Меня зовут Андрей Бурмистров. Я читаю курс по повышению производительности 1C команды gilev.ru – занимаюсь обучением людей тому, как ускорять 1С и решать проблемы производительности. И сегодня я хочу поделиться с вами опытом создания нашей командой инструмента по автоматическому поиску проблем в коде (в частности, в запросах), с возможностью анализа способов решения этих проблем.
Предпосылки создания инструмента

Сбор данных для анализа оптимальности работы системы уже давно автоматизирован. Но анализ этих данных и выдача рекомендаций по нему, как правило, всегда производится человеком. Причем, этот анализ, конечно, стоит ощутимых денег, потому что эта работа довольно-таки творческая, а людей, профессионально занимающихся оптимизацией, не так много. Заказчик, естественно, хотел бы затраты на такую оптимизацию снизить. Отсюда вытекает следующее решение – сделать выявление неоптимального кода максимально автоматическим.

Когда я готовил доклад, мне вспомнилась первая производственная революция – было много ручного монотонного труда, в результате которого продукт получался долго и не всегда постоянного качества, т.е. он мог быть лучше или хуже. Большую роль играл человеческий фактор.
С оптимизацией сейчас у нас такая же ситуация. До сих пор для многих ускорение, оптимизация – это невидимое шаманство. Люди произносят какие-то тайные слова, что-то делают, и в итоге система начинает работать быстрее.
Хочется все это как-то упростить и сделать работу по оптимизации системы намного быстрее и качественнее – с тем же эффектом, как у производственной революции в свое время.
В итоге мы решили автоматизировать анализ запросов в системе.
Вроде бы, все понятно – есть код конфигурации и текст запроса. Берем код, ищем там запросы, выделяем неоптимальные места – ничего сложного.
Но мало того, что нужно найти эти неоптимальные места автоматически, а не вручную, как это сейчас делается в большинстве случаев, нужно еще и дать рекомендации, как это исправить.

Изначально инструмент задумывался для того, чтобы упростить жизнь программистам и снизить к ним требования по наличию серьезных знаний в SQL – чтобы они могли увидеть, какая у них проблема, и узнать порядок действий по ее устранению.

Мы решили реализовать систему, которая, опираясь на опыт экспертов в области оптимизации запросов, предложит решение проблем производительности. Разрабатываемый продукт должен упростить жизнь программиста, который, конечно, по-прежнему должен уметь получить один и тот же результат, написав разные варианты запроса, но ему уже не придется «тыкаться» вслепую.

На прошлой конференции уже затрагивалась тема о том, можно ли по тексту запроса, не выполняя его, автоматически понять, что в нем не так. Ответ в тех или иных интерпретациях звучал один – пока такого сделать нельзя.
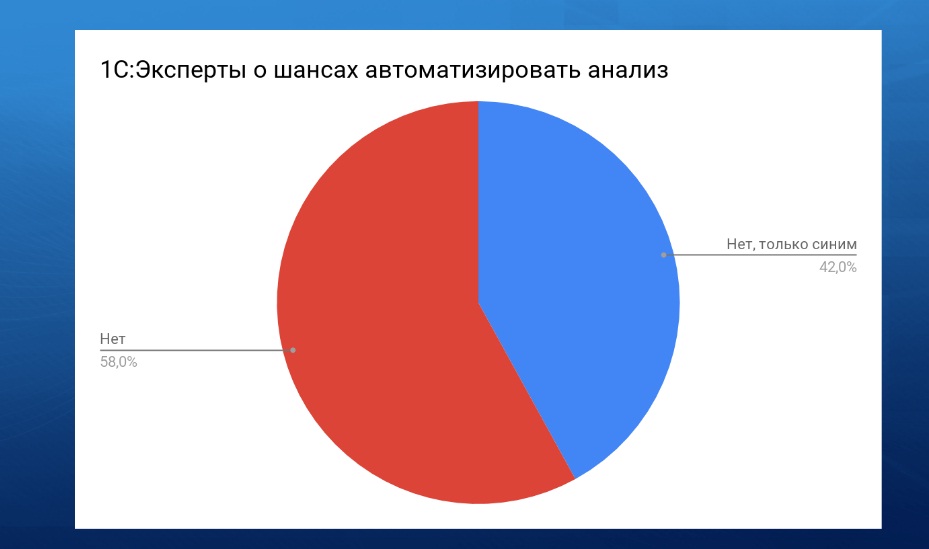
Тем более, оценить стоимость разработки инструмента для такого анализа не просто, это – как посчитать, сколько денег стоит научное открытие. Хотя, если попотеть и потратить на это несколько сотен часов, то такой инструмент сделать можно.
Первые трудности

