




")






{kind=link}
Приветствую коллеги!
В комментариях к статье 1C + Python + Django Rest Framework + Vue.js. Опыт несложной full-stack разработки я оставил комментарий и предложил другой путь решения подобных задач. Завязалась дискуссия в ходе которой я предложил свой подход, который успешно опробован на наших клиентах к решению аналогичной задачи (личный кабинет для техподдержки).
Исходная задача
В организации есть рабочая информационная база 1С (она же учетная система). Необходимо создать личный кабинет для пользователей с возможностью web-доступа. Причем пользователи должны полноценно работать в любом браузере, интерфейс желательно иметь адаптивный (меняет дизайн страницы в зависимости от поведения пользователя, платформы, размера экрана и ориентации устройства: компьютера, смартфона, планшета). Личный кабинет должен быть достаточно легко модифицируемым и расширяемым.
Задач такого круга масса: личный кабинет покупателя для заказа товаров онлайн, внесение показаний счетчиков в сфере ЖКХ, службы доставки товаров, техподдержка и прием заявок клиентов и т.д.
Варианты решений
Первый вариант. Классический. Разделить личный кабинет и информационную базу 1С. Это самый древний способ, который к нам пришел еще с бородатых времен 1С версии 7.7. Личный кабинет при этом делается на каком-нибудь веб-движке и при необходимости какой-нибудь веб-ориентированной СУБД. Например, PHP + MySQL или Django Rest Framework + Vue.js + MariaDB. При этом время от времени происходит обмен данными между веб-частью и центральной ИБ на 1С и происходит синхронизация данных.
Плюсы:
- Независимость 1С и веб-частей друг от друга. В случае остановки работы одной части, вторая продолжает работу.
Минусы:
- Оперативность обмена данными. Необходимо время, чтобы выгрузить информацию из 1С и загрузить ее в веб-часть, а так же время на обратную операцию. Соответственно это влечет за собой паузы между обменами и в некоторых случаях это критично.
- Сложность дальнейшего сопровождения. Сопровождать две системы практически всегда сложнее чем одну при условии, что выполняют по сути они одну и ту же задачу.
- Длинная цепочка взаимодействий всей системы. Здесь я имею ввиду повышение риска остановки обмена, если одно из цепи перестанет работать: остановка регламентных заданий в случае зависания, недоступность FTP-сервера если его используют для обмена, какие-то ошибки, связанные с выгрузкой для веба и т.д. Крепость всей цепи определяется крепостью самого слабого звена.
Несмотря на то, что это один из первых способов, который появился очень давно, его успешно продолжают использовать и по сей день.
С развитием платформы и выходом версии 8.2 появился еще один способ.
Вариант два. Использование стандартного web-клиента 1С. Зачем делить систему на части, если можно дать пользователям доступ к рабочей базе, разграничить все права и пользователь сможет видеть только то, что ему нужно?
Плюсы:
- Все в одном месте. Тут комментарии излишни.
- Простота разработки. Мы вообще не вникаем в веб и все делаем на платформе 1С.
Минусы:
- Лицензии на платформу 1С. Каждый дополнительный сеанс ведет к увеличению стоимости всей системы.
- Права пользователей. Тут надо усиленно следить. Не дай бог, клиент увидит, или еще страшнее сделает, что-то не то, что изначально не запланировали. Из этого пункта вытекает следующий.
- Конфиденциальность. Часто базы 1С размещают на внутренних серверах компании, потому, что не все что есть в базе должно быть публично.
- Ни для кого не секрет, что 1С иногда необходимо останавливать для регламентных операций и обслуживания. Очевидно, что во время этих остановок никто не сможет работать.
- Количество пользователей в онлайне. Если в варианте номер один, веб-странички при достаточно скромных мощностях на хостинге непринужденно могут обслуживать сотни и тысячи клиентов, то на платформе 1С все не так хорошо. Необходимы сумасшедшие мощности сервера 1С.
Вариант три. Использование HTTP-сервисов 1C. С выходом 8.3 в платформу были добавлены новые механизмы: сначала web-сервисы для интеграции с другими информационными системами, а потом и HTTP-сервисы, предназначеные для обработки HTTP-запросов, которые сначала поступают на веб-сервер, который передает на обработку эти запросы 1С, а уже 1С обрабатывает эти запросы и возвращает результат так же по протоколу HTTP, браузер видит ответ и отображает пользователю результат. При этом мы можем возвращать HTTP-запросам клиентов АБСОЛЮТНО любые данные: картинки, HTTP-страницы, JSON-данные, обычный текст и т.п.
