


.png")
.png")

{kind=link}
К сожалению, не всегда хватает функций, которые встроены в платформу, нужно конкретное решение, например, то, что используется в искусственном интеллекте или же в любом поисковике - это анализ самого предложения или слова. Конечно, до искусственного интеллекта дело еще дойдет, но нужно сейчас только проанализировать и сопоставить, или же посчитать, или же заменить слова на любые требуемые предложения или разделенные массив слов, там уже кому как повезет с проектом. Для реализации такого механизма как-то хотелось полноценное решение, ждать платформу 8.23 как-то хочется, но не сейчас :) Ну, в общем, из разных источников был собран небольшой механизм, который может решить вышеописанную задачу.
QUOTING
\x where x is non-alphanumeric is a literal x
\Q...\E treat enclosed characters as literal
ESCAPED CHARACTERS
This table applies to ASCII and Unicode environments. An unrecognized escape sequence causes an error.
\a alarm, that is, the BEL character (hex 07)
\cx "control-x", where x is any ASCII printing character
\e escape (hex 1B)
\f form feed (hex 0C)
\n newline (hex 0A)
\r carriage return (hex 0D)
\t tab (hex 09)
\0dd character with octal code 0dd
\ddd character with octal code ddd, or backreference
\o{ddd..} character with octal code ddd..
\N{U+hh..} character with Unicode code point hh.. (Unicode mode only)
\xhh character with hex code hh
\x{hh..} character with hex code hh..
CHARACTER TYPES
. any character except newline;
in dotall mode, any character whatsoever
\C one code unit, even in UTF mode (best avoided)
\d a decimal digit
\D a character that is not a decimal digit
\h a horizontal white space character
\H a character that is not a horizontal white space character
\N a character that is not a newline
\p{xx} a character with the xx property
\P{xx} a character without the xx property
\R a newline sequence
\s a white space character
\S a character that is not a white space character
\v a vertical white space character
\V a character that is not a vertical white space character
\w a "word" character
\W a "non-word" character
\X a Unicode extended grapheme cluster
GENERAL CATEGORY PROPERTIES FOR \p and \P
C Other
Cc Control
Cf Format
Cn Unassigned
Co Private use
Cs Surrogate
L Letter
Ll Lower case letter
Lm Modifier letter
Lo Other letter
Lt Title case letter
Lu Upper case letter
L& Ll, Lu, or Lt
M Mark
Mc Spacing mark
Me Enclosing mark
Mn Non-spacing mark
N Number
Nd Decimal number
Nl Letter number
No Other number
P Punctuation
Pc Connector punctuation
Pd Dash punctuation
Pe Close punctuation
Pf Final punctuation
Pi Initial punctuation
Po Other punctuation
Ps Open punctuation
S Symbol
Sc Currency symbol
Sk Modifier symbol
Sm Mathematical symbol
So Other symbol
Z Separator
Zl Line separator
Zp Paragraph separator
Zs Space separator
PCRE2 SPECIAL CATEGORY PROPERTIES FOR \p and \P
Xan Alphanumeric: union of properties L and N
Xps POSIX space: property Z or tab, NL, VT, FF, CR
Xsp Perl space: property Z or tab, NL, VT, FF, CR
Xuc Univerally-named character: one that can be
represented by a Universal Character Name
Xwd Perl word: property Xan or underscore
CHARACTER CLASSES
[...] positive character class
[^...] negative character class
[x-y] range (can be used for hex characters)
[[:xxx:]] positive POSIX named set
[[:^xxx:]] negative POSIX named set
alnum alphanumeric
alpha alphabetic
ascii 0-127
blank space or tab
cntrl control character
digit decimal digit
graph printing, excluding space
lower lower case letter
print printing, including space
punct printing, excluding alphanumeric
space white space
upper upper case letter
word same as \w
xdigit hexadecimal digit
QUANTIFIERS
? 0 or 1, greedy
?+ 0 or 1, possessive
?? 0 or 1, lazy
* 0 or more, greedy
*+ 0 or more, possessive
*? 0 or more, lazy
+ 1 or more, greedy
++ 1 or more, possessive
+? 1 or more, lazy
{n} exactly n
{n,m} at least n, no more than m, greedy
{n,m}+ at least n, no more than m, possessive
{n,m}? at least n, no more than m, lazy
{n,} n or more, greedy
{n,}+ n or more, possessive
{n,}? n or more, lazy
ANCHORS AND SIMPLE ASSERTIONS
\b word boundary
\B not a word boundary
^ start of subject
also after an internal newline in multiline mode
(after any newline if PCRE2_ALT_CIRCUMFLEX is set)
\A start of subject
$ end of subject
also before newline at end of subject
also before internal newline in multiline mode
\Z end of subject
also before newline at end of subject
\z end of subject
\G first matching position in subject
REPORTED MATCH POINT SETTING
\K set reported start of match
ALTERNATION
expr|expr|expr...
CAPTURING
(...) capture group
(?<name>...) named capture group (Perl)
(?'name'...) named capture group (Perl)
(?P<name>...) named capture group (Python)
(?:...) non-capture group
(?|...) non-capture group; reset group numbers for
capture groups in each alternative
ATOMIC GROUPS
(?>...) atomic non-capture group
(*atomic:...) atomic non-capture group
COMMENT
(?#....) comment (not nestable)
OPTION SETTING
Changes of these options within a group are automatically cancelled at the end of the group.
(?i) caseless
(?J) allow duplicate named groups
(?m) multiline
(?n) no auto capture
(?s) single line (dotall)
(?U) default ungreedy (lazy)
(?x) extended: ignore white space except in classes
(?xx) as (?x) but also ignore space and tab in classes
(?-...) unset option(s)
(?^) unset imnsx options
(*LIMIT_DEPTH=d) set the backtracking limit to d
(*LIMIT_HEAP=d) set the heap size limit to d * 1024 bytes
(*LIMIT_MATCH=d) set the match limit to d
(*NOTEMPTY) set PCRE2_NOTEMPTY when matching
(*NOTEMPTY_ATSTART) set PCRE2_NOTEMPTY_ATSTART when matching
(*NO_AUTO_POSSESS) no auto-possessification (PCRE2_NO_AUTO_POSSESS)
(*NO_DOTSTAR_ANCHOR) no .* anchoring (PCRE2_NO_DOTSTAR_ANCHOR)
(*NO_JIT) disable JIT optimization
(*NO_START_OPT) no start-match optimization (PCRE2_NO_START_OPTIMIZE)
(*UTF) set appropriate UTF mode for the library in use
(*UCP) set PCRE2_UCP (use Unicode properties for \d etc)
NEWLINE CONVENTION
These are recognized only at the very start of the pattern or after option settings with a similar syntax.
(*CR) carriage return only
(*LF) linefeed only
(*CRLF) carriage return followed by linefeed
(*ANYCRLF) all three of the above
(*ANY) any Unicode newline sequence
(*NUL) the NUL character (binary zero)
WHAT \R MATCHES
These are recognized only at the very start of the pattern or after option setting with a similar syntax.
(*BSR_ANYCRLF) CR, LF, or CRLF
(*BSR_UNICODE) any Unicode newline sequence
LOOKAHEAD AND LOOKBEHIND ASSERTIONS
(?=...) )
(*pla:...) ) positive lookahead
(*positive_lookahead:...) )
(?!...) )
(*nla:...) ) negative lookahead
(*negative_lookahead:...) )
(?<=...) )
(*plb:...) ) positive lookbehind
(*positive_lookbehind:...) )
(?<!...) )
(*nlb:...) ) negative lookbehind
(*negative_lookbehind:...) )
NON-ATOMIC LOOKAROUND ASSERTIONS
These assertions are specific to PCRE2 and are not Perl-compatible.
