Случается стабильно несколько раз в квартал, всегда только на одном и том же сервере (из трех основных рабочих).
Возможно дело в том, что он standart 2012 (с соответствующим ограничением по максимуму оперативки), а может из-за того, что на более всего баз и пользовательских соединений (по количеству).
Симптоматика: «во всех базах сервера все мертво встало». Ехали, ехали, ехали — стоп. И стоит. Всё. Во всех пяти десятках баз.
Поскольку на сервере крутится расчет зарплаты, а также лежит основная бд техподдержки - реакция почти всегда мгновенна. Ночью, правда, не будят — сами спят.. и то хорошо.
Если посмотреть в такой момент в «консоли серверов 1С» сеансы любой причастной бд, упорядочив по «Время вызова (текущее)», то увидим:
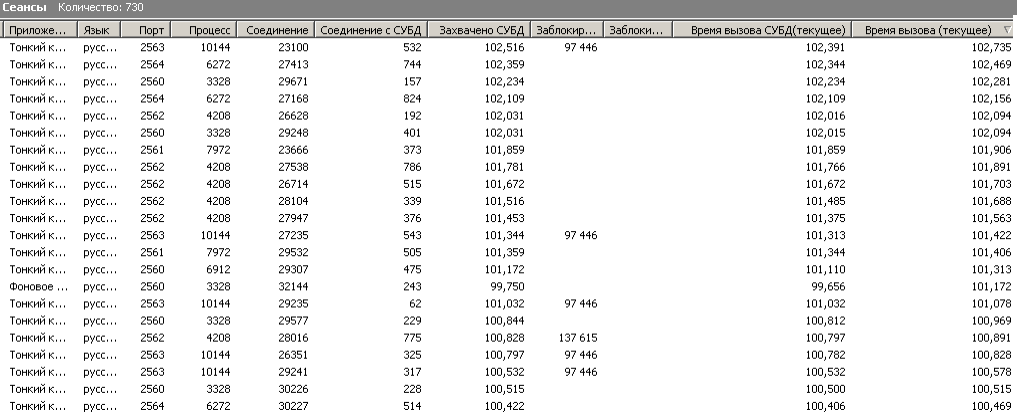
Куча сеансов с большим «Время вызова (текущее)», Время вызова СУБД(текущее) и заполненным «Соединение с СУБД».
Очень напоминает ожидания на блокировках, и блокировки (как автоматические, так и управляемые) в наличии таки часто есть, но являются следствием (не исходной причиной проблем).
Если же смотреть на sql-сервер процедурой exec [sp_WhoIsActive] (или просто «активити монитором») - то картинка примерно такая:
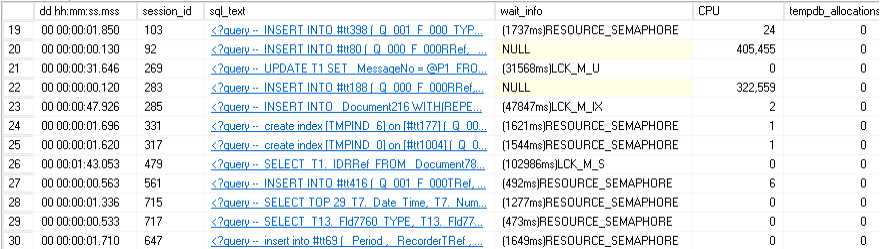
Или вот такая:
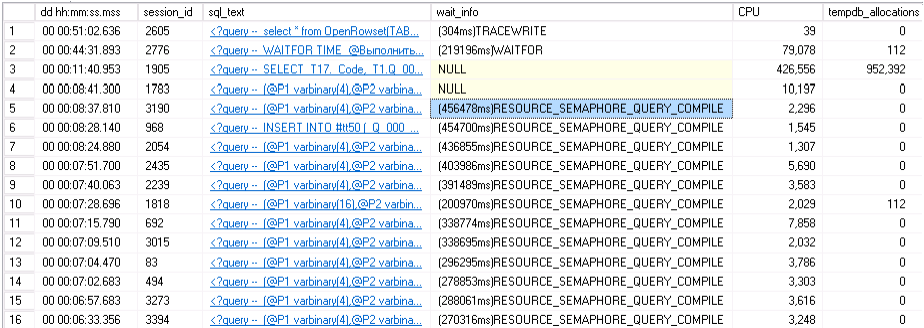
Если отсортировать по «количеству использованной памяти»
exec [sp_WhoIsActive] @sort_order = '[used_memory]
то наверх обычно вываливается три-четыре-пять одинаковых (с точностью до номеров времянок) запросов.