Однако как только мы принялись за дело, обнаружилось очень много подводных камней.
Сначала мы хотели реализовать анализ с помощью схемы запроса, которая уже есть в 1С – хотели подставлять в схему запроса текст, чтобы она его разбирала на блоки, и мы их потом пытались анализировать. Мы попробовали этот способ, и оказалось, что он практически неприемлем. Он очень топорный, простой, примитивный, и сделать какой-то анализ на основании схемы запроса практически нереально. Поэтому мы решили строить дерево запроса по тексту запроса самостоятельно, своими силами.
Также у нас было пожелание, чтобы весь инструмент целиком был написан на коде 1С. Но на 1С это работало очень медленно, поэтому сейчас мы строим дерево запроса, используя возможности Java. Надо отметить, что если бы наш человек, который писал код, не занимался Java, мы бы этот инструмент, наверное, так и не написали до сих пор.

Еще одним подводным камнем для нас оказалась неоднозначность рекомендаций, которые должна выдавать наша система. Например, если есть запрос, который сканирует данные – это возможно плохо, а возможно и хорошо. Если это хорошо, то для кого это хорошо? Если у вас используется небольшая таблица, или вы из нее выбираете 90% данных, то какому-то одному пользователю это будет хорошо, зато всем остальным будет плохо, потому что, если запрос в транзакции, то он блокирует данные.
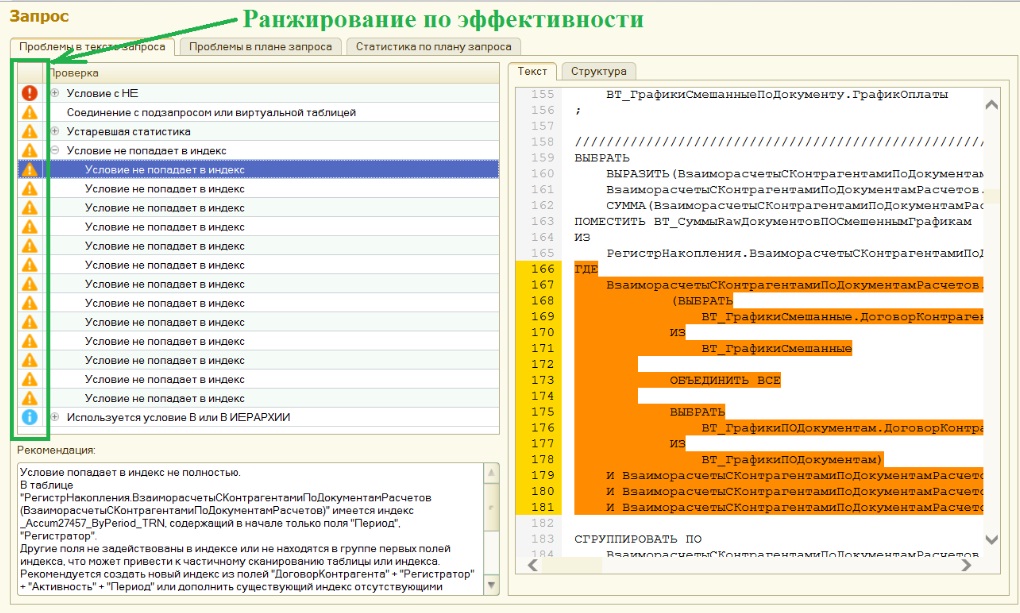
Или, допустим, мы сделали автоматический анализ какого-то запроса с множеством неоптимальных мест – получили список рекомендаций. Здесь тоже не все однозначно – есть рекомендации только для частных случаев, а есть те, которые носят гарантированный характер. Нам надо понимать, какие ошибки в этом запросе являются более, а какие менее критичными, и ставить в этом списке выше те, которые более критичны.
Сейчас мы выводим рекомендации в виде дерева по типам, и для каждого типа даем визуальное обозначение эффективности иконками.
Основные принципы работы инструмента

