I) Проблемы, которые мы пытаемся решать сверткой БД
1) Увеличение размера БД
2) Низкая производительность выполнения запросов
3) Большой объём "ненужных данных" которые мешают работе пользователей
II) "Технологические" решения проблем
1) Проблема увеличения размера БД
а) Разделение БД на файловые группы
б) Размещение БД или её части на сетевом диске
в) Сжатие таблиц БД
г) Секционирование таблиц БД
2) Проблема низкой производительности запросов
3) Проблема большого объёма "ненужных данных", которые мешают работе пользователей
В современных условиях очень странно бывает иногда слышать "нам нужно свернуть БД 1С - её объём превышает 50 ГБ". Если бы такое собирались сделать администраторы систем SAP R3 или Oracle e Business Suite или даже MS Dynamics Ax их бы наверное уволили. Тем не менее, для 1С это является "стандартной практикой".
Для файловых версий история тянется ещё с версии 1С 7.7 с ограничением в 2ГБ на размер базы. Сейчас ограничение 2ГБ уже только на размер таблицы, размер файла уже может получиться очень и очень не маленьким. Правда если база у вас выросла до такого размера, то наверное туда активно вносились данные - может нужно задуматься о клиент-сервере?
Собственно целью данной статьи является "отговорить" от выполнения свертки БД пользователей клиент-серверного варианта 1С, за счет использования несколько более "продвинутых" технологий.
I) Проблемы, которые мы пытаемся решать сверткой БД
1) Увеличение размера БД
Собственно главный вопрос: а для чего уменьшать размер БД?
Давайте приложим немного математики:
Серверный жесткий диск на 500 ГБ стоит около 10 т.р. Объединить в RAID 1 для надежности будет 20 т.р.
Естественно могут быть проблемы отсутствия места под новые жесткие диски в самом сервере...
А покупка внешнего дискового массива уже обойдётся не так дешево. Что же делать?
Да всё просто - разместить файлы БД на сетевом диске, а как? Ну об этом статье далее.
Увеличение доступного для БД дискового пространства обойдётся нам в 20 т.р. + 10 минут работы специалиста. Сколько часов работы специалиста потребует свертка БД? А сколько времени простоя может получиться? По самым скромным оценкам за свертку УПП объемом гигабайт в 60, со средним количеством ошибок, партионным учетом с проверкой результатов свертки, выправления этого же партионного учета возьмутся тысяч за 30-40.
Универсальной обработкой всё и сразу вряд ли свернётся, особенно если у вас база практически "никогда не останавливается". Партионный учет в любом случае выправлять. Вообщем много там работы. А самое главное, что итоговая проверка должна быть очень тщательной, и всё равно останутся ошибки...
Кроме того, если база уже размером не 60 а, к примеру, 120 ГБ... малейшая ошибка в коде 1С при свертке и всё... процедура заканчивается не удачно. А ошибки точно будут. Как "недостаточно памяти" при работе с ТЗ, так и ошибки вроде
Итоговая цифра получается 30-40 т. минимум против 20-25 в случае покупки жесткого диска, и получения 500 ГБ дополнительного места
Поэтому появляются продукты вроде //infostart.ru/public/78934/
Хорошие наверное продукты, и цели свои выполняют. Вот только меняется структура таблиц от версии к версии платформы. 1С нам об этом не раз говорили. Появился разделитель данных в 14-ом релизе и всё... скорее всего эта обработка для 14 релиза уже не подойдёт. Да и страшно как-то, не говоря уже о нарушении лицензионного соглашения.
И даже после этого найдутся пользователи которым "вдруг неожиданно понадобились" стертые данные, которые "как раз хотели поправить" каку-то циферку, которая "не влияет на последовательнсти" в документе закрытого периода. А хуже если выяснится что кто-то эти документы смотрел постоянно для каких-то только ему ведомых целей. Конечно это всё лишь ошибки в методике работы, но тем не менее недовольство пользователей будет.
2) Низкая производительность выполнения запросов
Ну кто же сказал что "чем меньше тем быстрее"? Для корректно разработанной ИС это утверждение не верно.