(и вероятно exec sp_BlitzCache @ExpertMode = 1, @SortOrder = 'memory grant' покажет ту же картину. )
Вот искусственно созданный пример:
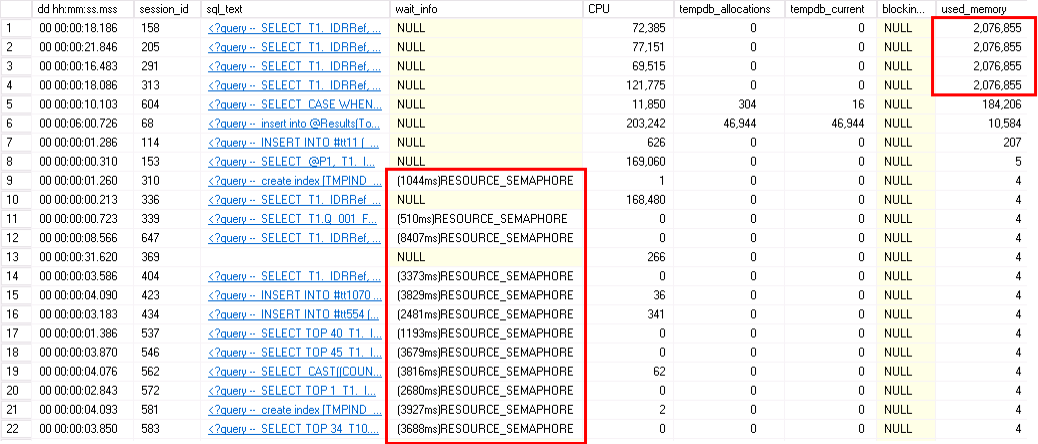
Согласно документации, [used_memory] — для активного запроса — количество восьмикилобайтовых страниц, использованных при выполнении этого запроса
Т.е. 2076855 * 8 Kb ~= 15 Gb.
Выделено 15 Gb на исполнение одного запроса.. а я их для верности четыре штуки запустил.
Минус 60 Gb у сервера.
А этот экземпляр - вообще-то Microsoft SQL Server 2012 Standard Edition — т.е. «Максимальный объем используемой памяти = 64 ГБ»
Глянув на историю sys.dm_os_memory_clerks (что потребляло память sql-сервера ) можно увидеть скачки MEMORYCLERK_SQLQERESERVATIONS (выделение памяти под исполнение запросов: When a query needs memory for sort/hash operations..)
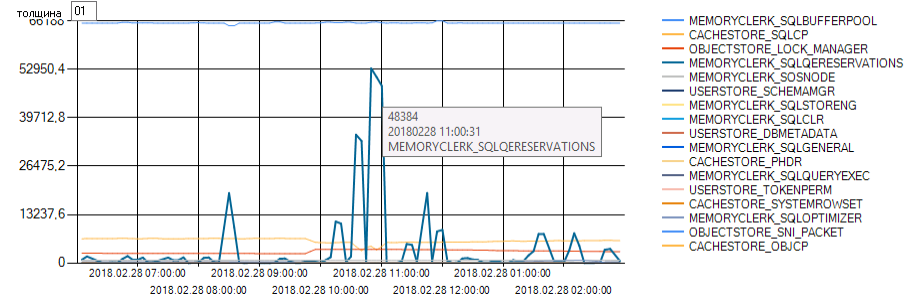
В те же моменты видно снижение выделения памяти под кэш планов исполнения CACHESTORE_SQLCP, а часто и снижение памяти под кеш страниц данных MEMORYCLERK_SQLBUFFERPOOL (на данном графике нет вытеснения страниц данных — только потому, что серверу, который я выбрал для экспериментов, выставили maximum server memory в 110 Gb.. он хоть и стандарт — а все 110 забрал, под буферпул пользует максимальные 64, а прочий объем частью пользуется под все, кроме буферпула, а частью простаивает.. почти всегда.. но, как видите, иногда и идет в дело)
Не знаю точно, есть ли иные причины (интернет намекает, что для RESOURCE_SEMAPHORE_QUERY_COMPILE есть), но чаще всего вижу именно это: запрос (или несколько одинаковых) запускаются, съедают значительный кусок оперативки под исполнение, прочие запросы встают или на стадии компиляции (оно ж тоже хочет память!) , или на стадии исполнения (hash join-ы изрядно могут кушать, Hash Match Aggregate любит память ,а также случается Sort в памяти).