Плюсы:
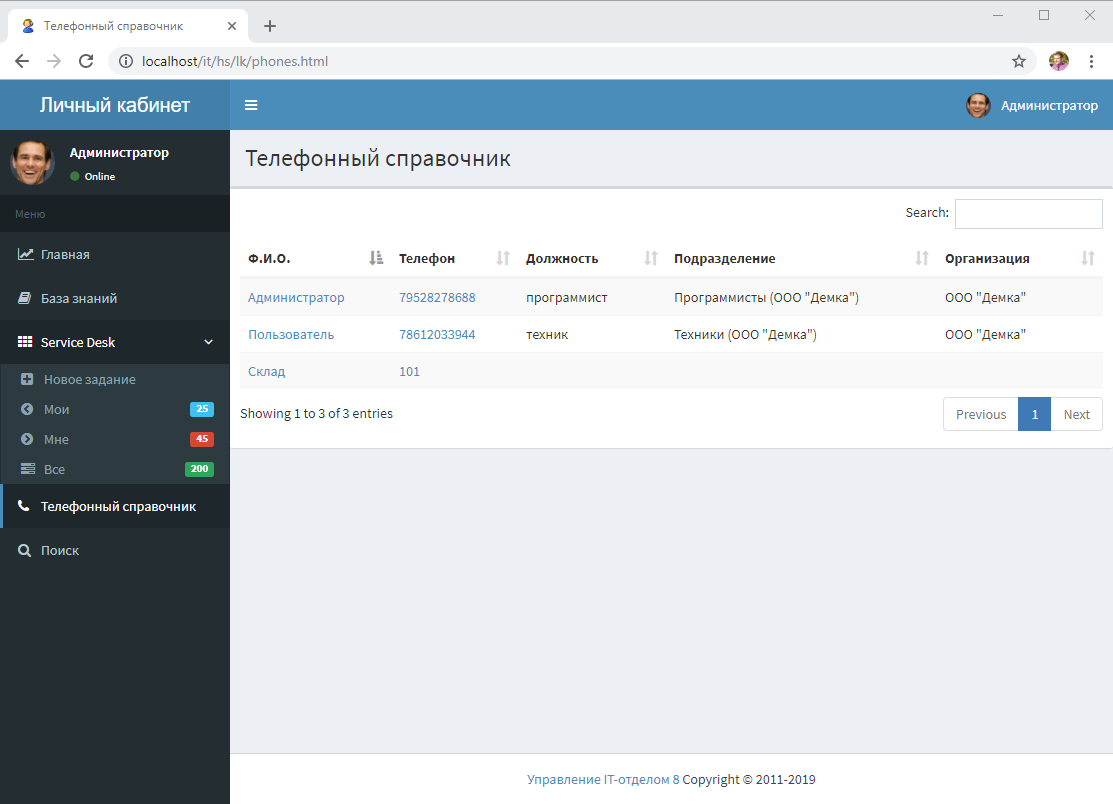
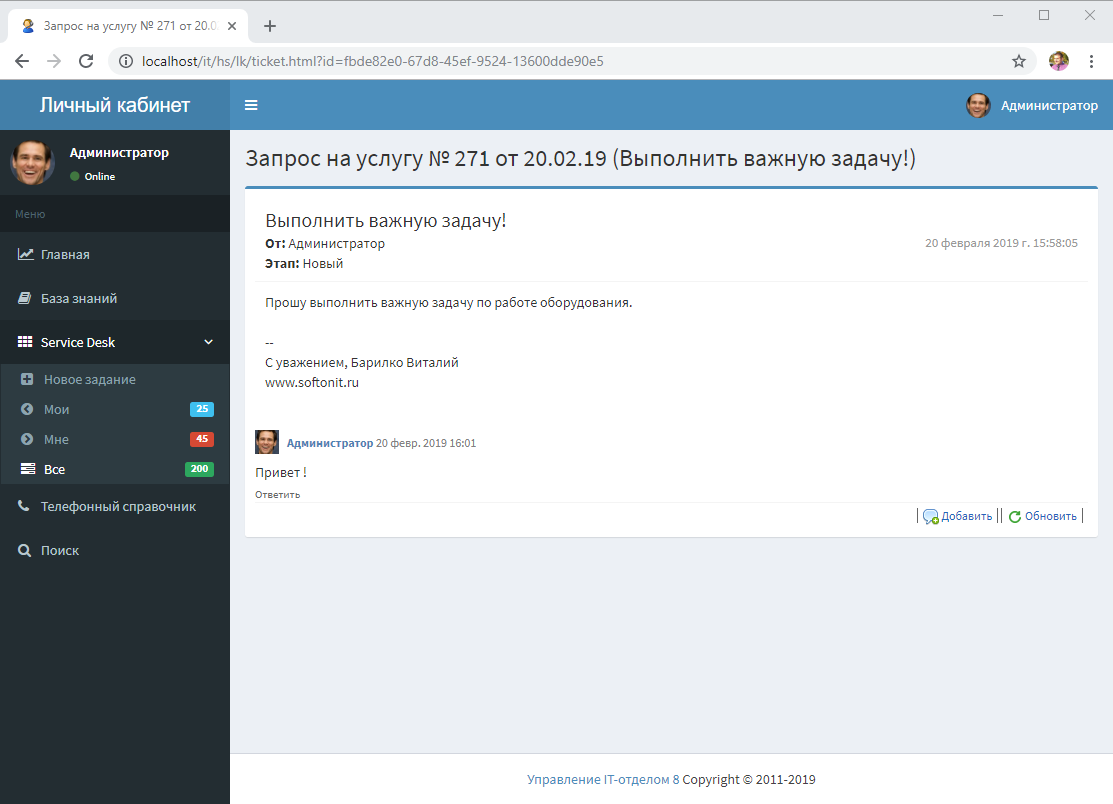
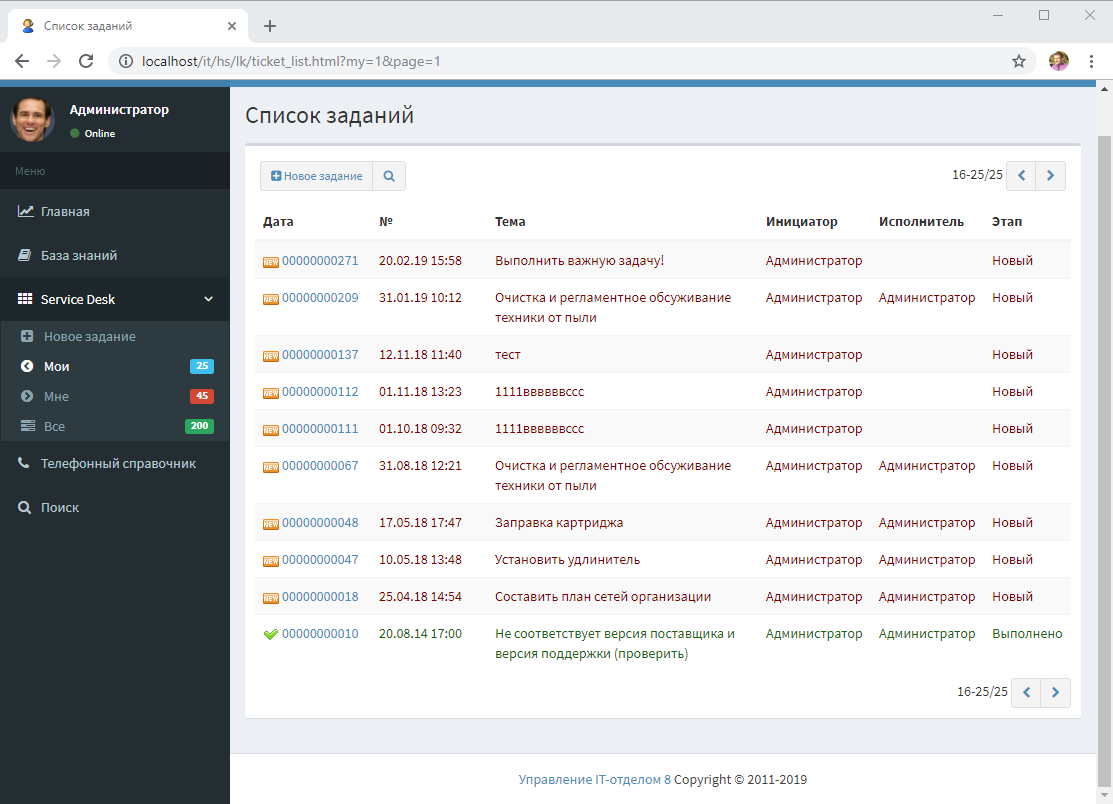
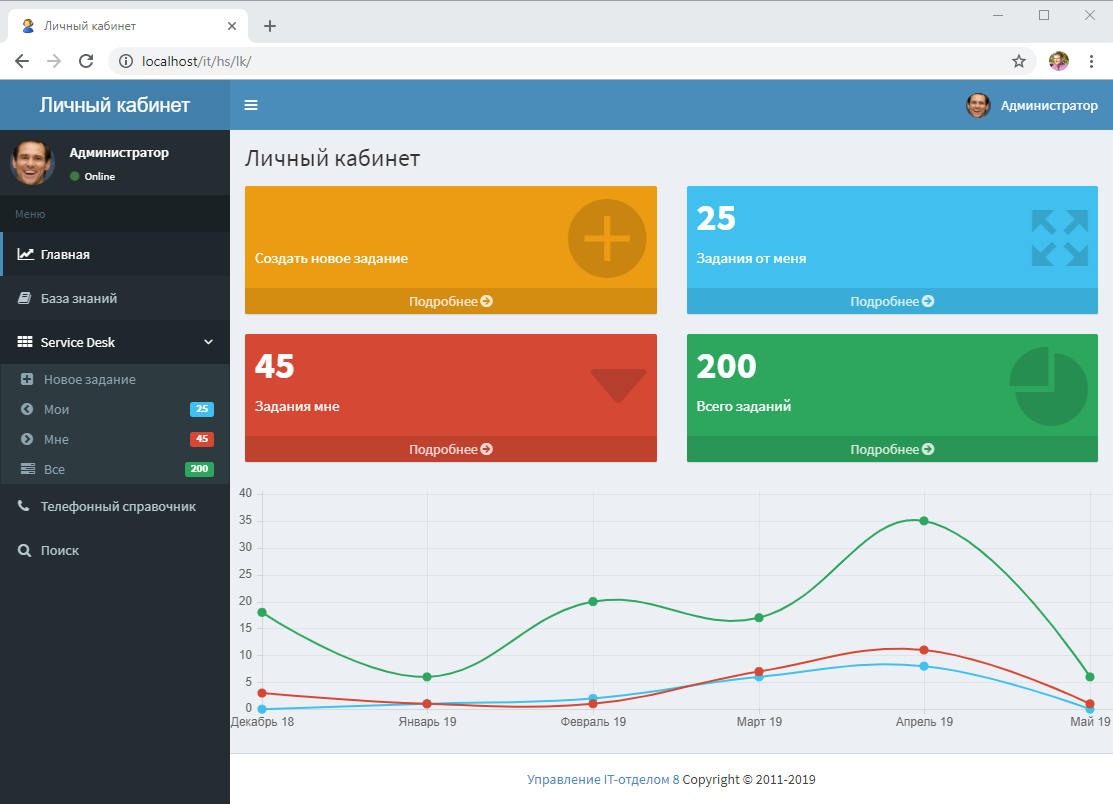
- Все можно сделать очень красиво и не будет понятно, что эти страницы сформированы вообще в 1С. Собственно, в скриншотах есть страничка, которая отображает "как оно есть" в нашей разработке. Тут и адаптивность, разные фреймворки и компоненты, в общем все, что вашей душе угодно.
- Скорость работы по сравнению с вариантом два достаточно высокая, за счет возможности переиспользования сеансов. Но все равно вариант один будет быстрее т.к. нет накладных расходов.
Минусы:
- Лицензии. Тут не все понятно, но понятно то, что они нужны. Как лично понял я, они нужны в объеме онлайн-сеансов (возможно ошибаюсь и если есть более точная информация поправьте меня). Т.е. если в онлайне одновременно работают 10 человек в личном кабинете, то необходимо 10 лицензий. Сеансы живут какое-то время, а потом уничтожаются, временем жизни сеансов можно управлять настройками.