На рисунке ниже кратко и "на птичьем языке" приведен простейший пример выборки по индексу типа B-Дерева записи в таблице адресов:
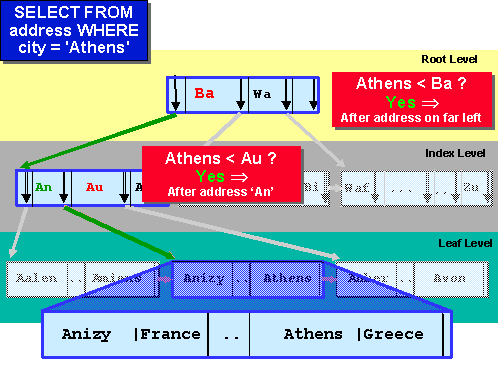
В тему индексов углубляться не хочу, тем более там всё несколько сложнее. Самое главное - поиск проходит не "горизонтально" по таблице, а "вертикально" по "уровням" индекса.
Аналогия - записная книжка: Каждая страница начинается со своей буквы, только вот на каждой странице ещё такая же записная книжка в которой вы можете выбрать вторую букву в слове, и так до тех пор, пока не встретите ту страницу, на которой будет одна или несколько записей. Удобно? Конечно удобно, в случае если у вас больше нескольких сотен контактов. А если у вас их всего десять? Не проще ли их просто записать на один листочек, который можно просмотреть глазами? Вот и в случае индексов так же. Он эффективен если в таблице несколько тысяч записей, а вот если одна единственная - не очень. Благо СУБД научились самостоятельно выбирать "план запроса" и решать использовать или не использовать тот или иной индекс. Вот только в случае "перебора" всех строк таблицы без индекса СУБД очень часто блокирует всю эту таблицу, и вы наблюдаете "непонятно откуда взявшиеся блокировки" после свертки ИБ.
Сворачиваем мы обычно таблицы остатков. В таблице остатков первым полем во всех индексах будет период. Т.е при любых запросах на самом верхнем уровне индекса будет уже отобраны рассчитанные остатки на нужный период. Следовательно на запросы по остаткам свёртка базы окажет наименьшее влияние, повторюсь, при правильной организации системы.
3) Большой объём "ненужных данных" которые мешают работе пользователей
Об этом вы пользователям сперва сделайте рассылку. И получите кучу сообщений что "данные ненужными не бывают". Тем не менее многим не нравится "видеть документы за прошлые периоды" и "архивные данные", с ними нельзя не согласиться. Но решает ли сверка эти проблемы? Убирает ли она ненужные номенклатуры из номенклатурного справочника? Контрагентов с которыми больше не будет вестись работа? А как показывает практика большинство проблем именно в этом.
II) "Технологические" решения проблем
1) Проблема увеличения размера БД
а) Разделение БД на файловые группы
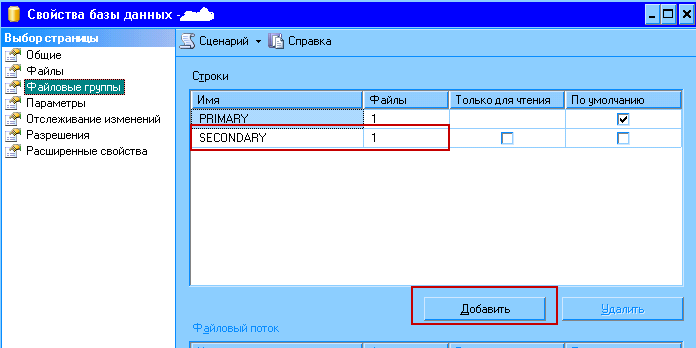
- Открываем Management Studio в списке баз выбираем нужную, открываем её свойства.
