





Есть у нас регистр сведений с атрибутами документов. Строк в нем примерно 250 000 000. Да, миллионов. И иногда возникает естественное желание этим регистром воспользоваться. Например, так:
ВЫБРАТЬ
Документы.ИД КАК ИД,
Срез_1.Значение КАК Атрибут1,
Срез_2.Значение КАК Атрибут2,
Срез_3.Значение КАК Атрибут3
ПОМЕСТИТЬ
ДокументыСАтрибутами
ИЗ
Документы КАК Документы
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.АтрибутыДокументов.СрезПоследних(&ПериодСреза,
Атрибут = ЗНАЧЕНИЕ(Перечисление.АтрибутыДокументов.Атрибут1)) КАК Срез_1
ПО Документы.ИД = Срез_1.ИД
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.АтрибутыДокументов.СрезПоследних(&ПериодСреза,
Атрибут = ЗНАЧЕНИЕ(Перечисление.АтрибутыДокументов.Атрибут2)) КАК Срез_2
ПО Документы.ИД = Срез_2.ИД
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.АтрибутыДокументов.СрезПоследних(&ПериодСреза,
Атрибут = ЗНАЧЕНИЕ(Перечисление.АтрибутыДокументов.Атрибут3)) КАК Срез_3
ПО Документы.ИД = Срез_3.ИД
Опытный 1С-ник сразу видит, что три соединения с виртуальной таблицей противоречат стандартам разработки и хочет это оптимизировать. К тому же, нет условий на документы внутри срезов, что дает повод задуматься о производительности.
Программист идет в профайлер, смотрит время текущей версии запроса и видит это:
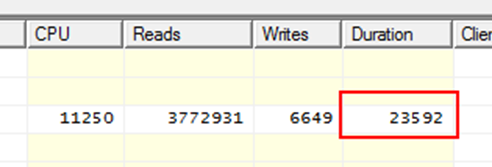
23 секунды, немного. Но и немало.
Пишет запрос, который выбирает атрибуты документов во временную таблицу. Добавляет условие по документам внутрь среза, потому что «так правильно» (https://its.1c.ru/db/metod8dev#content:2594:hdoc).
ВЫБРАТЬ
Срез.Атрибут КАК Атрибут,
Срез.ИД КАК ИД,
Срез.Значение КАК Значение
ПОМЕСТИТЬ
ВТЗначАтрибутов
ИЗ
РегистрСведений.АтрибутыДокументов.СрезПоследних(&ПериодСреза,
Атрибут В (ВЫБРАТЬ ВТ1.Атрибут ИЗ ВТАтрибуты как ВТ1)
И (ИД)
В (
ВЫБРАТЬ
Документы.ИД
ИЗ
Документы
)
) КАК Срез
И соединяет полученную таблицу с документами
ВЫБРАТЬ
Документы.ИД КАК ИД,
Срез_1.Значение КАК Атрибут1,
Срез_2.Значение КАК Атрибут2,
Срез_3.Значение КАК Атрибут3
ПОМЕСТИТЬ
ДокументыСАтрибутами
ИЗ
Документы КАК Документы
ЛЕВОЕ СОЕДИНЕНИЕ ВТЗначАтрибутов КАК Срез_1
ПО Срез_1.Атрибут = ЗНАЧЕНИЕ(Перечисление.АтрибутыДокументов.Атрибут1)
И Документы.ИД = Срез_1.ИД
ЛЕВОЕ СОЕДИНЕНИЕ ВТЗначАтрибутов КАК Срез_2
ПО Срез_2.Атрибут = ЗНАЧЕНИЕ(Перечисление.АтрибутыДокументов.Атрибут2)
И Документы.ИД = Срез_2.ИД
ЛЕВОЕ СОЕДИНЕНИЕ ВТЗначАтрибутов КАК Срез_3
ПО Срез_3.Атрибут = ЗНАЧЕНИЕ(Перечисление.АтрибутыДокументов.Атрибут3)
И Документы.ИД = Срез_3.ИД
Здесь небольшое отступление, чтобы восполнить пробелы в структурах данных.
Таблица с атрибутами содержит 3 строки со значениями перечислений.