(?*...) )
(*napla:...) ) synonyms
(*non_atomic_positive_lookahead:...) )
(?<*...) )
(*naplb:...) ) synonyms
(*non_atomic_positive_lookbehind:...) )
SCRIPT RUNS
(*script_run:...) ) script run, can be backtracked into
(*sr:...) )
(*atomic_script_run:...) ) atomic script run
(*asr:...) )
BACKREFERENCES
\n reference by number (can be ambiguous)
\gn reference by number
\g{n} reference by number
\g+n relative reference by number (PCRE2 extension)
\g-n relative reference by number
\g{+n} relative reference by number (PCRE2 extension)
\g{-n} relative reference by number
\k<name> reference by name (Perl)
\k'name' reference by name (Perl)
\g{name} reference by name (Perl)
\k{name} reference by name (.NET)
(?P=name) reference by name (Python)
SUBROUTINE REFERENCES (POSSIBLY RECURSIVE)
(?R) recurse whole pattern
(?n) call subroutine by absolute number
(?+n) call subroutine by relative number
(?-n) call subroutine by relative number
(?&name) call subroutine by name (Perl)
(?P>name) call subroutine by name (Python)
\g<name> call subroutine by name (Oniguruma)
\g'name' call subroutine by name (Oniguruma)
\g<n> call subroutine by absolute number (Oniguruma)
\g'n' call subroutine by absolute number (Oniguruma)
\g<+n> call subroutine by relative number (PCRE2 extension)
\g'+n' call subroutine by relative number (PCRE2 extension)
\g<-n> call subroutine by relative number (PCRE2 extension)
\g'-n' call subroutine by relative number (PCRE2 extension)
CONDITIONAL PATTERNS
(?(condition)yes-pattern)
(?(condition)yes-pattern|no-pattern)
(?(n) absolute reference condition
(?(+n) relative reference condition
(?(-n) relative reference condition
(?(<name>) named reference condition (Perl)
(?('name') named reference condition (Perl)
(?(name) named reference condition (PCRE2, deprecated)
(?(R) overall recursion condition
(?(Rn) specific numbered group recursion condition
(?(R&name) specific named group recursion condition
(?(DEFINE) define groups for reference
(?(VERSION[>]=n.m) test PCRE2 version
(?(assert) assertion condition
Шпаргалка по регулярным выражениям
Регулярное выражение представляет собой «строку-шаблон», написанную на формальном языке поиска, по которой производится поиск в целевом строковом представлении (контенте). «Строка-шаблон» состоит из строковых, цифровых и специальных символов, а также заключается между ограничителями шаблона (/RegExp/). В роли ограничителей шаблона нельзя использовать буквы и цифры, чаще всего используются /, # и ~.
В шпаргалке описываются регулярные выражения, работающие с библиотекой PCRE.
Метасимволы
Зарезервированные специальные символы. Для использования метасимвола, как обычного литерала, необходимо экранировать его, для этого нужно поставить \ непосредственно перед экронируемым метасимволом, например . — это совпадение с любым символом кроме пробельного, а \. — это совпадение только с точкой.
Позиционные:
^— начало строки (/^RegExp/), внутри символьного класса трактуется как литерал или знак отрицания (зависит от расположения в наборе).$— конец строки (/RegExp$/), внутри символьного класса трактуется как литерал.\A— начало текста (/\ARegExp/), похож на^, но в мультистроковом режиме\Aбудет всегда обозначать начало всего текста, а^— начало каждой строки;\z— конец текста (/RegExp\z/), похож на$, но в мультистроковом режиме\zбудет всегда обозначать конец всего текста, а$— конец каждой строки;\Z— похож на\z, но если последним символом текста является перевод строки, то\Zбудет занимать позицию, находящуюся перед последним переводом строки, а\zвсегда будет на позиции в самом конце текста;\b— обозначает границу слова, для обращения к первой букве словаwww«W» используется так (\bw), а к последней букве так (w\b);\B— обратное от\b, для обращения к средней (второй) букве «w» словаwwwиспользуется так (\Bw\B);\G— останавливается на позиции окончания повторяющихся подряд символов, например:\Gwостановится на четвертой позиции послеwww, при поиске в строкеwww.example.com.
Группирующие:
(— открывает вложенное выражение;)— закрывает вложенное выражение;|— логическое «или», может использоваться внутри ((abc|def|ghi)) и вне (abc|def|ghi) группы.
Пробельные:
\f— конец страницы;\n— новая строка;\r— возврат каретки;\t— табуляция;\v— вертикальная табуляция.
Квантификаторы (для поиска последовательностей):
{number}— точное количество вхождений;{min,max}— диапазон вхождений отminдоmax;?— ноль или одно вхождение (эквивалентно{0,1});+— одно или более одно вхождения (эквивалентно{1,});*— ноль, одно или более одно вхождения (эквивалентно{0,}).
Объединяющие (для символьных классов):
[— открывает символьный класс;]— закрывает символьный класс;-— задает диапазон символов в символьном классе ([0-9]);^— если^располагается в самом начале, то это означает отрицание всех символов, входящих в состав данного символьного класса (/[^0-9]/), на другой позиции трактуется как литерал;\d— целое число ([0-9]);\D— любой символ кроме целочисленного ([^0-9]);\s— любой пробельный символ ([\f\n\r\t\v ]);\S— любой символ кроме пробельного ([^\f\n\r\t\v ]);\w— целое число, буква и подчеркивание ([a-zA-Z0-9_]);\W— любой символ кроме целого числа, буквы и подчеркивания ([^a-zA-Z0-9_]).
Квантификаторы
Располагаются следом за символьным классом, группой или одиночным символом, указывая количество их повторений, например .* обозначает любые символы в любом количестве.
По умолчанию квантификаторы являются «жадными», например если произвести поиск всех тегов в HTML-коде <.*>, то все теги будут трактоваться как один, так как после первого совпадения следующие теги будут соответствовать .*. Для решения задачи нужно или уточнить искомый результат <[^>]*>, или сделать квантификатор «ленивым», поставив ? после квантификатора <.*?>.
Существует еще один «сверхжадный» режим, его еще называют «ревнивым», он является самым быстродейственным и служит для поиска самого длинного варианта. Данный режим полезен для проверки существования подстроки в строке, а также для исключения из результатов поиска нежелаемых совпадений. Для включения «ревнивого» режима нужно поставить + после квантификатора.
| Жадный | Ленивый | Ревнивый |
|---|---|---|
? |
?? |
?+ |
+ |
+? |
++ |
* |
*? |
*+ |
Символьные классы
Наборы различных символов, помещенные в квадратные скобки. В некоторых случаях поведение метасимволов в символьных классах может изменяться по сравнению с их аналогами, находящимися на других позициях «строки-шаблона», например . внутри набора трактуется как литерал.
[abc]— любой один символ из трех указанных: «a» или «b» или «c».[^abc]— любые символы кроме трех указанных: «a» или «b» или «c».[a-d]— символы в диапазоне от «a» до «d» (a, b, c, d).[^a-d]— любые символ кроме диапазона от «a» до «d» (a, b, c, d).[0-9]— целые числа от «0» до «9» (0, 1, 2, 3, 4, 5, 6, 7, 8, 9).[^a-d1-4]— любые символы кроме диапазона букв от «a» до «d» (a, b, c, d) и цифр от «1» до «4» (1, 2, 3, 4).
Группы (подмаски)
Группировка добавляет функционал «обратных ссылок», которые дают возможность запоминать найденные группы символов под порядковыми номерами и обращаться к ним по этим номерам как по ссылкам. Для обращения к обратным ссылкам в «строке-шаблоне» используется обратный слэш и присвоенный номер группе (\1), а для обращения в «строке-замене» — знак доллара ($1). Для примера подставим закрывающий HTML-тег заголовка:
/<h([1-6])>.*?<\/h\1>/
В некоторых случаях дополнительно к цифровым удобно использовать именованные группы ((?P<group-name>...) или ((?<group-name>...)), например для обработки динамических HTTP-роутов:
/^(?<category>[a-z0-9-]+)\/(?<post>[a-z0-9-]+)(?<extension>\.html)$/i
Встречаются ситуации, когда необходимо сгруппировать символы, но саму группу не запоминать. Для этого нужно после открывающейся скобки поставить знак вопроса и двоеточие ((?:...)).