- Переходим на вкладку "Файловые группы" как показано на рисунке, и добавляем ещё одну файловую группу (на примере она названа SECONDARY)
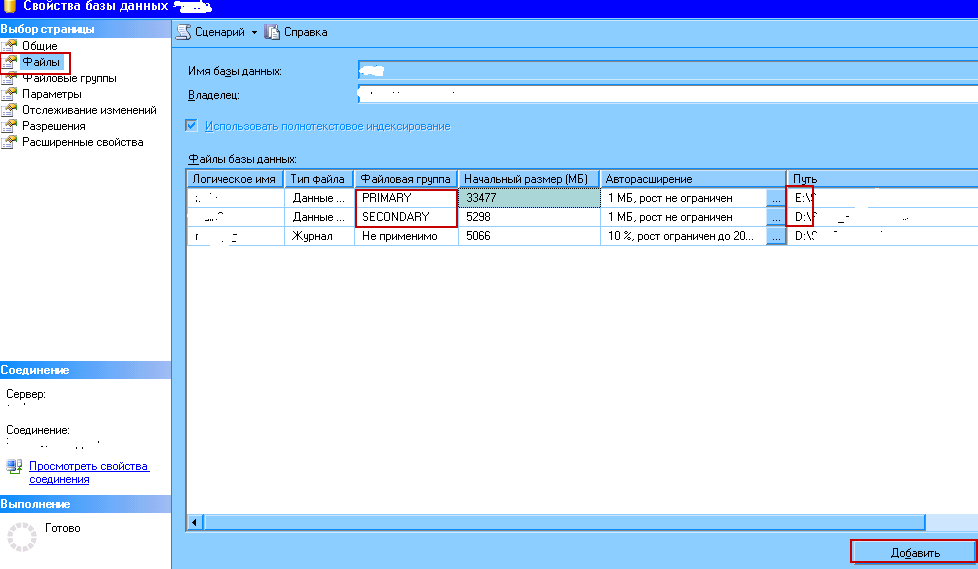
- Переходим на вкладку "Файлы" и добавляем новый файл, для которого выбираем созданную файловую группу. Этот файл МОЖНО РАСПОЛОЖИТЬ НА ДРУГОМ ДИСКЕ
- Теперь используя обработку к примеру://infostart.ru/public/78049/ определяем какие таблицы мы можем смело "пожертвовать" на более медленный (ну или наоборот всё на медленный, остальные - на более быстрый) носитель. Правило 80/20 здесь действует. 80% операций проводятся с 20% данными, так что думайте какие таблички вам нужны оперативно, а какие не очень. "Хранилище дополнительной информации", документы ввода начальных остатков, документы которые уже не используете сразу определяйте как те которые можно перенести в "медленную" файловую группу.
- Выбираем таблицу которую нужно перенести в другую файловую группу - выбираем меню изменения таблицы (проект) и в свойствах меняем файловую группу:
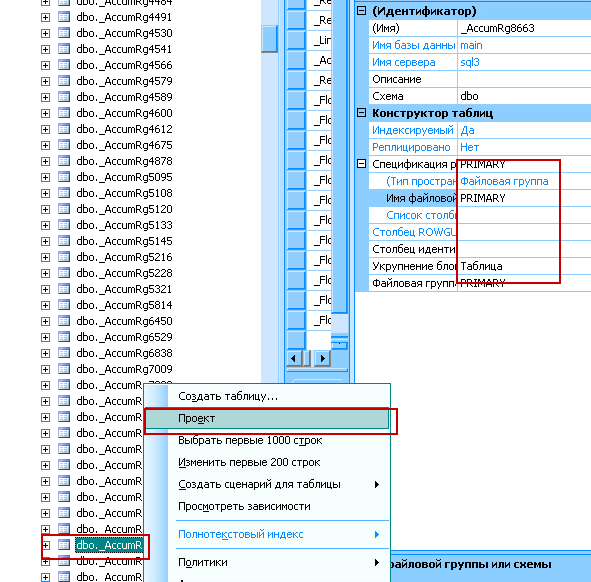
индексы таблицы при этом тоже переносятся в данную файловую группу.
Достаточно удобный механизм распределения таблиц по дисковым массивом разной скорости. Лицензионному соглашению это не противоречит, т.к. в решении мы не используем доступ к данным и к информационной базе средствами отличными от платформы 1С. Мы лишь организуем хранение этих данных удобным образом.
б) Размещение БД или её части на сетевом диске
DBCC TRACEON (1807)
Пишем данную команду в Management Studio, выполняем и можем успешно создавать базы по сети. Само собой при этом экземпляр SQL Server-а должен быть запущен от имени доменной учетной записи, и у этой записи должны быть права на нужную сетевую папку.
Но прошу быть очень внимательными при использовании данной команды в случае если у вас пропадёт сеть при работе с БД вся БД на время её отсутствия будет не доступной. Microsoft не зря закрыли эту возможность для массового использования. Вообще эта возможность предполагается для создания баз на NAS хранилищах, что и настоятельно рекомендую. Подойдёт так же стабильный и надежный файловый сервер, имеющий прямое подключение к серверу на котором запущен MS SQL СУБД.
Подробнее про другие флаги трассировки можно прочитать в статье http://msdn.microsoft.com/ru-ru/library/ms188396.aspx
Т.е. часть файловую группу можно вообще хранить в сети, а уж там дисковое пространство расширяется без проблем.
в) Сжатие таблиц БД
EXEC sp_MSforeachtable 'ALTER INDEX ALL ON ? REBUILD WITH (DATA_COMPRESSION = PAGE)' GO
После выполнения этого кода все таблицы в БД будут сжаты. Очевидно, что можно сжимать и таблицы по отдельности... это как бы на ваш выбор. Что даёт сжатие?
- Экономия дискового пространства
- Снижение нагрузки на дисковую подсистему
Что расходуется? - процессорное время.