Чтобы улучшить рекомендации в неоднозначных ситуациях, мы используем два разных подхода, которые дополняют друг друга – проактивный и реактивный.

Проактивный подход основан на прогнозных алгоритмах. Это когда у нас есть текст запроса, и мы анализируем этот текст, не выполняя его. Например, мы можем проанализировать программный модуль на 20 000 строк кода и найти по тексту в нем неоптимальные места.

А реактивный подход позволяет нашему инструменту в своих рекомендациях учитывать те явные факторы, которые влияют на решение оптимизатора запросов – например, статистику строк в таблице, распределение количества строк по значениям колонки, наличие подходящих индексов. Все, что по нашему мнению собирает оптимизатор запросов для принятия решения, должны собирать и мы.

Когда мы сделали первый прототип инструмента, наши клиенты пожелали видеть в нем анализ не просто отдельных запросов, а всей конфигурации целиком. Поэтому сейчас мы выгружаем конфигурацию в текстовые файлы и пытаемся найти в ней все неоптимальные запросы. Пока что наш инструмент работает только с запросами, но развивать его можно бесконечно.
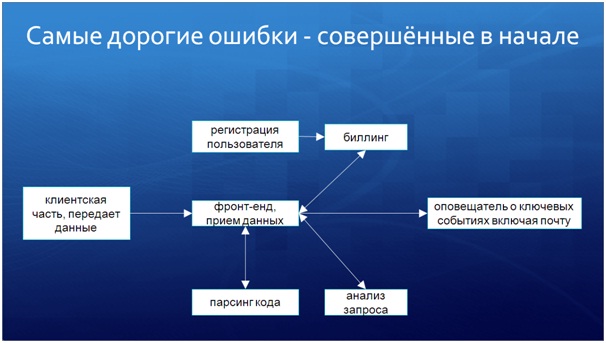
На слайде показана модульная архитектура нашей системы. Все обозначенное квадратами – это самостоятельный отдельный код или информационная база. В плане надежности мы не стали «класть все яйца в одну корзину», и тем самым усилили отказоустойчивость системы, поскольку одна из баз провоцировала падения платформы 1С, а модульный подход позволил минимизировать влияние этих падений на систему в целом.

Анализ всей конфигурации для поиска проблем в ней – задача нетривиальная. Представьте, что у вас есть текстовый файл с 20 000 строк программного кода, и вам нужно выбрать оттуда запросы. Как это сделать? Регулярки? Просто найти запросы по ключевым словам? Если мы хотим в будущем научить инструмент находить в коде запросы в цикле и анализировать их, то здесь регулярки нам уже не помогут.
В результате, наш инструмент анализирует программный код и строит из него синтаксическое дерево – разбирает по кускам код в дерево значений.
С этим деревом значений мы можем понимать логику работы кода и очень подробно анализировать структуру программного модуля – можем находить запросы в цикле, отдельные запросы и даже, если постараться, можем собирать динамически формируемые запросы.