Существует еще «атомарная группировка« ((?>...)). Она похожа на «ревнивую« квантификацию, точно также при первом найденном совпадении останавливает поиск в группе и является самой быстрой из группировок.
Подмаска дает возможность применять условия типа if и if-else:
(?(шаблон-условие)шаблон-если-успех);(?(шаблон-условие)шаблон-если-успех|шаблон-если-провал).
Также подмаску можно использовать для поиска конкретного фрагмента в целевой строке, по указанной подмаске будет производиться поиск, но при этом сама подмаска не будет включена в результат поиска.
| Формат | Название | Пример | Результат |
|---|---|---|---|
(?=...) |
Позитивный просмотр вперёд | .*(?=\.com) |
example.com example.org |
(?!...) |
Негативный просмотр вперёд | .*(?!\.com) |
example.com example.org |
(?<=...) |
Позитивный просмотр назад | (?<=example\.).* |
example.com example.org |
(?<!...) |
Негативный просмотр назад | (?<!example\.).* |
example.com example.org |
Модификаторы (флаги)
Модифицируют поведение регулярного выражения, стоящий перед модификатором - инвертирует его поведение (не распространяется на U). Флаги указываются после «строки-шаблона» в произвольном порядке (/RegExp/ugi).
g— ищет все совпадения со «строкой-шаблоном» (по умолчанию поиск останавливается после первого совпадения).i— регистронезависимость («a» и «A» считаются эквивалентными).m— мультистроковость (по умолчанию целевая строка, в котором производится поиск, считается одной строкой).s— однострочность (контент считается одной строкой в отличие от режима по умолчанию, метасимвол.включает в себя пробельные символы).u— поддержка юникода («строка-шаблон» и целевая строка будут обрабатываться в кодировке UTF-8).U— инверсия жадности квантификаторов (по умолчанию квантификаторы становятся «ленивыми», вернуть им «жадность» можно, поставив после квантификатора?).x— все неэкранированные пробельные символы, которые находятся вне символьного класса, будут проигнорированы.
Регулярные выражения (regex или regexp) очень эффективны для извлечения информации из текста. Для этого нужно произвести поиск одного или нескольких совпадений по определённому шаблону (т. е. определённой последовательности символов ASCII или unicode).
Области применения regex разнообразны, от валидации до парсинга/замены строк, передачи данных в другие форматы и Web Scraping’а.
Одна из любопытных особенностей регулярных выражений в их универсальности, стоит вам выучить синтаксис, и вы сможете применять их в любом (почти) языке программирования (JavaScript, Java, VB, C #, C / C++, Python, Perl, Ruby, Delphi, R, Tcl, и многих других). Небольшие отличия касаются только наиболее продвинутых функций и версий синтаксиса, поддерживаемых движком.
Давайте начнём с нескольких примеров.
Основы
Якоря — ^ и $
^Привет соответствует строке, начинающейся с Привет -> тестпока$ соответствует строке, заканчивающейся на пока^Привет пока$ точное совпадение (начинается и заканчивается как Привет пока)воробушки соответствует любой строке, в которой есть текст воробушки
Квантификаторы — * + ? и {}
abc* соответствует строке, в которой после ab следует 0 или более символов c -> тестabc+ соответствует строке, в которой после ab следует один или более символов cabc? соответствует строке, в которой после ab следует 0 или один символ cabc{2} соответствует строке, в которой после ab следует 2 символа cabc{2,} соответствует строке, в которой после ab следует 2 или более символов cabc{2,5} соответствует строке, в которой после ab следует от 2 до 5 символов ca(bc)* соответствует строке, в которой после ab следует 0 или более последовательностей символов bca(bc){2,5} соответствует строке, в которой после ab следует от 2 до 5 последовательностей символов bc
Оператор ИЛИ — | или []
a(b|c) соответствует строке, в которой после a следует b или c -> тестa[bc] как и в предыдущем примере
Символьные классы — \d \w \s и .
\d соответствует одному символу, который является цифрой -> тест\w соответствует слову (может состоять из букв, цифр и подчёркивания) -> тест\s соответствует символу пробела (включая табуляцию и прерывание строки). соответствует любому символу -> тест
Используйте оператор . с осторожностью, так как зачастую класс или отрицаемый класс символов (который мы рассмотрим далее) быстрее и точнее.
У операторов \d, \w и \s также есть отрицания R13; \D, \W и \S соответственно.
Например, оператор \D будет искать соответствия противоположенные \d.
\D соответствует одному символу, который не является цифрой -> тест
Некоторые символы, например ^.[$()|*+?{\ , необходимо выделять обратным слешем \ .
\$\d соответствует строке, в которой после символа $ следует одна цифра -> тест
Непечатаемые символы также можно искать, например табуляцию \t, новую строку \n, возврат каретки \r.
Флаги
Мы научились строить регулярные выражения, но забыли о фундаментальной концепции R13; флагах.
Регулярное выражение, как правило, записывается в такой форме /abc/, где шаблон для сопоставления выделен двумя слешами /. В конце выражения, мы определяем значение флага (эти значения можно комбинировать):
- g (global) R13; не возвращает результат после первого совпадения, а продолжает поиск с конца предыдущего совпадения.
- m (multi line) R13; с таким флагом, операторы
^и$вызовут совпадение в начале и конце строки ввода (line), вместо строки целиком (string). - i (insensitive) R13; делает выражение регистронезависимым (например, /aBc/i соответствует AbC).
Средний уровень
Скобочные группы R13; ()
a(bc) создаём группу со значением bc -> тестa(?:bc)* оперетор ?: отключает группу -> тестa(?<foo>bc) так, мы можем присвоить имя группе -> тест
Этот оператор очень полезен, когда нужно извлечь информацию из строк или данных, используя ваш любимый язык программирования. Любые множественные совпадения, по нескольким группам, будут представлены в виде классического массива: доступ к их значениям можно получить с помощью индекса из результатов сопоставления.
Если присвоить группам имена (используя (?<foo>...)), то можно получить их значения, используя результат сопоставления, как словарь, где ключами будут имена каждой группы.
Скобочные выражения R13; []
[abc] соответствует строке, которая содержит либо символ a или a b или a c -> такой же эффект от a|b|c -> тест[a-c] то же, что и выше[a-fA-F0–9] строка, представляющая одну шестнадцатеричную цифру без учёта регистра -> тест[0–9]% строка, содержащая символ от 0 до 9 перед знаком %[^a-zA-Z] строка, которая не имеет буквы от a до z или от A до Z. В этом случае ^ используется как отрицание в выражении -> тест
Помните, что внутри скобочных выражений все специальные символы (включая обратную косую черту \) теряют своё служебное значение, поэтому нам ненужно их экранировать.
Жадные и ленивые сопоставления
Квантификаторы ( * + {}) R13; это «жадные» операторы, потому что они продолжают поиск соответствий, как можно глубже R13; через весь текст.
Например, выражение <.+> соответствует <div>simple div</div> в This is a <div> simple div</div> test. Чтобы найти только тэг div R13; можно использовать оператор ?, сделав выражение «ленивым»:
<.+?> соответствует любому символу, один или несколько раз найденному между < и >, расширяется по мере необходимости -> тест
Обратите внимание, что хорошей практикой считается не использовать оператор . , в пользу более строгого выражения:
<[^<>]+> соответствует любому символу, кроме < или >, один или более раз встречающемуся между < и > -> тест
Продвинутый уровень
Границы слов R13; \b и \B
\babc\b выполняет поиск слова целиком -> тест
\b R13; соответствует границе слова, наподобие якоря (он похож на $ и ^), где предыдущий символ R13; словесный (например, \w), а следующий R13; нет, либо наоборот, (например, это может быть начало строки или пробел).
