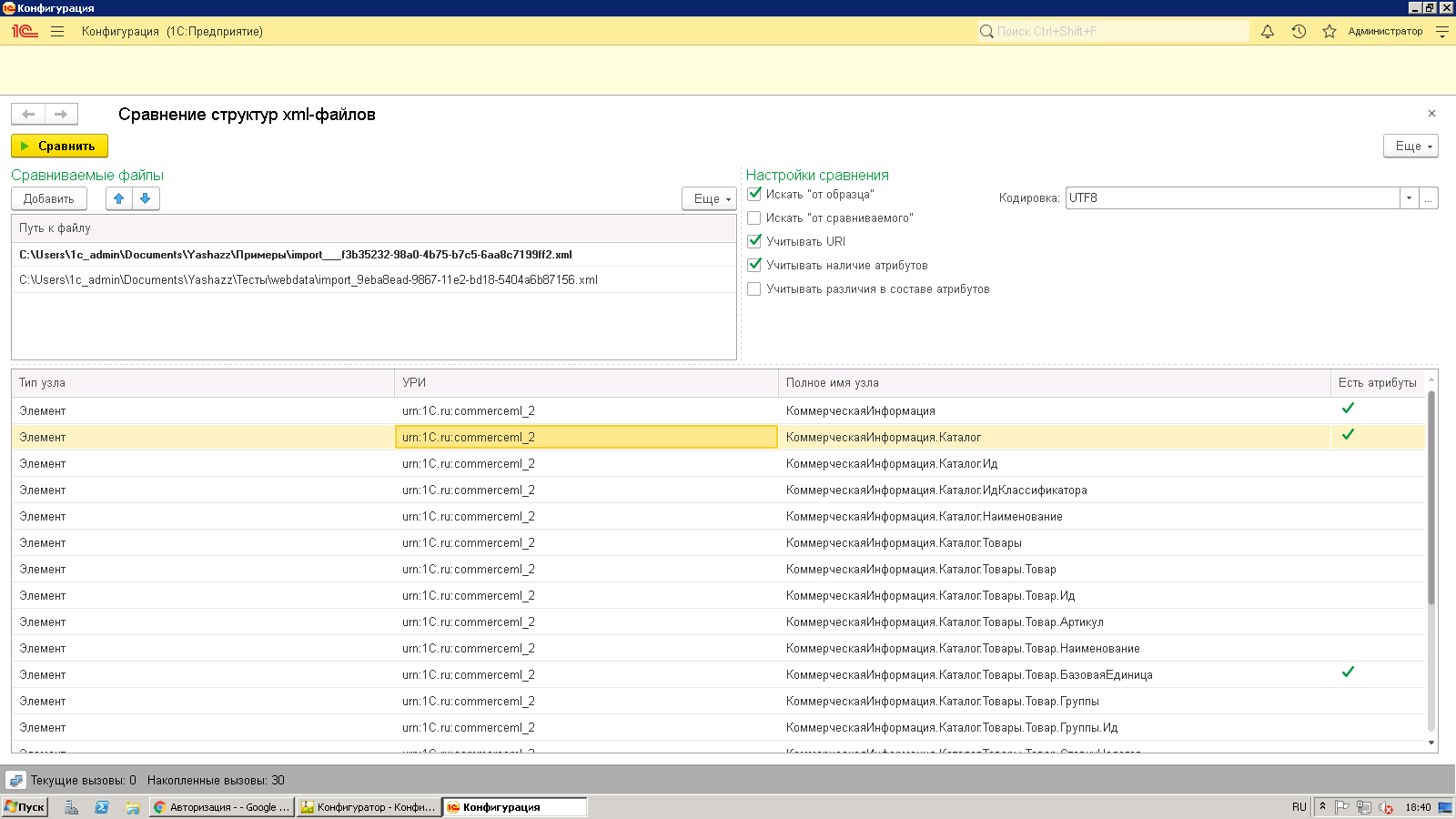


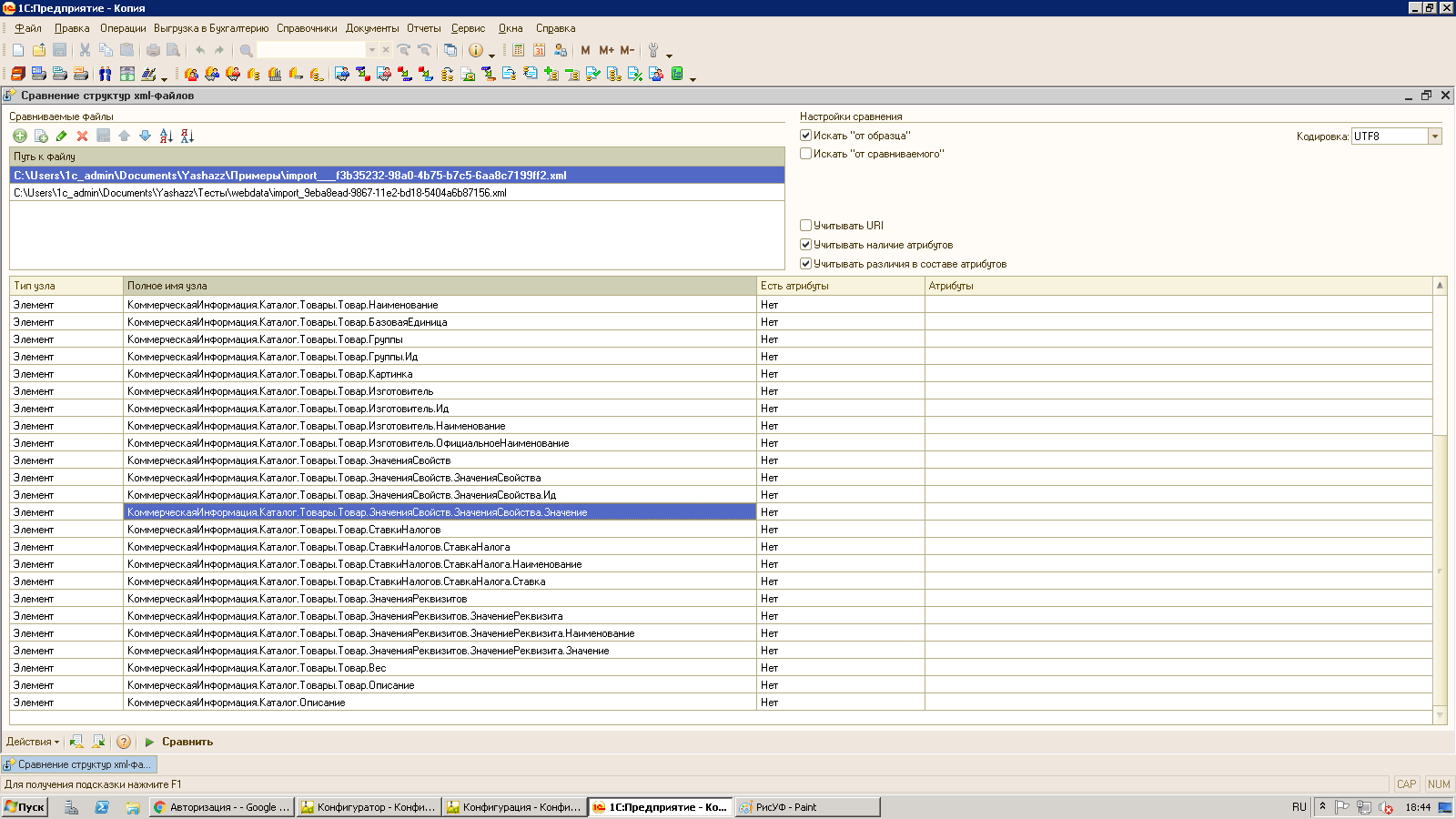
Есть несколько файлов и есть образец, с которым их все надо сравнить. Например, некий обмен и вам дали образец, и вы пишете код, делающий файлы согласно образцу. Обработка позволяет отследить недочёты, допущенные в тегах, атрибутах, но игнорируя текстовое содержимое. Также игнорируются значения атрибутов, секции CData итд. По сути, это только две структуры с типами узлов, полными путями узлов, фактом наличия атрибутов и их именами.
Можно настраивать режимы сравнения - все файлы с образцом (т.е. данные, которые есть в файле, но нет в образце), или образец с каждым из файлов (т.е. данные, которые есть в образце, но нет в файле). Можно указать, учитывать ли пространства имён (каждого тега), наличие атрибутов, их имена.
Использованы 2 технологии - для релизов до 8.3.10 обычное ЧтениеXML из файла, для 8.3.10 и выше - через двоичные данные (описано в статье //infostart.ru/public/1130284/). Использовано чтение через документ DOM. Сделаны обычная и управляемая форма (асинхрон, без модальных). Одинаковые по структуре узлы схлопываются, что убыстряет работу.
Результаты показываются в виде таблиц с полным путём каждого узла. Различия в атрибутах в текущей версии не показываются - если надо, пишите в комментах, выведу. Файл, чей путь указан первым, считается образцом. При движении по таблице путей файлов для образца показывается его таблица данных по структуре, для остальных строк - таблицы результатов сравнения, различия; либо сообщение, что различий нет.
Если попадутся косяки - просьба писать, буду допиливать, т.к. материала для тестирования сейчас маловато.
Также, можно встроить разрезку хмл-файлов на куски, если они окажутся слишком велики для DOM, с помощью технологии, описанной в той же статье.
Тестировалось на 8.3.15.1534.

{kind=link}