Возникло стремление выявить топ чудесных запросов, потребляющих оперативку.
Сделать это можно с помощью анализа истории представления статистики исполнения sys.dm_exec_query_stats .
Начиная с Service Pack 3 (KB3072779) в Microsoft SQL Server 2012 у представления sys.dm_exec_query_stats появляются новые поля total_grant_kb и total_used_grant_kb — зарезервированная под исполнение и реально использованная запросом память. (ну и понятно, в SQL Server 2016 они уже с самого начала есть, а SQL Server 2014 под рукой нету).
Нам нужно первое, но представляет интерес и второе (об этом ниже) .
Исходная мысль была «найти запросы за проблемный период с максимальным суммарным значением total_grant_kb».
Нашлось несколько запросов со сканами небольших таблиц их последующим hash-соединением.
А ожидаемые запросы, которые были мне вживую видны в ходе проблем через exec [sp_WhoIsActive] @sort_order = '[used_memory] - не нашлись..
Посмотрев на запросы со сканами небольших — понял, что они все быстрые (несколько миллисекунд) и погоды особо не делают.. ну забрал он 100 Mb на 10 мс.. ну так он тут же их отдал, как исполнился.
Мысль трансформировалась в «найти запросы за проблемный период с максимальным суммарным значением (total_grant_kb * время_исполнения_запроса)». Идея, думаю, ясна..
Вот тут-то они все и полезли на свет..
Пример реальных проблем рабочего сервера.
Наблюдались проблемы с бд техподдержки и прочими базами sql-сервера h01 19 и 20 февраля.
В тот день нашел и поправил все "вручную", наблюдениями за сервером с помощью [sp_WhoIsActive], раскопками в журнале регистрации и т.д.
Теперь, спустя некоторое время - пытаюсь найти "корень бед" используя свою систему сбора и анализа информации по производительности серверов.
В процессе допиливаю ее немного напильником..
Смотрим ожидания сервера:
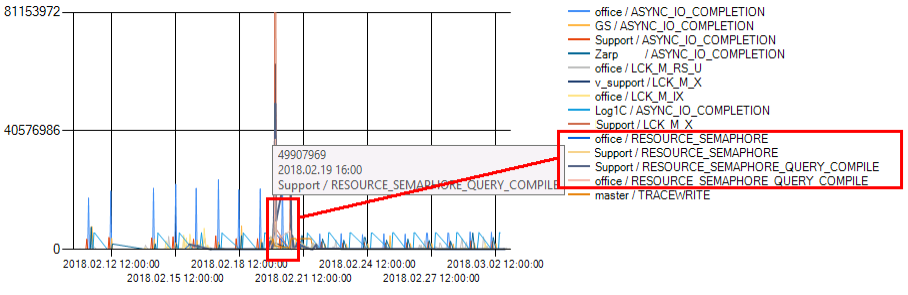
Есть блокировки, и ожидания RESOURCE_SEMAPHORE в наличии.. По блокировкам — убеждаюсь, что Head blocker-ами выступали запросы, повисшие на тех же RESOURCE_SEMAPHORE (как изучались блокировки здесь не разбираю — это отдельная тема).
Смотрю лог sys.dm_os_memory_clerks за те же дни: 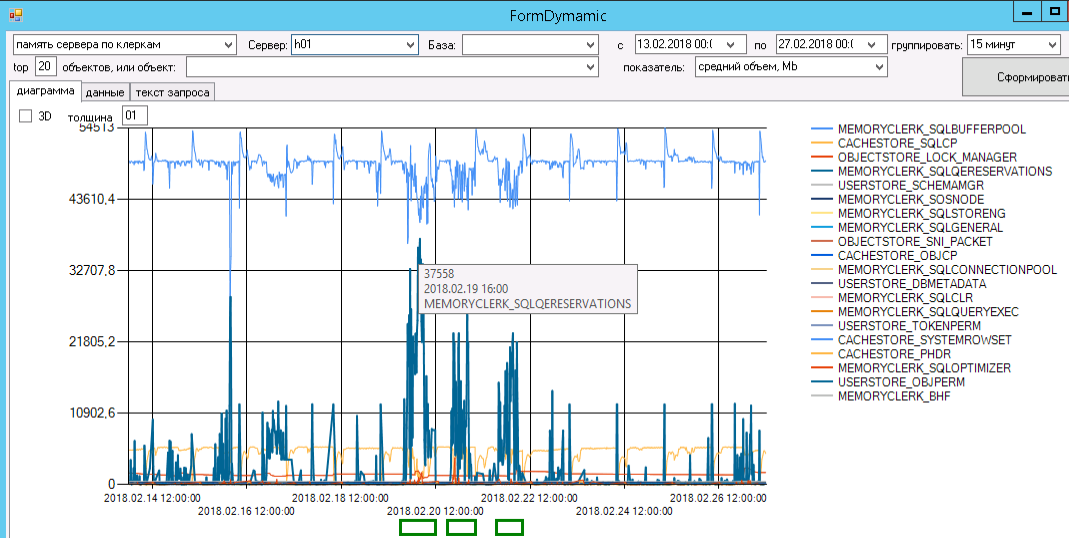
Хорошо видны моменты выделения оперативки под запросы.