ВЫБРАТЬ
ЗНАЧЕНИЕ(Перечисление.Атрибуты.Атрибут1) КАК Атрибут
ПОМЕСТИТЬ ВТАтрибуты
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
ЗНАЧЕНИЕ(Перечисление.Атрибуты.Атрибут2)
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
ЗНАЧЕНИЕ(Перечисление.Атрибуты.Атрибут2)
ИНДЕКСИРОВАТЬ ПО
Атрибут
Таблица «Документы» довольно большая, там 300 000 строк. Колонок в ней немного, для данного примера это неважно.
ВЫБРАТЬ
Док.ИД КАК ИД
ПОМЕСТИТЬ
Документы
ИЗ
Документ.Какой_то_документ
ГДЕ
Какие-то условия
Довольный 1С-ник запускает новый запрос в надежде получить значительный прирост скорости и немигающим взглядом смотрит в монитор:
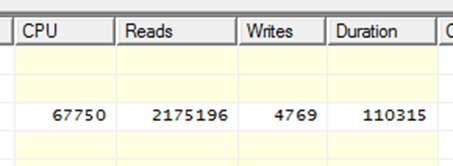
Хуже в 5 раз. Почему? Да потому что количество атрибутов разное. Атрибут 1 – 2000, Атрибут 2 – 120 000, Атрибут 3 – 120 000.
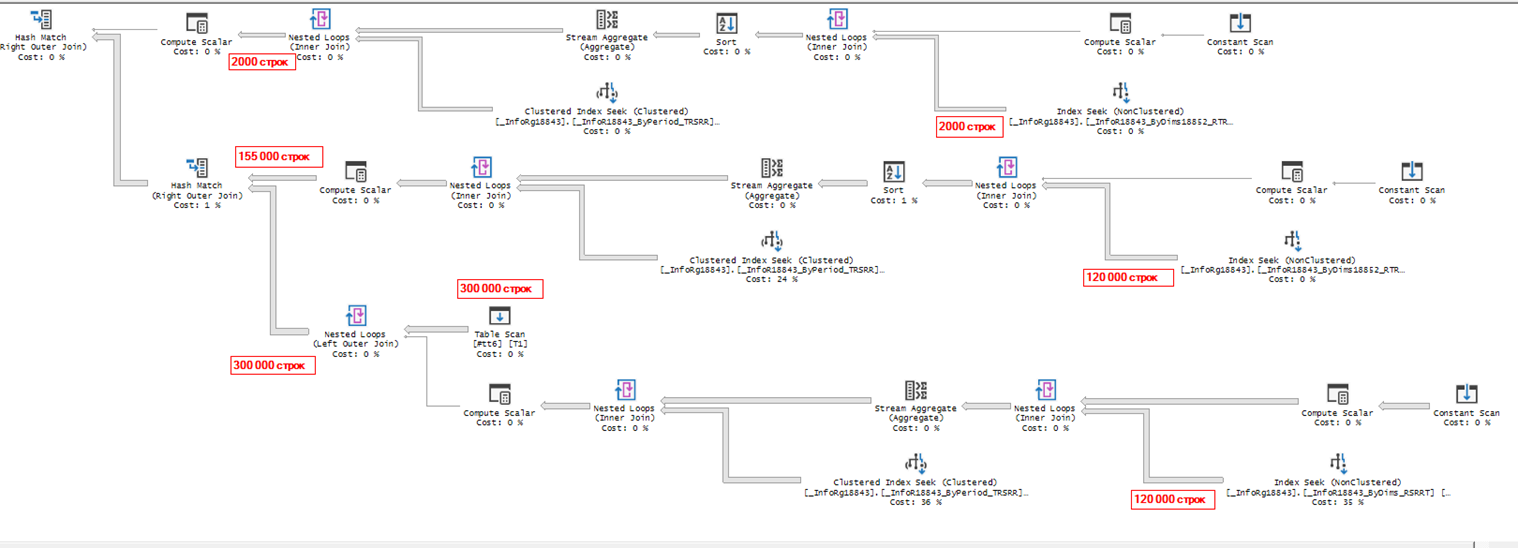
Посмотрим на планы запросов. Сначала на исходный, до оптимизации. Сервер считает, что лучше всего будет выполнить 3 поиска в регистре атрибутов по ИД документов (и, забегая вперед, скажу, что сервер прав).