\B R13; соответствует несловообразующей границе. Соответствие не должно обнаруживаться на границе \b .
\Babc\B соответствует, только если шаблон полностью окружён словами -> тест
Обратные ссылки — \1
([abc])\1 \1 соответствует тексту из первой захватываемой группы -> тест([abc])([de])\2\1 можно использовать \2 (\3, \4, и т.д.) для определения порядкового номера захватываемой группы -> тест(?<foo>[abc])\k<foo> мы присвоили имя foo группе, и теперь ссылаемся на неё используя R13; (\k<foo>). Результат, как и в первом выражении -> тест
Опережающие и ретроспективные проверки — (?=) and (?<=)
d(?=r) соответствует d, только если после этого следует r, но r не будет входить в соответствие выражения -> тест(?<=r)d соответствует d, только если перед этим есть r, но r не будет входить в соответствие выражения -> тест
Вы можете использовать оператор отрицания !
d(?!r) соответствует d, только если после этого нет r, но r не будет входить в соответствие выражения -> тест(?<!r)d соответствует d, только если перед этим нет r, но r не будет входить в соответствие выражения -> тест
| символ | описание | пример | строка и соответствие |
| обычные | все символы , кроме специальных. Соответствуют сами себе | а | причал |
| от | от кота | ||
| 12 | 612-2123 | ||
| специальные символы
[ ] \ ^ $ . | ? * + ( ) { } |
Чтобы использовать как сиволы текста, нужно их предварить «\» | \(812\) | тел. (812)812-24-15 |
| 0\.5 | 320.5 3205 | ||
| е\? | Что? Где? Когда? | ||
| ^ | Начало строки | ^ааа | ааа |
| ^ма | март или май | ||
| $ | Конец строки | a$ | ааа аа$ |
| ^бег$ | бег бегун |
||
| \b | Граница слова | а\b | а он когда завтра? |
| \bон | вон он | ||
| \B | Не граница слова | \Bон | вон он |
| \G | Предыдущий успешный поиск | \Ga | aaa aaa (поиск остановился на 4-й позиции — там, где не нашлось a) |
| . | любой символ кроме символа новой строки «\n» | м.й | мой май мама |
| Символьный класс — Набор символов в квадратных скобках [ ] | в данном месте — один из перечисленных символов | 2[19]5 | 215 265 21 295 |
| он[?!] | тон? Нет, не тон. Полутон! | ||
| Возможно указание диапазонов символов. [0-9] соответствует любой цифре. [А-Яа-я] — любая буква русского алфавита кроме «ё» и «Ё» | 2[0-9]4 | 204 24234 | |
| л[А-Яа-я]н | луна лень лён слОн | ||
| л[А-Яа-яёЁ]н | луна лень лён слОн | ||
| [^] -символ, который не входит в набор | [^0-9] | 212или213 конфет | |
| \d | Соответствует цифре. Эквивалентно [0-9] | img\d | img5 img74 img |
| \D | Соответствует нецифровому символу. Эквивалентно [^0-9] | ||
| \s | Соответствует любому пробельному символу. Эквивалентно [ \f\n\r\t\v] | ||
| \S | Соответствует любому непробельному символу. Эквивалентно [^ \f\n\r\t\v] | ||
| \w | Соответствует любому буквенному символу, цифровому и знаку подчеркивания. Эквивалентно [[:word:]] | ||
| \W | Соответствует любому символу, кроме буквенного символа, цифрового или подчеркивания. Эквивалентно [^[:word:]] | ||
Квантификация (сколько раз предшествующее выражение может встречаться.) |
|||
| {n} | ровно n раз | [0-9]{3} | 316 29 15 1 |
| {m,n} | от m до n раз | [0-9]{2,3} | 316 29 15 1 |
| {m,} | не менее m раз | cто{2,}й | стой, стоой, стооой |
| {0,n} | не более n раз | сто{0,3}й | стой, стоой, стооой, стоооой |
| * | ноль или более раз. Эквивалентно {0,} | сто* | ст сто стоо |
| + | Один или более раз. Эквивалентно {1,} | сто+ | ст сто стоо |
| ? | Ноль или одно. Эквивалентно {0,1} | сто? | ст сто стоо |
| cт?л | стол стул ст5л стл | ||
Жадная и ленивая квантификация |
|||
| Жадная квантификация | Максимально длинная строка из возможных
Обычные квантификаторы * + ? {m,n} являются жадными
|
<.*> | <span>123</span> |
| \(.+\) | (812)234, (812)235 | ||
| cт.{3,}й | стооооой. Что это за лай | ||
| Ленивая квантификация
*? +? ?? {m,n}? |
Минимально длинная строка из возможных | <.*?> | <span>123</span> |
| \(.+?\) | (812)234,(812)235 | ||
| ст.{3,}?й | стооооой. Что это за лай | ||
| Сверхжадная
*+ ++ ?+ {m,n+} |
Действует как жадный, при этом не возвращается к точке возврата
|
<.*+> | <span>123</span>
Соответствие не будет найдено, поскольку после символа «<» .*+ «скушает» все оставшиеся: span>123</span> . После чего символ «>» будет не найден. |
Группировка |
|||
| () | для групировки. Шаблон внутри как единое целое. может быть квантифицирован | ([a-z][0-9]-)+ | a7-b9-c26-e5-d13 |
| (ab){3} | abcabababcdab | ||
| для получения значения | сегодня ([0-9]+) | сегодня 18 января. $1 — верёт ’18’ | |
| группировка без обратной связи (?:) |
отмена получения значения. | сегодня (?:[0-9]+) | $1 ничего не вернёт |
| () \1 … \9 | обозначения от \1 до \9 для проверки на совпадение с ранее найденной подстрокой | ([0-9])\1 | 88, 96, 99, 25,11 |
| ([а-я])[а-я]*\1 | сос, нос, кок,тот | ||
| (..|..) | или первая часть или вторая | (\+7|8)-[0-9-]* | 8-812-243-12-63, +7-376-9052412 |
| (он|ты|я) | я, ты, он, она — вместе дружная семья | ||
| атомарная групировка (?>шаблон) | запрещает проверку любых других вариантов внутри группы, когда один вариант уже найден. + отмена получения значения | a(?>bc|b|x)cc | abccaxcc но не abccaxcc : вариант x найден, остальные проигнорированы. $1 тоже ничего не вернёт |
| (?i) (?s) (?m) (?g) (?x) (?r) | Включает соответствующий модификатор | (?i)onE | onE, one, OnE |
| (?-i) (?-s) (?-m) (?-g) (?-x) (?-r) | Выключает модификатор | (?-i)onE | onE, oNe, one, OnE |
| (?i-sm) | Включает и выключает несколько модификаторов | ||
| (?i-s:шаблон) | Включает/Выключает модификаторы только в пределах группы | (?i)o(?-i:n)E | onE, oNe, one, OnE, oNE
буква n должна быть маленькой |
| (?#комментарий) | группа не проверяется на вхождение в текст. | [0-9](?#одна цифра)d5 | 5d5, d6, 67d5 |
Любое регулярное выражение из статьи вы можете сразу пощупать. Так будет понятнее, о чем речь в статье — вставили пример из статьи, потом поигрались сами, делая шаг влево, шаг вправо. Где тренироваться:
-
Notepad++ (установить Search Mode → Regular expression)
-
Regex101 (мой фаворит в онлайн вариантах)
Инструменты есть, теперь начнём
Поиск текста
Самый простой вариант регэкспа. Работает как простой поиск — ищет точно такую же строку, как вы ввели.
Текст: Море, море, океан
Regex: море
Найдет: Море, море, океан
Выделение курсивом не поможет моментально ухватить суть, что именно нашел regex, а выделить цветом в статье я не могу. Атрибут BACKGROUND-COLOR не сработал, поэтому я буду дублировать регулярки текстом (чтобы можно было скопировать себе) и рисунком, чтобы показать, что именно regex нашел:
Текст: Море, море, океан
Regex: море
Найдет: Море, море, океан
Обратите внимание, нашлось именно «море», а не первое «Море». Регулярные выражения регистрозависимые!