Буду изучать три выделенных зеленым периода:
19.02.2018 07:00 — 19:00 (весь день меня эта штука мучила, очень хорошо помню)
20.02.2018 08:00 — 17:00
21.02.2018 08:00 — 17:00
Изучаю первый период, дополнил просмотрщик параметром «Полученная память на время (grant_kb * Duration_ms)».
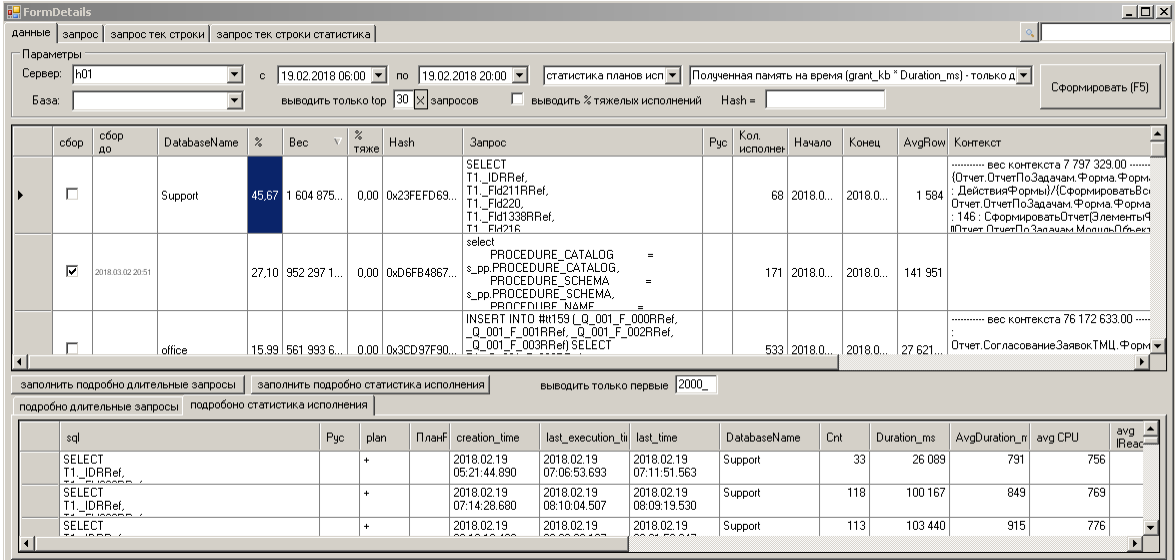
Пара лидеров отлично видна — отчет в базе техподдержки и какое-то странное обращение к sys.spt_procedure_params_view
Третье место можно даже не смотреть пока.
Первый запрос (Отчет.ОтчетПоЗадачам) — довольно тяжелый, по 200 тыс логических чтений.. исполняется за секунду в среднем (есть прыжки до десятка секунд — это следствие тормозов на RESOURCE_SEMAPHORE видимо).
А количество запросов (колонка cnt) – по сто-двести за 30-60 мин (от creation_time до last_execution_time). Отчет популярный. Чего уж там - сам пользуюсь..
Смотрим выделение памяти (прокрутил нижнюю таблицу до нужных колонок)

Сервер выдает (avg grant_kg) по 2.5 Gb на запрос!
А запрос использует (avg used_grant_kg) из этого богатства менее 100 Kb!
В чем дело?
Смотрим текст и план исполнения:
SELECT
T1._СсылкаRRef,
...