Сначала мы решили реализовать наш инструмент целиком на 1С. Но представьте себе текстовый модуль на 30 000 строк, по которому надо построить синтаксическое дерево – на языке 1С даже на мощном оборудовании это выполнялось очень долго.
Поэтому мы реализовали сервис, который превращает программный модуль в дерево с помощью кода на Java. Это сразу дало ускорение в 14 раз как минимум.
Поэтому, если вдруг вы на 1С решаете какие-то задачи, не связанные напрямую с учетом, а связанные, например, с обработкой больших объемов текстовых данных – подумайте о других инструментах, не об 1С. Это даст вам ускорение не то что в разы, а на порядки.
Разбор конфигурации – это очень затратная операция.
Например, первая наша попытка декомпозировать УПП дала 90 гигабайт, несмотря на то, что исходный код в сотни раз меньше по объему. Да, это очень подробно, и позволяет потом обращаться вплоть до строчки кода, но эта операция очень недешевая, поэтому мы сделали систему самообучающейся. При разборе конфигурации программный модуль сохраняется, и, если в систему поступает такой же программный модуль, он уже не разбирается, а берется из кэша, и анализ происходит на порядки быстрее.
Аналогичный способ вы можете использовать при анализе больших блоков данных, например, при работе с очень сложными отчетами – перед анализом вы можете сделать хэш этих данных и, если поступает запрос на получение данных с таким же хэшем, вы можете брать готовый обработанный результат. Это позволяет экономить ресурсы. Например, если отчет формируется один час, а через два часа пользователь с теми же настройками делает тот же отчет, то, если в течение этого часа в системе ничего не менялось (не менялись те данные, которые влияют на отчет), тогда берется результат предыдущего отчета – пользователю не нужно ждать еще один час.
Подводные камни, с которыми мы столкнулись
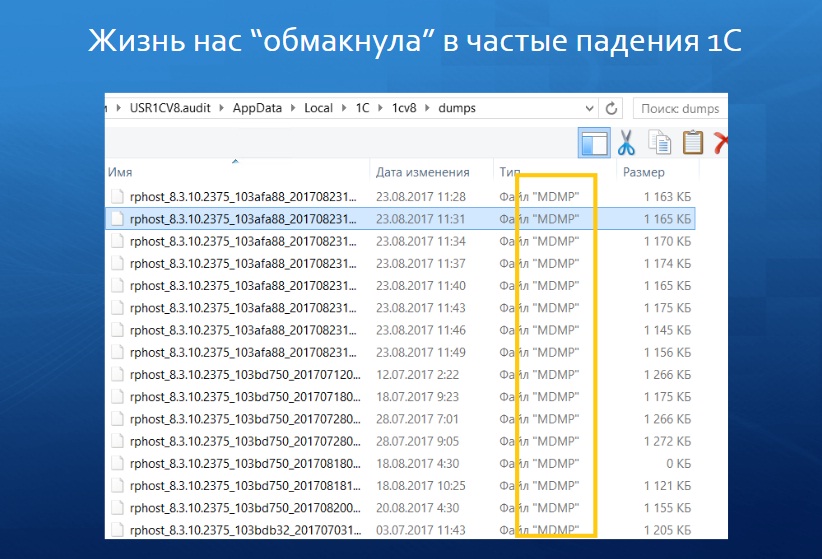
Мы столкнулись с проблемой падений 1С, которые иногда были вообще неочевидные.

Выяснили интересную особенность. В конфигурации был код, который показан на слайде – это функция, которая либо возвращает значение, либо вызывает исключение. И, почему-то, если при вызове этой функции была высокая вложенность, то в последней строке, когда результат функции присваивается переменной, возникало исключение. Причем, эта ошибка была не повторяемая, воспроизводилась не в 100% случаев.
Если у вас где-нибудь используется подобная конструкция, то от нее лучше избавляться. Даже если обернуть ее в «Попытку-Исключение», она все равно приводит к падению. Видимо, есть какая-то ошибка платформы – когда-то воспроизводится, когда-то нет.