- При изменении поведения HTTP-сервиса необходимо остановить работу.
На ИСе много примеров использования HTTP-сервисов среди которых:
На что действительно способны HTTP-сервисы
HTTP-сервис: отчеты [Расширение]
Реализация простого http-сервиса "Просмотр карточки номенклатуры(товара) в браузере"
Но все они не универсальные и заточены под одну конкретную задачу или решение какой-то одной проблемы. Я бы хотел остановится на использовании HTTP-сервисов немного в другом контексте...
Вариант четыре. Он же гибридный вариант три. Универсальный HTTP-сервис.
Это уже мой подход к этому вопросу. Я долго думал, на тему как сделать так, чтобы HTTP-сервис не нужно было постоянно бы изменять в конфигураторе (хотя это спорно, так как сейчас все идет к расширениям и этот функционал можно реализовать через расширение конфигурации) и реализовать что-то универсальное. И мысли примерно следующие: по факту HTTP-сервис всегда работает по алгоритму: пришел какой-то запрос вида http://site.ru/hs/lk/index.html необходимо понять, что от нас хотят, покопаться в 1С, возможно сделать какой-то запрос или еще что-то и отдать соответствующий ответ. Т.е. схема работы HTTP-сервиса примерно такая:
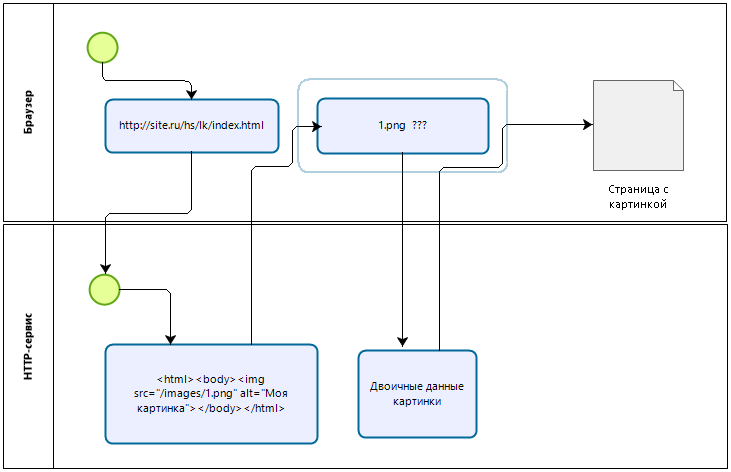
Это все схематично. Обратите внимание на один важный момент. Для каждого последующего запроса алгоритм будет одинаковый. Пришел запрос - отдаем ответ.
Т.е. если мы в браузере открыли страничку по адресу: http://site.ru/hs/lk/index.html которую обработал HTTP-сервис и вернул нам:
<html><body><img src="/images/1.png" alt="Моя картинка"></body></html>
То автоматически браузером будет выполнен второй запрос по адресу: http://site.ru/hs/lk/images/1.png и в браузер будет подставлена картинка, которая получена вторым запросом.
Т.е. количество запросов к HTTP-сервису будет 2, а показана всего одна страничка, но на ней будет картинка. Если ссылок в документе будет несколько, то каждый раз браузер будет обращаться к HTTP-сервису и просить у него то, чего ему не хватает. Круто да?
Что это дает нам? А это позволяет нам сделать следующее: если мы научимся хранить данные, которые мы хотим отдавать пользователям, присвоим им адреса, по которым можно будет их найти, научимся обрабатывать не найденные страницы и HTTP-сервис будем использовать как низкоуровневую прослойку между этими данными и пользователями, то мы получим универсальный механизм. Мы получаем образно говоря HTTP-сервер на платформе 1С.
Т.е. пусть:
index.html - это вот эта страничка с текстом. Где ее тип text/html, а текст вот такой <html><body><img src="/images/1.png" alt="Моя картинка"></body></html>
/images/1.png - это картинка и она имеет тип image/png и содержит вот такие-то двоичные данные, в которых хранится картинка.
Итого HTTP-сервис теперь все отдает как надо для нашего примера. Получил страничку, нашел ее в списке и отобразил, увидел, что еще требуется картинка, послал запрос за картинкой, получил, дорисовал картинку.