Хотя, конечно, есть варианты. В JavaScript можно указать дополнительный флажок i, чтобы не учитывать регистр при поиске. В блокноте (notepad++) тоже есть галка «Match case». Но учтите, что это не функция по умолчанию. И всегда стоит проверить, регистрозависимая ваша реализация поиска, или нет.
А что будет, если у нас несколько вхождений искомого слова?
Текст: Море, море, море, океан
Regex: море
Найдет: Море, море, море, океан
По умолчанию большинство механизмов обработки регэкспа вернет только первое вхождение. В JavaScript есть флаг g (global), с ним можно получить массив, содержащий все вхождения.
А что, если у нас искомое слово не само по себе, это часть слова? Регулярное выражение найдет его:
Текст: Море, 55мореон, океан
Regex: море
Найдет: Море, 55мореон, океан
Это поведение по умолчанию. Для поиска это даже хорошо. Вот, допустим, я помню, что недавно в чате коллега рассказывала какую-то историю про интересный баг в игре. Что-то там связанное с кораблем... Но что именно? Уже не помню. Как найти?
Если поиск работает только по точному совпадению, мне придется перебирать все падежи для слова «корабль». А если он работает по включению, я просто не буду писать окончание, и все равно найду нужный текст:
Regex: корабл
Найдет:
На корабле
И тут корабль
У корабля
Это статический, заранее заданный текст. Но его можно найти и без регулярок. Регулярные выражения особенно хороши, когда мы не знаем точно, что мы ищем. Мы знаем часть слова, или шаблон.
Поиск любого символа
. — найдет любой символ (один).
Текст:
Аня
Ася
Оля
Аля
Валя
Regex: А.я
Результат:
Аня
Ася
ОляАля
Валя
Точка найдет вообще любой символ, включая цифры, спецсисимволы, даже пробелы. Так что кроме нормальных имен, мы найдем и такие значения:
А6я
А&я
А я
Учтите это при поиске! Точка очень удобный символ, но в то же время очень опасный — если используете ее, обязательно тестируйте получившееся регулярное выражение. Найдет ли оно то, что нужно? А лишнее не найдет?
Точку точка тоже найдет!
Regex: file.
Найдет:
file.txt
file1.txt
file2.xls
Но что, если нам надо найти именно точку? Скажем, мы хотим найти все файлы с расширением txt и пишем такой шаблон:
Regex: .txt
Результат:
file.txt
log.txt
file.png1txt.doc
one_txt.jpg
Да, txt файлы мы нашли, но помимо них еще и «мусорные» значения, у которых слово «txt» идет в середине слова. Чтобы отсечь лишнее, мы можем использовать позицию внутри строки (о ней мы поговорим чуть дальше).
Но если мы хотим найти именно точку, то нужно ее заэкранировать — то есть добавить перед ней обратный слеш:
Regex: \.txt
Результат:
file.txt
log.txt
file.png
1txt.doc
one_txt.jpg
Также мы будем поступать со всеми спецсимволами. Хотим найти именно такой символ в тексте? Добавляем перед ним обратный слеш.
Правило поиска для точки:
. — любой символ
\. — точка
Поиск по набору символов
Допустим, мы хотим найти имена «Алла», «Анна» в списке. Можно попробовать поиск через точку, но кроме нормальных имен, вернется всякая фигня:
Regex: А..а
Результат:
Анна
Алла
аоикА74арплт
Аркан
А^&а
Абба
Если же мы хотим именно Анну да Аллу, вместо точки нужно использовать диапазон допустимых значений. Ставим квадратные скобки, а внутри них перечисляем нужные символы:
Regex: А[нл][нл]а
Результат:
Анна
Алла
аоикА74арплт
Аркан
А^&а
Абба
Вот теперь результат уже лучше! Да, нам все еще может вернуться «Анла», но такие ошибки исправим чуть позже.
Как работают квадратные скобки? Внутри них мы указываем набор допустимых символов. Это может быть перечисление нужных букв, или указание диапазона:
[нл] — только «н» и «л»
[а-я] — все русские буквы в нижнем регистре от «а» до «я» (кроме «ё»)
[А-Я] — все заглавные русские буквы
[А-Яа-яЁё] — все русские буквы
[a-z] — латиница мелким шрифтом
[a-zA-Z] — все английские буквы
[0-9] — любая цифра
[В-Ю] — буквы от «В» до «Ю» (да, диапазон — это не только от А до Я)
[А-ГО-Р] — буквы от «А» до «Г» и от «О» до «Р»
Обратите внимание — если мы перечисляем возможные варианты, мы не ставим между ними разделителей! Ни пробел, ни запятую — ничего.
[абв] — только «а», «б» или «в»
[а б в] — «а», «б», «в», или пробел (что может привести к нежелательному результату)
[а, б, в] — «а», «б», «в», пробел или запятая
Единственный допустимый разделитель — это дефис. Если система видит дефис внутри квадратных скобок — значит, это диапазон:
-
Символ до дефиса — начало диапазона
-
Символ после — конец
Один символ! Не два или десять, а один! Учтите это, если захотите написать что-то типа [1-31]. Нет, это не диапазон от 1 до 31, эта запись читается так:
-
Диапазон от 1 до 3
-
И число 1
Здесь отсутствие разделителей играет злую шутку с нашим сознанием. Ведь кажется, что мы написали диапазон от 1 до 31! Но нет. Поэтому, если вы пишете регулярные выражения, очень важно их тестировать. Не зря же мы тестировщики! Проверьте то, что написали! Особенно, если с помощью регулярного выражения вы пытаетесь что-то удалить =)) Как бы не удалили лишнее...
Указание диапазона вместо точки помогает отсеять заведомо плохие данные:
Regex: А.я или А[а-я]я
Результат для обоих:
Аня
Ася
Аля
Результат для «А.я»:
А6я
А&я
А я
^ внутри [] означает исключение:
[^0-9] — любой символ, кроме цифр
[^ёЁ] — любой символ, кроме буквы «ё»
[^а-в8] — любой символ, кроме букв «а», «б», «в» и цифры 8
Например, мы хотим найти все txt файлы, кроме разбитых на кусочки — заканчивающихся на цифру:
Regex: [^0-9]\.txt
Результат:
file.txt
log.txt
file_1.txt
1.txt
Так как квадратные скобки являются спецсимволами, то их нельзя найти в тексте без экранирования:
Regex: fruits[0]
Найдет: fruits0
Не найдет: fruits[0]
Это регулярное выражение говорит «найди мне текст «fruits», а потом число 0». Квадратные скобки не экранированы — значит, внутри будет набор допустимых символов.
Если мы хотим найти именно 0-левой элемент массива фруктов, надо записать так:
Regex: fruits\[0\]
Найдет: fruits[0]
Не найдет: fruits0
А если мы хотим найти все элементы массива фруктов, мы внутри экранированных квадратных скобок ставим неэкранированные!
Regex: fruits\[[0-9]\]
Найдет:
fruits[0] = “апельсин”;
fruits[1] = “яблоко”;
fruits[2] = “лимон”;
Не найдет:
cat[0] = “чеширский кот”;
Конечно, «читать» такое регулярное выражение становится немного тяжело, столько разных символов написано...
Без паники! Если вы видите сложное регулярное выражение, то просто разберите его по частям. Помните про основу эффективного тайм-менеджмента? Слона надо есть по частям.
Допустим, после отпуска накопилась гора писем. Смотришь на нее и сразу впадаешь в уныние:
— Ууууууу, я это за день не закончу!
Проблема в том, что груз задачи мешает работать. Мы ведь понимаем, что это надолго. А большую задачу делать не хочется... Поэтому мы ее откладываем, беремся за задачи поменьше. В итоге да, день прошел, а мы не успели закончить.