Так что если у вас процессор загружен всё время на 70% и выше - сжатие вам использовать нельзя. Если 20-30% загрузка процессора, и при этом очередь к диску вырастает до 3-4... то сжатие таблиц - как раз "лекарство" для вас. Подробнее про сжатие таблиц БД -http://msdn.microsoft.com/ru-ru/library/cc280449(v=sql.100).aspx
Важное замечание - функция сжатия таблиц доступна только для обладателей версии Enterprise SQL Server
г) Секционирование таблиц БД
Разделить таблицы на разные файловые группы конечно хорошо... но вы скажете что есть тут парочка таблиц... которые тянутся с 2005 года... и уже занимают с десяток гигабайт.. вот бы в них все данные да отдельный диск положить, а текущие оставить.
Вы не поверите, но и это тоже возможно, хотя и не очень просто:
- Создаём функцию секционирования по дате:
create partition function YearSection(datetime)
as range right for values ('20110101');
Всё что до 2011 года будет попадать в одну секцию, всё что после - в другую.
- Создаём схему секционирования
create partition scheme YearScheme
as partition YearSection to (SECONDARY, PRIMARY);
- Этим говорим, что все данные до 11 года будут попадать в файловую группу "Secondary" а после - в "Primary"
- Теперь осталось таблицу перестроить с разделением на секции. Для этого проще всего воспользоваться уже management studio, потому как процесс не простой. Вам нужно перестроить кластерный индекс для таблицы (который по сути и является самой таблицей), выбрав для индекса созданную схему секционирования:
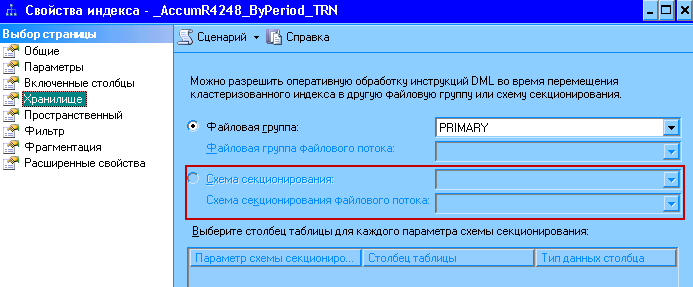
На рисунке вы видите что выбор не доступен - всё правильно, секционирование таблиц возможно только в версии Enterprise MS SQL Server. Кластерный индекс отличить легко - картинка с круглыми скобками. Для РН и всех объектов 1С он создаётся. Для РН кластерный индекс по периоду есть всегда. Для документов и справочников хорошо бы конечно создать другой, который включает реквизит по которому будет секционирование... но это уже будет являться нарушением лицензионного соглашения.
2) Проблема низкой производительности запросов
Все действия, описанные выше не должны повлиять на скорость выполнения основных запросов. Более того, использование файловых групп и секций таблиц позволит вам разместить наиболее часто используемые данные на быстрых дисковых массивах, позволит поменять конфигурацию дисковых массивов, использовать небольшие по размеру i/o accelerator. Таким образом скорость выполнение запросов только повысится. А сжатие таблиц позволит вам дополнительно разгрузить дисковую подсистему, если она являлась узким местом. А вообще если говорить о скорости выполнения запросов, то анализ их планов выполнения, оптимизация запросов для грамотного использования индексов даст намного более существенный прирост производительности, чем все "ухищрения" на уровне MS SQL.
3) Проблема большого объёма "ненужных данных", которые мешают работе пользователей
Но для этого нужно не сворачивать базу, а проделать следующее:
а) Объяснить всем как пользоваться отборами, как они сохраняются, как пользоваться интервалами журнала, как они сохраняются
б) Пометить на удаление ненужные данные если они не несут никакой смысловой нагрузки (контрагентов и номенклатуру, с которыми больш не работаете) - этим вы принесёте пользователям больше пользы чем сверткой. В случае наличия ресурсов настроить автоматическую пометку на удаление неиспользуемых объектов и сделать отбор по умолчанию в программном коде для того чтобы не отображались по умолчанию не нужные пользователям объекты - помеченные на удаление
в) Настроить другие полезные "отборы по умолчанию" - например чтобы каждый менеджер по умолчанию видел только свои документы. А если хочет посмотреть документы "товарища" - нужно отключать отбор.
По всем реквизитам, которые участвуют в отборе не забывайте ставить признак "Индексировать с доп. упорядочиванием" - тогда на производительности системы такие "удобства" не скажутся.

Вступайте в нашу телеграмм-группу Инфостарт