Начнем с дисклеймера.
Данная публикация не охватывает абсолютно все случаи жизни и не является единственно правильной, или вообще правильной, для решения конкретно ваших задач. Здесь просто описан простой способ получения определенного результата в конкретных условиях. Возможно вам он тоже подойдет.
Для начинающего программиста создание отчетов на СКД зачастую является делом не тривиальным. И не только потому, что изучение СКД не входит в общий курс обучения программированию 1с, но и потому, что являясь достаточно разветвленной и самостоятельной подсистемой конфигуратора, имеет свои особенности. Многие рекомендуют изучать книгу Хрусталевой "Разработка сложных отчетов в 1с Предприятии. Система компоновки данных". Именно эта книга, и даже не вся, а только её начало, натолкнуло меня на путь решения задачи, которую до этого я безуспешно пытался решить в течении 2-х дней. Дело в понимании механизмов работы СКД.
Задача.
Итак, необходимо собрать отчет по использованным на проекты материалам за некий период времени. Сам материал задается подобием, а используемые для этого данные представляют из себя выборку из документов заказа материала со склада производством и требований-накладных, т.е. фактического его списания. Иерархия отчета такова: проект - документ заказа - требования-накладные. Т.е. в проекте может быть много заявок и по каждой заявке может быть несколько списаний одного и того же материала, т.к. забирали заказанные материалы не все сразу, а по частям.
Первоначально подход был такой:
1. Написать запрос в котором соединить заявки и списания по этим заявкам и получать данные для СКД
2. Создать иерархию результатов отчета
3. Механизмами СКД вычислить ресурсы (итоги) по количеству заказанного и фактически списанного для каждой ступени иерархии
4. ...и вуаля
План выглядит годным, приступаем к реализации и на выходе получаем такую таблицу:
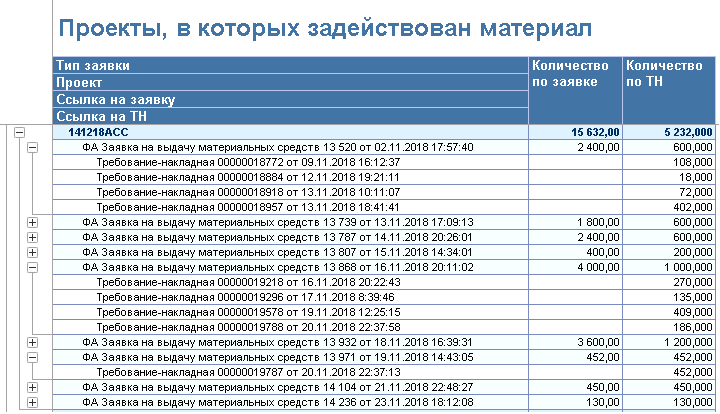
Обратите внимание, что общее количество заказанного и списанного по заявке не совпадает:

В общем случае так может быть, для этого отчет и делается, но не в этот раз. Также обратите внимание на то, что не совпадает запрошенное количество по конкретной заявке:
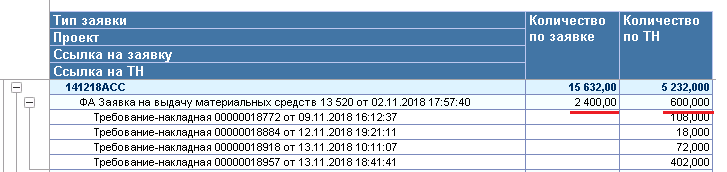
Путем нехитрых размышлений приходим к выводу, что 2400 - это ни что иное, как 600*4, т.е. запрошенное по заявке количество * количество списаний по этой завке.
Убеждаемся в этом находя заявку, где количество списаний одно:

Да, для одного списания всё рассчитывается верно. Ошибка найдена: т.к заявка является группировкой, то для неё также рассчитывается ресурс "Количество по заявке". Становится понятно, что дело в том, что после отработки запрос фактически возвращает таблицу вида:
Таблица 1. Исходный запрос
| Проект | Материал | Заказ | Списание | Кол-во заказ | Кол-во списание |
| 141218АСС | Брус | ДокументЗаказа | ДокументСписания№1 | 600 | 108 |
| 141218АСС | Брус | ДокументЗаказа | ДокументСписания№2 | 600 | 18 |
| 141218АСС | Брус | ДокументЗаказа | ДокументСписания№3 | 600 | 72 |
| 141218АСС | Брус | ДокументЗаказа | ДокументСписания№4 | 600 | 402 |
Так как "ДокументЗаказа" - один и тот же, то при вычисление ресурса для группировки по этому документу СКД просуммировал значение поля "Кол-во заказ" 4 раза.
В этом месте начинаются поиски в интернете и придумывание способов вычислить сумму заказов в пределах одного проекта чтобы потом подставить её в вычисление ресурса с агрегатной функцией макс. или мин. или тому подобных вещей. В любом случае мы приходим к необходимости усложнения исходного запроса для того, чтобы поля детальных записей не дублировались, т.к. ресурсы вычисляются именно по детальным записям.
Решение.
Как обычно постое, реализуемое за 10 минут с перекурами, если точно (не примерно, а точно) знать что и как работает.
Как я писал в начале, система компоновки данных сложная и развита система внутри платформы. Это целый отдельный механизм. Одной из функциональных особенностей этой системы является механизм связей наборов данных:

Начав читать указанную выше книгу Хрусталевой, мы понимаем, что механизм связей наборов данных является чем-то вроде "внутреннего запроса СКД". Т.е. с помощью него можно соединить данные из нескольких источников по неким критериям в единую таблицу, при этом сами исходные данные будут рассматриваться отдельно друг от друга как самостоятельные.
Таким образом можно вместо одного сложного (а вполне возможно - и очень сложного) исходного запроса написать два простых, разделив тем самым приведенную выше таблицу на две. Таблицу с документами заказа:
Таблица 2. Документы заказа
| Проект | Материал | Документ заказа | Кол-во заказ | |
| 141218АСС | Брус | ДокументЗаказа | 600 |
и таблицу с документами списаний :
Таблица 3. Документы списаний
| Номенклатура | Документ списания | Кол-во списание | Документ-Основание |
| Брус | ДокументСписания№1 | 108 | ДокументЗаказа |
| Брус | ДокументСписания№2 | 18 | ДокументЗаказа |
| Брус | ДокументСписания№3 | 72 | ДокументЗаказа |
| Брус | ДокументСписания№4 | 402 | ДокументЗаказа |
где "Документ-Основание" - реквизит документа списания хранящий ссылку на документ заказа материала, по которому это списание проводится.
Для соединения этих запросов в одно целое необходимо выполнить ещё один запрос. Этот последний запрос выполняет за нас механизм "Связи наборов данных", виртуально сделав левое соединение и фактически получив Таблицу 1. Для этого необходимо указать запросы и связываемые поля. В нашем случае это поля "СсылкаНаЗаявку" и "ДокументОснование" в которых хранится ссылка на документ заказа, а также, - т.к. в документах заказа и списания материалов может быть несколько, - поле с материалом:

Ну и указать ресурсы:
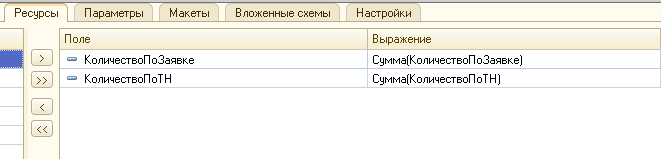
В результате мы получаем необходимый нам иерархический документ, но ресурсы для него будут считаться раздельно, т.к. исходные таблицы с результатами запросов - различны:

Что и требовалось доказать.
Вступайте в нашу телеграмм-группу Инфостарт