FROM
_БизнесПроцесс.Обращение T1 WITH(NOLOCK)
LEFT OUTER JOIN _БизнесПроцесс.Задание T2 WITH(NOLOCK)
ON ((T1._СсылкаRRef = T2._ОбращениеRRef) AND (T2._ОсновноеЗаданиеRRef = @P3))
WHERE
(T1._ПометкаУдаления = 0x00) AND (T1._ИнициаторRRef = @P4)
AND (NOT (((T1._СостояниеRRef IN (@P5, @P6, @P7, @P8, @P9, @P10)))))
AND CASE WHEN (@P11 = @P12) THEN CASE WHEN (@P13 <= T1._Дата) THEN 0x01 ELSE 0x00 END ELSE CASE WHEN ((T1._Дата >= @P14) AND (T1._Дата <= @P15)) THEN 0x01 ELSE 0x00 END END = 0x01
UNION ALL
SELECT
...
FROM
_БизнесПроцесс.Задание T3 WITH(NOLOCK)
LEFT OUTER JOIN _БизнесПроцесс.Обращение T4 WITH(NOLOCK)
ON (T3._ОбращениеRRef = T4._СсылкаRRef)
WHERE
(T3._ИнициаторRRef = @P18)
AND (NOT (((T3._СостояниеRRef IN (@P19, @P20, @P21, @P22, @P23, @P24)))))
AND CASE WHEN (@P25 = @P26) THEN CASE WHEN (@P27 <= T4._Дата) THEN 0x01 WHEN NOT (@P28 <= T4._Дата) THEN 0x00 END ELSE CASE WHEN ((T4._Дата >= @P29) AND (T4._Дата <= @P30)) THEN 0x01 WHEN NOT ((T4._Дата >= @P31) AND (T4._Дата <= @P32)) THEN 0x00 END END = 0x01
ORDER BY
13, 6, 5, 1, 15
План содержит только одно подозрительное место:
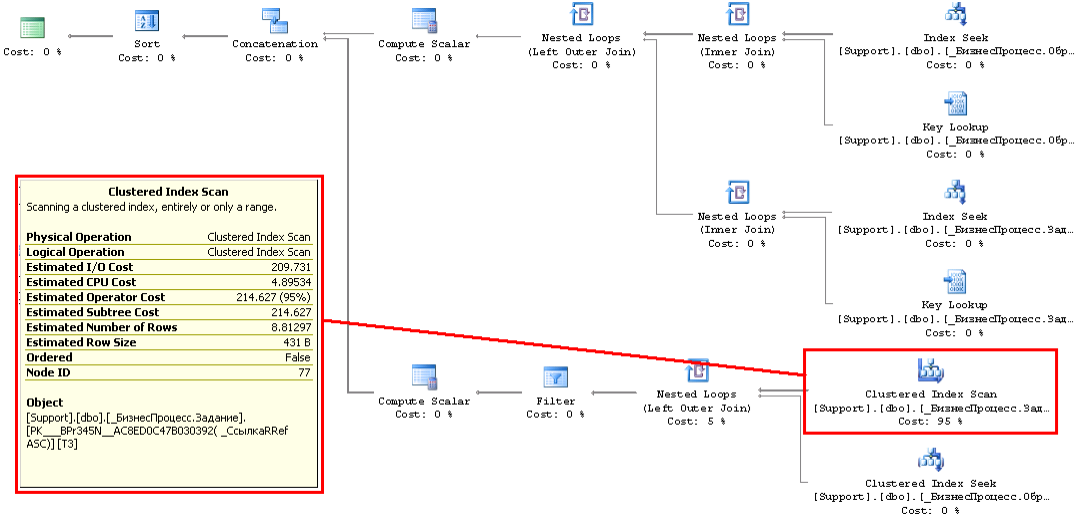 Сканирование кластерного индекса _БизнесПроцесс.Задание с предикатом [_ИнициаторRRef]=[@P18] AND [_СостояниеRRef] <>[@P24] [_СостояниеRRef] <>[@P23] AND [_СостояниеRRef] <>[@P22 ... AND [_СостояниеRRef]<>[@P19]
Сканирование кластерного индекса _БизнесПроцесс.Задание с предикатом [_ИнициаторRRef]=[@P18] AND [_СостояниеRRef] <>[@P24] [_СостояниеRRef] <>[@P23] AND [_СостояниеRRef] <>[@P22 ... AND [_СостояниеRRef]<>[@P19]Индекса по полю Инициатор нету.
