итоги) T4
WHERE
T4._Период = ? AND ((T4._ТоварRRef IN (SELECT T5._Q_000_F_000RRef AS Q_003_F_000RRef FROM #tt967 T5 WITH(NOLOCK)) AND (T4._СкладRRef = ?)))
GROUP BY
...
HAVING (CAST(SUM(T4._Количество) AS NUMERIC(32, 8))) <> 0.0
) T3
ON ((T3.ТоварRRef = T1.Q_001_F_000RRef) AND (T3.БлокRRef = T1.Q_001_F_001RRef))
ORDER BY (T1.Q_001_F_000RRef), (T1.Q_001_F_001RRef)
Код тоже
ВЫБРАТЬ
Товары.Товар КАК Товар, Товары.Блок КАК Блок, Резервы.Документ, Резервы.Вид, ….
ЕСТЬNULL(Резервы.КоличествоОстаток, 0) КАК Остаток
ИЗ
(ВЫБРАТЬ РАЗЛИЧНЫЕ Товар, Блок ИЗ времТов) КАК Товары
ЛЕВОЕ СОЕДИНЕНИЕ РегистрНакопления.РезервТоваров.Остатки(, Товар В (Выбрать Товар ИЗ времТов) И Склад = &Склад) КАК Резервы
ПО Резервы.Товар = Товары.Товар И Резервы. Блок = Товары. Блок
Вообще-то этот запрос за миллисекунды обычно отрабатывает
Гляжу статистику исполнения (лог sys.dm_exec_query_stats) – обнаруживается начало сбоя
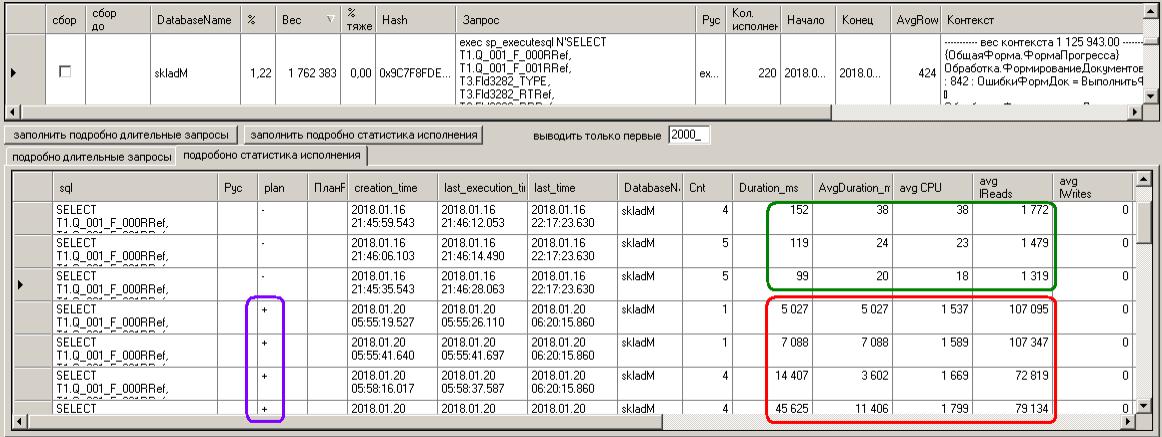
Записи, выделенные зеленым — относятся вообще 16 января (вывел историю в надежде глянуть «как оно было ранее» - получилось)
«Плохие» исполнения начинаются с 05:55 10 января (на самом деле раньше, но статистика фиксируется только с этой точки)
Аналогично нахожу завершение «плохих» исполнений
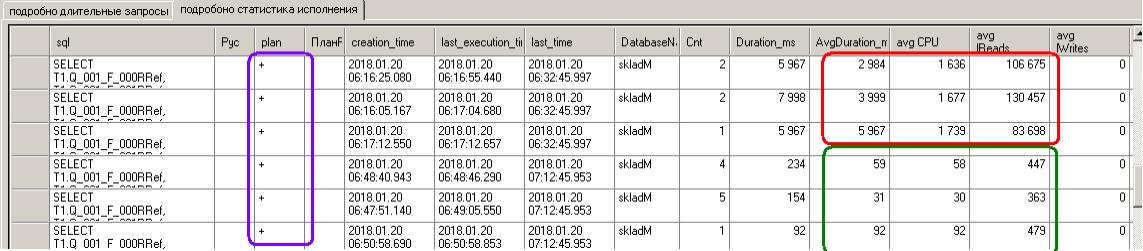
Причем здесь есть возможность глянуть и «плохой», и «хороший» планы исполнения (плюсики, отмеченные фиолетовым).
«Хороший план», как и ожидалось — по кластерному индексу таблицы итогов регистра (измерения Товар,Блок,Склад,...)
