









{kind=link}
Для чего нужен веб-разбор
Веб-разбор сайтов нужен для автоматизации получения структурированных данных, к которым отсутствует иной способ программного доступа.
В основном это нужно для последующей автоматизированной обработки собранных данных.
Например, разбор сайтов поставщиков или конкурентов для составления списка товаров и цен.
Автоматический разборщик в своей работе опирается на html разметку сайта.
Из этого можно сделать простой вывод, что настроенные алгоритмы разбора работают ровно до того момента, как структура верстки значительно изменилась.
После изменения структуры верстки, разборщика надо снова перенастраивать (обучать).
Однако, если данных достаточно много, то написание и переобучение автоматического разборщика гораздо выгоднее ручного человеческого труда по копи-вставке.
Почему именно chrome devtools инструменты
Выбор данного подхода был выбран по следующим причинам:
*) По роду своей деятельности (я делаю веб для 1С) мне приходится много работать с этим инструментом и мне было интересно применить этот инструмент и для других целей;
*) Это отличный повод написать публикацию из разряда "Смотри как умею" :)
Если более развернуто ответить на сей вопрос, то подходы веб-разбора, основанный на получении простой html строки стремительно уходят в прошлое.
Сейчас все больше сайтов делаются по ОСП технологии (ОдноСтраничные Приложения) и на get запрос с сервера может приехать пустая страничка с подключенным js кодом. Что здесь разбирать ?
А при работе с сайтом через devtools, мы можем прочитать уже зрительно отображенные данные, которые обозреватель уже отрисовал кодом из js скрипта.
Для тех, кто к вебу имеет отдаленное отношение, расскажу пару слов, что такое приблуды разраба (devtools).
Инструменты разраба (от враж. «development tools» или сокращённо «DevTools») ^72; это программы, позволяющие создавать, тестировать и отлаживать программное обеспечение.
Современные обозреватели, Safari, Firefox, Microsoft Edge, Chrome и другие, имеют встроенные инструменты разработчика, позволяющие просмотреть исходный код сайта.
Отдельно устанавливать их не требуется.
С их помощью можно просматривать и отлаживать HTML сайта, его CSS и Javascript. Также можно проверить сетевой трафик, потребляемый сайтом, его быстродействие и много других параметров.
Так вот через эти приблуды можно управлять обозревателем извне:
*) Подключиться к обозревателю;
*) Оправить команду перехода на сайт;
*) Отправить команду поиска определенного элемента;
*) Получить html содержимое определенного элемента;
*) Отправить команду закрытия обозревателя;
Все управление выполняется через веб-гнезда. Для этого закрываем обозреватель и заново запускаем его с ключами командной строки. Запущенный обозреватель поднимает внутри себя сервер веб-гнезд и готов принимать подключения и выполнять команды. Ничего сложного (хе-хе, пока разберешься до уровня "ничего сложного" пуд соли скушаешь).
Более подробно описано на сайте https://chromedevtools.github.io/devtools-protocol/
Плюс можно посмотреть в коде приложенной обработки как оно работает на практике.
Мною выполнено несколько проектов на этой обработке. Например, https://youtu.be/hGplfrx4ubM
Структура обработки-шаблона
Итак, лирическое вводное отступление прошли и переходим к практике. Начнем с устройства обработки.
Обработка содержит в себе следующие блоки:
*) Подготовку набора адресов страничек, которые будем разбирать;
*) Запуск обозревателя;
*) Подключение родной компоненты для общения с обозревателем через веб-гнезда (компонента встроена);
*) Проход по каждой строке набора страничек;
*) Отправка команды обозревателю для перехода на целевой адрес в новой вкладке.
*) Выполнение команд: щелчки на элементах сайта, поиск определенных элементов структуры, передача 1С данных в виде html строки для разбора;
*) Преобразование сырых html данных в тз сырых данных;
*) Создание итоговой тз нужного формата и заполнение строк из тз с сырыми данными;
*) Обработка тз с итоговыми данными (запись в базу);
*) Закрытие обозревателя;
Обработка предназначена для запуска из регламентного задания. На форму обработки прокинута только одна кнопка для возможности ручного запуска. При этом весь код выполняется полностью на сервере.
Это надо учитывать, если вы запустите обработку в серверной базе и не увидите результата :)
Применение обработки для получения списка цитат
Применять обработку на практике будем на сайте с цитатами из произведений Пушкина. Да, любителям портить свой язык вражизмами посвящается.

