

Поводом к написанию обработки стала необходимость отладить выражение XPath, которое должно было вычисляться относительно узла, расположенного где-то в середине большого файла. К моему удивлению, адекватных бесплатных средств работы с XML, которые бы позволили это сделать - нет.
Все те утилиты, которые удалось найти делали это либо плохо, либо не так, как надо. Нужный функционал был в платном пакете XML Spy, однако, даже там нужно было писать весь путь от начала документа. Мне же нужно было проверить выражение относительно середины документа....
В результате, получилась данная обработка. Возможности:
- Быстро и просто подготовить отладку выражения - вставить XML текст, ввести выражение, выполнить.
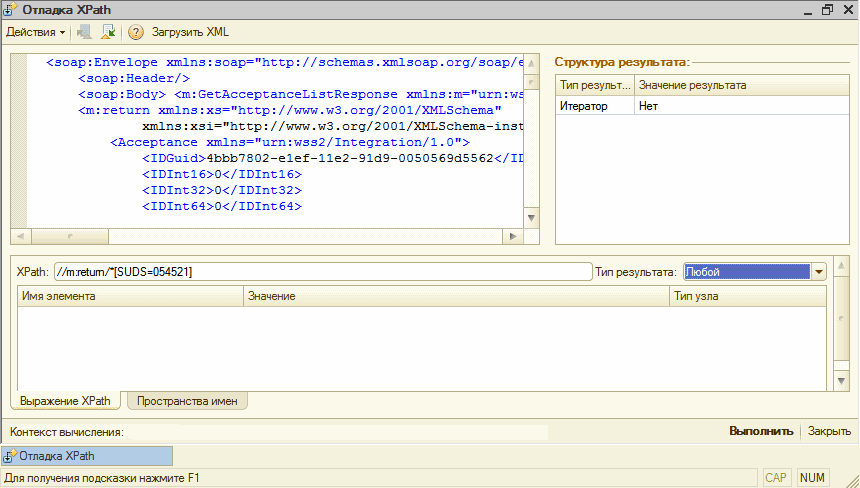
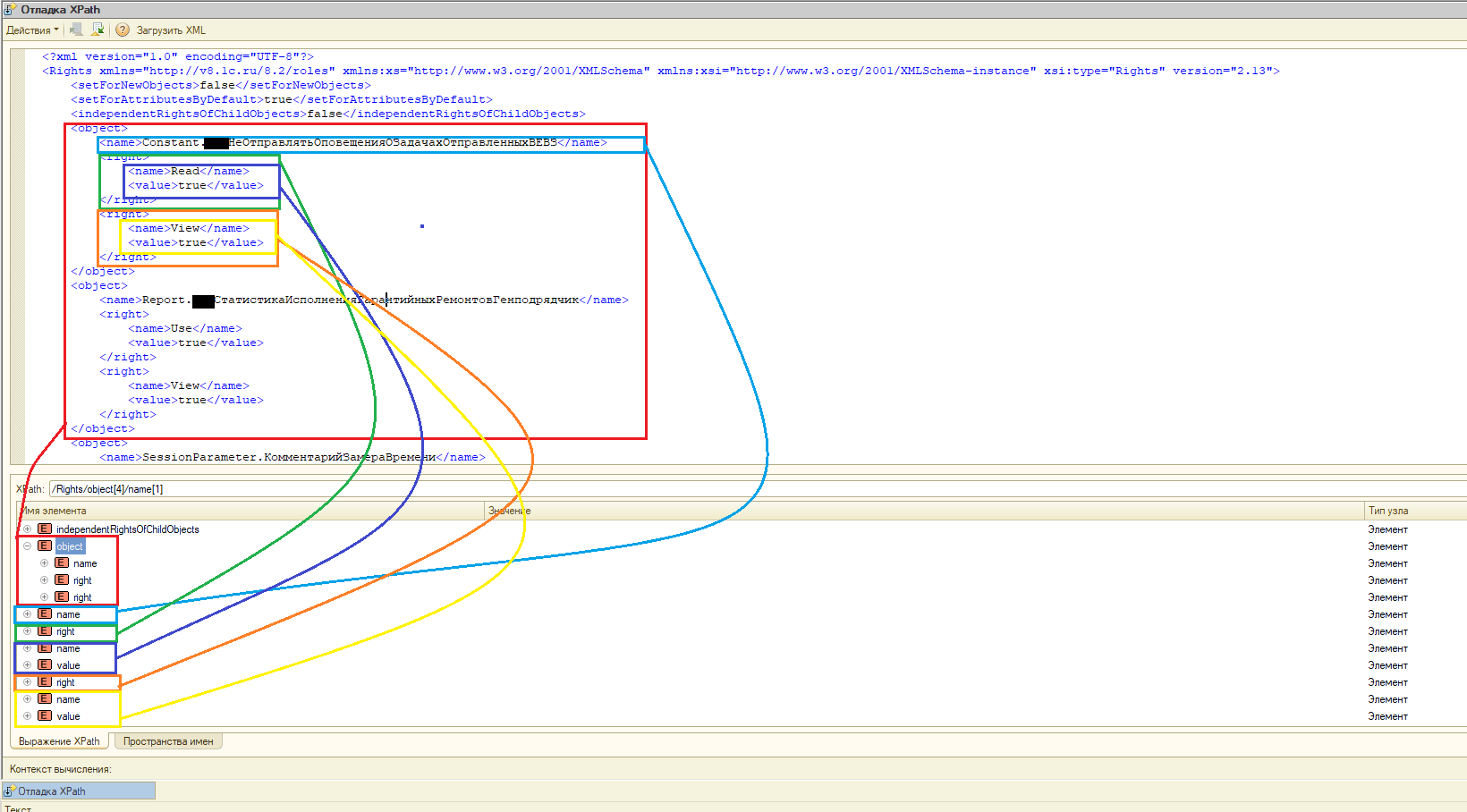
- Отображает результат выражения в виде дерева узлов. Все узлы, попавшие в результат выражения визуализируются.
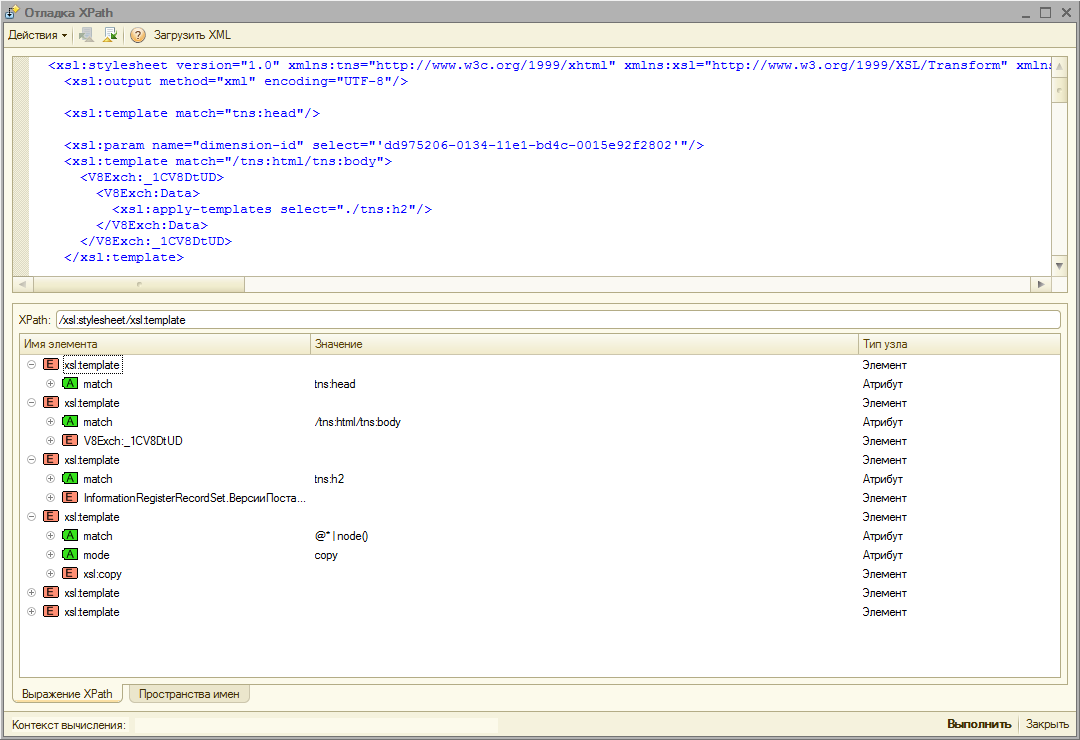
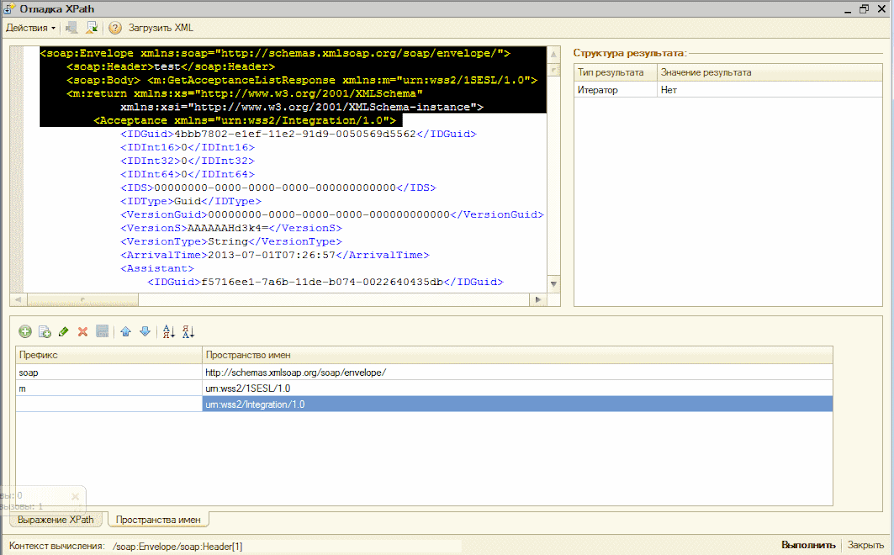
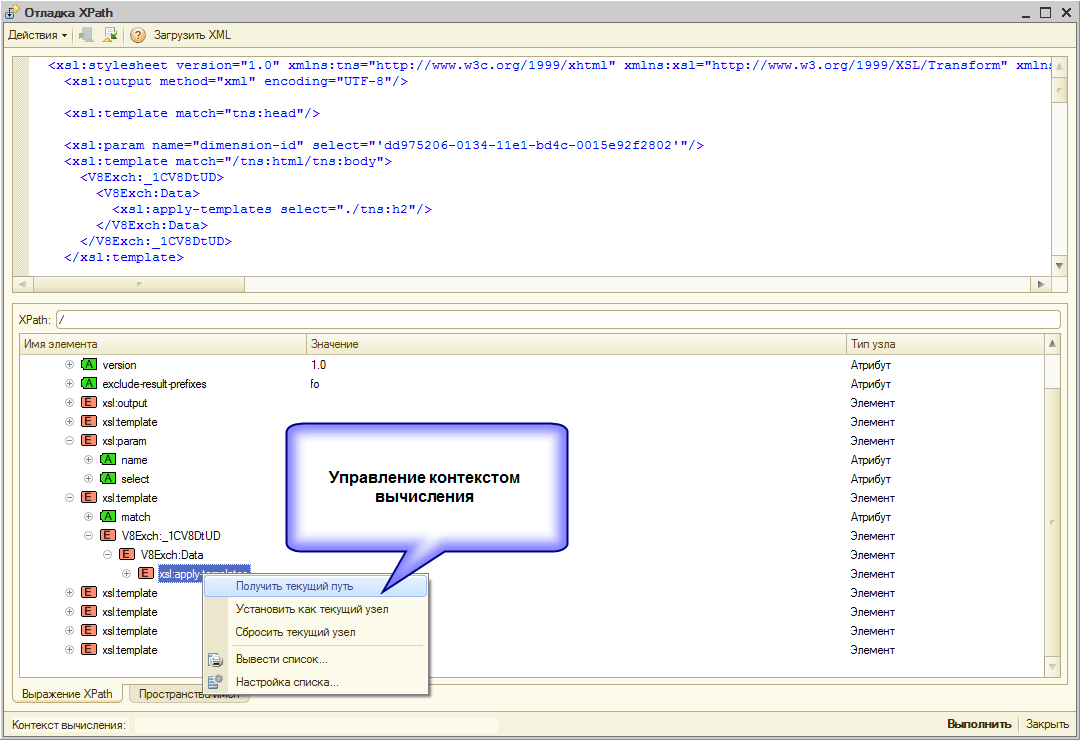
- Позволяет узнать текущий путь в документе для любого узла. То есть, для любого узла можем получить его путь в виде "/parent/parent[2]/child[3]"
- Позволяет вычислять выражение относительно произвольного контекста. Например, есть длинный документ, в середине которого есть узел, на котором вам нужно вычислить выражение. Порядок действий:
- 1. Вычисляем выражение "/" и получаем визуальное дерево документа (выполнять п.1 необязательно, можно писать сразу выражение)
- 2. Переходим в дереве на нужный узел и устанавливаем его в качестве текущего
- 3. Пишем выражение относительно текущего узла, а не от корня документа, как в большинстве аналогов
- 4. Наслаждаемся
При просмотре дерева используется динамический выбор узлов DOM, т.е. дерево результата не строится целиком, а экономит память и отображает узлы по мере необходимости.
Вступайте в нашу телеграмм-группу Инфостарт



{kind=link}