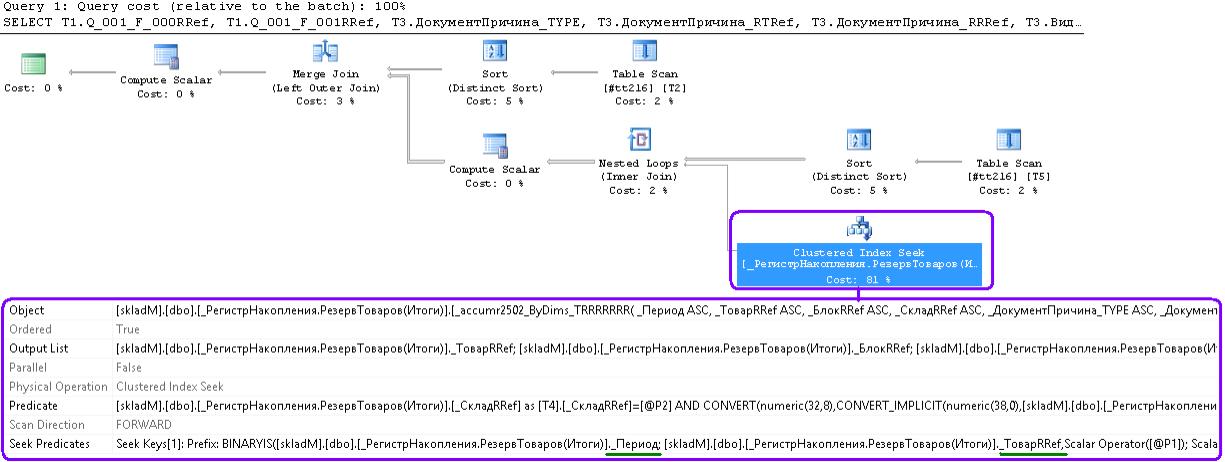
Отбираем из кластерного таблички итогов РезерваТоваров записи по периоду (3999-11-01) и списку товаров, проверяем выбранное на склад и сливаем со списком товаров/блоков (merge).
Нормально.
Можно и лучше, но нормально.
«Плохой» план.. тут ожидал пробежки по индексу реквизита «Склад», но реальность еще интереснее
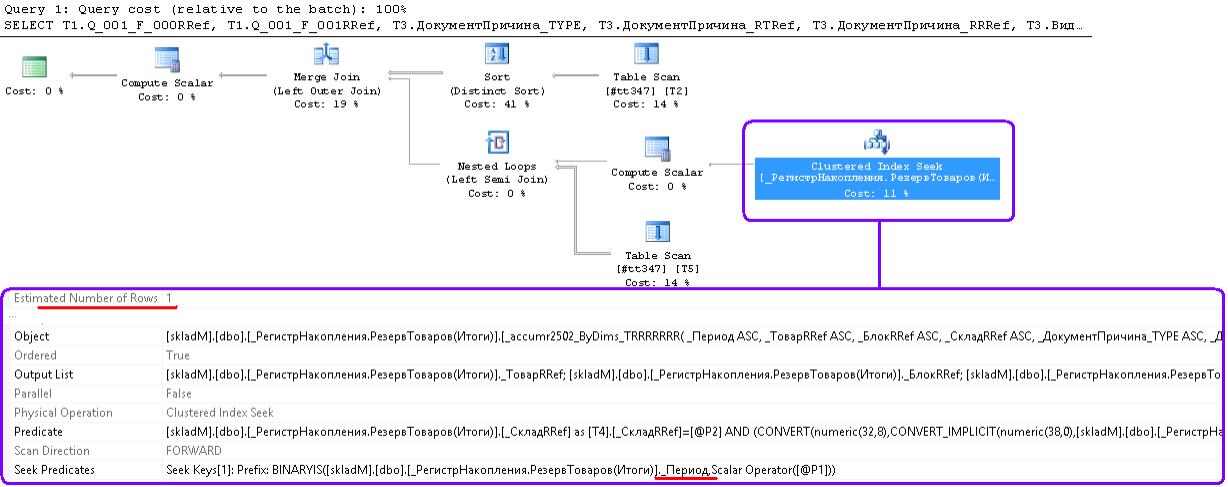
Отбираем из кластерного таблички итогов РезерваТоваров ВСЕ записи по периоду (в seek predicates только _Период), потом в найденном проверим склад.. .
И ожидается, что получим одну строчку.
А уж потом мы залезем в список товаров (nested loops) и т. д.
Явно по табличке статистики кривые.
В данном случае решение — просто перенесли пересчет статистик таблицы итогов регистра «РезервТоваров» назад, в задание «раз в три часа»
И нормализовалось.