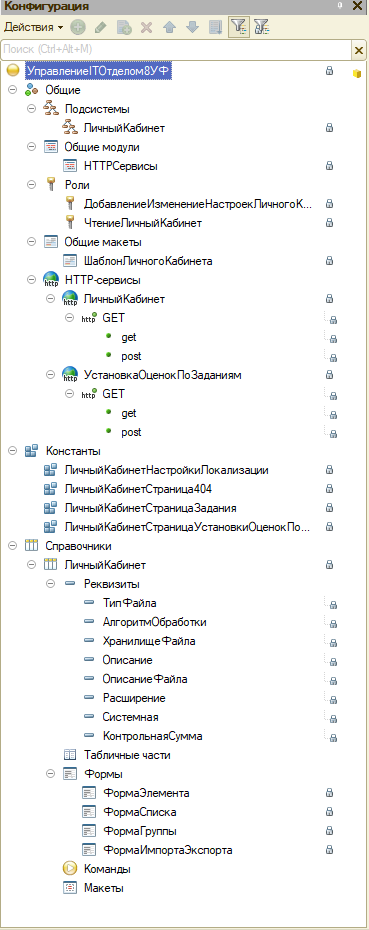
Структура выше ничего не напоминает? Это ведь справочник чистой воды :) Давайте его прикрутим.

Далее скриншоты из нашего решения. Файл index.html - имеет адрес от корня HTTP-сервиса, а вот эта картинка:
 Имеет адрес /images/nophoto.png
Имеет адрес /images/nophoto.png
А вот сама страница:
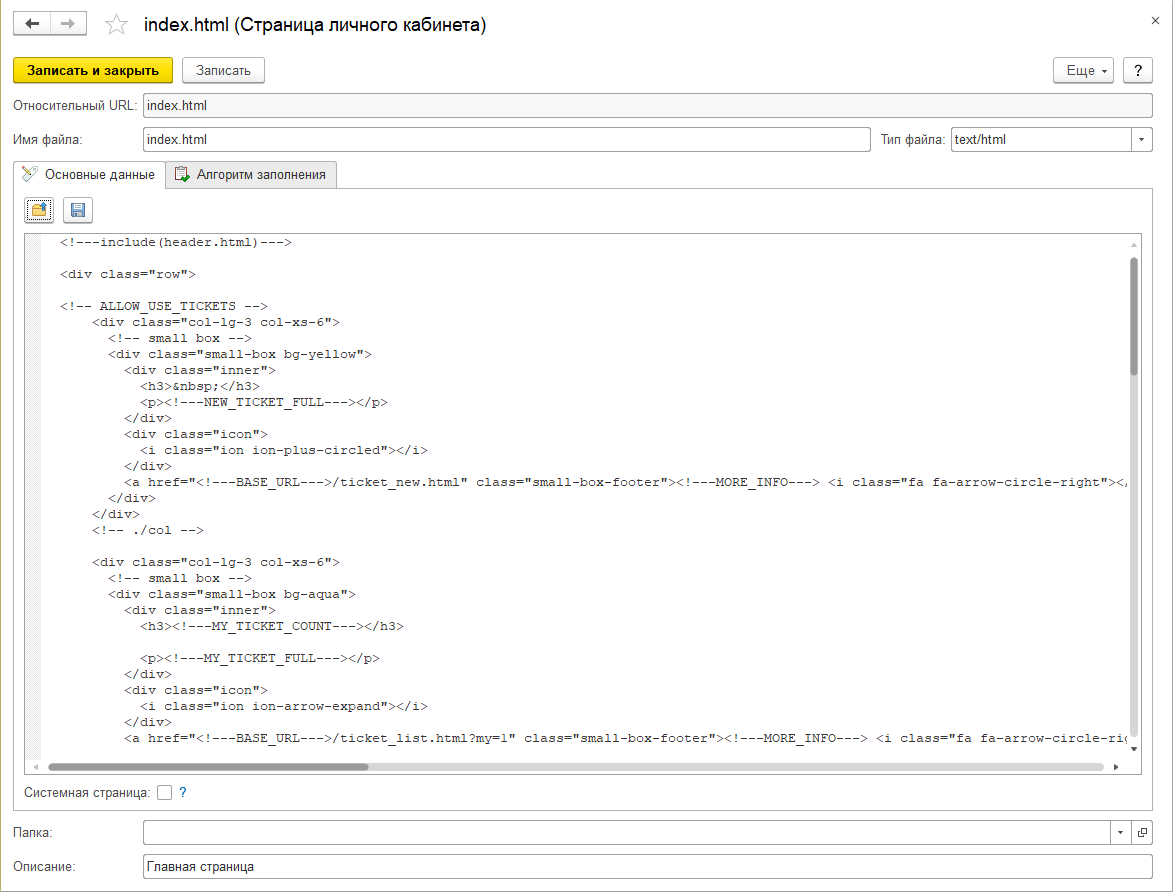 Обратите внимание, что это шаблон заполнения. Область <!--include(header.html)---> означает, что найди файл по адресу /header.html и вставь его содержимое в это место. Области на страницах повторяются поэтому так делать имеет смысл во избежание дублирования HTML-кода.