Кроме этого, мы столкнулись с утечками памяти. Дело в том, что, поскольку код по анализу получился довольно большим и сложным, частично сформированным автоматически, мы не могли уследить, что есть структура, внутри которой есть массив, внутри которого есть дерево значений, а где-то в строке дерева значений есть ссылка на сам массив или на саму структуру. И, когда процедура заканчивалась, память от этих вложенных структур не освобождалась. Для нейтрализации таких ситуаций мы написали код, который все эти вложенные коллекции перед выходом из процедуры очищает.
Если вы тоже пишете конструкции, где используется большое количество вложенных друг в друга коллекций, у вас тоже есть высокий риск утечек памяти. Тем более, если у вас уже есть утечки памяти, проверьте, где у вас используется подобное. Для подстраховки можно написать очистку, чтобы коллекции при выходе из процедуры всегда чистились.

В итоге у нас получилась модульная система, в которой часть данных обрабатывается в одном сервисе, на одном компьютере, часть – в другом, часть – в третьем. Это было сделано специально, чтобы при падении одной части другие работали независимо. Но при этом нам приходилось передавать между сервисами большое количество данных. Например, запрос в «ЗУП» может весить несколько десятков мегабайт, и его при анализе конфигурации надо передавать между сервисами. Естественно, это происходило долго.
- Сначала мы большое дерево значений для передачи в сервис сериализовывали с помощью «ЗначениеВСтрокуВнутр» – объем данных получался большой.
- После этого мы решили сначала помещать дерево значений в хранилище значений, и потом уже для хранилища значений делать «ЗначениеВСтрокуВнутр» – объем данных стал гораздо меньше, чем первый.
- Есть подозрение, что если мы загрузим дерево значений в XML, потом XML упакуем в хранилище значения, для которого сделаем «ЗначениеВСтрокуВнутр» и этот результат будем передавать, то объем данных будет еще меньше.
Если у вас есть разные сервисы, и вы занимаетесь обменами, посмотрите в сторону хранилища значений. Не станет ли объем данных для передачи в этом случае меньше? Нам это дало очень сильный выигрыш. У нас были большие объемы, и скорость очень влияла.