Более правильное решение, как представляется — переписать запрос так, чтоб в seek predicates попадали все четыре условия: по _Период, _Товар, _Блок и _Склад
Вполне реально, если загнать во времянку все четыре поля и соединять — страшно сказать — с РегистрНакопления.РезервТоваров.Остатки(,) без условий в срезе.
Это вроде идет против всех правил и наставлений по написанию запросов, однако начиная с mssql2012 часто вижу, что оптимизатор в планах исполнения успешно загоняет соединения в самое начало последовательности исполнения, раскрывая скобки подзапросов виртуальной таблицы Остатки().. поумнел.
Вот попробовал
ВЫБРАТЬ
…
ИЗ
времТов КАК Товары
ЛЕВОЕ СОЕДИНЕНИЕ РегистрНакопления.РезервТоваров.Остатки(,) КАК Резервы
ПО Резервы.Товар = Товары.Товар И Резервы.Блок = Товары.Блок И Резервы.Склад = Товары.Склад
и получил что требовалось
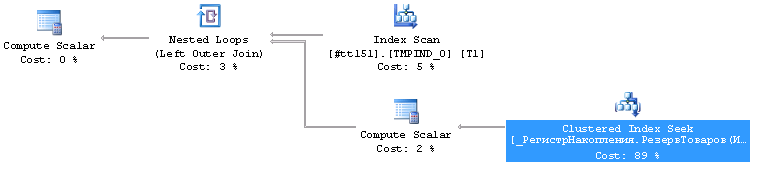
Clustered Index Seek в данном случае имеет Seek Predicates вот такой (в скриншот категорически не лезет):
Seek Keys[1]: Prefix: BINARYIS([skladM].[dbo].[_РегистрНакопления.РезервТоваров(Итоги)]._Период; [skladM].[dbo].[_РегистрНакопления.РезервТоваров(Итоги)]._ТоварRRef; [skladM].[dbo].[_РегистрНакопления.РезервТоваров(Итоги)]._БлокRRef; [skladM].[dbo].[_РегистрНакопления.РезервТоваров(Итоги)]._СкладRRef,Scalar Operator([@P1]); Scalar Operator([tempdb].[dbo].[#tt151].[_Q_000_F_000RRef] as [T1].[_Q_000_F_000RRef]); Scalar Operator([tempdb].[dbo].[#tt151].[_Q_000_F_001RRef] as [T1].[_Q_000_F_001RRef]); Scalar Operator([tempdb].[dbo].[#tt151].[_Q_000_F_002RRef] as [T1].[_Q_000_F_002RRef]))
Видно, что поиск в индексе по периоду и трем первым измерениям регистра.
Количество логических чтений (даже с учетом создания индекса, создание которого я для верности воткнул во времянку) — уменьшилось до 120-250
Хороший вариант, но люди от него шарахнутся, как черт от ладана.. срез без условий.. Да и толку бизнесу от этой вкусовщины немного, пара микросекунд прибыль не принесет — и так «good enough»...
Этот прием нельзя рекомендовать как общее правило.. слишком много оговорок и условий для стабильной работы
(желательно текущие итоги /не задана дата/, присоединение РегистрНакопления.ИМЯ.Остатки(,) внутренним или левым к времянке, которая содержит измерения регистра начиная с первого, условия соединения по измерениям с первого и далее — чтоб ложилось в кластерный; минимальное количество таблиц в запросе, лучше времянка + ..Остатки(,) ).
Спустя пару дней после написания абзаца заглянул — как оно работает? Так вот - увидел «хороший» план, только merge join сменился на Nested Loops, и Clustered Index Seek идет .. по периоду и первым трем измерениям!.. оптимизатор сообразил поменять два обращения к времянке местами (условие виртуальной таблицы Остатков по «товар в выборке» проверяет уже после поиска в кластерном регистра). Чудеса, однако..
Вывод раз.
Несмотря на принятое решение «оставить как есть и чаще пересчитывать статистику», в похожих случаях лучше всеж переписать запрос..
Упростить, иногда разобрать на несколько времянок — но в каждом запросе пакета оставить оптимизатору один, наиболее очевидный и выгодный вариант.
Если запрос важен для бизнес-процесса, то пусть работает на пять микросекунд дольше и плодит на две сотни логический чтений больше — зато стабильно, без срывов и отказов.. да и вас ночью не разбудят.
Вывод два.
В регистре резервов измерение «Склад» почему-то не на первом месте. Поиск в конфигураторе выдает сотни три ссылок по «РезервТоваров.Остатки», просмотрел наискосок около трети — везде отбор по складу или набору складов. Насчитал десять исключений (из них три похожи на баги). Однако - и по первому теперешнему измерению "Товар" отбор тоже всегда есть. Скорее теоретический вопрос, "как бы оно было бы лучше"..