Обратите внимание, что это шаблон заполнения. Область <!--include(header.html)---> означает, что найди файл по адресу /header.html и вставь его содержимое в это место. Области на страницах повторяются поэтому так делать имеет смысл во избежание дублирования HTML-кода.
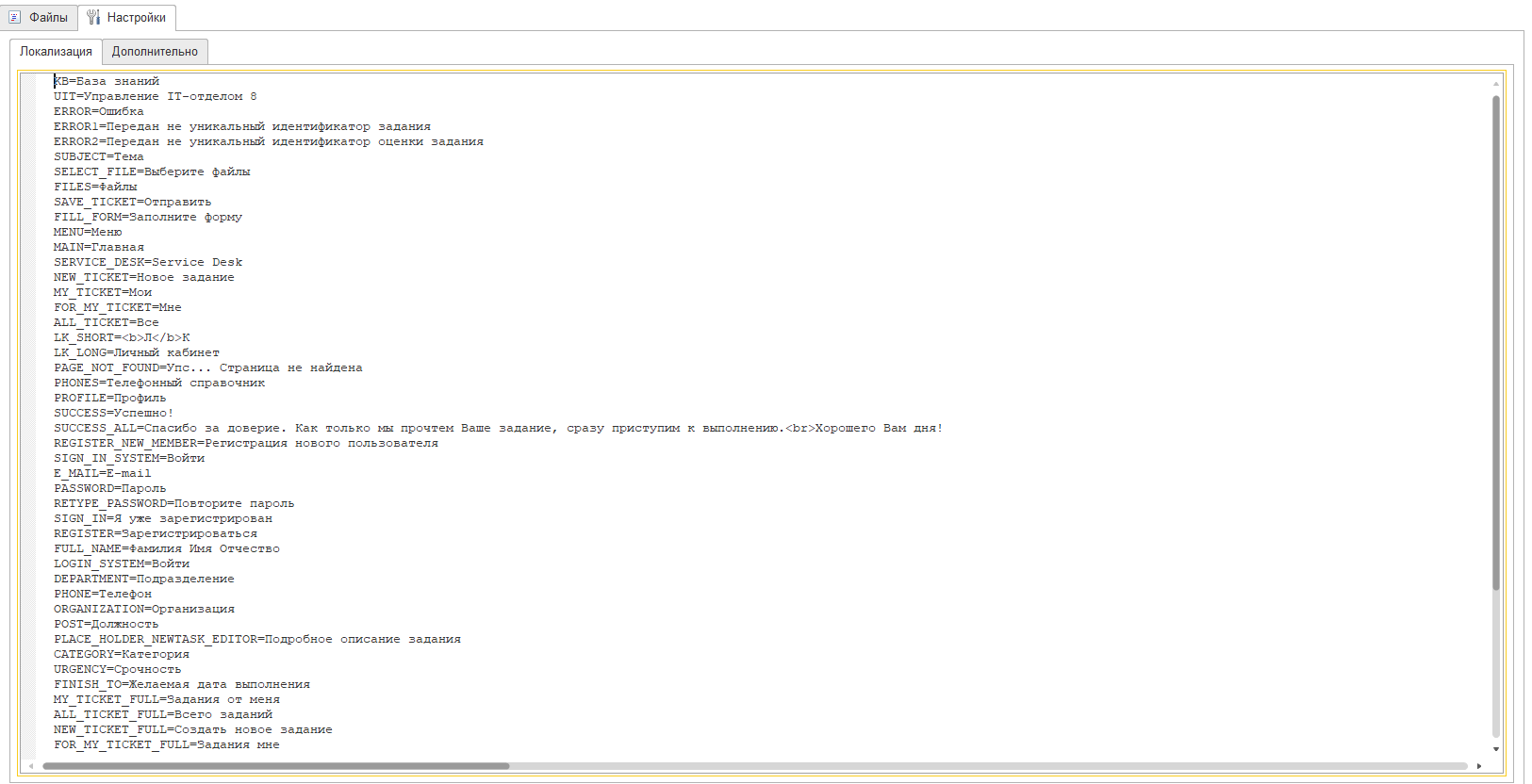
Далее, находим все остальные языковые константы вида <!---TEXT---> и заполняем их используя вкладку "Локализация" - это позволит заменить постоянные строки, чтобы их можно было внести в одном месте, а потом использовать как константы:
 Далее, когда текст более или менее готов, мы выполняем дополнительный код на встроенном языке 1С, который находится на закладке "Алгоритм заполнения" и дозаполняем глобальную переменную для HTTP-сервиса "Переменные" и/или выполняем какие-то дополнительные действия. У нас есть в этом случае то, что должны вернуть:
Далее, когда текст более или менее готов, мы выполняем дополнительный код на встроенном языке 1С, который находится на закладке "Алгоритм заполнения" и дозаполняем глобальную переменную для HTTP-сервиса "Переменные" и/или выполняем какие-то дополнительные действия. У нас есть в этом случае то, что должны вернуть:
- Тело - переменная в которой ответ, который будет передан. Уже с заполненными языковыми переменными и вставленными областями.
- Переменные - если есть переменная, которая отсутствует в локализации, то ее можно дополнительно объявить в алгоритме заполнения добавив ее в структуру.
- Запрос - собственно исходный HTTPЗапрос.
И то, что можем использовать в алгоритме:
- ОтносительныйURL - какой запрос пришел.
- ОтносительныйURLПеренаправления куда безусловно перенаправить если это необходимо. Например реализовав редирект 301 или 302.
- ИмяФайла - наименование элемента в справочнике ЛичныйКабинет.
- Путь - группа где находится элемент в справочнике ЛичныйКабинет.
- POST - POST-переменные, которые были нам переданы в виде Соответствия. Здесь мы можем получить и обработать что-то от веб-форм (например файлы из браузера).