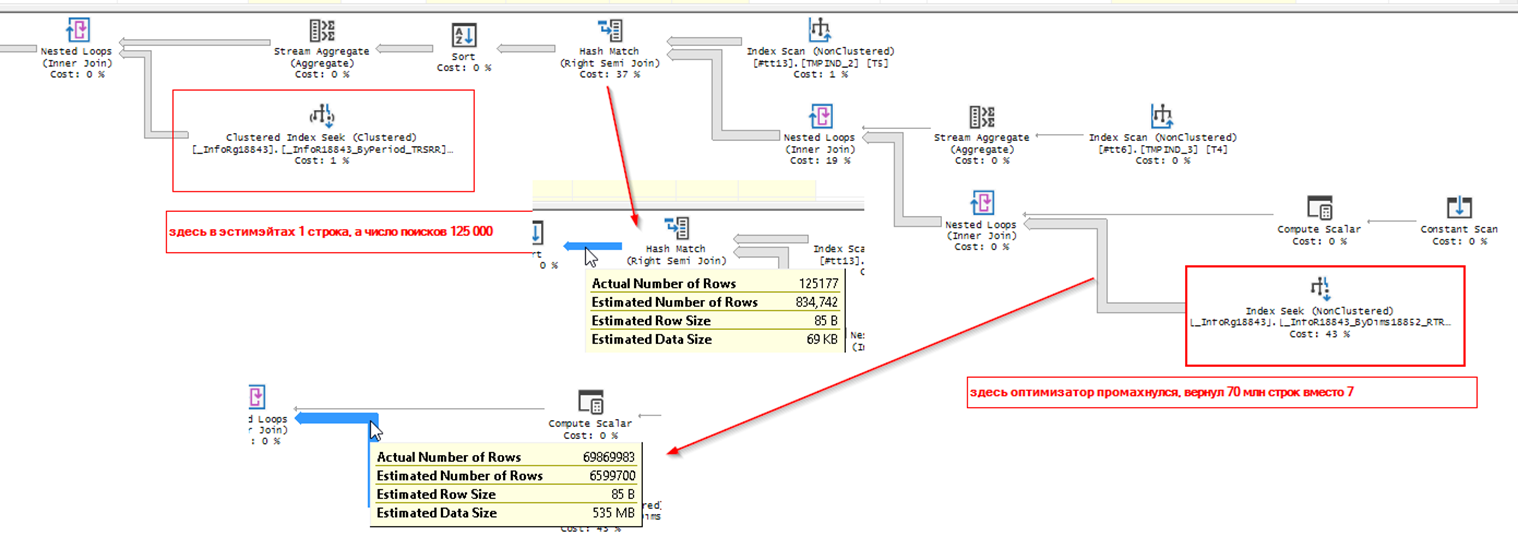
После оптимизации получился другой план, в котором сервер посчитал, что будет лучше сначала сформировать срез атрибутов по всем документам, и лишь после этого отобрать нужные документы. Причем, слегка промахнулся в оценке, выбрав в итоге 70 млн строк, вместо 7 млн. Одна из причин замедления - самый правый IndexSeek, выполнившийся 70 млн раз.
Путем недолгих размышлений условие на атрибут сначала было вынесено из среза наружу, но результата это не принесло, план остался тот же, только время снизилось за счет прогретого буфера. И лишь полный отказ от этого условия дал нужный эффект. Но этим самым мы вернулись к отправной точке, просто вынесли срез последних во временную таблицу.
Вот условие, о котором идет речь:
Атрибут В (ВЫБРАТЬ ВТ1.Атрибут ИЗ ВТАтрибуты как ВТ1)
А вот новые данные по запросу (на прогретом буфере).
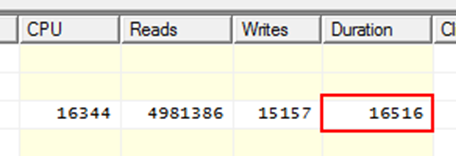
План запроса вернулся к исходному состоянию (сравните с первым скриншотом, там 3 таких блока), что логично, т.к. запрос тоже вернулся к исходному.

Но это только срез последних. А ведь еще есть соединение с таблицей документов. На него тратится 5 секунд, и это нивелирует все усилия по оптимизации данного запроса.
Такой вот, безрезультатный результат.
P.S. Не то, чтобы я призываю к отказу от отборов в виртуальных таблицах, но иногда надо все же проверить, что получится в итоге оптимизации.
Вступайте в нашу телеграмм-группу Инфостарт