[Экрозапись1. Запуск двух вкладок обозревателя и закрытие]
Открываем обработку и нажимаем кнопку запуска. Зрительно мы видим следующие действия:
*) Запустился обозреватель;
*) Запустились по очереди две вкладки;
*) Закрылся обозреватель;
Далее по очереди разберем каждое действие.
Запуск обозревателя
Запуск обозревателя должен выполняться на порту 9222 (по умолчанию). При запуске должен подняться сервер, который мы и проверяем в трех попытках через каждые три секунды. Если обозреватель поднялся и отвечает, то ага и продолжаем дальше.
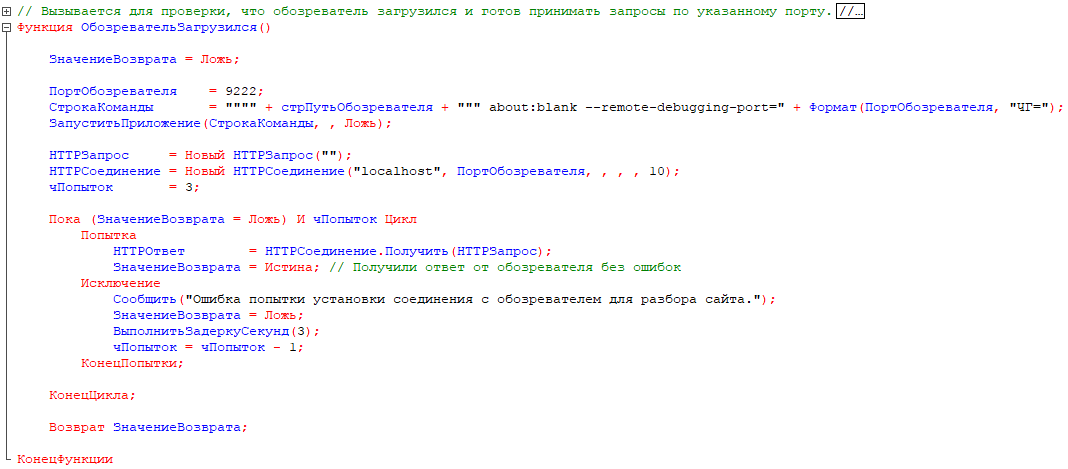
[Экроснимок2. Запуск обозревателя на порту по умолчанию]
Открытие вкладки с целью разбора
Следующим шагом мы должны открыть целевую страничку на новой вкладке и подключиться к этой вкладке. Для этого мы должны сделать запрос к обозревателю с указанием команды "/json/new?" и адреса загружаемой цели.
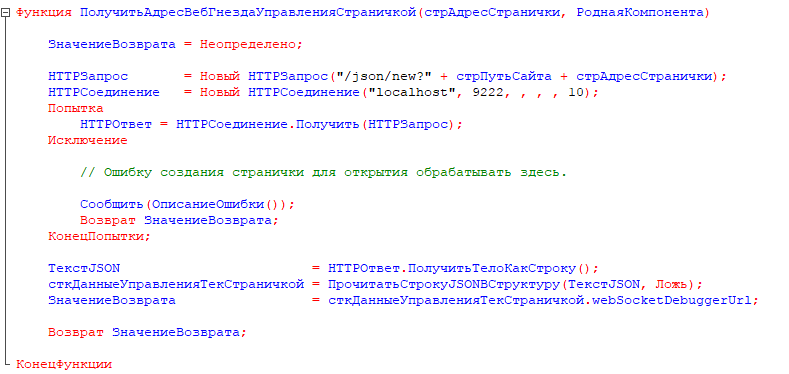
[Экроснимок3. Загрузка цели в новой вкладке]
В ответ обозреватель должен нам вернуть через ключ "webSocketDebuggerUrl" адрес вкладки для управления.
В момент открытия вкладки, обозреватель как раз и выполняет построение структуры сайта. И нам уже без разницы, это ОСП сайт или статичная верстка.
Получение строки html с данными
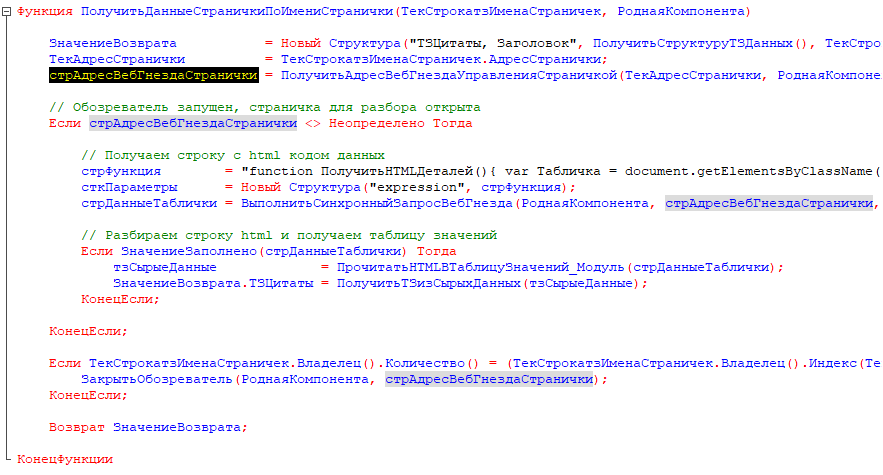
[Экроснимок4. Выполнение запросов к вкладке по адресу]
Зная адрес веб-гнезда вкладки из прошлого шага, мы можем отправлять команды обозревателю, которые будут применены именно к этой вкладке. Для наших целей мы будем выполнять синхронные запросы для получения строки html с сырыми исходными данными.
Разбор html строки в тз с сырыми данными
Разбирать html строку мы будем в промежуточную таблицу следующей структуры.