Так же возможна такая ситуация, когда в справочнике не найдена страничка, которую надо отобразить. В этом случае есть специальная настройка, которая говорит какую страничку выводить в этом случае. Страничка будет выведена и отдан ответ 404 (страница не найдена).
В общем случае подобный подход позволит всегда работать по принципу шаблонизатора и на платформе 1С. HTML-страницы формируются автоматически, анализируя запрос от пользователя. Т.е. если пользователь введет адрес или перейдет в личном кабинете по ссылке, например: http://адрес_сервера_1с.ru/имя_публикации/hs/lk/folder1/folder2/file.html?param=1 То для построения страницы пользователю система все, что после lk, т.е. /folder1/folder2/file.html?param=1 будет разбито на блоки и по шагам выполнен алгоритм, который описан выше. При этом мы так же можем использовать различные фреймворки для работы. В справочнике "Личный кабинет" есть возможность загрузить папку с фреймворком, а потом на своих страничках использовать стили и скрипты оттуда. Мы в своей разработке, например, использовали Bootstrap + JQuery + chart.js.
Для демонстрации прикреплена демо-версия подсистемы (dt-файл). Желающие могут скачать и попробовать поработать. Там все, что касается кода присутствует, но сделан примитив заполнения справочника с данными для отображения, не то, что в боевой базе и на скриншотах, но этого вполне достаточно, чтобы понять как это все работает и возможно кто-то возьмет за шаблон в свои аналогичные проекты.
PS: Для работы с демо-базой необходимо опубликовать базу на веб-сервере, и ввести в браузере http://адрес_сервера_1с.ru/имя_публикации/hs/lk/, после ввести данные для аутентификации "Администратор" (без кавычек) и пустой пароль. Можете параллельно в справочнике "Личный кабинет" изменять странички и после смотреть что получается в браузере.
PS: Спасибо, что дочитали до конца! :)
Вступайте в нашу телеграмм-группу Инфостарт