Скорее всего кто-то промахнулся он нужен.
Но, несмотря на скан — оптимизатор довольно реалистично оценивает количество возвращаемых сканом строк, Estimated number of rows болтается в районе десяти (с десяток планов посмотрел, за очень разные периоды)... какого ж ему надо гигабайты — неясно. О том, чтоб скан сам по себе требовал память — не слыхал. Возможно, есть какая-нить пессимистичная оценка Estimated number of rows, и по ней выдается память на финальный Sort? Сплошные домыслы.. Может кто в курсе?
Локальный итог, однако, таков : создал требуемый индекс под запрос (он - запрос - такой оказался не один), скан ушел..
Смотрим статистику, вот собственно момент перехода:
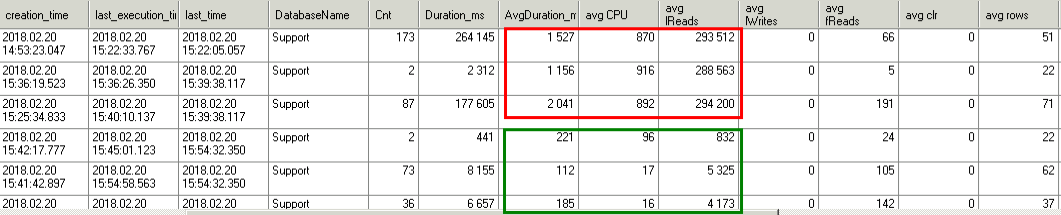
Видно, что запрос становится быстрее, логических чтений на два порядка меньше, CPU потребляет на порядок меньше.. а что с памятью?
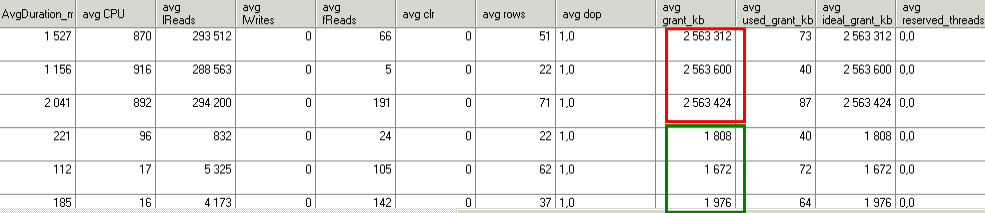
Теперь хочет всего полтора-два мегабайта на экземпляр.. ну отлично. Меня устраивает.
Смена индекса была 20.02.2018 в 15:40, однако подозрительные всплески расхода оперативки на запросы были и далее:
20.02.2018 08:00 — 17:00
21.02.2018 08:00 — 17:00
Тут уже работал странный запрос к sys.spt_procedure_params_view
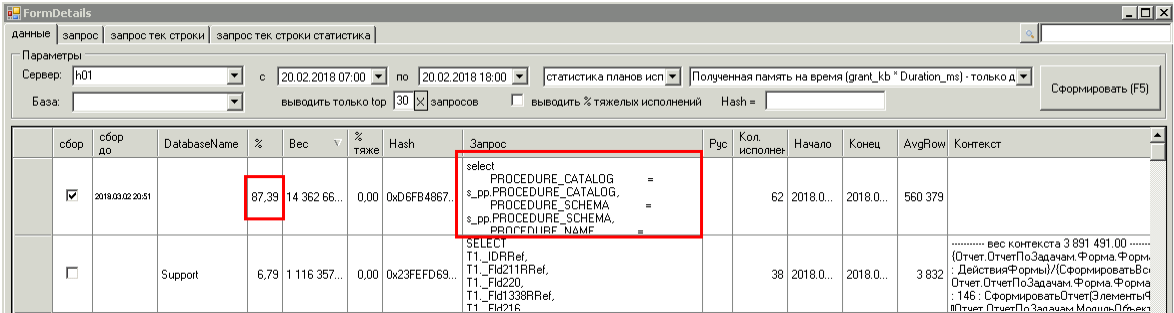
Не вдаваясь в подробности — мне удалось безболезненно нейтрализовать его к вечеру 21.02.2018
После этого живу вроде спокойно (это касается RESOURCE_SEMAPHORE на h01, о прочих аспектах моей жизни такого не скажешь - даже соседи кулачные бои на 23-е устраивали, не говоря уж о проблемах с серверами и кластерами).
Собственно, вот - спустя полторы недели после сбоя я нашел в статистике то, что видел и правил 19 и 20 февраля вживую.