А если не тратить время на размышления «сколько времени это у меня займет», а сосредоточиться на конкретной задаче (в данном случае — первом письме из стопки, потом втором...), то не успеете оглянуться, как уже всё разгребли!
Разберем по частям регулярное выражение — fruits\[[0-9]\]
Сначала идет просто текст — «fruits».
Потом обратный слеш. Ага, он что-то экранирует.
Что именно? Квадратную скобку. Значит, это просто квадратная скобка в моем тексте — «fruits[»
Дальше снова квадратная скобка. Она не экранирована — значит, это набор допустимых значений. Ищем закрывающую квадратную скобку.
Нашли. Наш набор: [0-9]. То есть любое число. Но одно. Там не может быть 10, 11 или 325, потому что квадратные скобки без квантификатора (о них мы поговорим чуть позже) заменяют ровно один символ.
Пока получается: fruits[«любое однозназначное число»
Дальше снова обратный слеш. То есть следующий за ним спецсимвол будет просто символом в моем тексте.
А следующий символ — ]
Получается выражение: fruits[«любое однозназначное число»]
Наше выражение найдет значения массива фруктов! Не только нулевое, но и первое, и пятое... Вплоть до девятого:
Regex: fruits\[[0-9]\]
Найдет:
fruits[0] = “апельсин”;
fruits[1] = “яблоко”;
fruits[9] = “лимон”;
Не найдет:
fruits[10] = “банан”;
fruits[325] = “ абрикос ”;
Как найти вообще все значения массива, см дальше, в разделе «квантификаторы».
А пока давайте посмотрим, как с помощью диапазонов можно найти все даты.
Какой у даты шаблон? Мы рассмотрим ДД.ММ.ГГГГ:
-
2 цифры дня
-
точка
-
2 цифры месяца
-
точка
-
4 цифры года
Запишем в виде регулярного выражения: [0-9][0-9]\.[0-9][0-9]\.[0-9][0-9][0-9][0-9].
Напомню, что мы не можем записать диапазон [1-31]. Потому что это будет значить не «диапазон от 1 до 31», а «диапазон от 1 до 3, плюс число 1». Поэтому пишем шаблон для каждой цифры отдельно.
В принципе, такое выражение найдет нам даты среди другого текста. Но что, если с помощью регулярки мы проверяем введенную пользователем дату? Подойдет ли такой regexp?
Давайте его протестируем! Как насчет 8888 года или 99 месяца, а?
Regex: [0-9][0-9]\.[0-9][0-9]\.[0-9][0-9][0-9][0-9]
Найдет:
01.01.1999
05.08.2015
Тоже найдет:
08.08.8888
99.99.2000
Попробуем ограничить:
-
День месяца может быть максимум 31 — первая цифра [0-3]
-
Максимальный месяц 12 — первая цифра [01]
-
Год или 19.., или 20.. — первая цифра [12], а вторая [09]
Вот, уже лучше, явно плохие данные регулярка отсекла. Надо признать, она отсечет довольно много тестовых данных, ведь обычно, когда хотят именно сломать, то фигачат именно «9999» год или «99» месяц...
Однако если мы присмотримся внимательнее к регулярному выражению, то сможем найти в нем дыры:
Regex: [0-3][0-9]\.[0-1][0-9]\.[12][09][0-9][0-9]
Не найдет:
08.08.8888
99.99.2000
Но найдет:
33.01.2000
01.19.1999
05.06.2999
Мы не можем с помощью одного диапазона указать допустимые значения. Или мы потеряем 31 число, или пропустим 39. И если мы хотим сделать проверку даты, одних диапазонов будет мало. Нужна возможность перечислить варианты, о которой мы сейчас и поговорим.
Перечисление вариантов
Квадратные скобки [] помогают перечислить варианты для одного символа. Если же мы хотим перечислить слова, то лучше использовать вертикальную черту — |.
Regex: Оля|Олечка|Котик
Найдет:
Оля
Олечка
Котик
Не найдет:
Оленька
Котенка
Можно использовать вертикальную черту и для одного символа. Можно даже внутри слова — тогда вариативную букву берем в круглые скобки
Regex: А(н|л)я
Найдет:
Аня
Аля
Круглые скобки обозначают группу символов. В этой группе у нас или буква «н», или буква «л». Зачем нужны скобки? Показать, где начинается и заканчивается группа. Иначе вертикальная черта применится ко всем символам — мы будем искать или «Ан», или «ля»:
Regex: Ан|ля
Найдет:
Аня
Аля
Оля
Малюля
А если мы хотим именно «Аня» или «Аля», то перечисление используем только для второго символа. Для этого берем его в скобки.
Эти 2 варианта вернут одно и то же:
-
А(н|л)я
-
А[нл]я
Но для замены одной буквы лучше использовать [], так как сравнение с символьным классом выполняется проще, чем обработка группы с проверкой на все её возможные модификаторы.
Давайте вернемся к задаче «проверить введенную пользователем дату с помощью регулярных выражений». Мы пробовали записать для дня диапазон [0-3][0-9], но он пропускает значения 33, 35, 39... Это нехорошо!
Тогда распишем ТЗ подробнее. Та-а-а-ак... Если первая цифра:
-
0 — вторая может от 1 до 9 (даты 00 быть не может)
-
1, 2 — вторая может от 0 до 9
-
3 — вторая только 0 или 1
Составим регулярные выражения на каждый пункт:
-
0[1-9]
-
[12][0-9]
-
3[01]
А теперь осталось их соединить в одно выражение! Получаем: 0[1-9]|[12][0-9]|3[01]
По аналогии разбираем месяц и год. Но это остается вам для домашнего задания =)
Потом, когда распишем регулярки отдельно для дня, месяца и года, собираем все вместе:
(<день>)\.(<месяц>)\.(<год>)
Обратите внимание — каждую часть регулярного выражения мы берем в скобки. Зачем? Чтобы показать системе, где заканчивается выбор. Вот смотрите, допустим, что для месяца и года у нас осталось выражение:
[0-1][0-9]\.[12][09][0-9][0-9]
Подставим то, что написали для дня:
0[1-9]|[12][0-9]|3[01]\.[0-1][0-9]\.[12][09][0-9][0-9]
Как читается это выражение?
-
ИЛИ 0[1-9]
-
ИЛИ [12][0-9]
-
ИЛИ 3[01]\.[0-1][0-9]\.[12][09][0-9][0-9]
Видите проблему? Число «19» будет считаться корректной датой. Система не знает, что перебор вариантов | закончился на точке после дня. Чтобы она это поняла, нужно взять перебор в скобки. Как в математике, разделяем слагаемые.
Так что запомните — если перебор идет в середине слова, его надо взять в круглые скобки!
Regex: А(нн|лл|лин|нтонин)а
Найдет:
Анна
Алла
Алина
Антонина
Без скобок:
Regex: Анн|лл|лин|нтонина
Найдет:
Анна
Алла
Аннушка
Кукулинка
Итого, если мы хотим указать допустимые значения:
-
Одного символа — используем []
-
Нескольких символов или целого слова — используем |
Метасимволы
Если мы хотим найти число, то пишем диапазон [0-9].
Если букву, то [а-яА-ЯёЁa-zA-Z].
А есть ли другой способ?