Также мы столкнулись с тем, что справочники в системе получались очень большие. Представьте себе «УПП» в разобранном виде – это программные модули, объекты метаданных с множеством свойств. В таком виде конфигурация на диске занимает 90 Гб.
Сначала этот справочник был каких-то необъятных размеров, причем его индексы были гораздо больше, чем сами данные. Нам пришлось перестроить эту структуру. Мы поняли, например, что такие служебные индексы, как «Наименование» и «Код» в нашей ситуации не актуальны, поэтому наименование мы сократили до нуля, чтобы платформа для него индекс не создавала.
Еще одно интересное наблюдение – если у справочника текстовый тип кода, то объем индекса будет гораздо больше, чем у числового. Если код вообще не нужен (или не нужен контроль уникальности в справочнике по коду), то его можно вообще убрать. Это экономит очень много места. Особенно, если справочник у вас подчиненный.
Убрав лишние индексы, мы сэкономили сотни гигабайт, потому что у нас анализируются очень большие конфигурации – это «УПП», «ЗУП» и прочие. Это дало нам очень большой выигрыш.
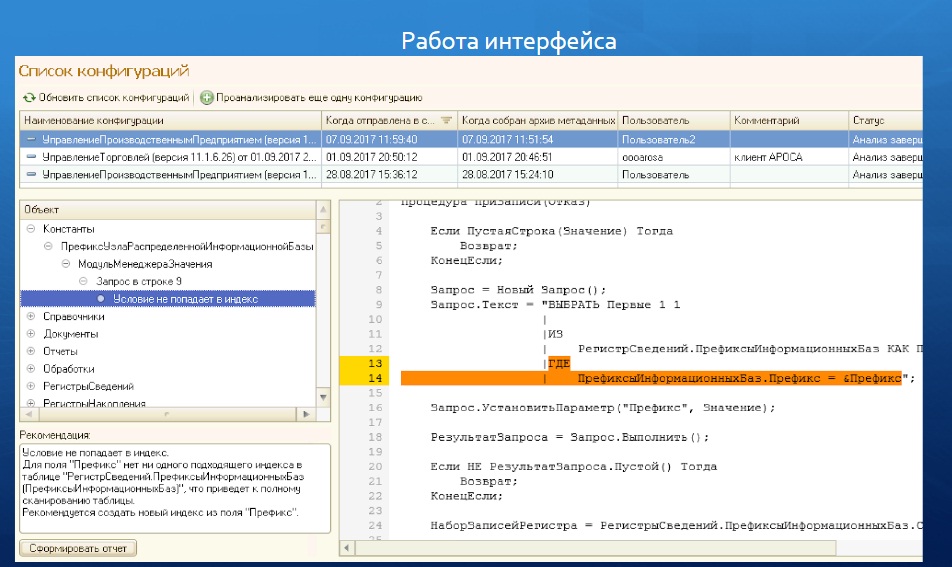
Интересная ситуация получилась с работой интерфейса.
Напомню, мы сделали инструмент, который показывает вам неоптимальные места не просто в запросе, а в коде всей конфигурации. Как видно на слайде, слева отображается некий аналог дерева конфигурации, а справа – место в коде. Но представьте, что программный модуль у вас занимает, допустим, 50 000 строк, и вам при клике с одной стороны нужно моментально и быстро отобразить данные с другой стороны, при этом подсветить, в какой строке проблема. Сначала это было сделано типичным для 1С образом, т. е. с сервера все дерево с данными передавалось на клиент. Это было невыносимо долго. Даже не пять и не десять секунд, а вплоть до минуты. Скорость была очень низкая. Наша ошибка заключалась в том, что все эти тысячи строк дерева человек вряд ли вообще откроет – он посмотрит лишь ограниченное количество строк дерева, а остальные никогда не откроет. Это – «избыточный» переданный объем. После оптимизации дерево рекомендаций стало открываться практически мгновенно.
Подсветку для проблемных строк запроса мы реализовали с помощью HTML-документа, но, чтобы быстро сформировать такой HTML-документ из программного модуля, нам тоже пришлось постараться.
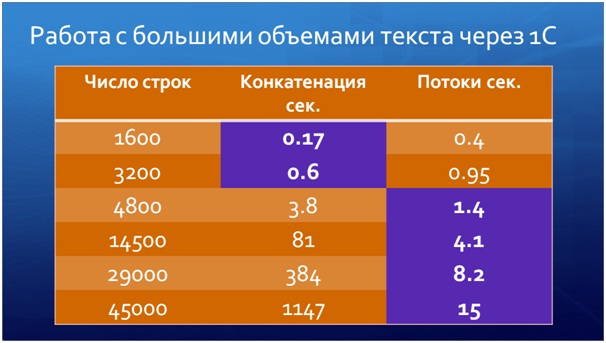
Представьте, что у вас есть 50 000 строк текста, из которого вам нужно сделать HTML-документ – для этого вам нужно перебрать все строки в цикле, и на выходе получить HTML-документ. Самый простой способ – это конкатенация строк, и, если строк относительно мало (допустим, 1 500), то конкатенация работает приемлемо, 3 000 строк – уже обрабатываются примерно половину секунды, а если строк становится больше 5 000, то конкатенацию использовать уже неоптимально.
В 8.3.10 появилась замечательная возможность работы с потоками. Дело в том, что новый объект «Поток данных» работает с памятью немного иначе, чем строки. И поэтому при работе с большими объемами данных (большими объемами строк), как в этом случае, он значительно выигрывает.
На слайде вы можете увидеть, какая получается разница. Когда 45 000 строк, конкатенацию можно не дождаться несколько минут, а потоки работают всего лишь за 15 секунд. Это я к тому, что наверняка у кого-то 1С используется не только для задач автоматизации учета. Может быть, вы на 1С еще какие-то интересные задачи автоматизируете. Есть такой новый объект – можете его использовать, в некоторых случаях он дает очень ощутимый эффект при работе со строками.
Что ускорить не получилось