Выводы
Если на sql-серврере в наличии ожидания RESOURCE_SEMAPHORE и/или маловато оперативки — стоит регулярно просматривать топ запросов с максимумом (total_grant_kb * Duration_ms). И править хотя бы откровенные несуразности (вроде того самого скана кластерного).
Эти же запросы могут и обнаружиться в топе длительных, в топе потребляющих CPU, или в топе по логическим чтениям.. а могут и не обнаружиться!
В моем случае ни один из явных лидеров-пожирателей оперативки на всех трех рабочих серверах в передовиках по прочим ресурсам — не присутствовал. Т.е. все мои регламенты (~раз в два-три месяца просмотр/правка длительных, потребляющих CPU, с максимум физ чтений, обслуживание топ 3 блокирующих + раз в неделю обслуживание топ 3 по логическим чтениям) — не имели шансов избавить меня от RESOURCE_SEMAPHORE.
В качестве бонуса — из памяти сервера ушел индекс PK___BPr45N__AC8ED0C47B030392
Вот топ 7 индексов/куч в памяти (в буферпуле) sql-сервера h01 за период:
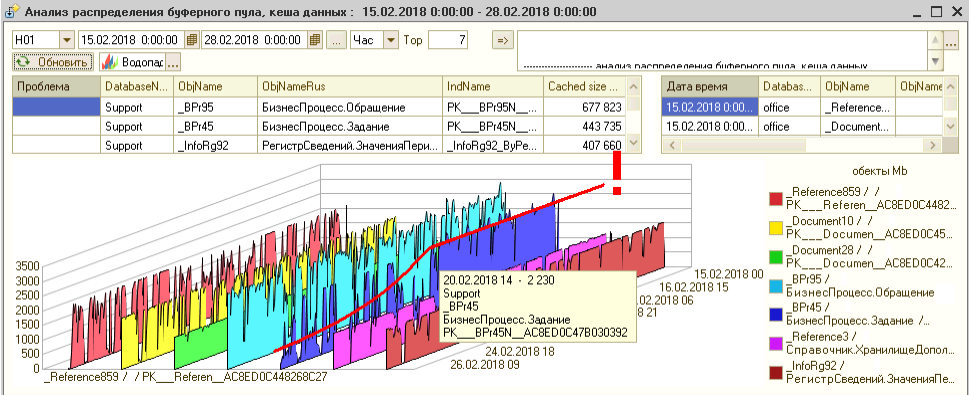
До 20.02.2018 кластерный таблицы [БизнесПроцесс.Задание] постоянно торчал в буферпуле сервера, отжирая 2.2 Gb
Убрав сканирующий его запрос — освободил и память (понятно, тот запрос был не один такой — но все равно эффект заметен)
Наверное, будет в какой-то мере работать и обратное.. Анализируя наполнение буферпула и убирая наиболее вопиющие сканирующие запросы — есть вероятность уменьшить прыжки MEMORYCLERK_SQLQERESERVATIONS и соответственно снизить риск RESOURCE_SEMAPHORE.
P.S.:
Поизучал на своих рабочих и тестовых серверах запросы, требующие оперативку.
И условно раздел их на четыре группы.
1. Оно им и правда надо. Здоровенные, неповоротливые, исполняются раз в день — но по нескольку часов. Статистические расчеты. Заливки olap-кубов. Отчеты за год-два по всей сети по всем товарам. Переливки данных. Вот такое тоже лезет: Рег.УстановитьПериодРассчитанныхИтогов(ПериодРассчитанныхИтогов_Новый);
Вот так выглядит:
Вот так выглядит:

Данный запрос хочет на исполнение вообще 900 Gb.. ему дают 45.. и он исполняется 4 часа.
Это заливка куба на сервере со статистикой, к 1С не имеет отношения вообще.
План исполнения этого монстра в монитор не лезет, ни по высоте, ни по ширине.. а однако большой у меня монитор..
Обычно такие запросы и так уже в фокусе внимания (гляньте на количество чтений и расход CPU..).
Что тут скажешь.. не держите оперативных oltp-баз на одном сервере со статистическими olap-базами. А если уж деваться некуда — следите за количеством оперативки и ядер, да и версии standart и express не для этого варианта.
2. Откровенные косяки, с пропущенным индексом, со сканом и последующим hash match или sort. Они не слишком крупны / часто запускаемые, чтоб быть замеченными в топ 10 по потреблению CPU, или в топах по логическим и физическим чтениям.. но они есть, и они крадут память.