Есть! В регулярных выражениях используются специальные метасимволы, которые заменяют собой конкретный диапазон значений:
|
Символ |
Эквивалент |
Пояснение |
|
\d |
[0-9] |
Цифровой символ |
|
\D |
[^0-9] |
Нецифровой символ |
|
\s |
[ \f\n\r\t\v] |
Пробельный символ |
|
\S |
[^ \f\n\r\t\v] |
Непробельный символ |
|
\w |
[[:word:]] |
Буквенный или цифровой символ или знак подчёркивания |
|
\W |
[^[:word:]] |
Любой символ, кроме буквенного или цифрового символа или знака подчёркивания |
|
. |
|
Вообще любой символ |
Это самые распространенные символы, которые вы будете использовать чаще всего. Но давайте разберемся с колонкой «эквивалент». Для \d все понятно — это просто некие числа. А что такое «пробельные символы»? В них входят:
|
Символ |
Пояснение |
|
|
Пробел |
|
\r |
Возврат каретки (Carriage return, CR) |
|
\n |
Перевод строки (Line feed, LF) |
|
\t |
Табуляция (Tab) |
|
\v |
Вертикальная табуляция (vertical tab) |
|
\f |
Конец страницы (Form feed) |
|
[\b] |
Возврат на 1 символ (Backspace) |
Из них вы чаще всего будете использовать сам пробел и перевод строки — выражение «\r\n». Напишем текст в несколько строк:
Первая строка
Вторая строка
Для регулярного выражения это:
Первая строка\r\nВторая строка
А вот что такое backspace в тексте? Как его можно увидеть вообще? Это же если написать символ и стереть его. В итоге символа нет! Неужели стирание хранится где-то в памяти? Но тогда это было бы ужасно, мы бы вообще ничего не смогли найти — откуда нам знать, сколько раз текст исправляли и в каких местах там теперь есть невидимый символ [\b]?
Выдыхаем — этот символ не найдет все места исправления текста. Просто символ backspace — это ASCII символ, который может появляться в тексте (ASCII code 8, или 10 в octal). Вы можете «создать» его, написать в консоли браузера (там используется JavaScript):
console.log("abc\b\bdef");
Результат команды:
adef
Мы написали «abc», а потом стерли «b» и «с». В итоге пользователь в консоли их не видит, но они есть. Потому что мы прямо в коде прописали символ удаления текста. Не просто удалили текст, а прописали этот символ. Вот такой символ регулярное выражение [\b] и найдет.
См также:
What's the use of the [\b] backspace regex? — подробнее об этом символе
Но обычно, когда мы вводим \s, мы имеем в виду пробел, табуляцию, или перенос строки.
Ок, с этими эквивалентами разобрались. А что значит [[:word:]]? Это один из способов заменить диапазон. Чтобы запомнить проще было, написали значения на английском, объединив символы в классы. Какие есть классы:
|
Класс символов |
Пояснение |
|
[[:alnum:]] |
Буквы или цифры: [а-яА-ЯёЁa-zA-Z0-9] |
|
[[:alpha:]] |
Только буквы: [а-яА-ЯёЁa-zA-Z] |
|
[[:digit:]] |
Только цифры: [0-9] |
|
[[:graph:]] |
Только отображаемые символы (пробелы, служебные знаки и т. д. не учитываются) |
|
[[:print:]] |
Отображаемые символы и пробелы |
|
[[:space:]] |
Пробельные символы [ \f\n\r\t\v] |
|
[[:punct:]] |
Знаки пунктуации: ! " # $ % & ' ( ) * + , \ -. / : ; < = > ? @ [ ] ^ _ ` { | } |
|
[[:word:]] |
Буквенный или цифровой символ или знак подчёркивания: [а-яА-ЯёЁa-zA-Z0-9_] |
Теперь мы можем переписать регулярку для проверки даты, которая выберет лишь даты формата ДД.ММ.ГГГГГ, отсеяв при этом все остальное:
[0-9][0-9]\.[0-9][0-9]\.[0-9][0-9][0-9][0-9]
↓
\d\d\.\d\d.\d\d\d\d
Согласитесь, через метасимволы запись посимпатичнее будет =))
Спецсимволы
Большинство символов в регулярном выражении представляют сами себя за исключением специальных символов:
[ ] \ / ^ $ . | ? * + ( ) { }
Эти символы нужны, чтобы обозначить диапазон допустимых значений или границу фразы, указать количество повторений, или сделать что-то еще. В разных типах регулярных выражений этот набор различается (см «разновидности регулярных выражений»).
Если вы хотите найти один из этих символов внутри вашего текста, его надо экранировать символом \ (обратная косая черта).
Regex: 2\^2 = 4
Найдет: 2^2 = 4
Можно экранировать целую последовательность символов, заключив её между \Q и \E (но не во всех разновидностях).
Regex: \Q{кто тут?}\E
Найдет: {кто тут?}
Квантификаторы (количество повторений)
Усложняем задачу. Есть некий текст, нам нужно вычленить оттуда все email-адреса. Например:
-
test@mail.ru
-
olga31@gmail.com
Как составляется регулярное выражение? Нужно внимательно изучить данные, которые мы хотим получить на выходе, и составить по ним шаблон. В email два разделителя — собачка «@» и точка «.».
Запишем ТЗ для регулярного выражения:
-
Буквы / цифры / _
-
Потом @
-
Снова буквы / цифры / _
-
Точка
-
Буквы
Так, до собачки у нас явно идет метасимвол «\w», туда попадет и просто текст (test), и цифры (olga31), и подчеркивание (pupsik_99). Но есть проблема — мы не знаем, сколько таких символов будет. Это при поиске даты все ясно — 2 цифры, 2 цифры, 4 цифры. А тут может быть как 2, так и 22 символа.
И тут на помощь приходят квантификаторы — так называют специальные символы в регулярных выражениях, которые указывают количество повторений текста.
Символ «+» означает «одно или более повторений», это как раз то, что нам надо! Получаем: \w+@
После собачки и снова идет \w, и снова от одного повторения. Получаем: \w+@\w+\.
После точки обычно идут именно символы, но для простоты можно снова написано \w. И снова несколько символов ждем, не зная точно сколько. Итого получилось выражение, которое найдет нам email любой длины:
Regex: \w+@\w+\.\w+
Найдет:
test@mail.ru
olga31@gmail.com
pupsik_99_and_slonik_33_and_mikky_87_and_kotik_28@yandex.megatron
Какие есть квантификаторы, кроме знака «+»?
|
Квантификатор |
Число повторений |
|
? |
Ноль или одно |
|
* |
Ноль или более |
|
+ |
Один или более |
Символ * часто используют с точкой — когда нам неважно, какой идет текст до интересующей нас фразы, мы заменяем его на «.*» — любой символ ноль или более раз.
Regex: .*\d\d\.\d\d\.\d\d\d\d.*
Найдет:
01.01.2000
Приходи на ДР 09.08.2015! Будет весело!
Но будьте осторожны! Если использовать «.*» повсеместно, можно получить много ложноположительных срабатываний:
Regex: .*@.*\..*
Найдет:
test@mail.ru
olga31@gmail.com
pupsik_99@yandex.ru
Но также найдет:
@yandex.ru
test@.ru
test@mail.
Уж лучше \w, и плюсик вместо звездочки.
А вот есть мы хотим найти все лог-файлы, которые нумеруются — log, log1, log2… log133, то * подойдет хорошо:
Regex: log\d*\.txt
Найдет:
log.txt
log1.txt
log2.txt
log3.txt
log33.txt
log133.txt
А знак вопроса (ноль или одно повторение) поможет нам найти людей с конкретной фамилией — причем всех, и мужчин, и женщин:
Regex: Назина?
Найдет:
Назин
Назина
Если мы хотим применить квантификатор к группе символов или нескольким словам, их нужно взять в скобки:
Regex: (Хихи)*(Хаха)*
Найдет:
ХихиХаха
ХихиХихиХихи
Хихи
Хаха
ХихиХихиХахаХахаХаха
(пустота — да, её такая регулярка тоже найдет)
Квантификаторы применяются к символу или группе в скобках, которые стоят перед ним.
А что, если мне нужно определенное количество повторений? Скажем, я хочу записать регулярное выражение для даты. Пока мы знаем только вариант «перечислить нужный метасимвол нужное количество раз» — \d\d\.\d\d\.\d\d\d\d.
