





{kind=link}
Итак, фичи:
- Чтение заголовка файла обмена с возможностью редактирования номеров сообщений, кодов узлов и т.п. Это можно и блокнотом сделать, конечно. Если он у вас откроет xml-файл на, скажем, 1.5 Гб.
- Статистический анализ содержимого: типы объектов, их количество, размер занимаемый в файле с возможной детализацией до объекта, количество и состав дублей вы файле выгрузки.
- Возможность пересохранить файл с набором опций: с измененной шапкой, изменить состав объектов в результирующем файле с точностью до каждого из них, возможность не выгружать дублирующую информацию.
- Возможность разделить файл на примерно равные части по объему.
Тестирование: Проверял в работе на платформах 8.3.18, .20, .21. Должно работать и в более ранних версиях.
Требования: наличие БСП.
Ограничения: не умеет работать с расширениями формата обмена (Можно сделать, но не было примера для тестов).
Инструкция по использованию
Выбор файла и структура его шапки
На первом скрине представлена начальная страница обработки. В самом верху необходимо выбрать файл. Поддерживаются как xml, так и zip-архивы. После выбора файла нажимаем "Анализ" и ждем результатов. Работает достаточно быстро.
После анализа файла будет заполнены все поля на форме. Информация о плане обмена, кодах узлов и номерах сообщений будет доступна только если выбран файл выгрузки через план обмена. Поле "Узел корреспондента" будет заполнено только если обработка открыта в одной из баз, участвующих в обмене.
Все поля доступны для редактирования. При сохранении файла (последняя вкладка) в результирующий файл будет записана шапка с корректировками.
Анализ состава файла
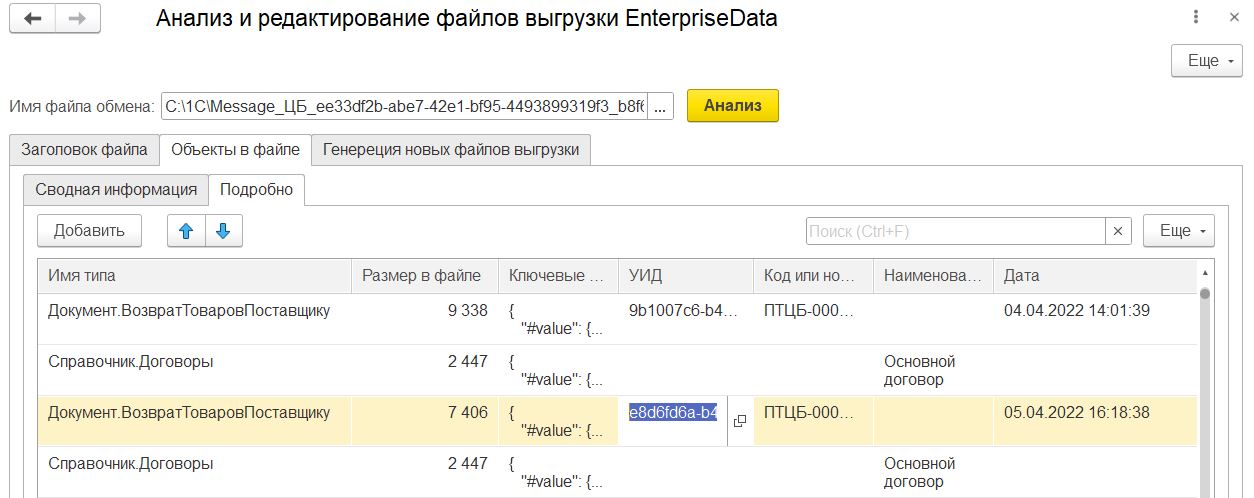
На странице "Объекты в файле" есть две вкладки "Сводная информация" и "Подробно". Скрины 2 и 3.
В сводной информации выводится две таблицы:
1. Перечень объектов в файле выгрузки. Группировка "Это удаление" тут и далее представляет собой признак, что передается информация об удалении объекта. Для каждого типа выводится количество объектов этого типа, общий размер в файле и средний размер одного объекта.