Вывод три.
Вспомнил вот хорошую статью (Автору отдельное спасибо за скрипт настройки немедленной рассылки «писем счастья» вида «SQL Server Alert System: 'Error 9002' occurred on \\VS1Test07» - пользуюсь)
Там поминалось о пересчете статистик в зависимости от даты последнего обновления и количества изменений в таблице со времени последнего обновления.
Ну и накидал скрипт апдейта.. страховочный, с условиями having max(sp.modification_counter) > 20000 and min(STATS_DATE(o.[object_id], ss.[stats_id])) < DATEADD(day, -3,GETDATE()) and ISNULL(SUM(sp.[rows]),SUM(p.[rows])) > 300000
Запускаю его раз в день, от описанного инцидента не спасет, но может поможет в чем другом.
Теперь думаю — нельзя ли поменять параметры и его переделать на запуск раз в час, чтоб спасал "от всего"..
Может есть у кого что-то похожее?
Из стародавнего, случай номер три
Около не помню скольки (восьми? больше?) лет назад сломался один из самых частых складских запросов.
Запрос к регистру остатков, при перемещении товара.
Склад встал.
Все причастные коллеги, побледнев, дружно искали причины безобразия.
Я искал блокировки (специфика того времени). И не находил (точнее - находил, но дело было явно не в них, а в их необычной длительности).
По истечении часа «все прошло, как с белых яблонь дым».
За это время успели пересчитать кучку непричастных индексов, удалить нулевые записи в итогах двух регистров, два раза перезагрузить кластер, врубить режим отладки, запустить замер производительности и отловить - таки проблемную строку.
Строка звучала как
Результаты = Запрос.ВыполнитьПакет();
Исполнение пакета запросов, внутри десяток запросов. Какой? Нашли в техжурнале. Но почему?
В общем, когда оно три дня спустя изволило вернуться — я уже ждал с профайлером наперевес..
Запрос немудреный (не стал его совсем вырезать — закомментировал на память..)
ВЫБРАТЬ
...
ИЗ
(ВЫБРАТЬ РАЗЛИЧНЫЕ
Товары.Товар КАК Товар,
Товары.Блок КАК Блок
ИЗ
Документ.ПеремТов.Товары КАК Товары
ГДЕ
Товары.Ссылка = &Ссылка) КАК Товары
ЛЕВОЕ СОЕДИНЕНИЕ РегистрНакопления.ОстаткиТоваров.Остатки(, Склад = &Склад И Товар В (Выбрать РАЗЛИЧНЫЕ Товар из Документ.ПеремТов.Товары где Ссылка = &Ссылка)) КАК Остатки
ПО Товары.Товар = Остатки.Товар И Товары.Блок = Остатки.Блок
СГРУППИРОВАТЬ ПО
....
Остаточный регистр накопления ОстаткиТоваров — брат-близнец РезерваТоваров, с измерениями Товар, Блок, Склад,...
Вот тут как раз было переключение на план исполнения по индексу измерения «Склад» !
Оптимизатору казалось, что начать с отбор с таблицы итогов по периоду и складу, а уж далее в найденном проверить (nested loops) на список товаров — отличная идея.
На деле же на складе оказывалось весьма много записей, index seek выходил долгим и возвращал довольно много строк.
UPDATE STATISTICS соответствующего _AccumRgT.. + чистка кеша планов запросов поправляли дело — план менялся на index seek в кластерном .. но ситуация повторялась черед день-два.
Пикантность ситуации состояла в том, что UPDATE STATISTICS того регистра (и вообще всех значимых) в то время работал чуть не «раз в час» (еще не умели толком ловить конкретные запросы, и действовали в соответствии с тактикой «Алеша, посыпь его мелом»).
Т.е. оно и так пересчитывается с дикой частотой, но в какой-то момент невыгодный план все равно оказывается в кэше.
Наверное тогда в первый раз сознательно применили тактику «пусть чуть хуже, но много стабильнее».
Загнали подзапрос с товарами во времянку, и вторым этапом соединили времянку с виртуальной таблицей остатков (остатки брали строго со всевозможными отборами - тогда еще вольностей себе не позволяли).
Работать стало стабильно.
Даже когда позже начали снижать частоту запуска UPDATE STATISTICS и выкидывать из нее таблицы по одной — все равно работало стабильно.
До сих пор оно так и работает (и наверное не тронет никто.. ибо "работает - не трогай").
Ну и самый типичный случай, не сказать, чтоб «миллионы их»... но полно
Вступайте в нашу телеграмм-группу Инфостарт