К сожалению, некоторые моменты в нашем инструменте ускорить не получилось, даже нам с нашим опытом.
Например, это отчет по проблемным местам. Берем конфигурацию, загоняем ее в инструмент, он ее анализирует. В итоге, можно либо интерактивно посмотреть, какие там проблемы, либо сформировать отчет и потом его почитать, отправить по почте руководству. Сам отчет формируется где-то 1% времени, а остальные 99% времени платформа 1С просто сохраняет этот отчет в XLS. Это происходит долго и, к сожалению, повлиять на это нельзя. Если вы планируете формировать и сохранять в Excel какие-то отчеты, где несколько тысяч строк, будьте готовы к тому, что это будет долго.
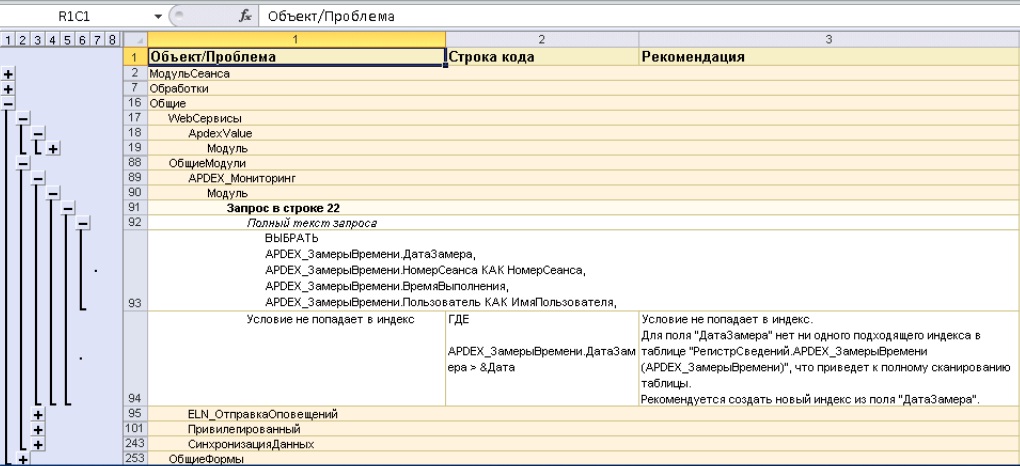
На слайде показан пример такого отчета по проблемным местам. Видно:
- объект, в котором есть какая-то проблема;
- модуль, который эту проблему содержит;
- строка в этом модуле;
- сам проблемный текст запроса;
- и отображается рекомендация, которая позволяет решить эту проблему.
Выполняете рекомендацию, и проблема уходит.
Заключение

Для интереса мы решили прогнать через инструмент несколько типовых конфигураций.
В типовой «1С:Бухгалтерии» у нас, например, получилось где-то 2000 с лишним потенциально проблемных мест. Это говорит о том, что даже если конфигурация типовая – это не значит, что она будет работать быстро, идеально и т.д. Ее код все равно пишут живые люди, и даже в типовых конфигурациях есть потенциальные возможности для оптимизации.

В итоге, я хочу отметить, что пока в области оптимизации слишком много ручного труда. Но сейчас наблюдается тренд, когда эта область автоматизируется. Мы начинаем делать буквально первые шаги в этом направлении, создавая инструменты для автоматизации анализа неоптимальности в коде. И, возможно, в ближайшее время у нас появятся несколько инструментов, способных находить такие проблемы автоматически. На мой взгляд, именно за этим будущее.
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2017 COMMUNITY.

Вступайте в нашу телеграмм-группу Инфостарт