Вот такое например:
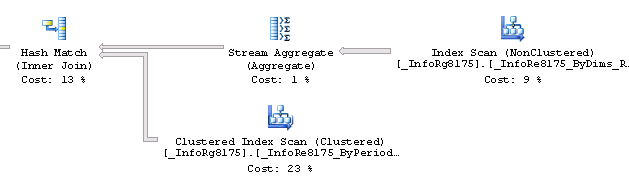

Три с половиной мегабайта — немного, но количество исполнений в течение 10 мин = 3-10 тыс — мое почтение..
Бывает и по-другому: исполняется раз в минуту, но желает гигабайт..
Причем, большей частью такое исправляются легким указанием «индексировать» в конфигураторе у соотвествующего поля нужного объекта.
Такие надо выявлять да чинить..
3. Непонятности, похожие на ошибки оптимизатора. Вроде нормальный план, правда, обязательно со сканом. Но при этом скан небольшой таблицы, Estimated number of rows от Actual number of rows близки к нулю.
Вот такое:
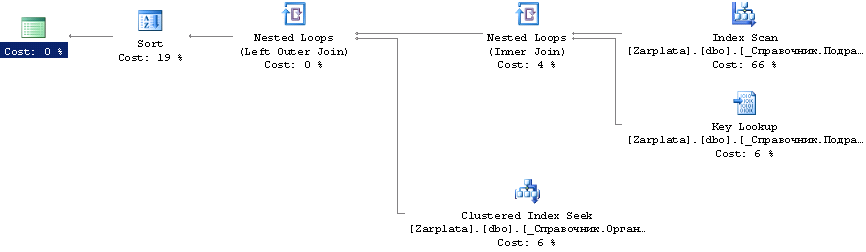
Стрелки тонкие, Estimated number of rows везде =1 , в реальном плане Actual number of rows тоже близко к 1.
С чего ж он хочет гигабайт и не использует потом из него совсем ничего?

Похожий случай мне и попался на h01
Оказывается, их таких довольно заметное количество.
4. Слеты планов
Когда план "ломается" — тоже, оказывается, может случается расход оперативки.
Оно и понятно — вылез скан вместо поиска, а следом сорт..

PPS:
Накаркал, дописался статей..
02.03.2018 в 13:30 на единственном рабочем
Microsoft SQL Server 2012 (SP3) (KB3072779) - 11.0.6020.0 (X64)
Oct 20 2015 15:36:27
Copyright (c) Microsoft Corporation
Enterprise Edition: Core-based Licensing (64-bit) on Windows NT 6.3 <X64> (Build 9600: )
Oct 20 2015 15:36:27
Copyright (c) Microsoft Corporation
Enterprise Edition: Core-based Licensing (64-bit) on Windows NT 6.3 <X64> (Build 9600: )
230 Gb оперативки
случился RESOURCE_SEMAPHORE:
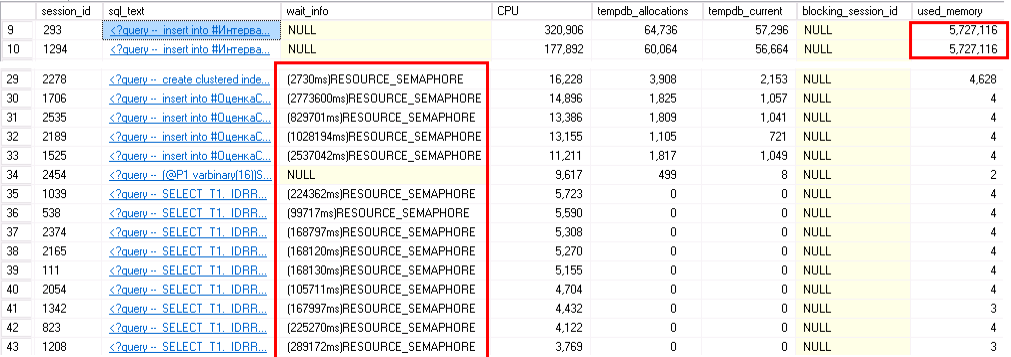
В пятницу, в полдень ближе к вечеру.. традиция.
Зафиксировал текст / источник / объект / автора, убил сессии, запретил запускать.
В понедельник буду разбираться.. есть надежда, что план исполнения "испортился"..
Вступайте в нашу телеграмм-группу Инфостарт