[Экроснимок5. Структура тз сырых данных]
Данная структура позволит нам разобрать дерево html в плоский вид, а потом перебрать строки и, ориентуясь на классы, сделать тз с итоговыми данными.
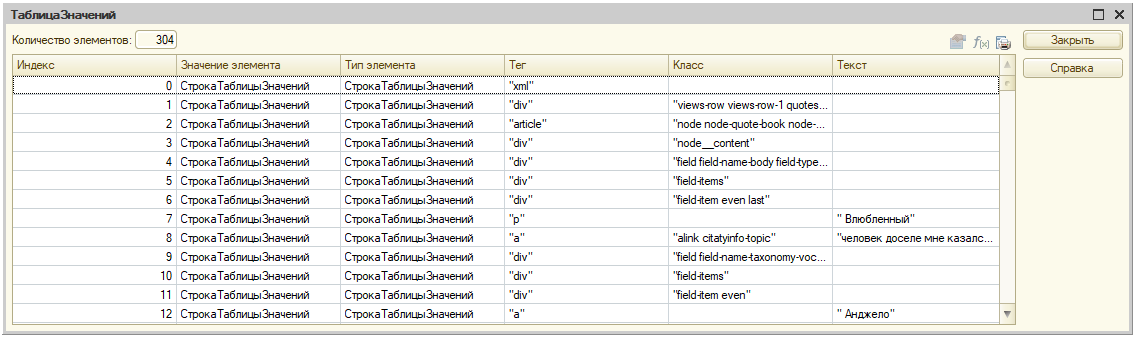
[Экроснимок6. ТЗ сырых данных]
Формирование итоговой ТЗ с затребованной структурой данных
В данном примере мы хотим получить табличку с данными о авторе цитаты, саму цитату и оценку цитаты.
Для этого мы перебираем строки, ориентуясь на классы.

[Экроснимок8. Алгоритм разбора тз сырых данных]
В итоге мы получаем желаемый результат.
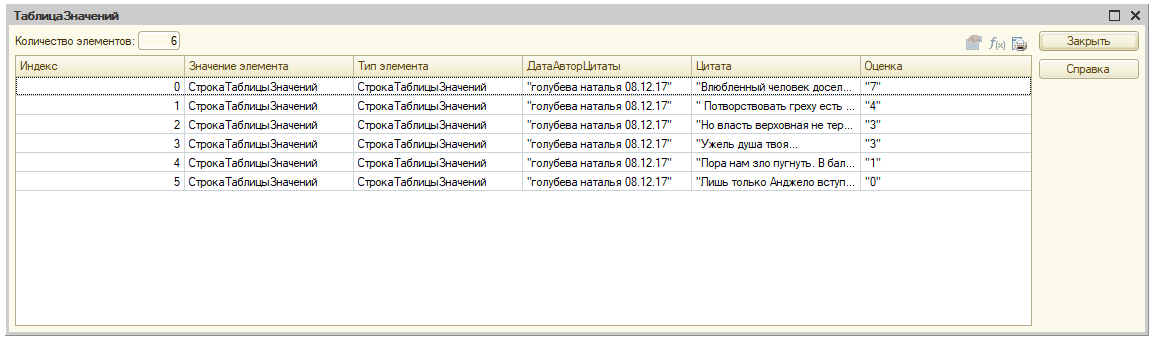
[Экроснимок9. Итоговый результат]
Автозакрытие обозревателя
Автозакрытие должно быть вызвано последней командой.

[Экроснимок7. Закрытие обозревателя]
На этом веб-разбор можно считать выполненным.
Повторюсь, что рабочий пример можно запустить и подробно изучить на примере данной обработки.
Если будут некоторые вопросы по обработке, смело обращайтесь, постараюсь помочь !
---
Данная публикация написана благодаря поддержке компании ITLand.
Лично благодарю руководителя отдела разработки за своевременные и грамотные ответы на мои вопросы.
---
Обработка писалась и тестировалась на версии 8.3.10.
Вступайте в нашу телеграмм-группу Инфостарт