2. Объекты, выгруженные неоднократно. Тут стоит заметить, что уникальность объекта в файле выгрузки я определяю по тегу "Ключевые поля" в разрезе типов объектов и признака "это удаление". Типовая синхронизация грешит тем, что не ведет уникальность объектов, которые она получает на выгрузку не по ссылке, а в виде структуры. В моем примере - это 6+ тысяч раз выгружена структура, которая представляет собой один договор. В этой таблице будут собраны все дубли в выгрузке с указанием их количества и размера в файле.
На вкладке "Подробно" представлена таблица со всеми объектам из файла. Для каждого из них выведены:
- тип объекта
- размер в файле
- полностью тег "ключевые поля"
- если есть УИД объекта, то он выведен. При этом из поля с УИДом можно открыть сам объект. (внимание! если в базе нет объекта метаданных с именем, как в поле "имя типа", то открываться объект будет достаточно долго!)
- для справочников и документов выводятся код или номер соответственно
- для справочников выводится наименование, если оно было в ключевых полях
- для документов выводится дата документа
- колонка с признаком "это удаление"
Вкладка "Генерация новых файлов выгрузки"
На вкладке следует указать новое имя файла, в который будет произведена запись. Конечный файл не может быть исходным. Т.е. нельзя перезаписать тот же самый файл.
Если поставить галочку "Разделить выгрузку на части", то будет предложено указать размер каждой части в килобайтах. При сохранении обработка будет накапливать размер выгруженных объектов и при достижении лимита создаст новый файл. В этом режиме к имени файла будет добавляться суффикс с индексом. Так же стоит отметить, что в этом режиме (только в этом) не будет сохраняться информация об обмене через план обмена и типовая синхронизация этих "кусков" не увидит. Для загрузки полученных файлов нужно будет воспользоваться обработкой "Выгрузка EnterpriseData", которая идет вместе с БСП. Ссылка на нее есть на форме обработки.
Если поставить галочку "Не выгружать дубли", то при формировании файла выгрузки обработка проследит, чтобы в него не попали дубли по ключевым полям.
Ниже расположено дерево значений, где можно галочками отметить, какие объекты будут выгружены. Снимать галочки можно с узлов. Колонка "Размер в файле" динамически пересчитывается и даст вам представление о том, какого размера получится файл. Галочки можно устанавливать с точностью до объекта. Для каждого объекта выведена информация по аналогии с таблицей "Подробно" анализа содержимого файла. В поле УИД так же есть кнопка открытия объекта базы с этим УИДом.
После выполнения всех настроек выгрузки следует нажать "Сохранить файл".
Пара замечаний
1. Размер в файле. Это не точный размер. Это "оптимистичная оценка". Результат будет скорее всего немного больше.
2. При загрузке файла, разделенного на части, не имеет значения в каком порядке грузить данные. На практике я не увидел недостатков.
3. Как следствие п.2 - есть интересный вариант: последовательно отмечать к выгрузке объекты разных типов, а потом грузить данные параллельно из нескольких клиентов. Фантастический буст по скорости загрузки.
4. Допустим, в одной базе была заведена новая номенклатура и введен документ ее приобретения. Был сформирован файл выгрузки в бухгалтерию. Моей обработкой этот файл поделили на части так, что данные о новой номенклатуре оказались в одном файле, а данные о приобретении с этой номенклатурой - в другом. Эти два файла грузят в базу вручную. Причем первым грузят тот, где есть документ, но нет справочника. Что будет? Ошибка? Я специально моделировал такую ситуацию для проверки. В этом случае обработка загрузки загрузит документ и для его заполнения создаст новый элемент номенклатуры по ключевым полям. Т.е. никаких "объект не найден" не случится. Если следом загрузить второй файл с номенклатурой, то ее карточка будет дозаполнена корректно.
5. Желательно хорошо представлять, как работают типовые механизмы обмена, если вы собираетесь редактировать шапку файла обмена. Можно легко сбить номера принятых/полученных на узлах. Но это не смертельно, они выправляются легко. Главное, чтобы вы понимали, как это работает и зачем нужно.
Вступайте в нашу телеграмм-группу Инфостарт