Ну ладно 2-4 раза повторение идет, а если 10? А если повторить надо фразу? Так и писать ее 10 раз? Не слишком удобно. А использовать * нельзя:
Regex: \d*\.\d*\.\d*
Найдет:
.0.1999
05.08.20155555555555555
03444.025555.200077777777777777
Чтобы указать конкретное количество повторений, их надо записать внутри фигурных скобок:
|
Квантификатор |
Число повторений |
|
{n} |
Ровно n раз |
|
{m,n} |
От m до n включительно |
|
{m,} |
Не менее m |
|
{,n} |
Не более n |
Таким образом, для проверки даты можно использовать как перечисление \d n раз, так и использование квантификатора:
\d\d\.\d\d\.\d\d\d\d
\d{2}\.\d{2}.\d{4}
Обе записи будут валидны. Но вторая читается чуть проще — не надо самому считать повторения, просто смотрим на цифру.
Не забывайте — квантификатор применяется к последнему символу!
Regex: data{2}
Найдет: dataa
Не найдет: datadata
Или группе символов, если они взяты в круглые скобки:
Regex: (data){2}
Найдет: datadata
Не найдет: dataa
Так как фигурные скобки используются в качестве указания количества повторений, то, если вы ищете именно фигурную скобку в тексте, ее надо экранировать:
Regex: x\{3\}
Найдет: x{3}
Иногда квантификатор находит не совсем то, что нам нужно.
Regex: <.*>
Ожидание:
<req>
<query>Ан</query>
<gender>FEMALE</gender>
Реальность:
<req> <query>Ан</query> <gender>FEMALE</gender></req>
Мы хотим найти все теги HTML или XML по отдельности, а регулярное выражение возвращает целую строку, внутри которой есть несколько тегов.
Напомню, что в разных реализациях регулярные выражения могут работать немного по разному. Это одно из отличий — в некоторых реализациях квантификаторам соответствует максимально длинная строка из возможных. Такие квантификаторы называют жадными.
Если мы понимаем, что нашли не то, что хотели, можно пойти двумя путями:
-
Учитывать символы, не соответствующие желаемому образцу
-
Определить квантификатор как нежадный (ленивый, англ. lazy) — большинство реализаций позволяют это сделать, добавив после него знак вопроса.
Как учитывать символы? Для примера с тегами можно написать такое регулярное выражение:
<[^>]*>
Оно ищет открывающий тег, внутри которого все, что угодно, кроме закрывающегося тега «>», и только потом тег закрывается. Так мы не даем захватить лишнее. Но учтите, использование ленивых квантификаторов может повлечь за собой обратную проблему — когда выражению соответствует слишком короткая, в частности, пустая строка.
|
Жадный |
Ленивый |
|
* |
*? |
|
+ |
+? |
|
{n,} |
{n,}? |
Есть еще и сверхжадная квантификация, также именуемая ревнивой. Но о ней почитайте в википедии =)
Позиция внутри строки
По умолчанию регулярные выражения ищут «по включению».
Regex: арка
Найдет:
арка
чарка
аркан
баварка
знахарка
Это не всегда то, что нам нужно. Иногда мы хотим найти конкретное слово.
Если мы ищем не одно слово, а некую строку, проблема решается в помощью пробелов:
Regex: Товар №\d+ добавлен в корзину в \d\d:\d\d
Найдет: Товар №555 добавлен в корзину в 15:30
Не найдет: Товарный чек №555 добавлен в корзину в 15:30
Или так:
Regex: .* арка .*
Найдет: Триумфальная арка была...
Не найдет: Знахарка сегодня...
А что, если у нас не пробел рядом с искомым словом? Это может быть знак препинания: «И вот перед нами арка.», или «...арка:».
Если мы ищем конкретное слово, то можно использовать метасимвол \b, обозначающий границу слова. Если поставить метасимвол с обоих концов слова, мы найдем именно это слово:
Regex: \bарка\b
Найдет:
арка
Не найдет:
чарка
аркан
баварка
знахарка
Можно ограничить только спереди — «найди все слова, которые начинаются на такое-то значение»:
Regex: \bарка
Найдет:
арка
аркан
Не найдет:
чарка
баварка
знахарка
Можно ограничить только сзади — «найди все слова, которые заканчиваются на такое-то значение»:
Regex: арка\b
Найдет:
арка
чарка
баварка
знахарка
Не найдет:
аркан
Если использовать метасимвол \B, он найдем нам НЕ-границу слова:
Regex: \Bакр\B
Найдет:
закройка
Не найдет:
акр
акрил
Если мы хотим найти конкретную фразу, а не слово, то используем следующие спецсимволы:
^ — начало текста (строки)
$ — конец текста (строки)
Если использовать их, мы будем уверены, что в наш текст не закралось ничего лишнего:
Regex: ^Я нашел!$
Найдет:
Я нашел!
Не найдет:
Смотри! Я нашел!
Я нашел! Посмотри!
Итого метасимволы, обозначающие позицию строки:
|
Символ |
Значение |
|
\b |
граница слова |
|
\B |
Не граница слова |
|
^ |
начало текста (строки) |
|
$ |
конец текста (строки) |
Использование ссылки назад
Допустим, при тестировании приложения вы обнаружили забавный баг в тексте — дублирование предлога «на»: «Поздравляем! Вы прошли на на новый уровень». А потом решили проверить, есть ли в коде еще такие ошибки.
Разработчик предоставил файлик со всеми текстами. Как найти повторы? С помощью ссылки назад. Когда мы берем что-то в круглые скобки внутри регулярного выражения, мы создаем группу. Каждой группе присваивается номер, по которому к ней можно обратиться.
Regex: [ ]+(\w+)[ ]+\1
Текст: Поздравляем! Вы прошли на на новый уровень. Так что что улыбаемся и и машем.
Разберемся, что означает это регулярное выражение:
[ ]+ → один или несколько пробелов, так мы ограничиваем слово. В принципе, тут можно заменить на метасимвол \b.
(\w+) → любой буквенный или цифровой символ, или знак подчеркивания. Квантификатор «+» означает, что символ должен идти минимум один раз. А то, что мы взяли все это выражение в круглые скобки, говорит о том, что это группа. Зачем она нужна, мы пока не знаем, ведь рядом с ней нет квантификатора. Значит, не для повторения. Но в любом случае, найденный символ или слово — это группа 1.
[ ]+ → снова один или несколько пробелов.
\1 → повторение группы 1. Это и есть ссылка назад. Так она записывается в JavaScript-е.
Важно: синтаксис ссылок назад очень зависит от реализации регулярных выражений.
|
ЯП |
Как обозначается ссылка назад |
|
JavaScript vi |
\ |
|
Perl |
$ |
|
PHP |
$matches[1] |
|
Java Python |
group[1] |
|
C# |
match.Groups[1] |
|
Visual Basic .NET |
match.Groups(1) |
Для чего еще нужна ссылка назад? Например, можно проверить верстку HTML, правильно ли ее составили? Верно ли, что открывающийся тег равен закрывающемуся?
Напишите выражение, которое найдет правильно написанные теги:
<h2>Заголовок 2-ого уровня</h2>
<h3>Заголовок 3-ого уровня</h3>
Но не найдет ошибки:
<h2>Заголовок 2-ого уровня</h3>
Просмотр вперед и назад
Еще может возникнуть необходимость найти какое-то место в тексте, но не включая найденное слово в выборку. Для этого мы «просматриваем» окружающий текст.
|
Представление |
Вид просмотра |
Пример |
Соответствие |
|
(?=шаблон) |
Позитивный просмотр вперёд |
Блюдо(?=11) |
Блюдо11 Блюдо113
|
|
(?!шаблон) |
Негативный просмотр вперёд (с отрицанием) |
Блюдо(?!11) |
Блюдо1
Блюдо511 |
|
(?<=шаблон) |
Позитивный просмотр назад |
(?<=Ольга )Назина |
Ольга Назина
|
|
(?шаблон) |
Негативный просмотр назад (с отрицанием) |
(см ниже на рисунке) |
Анна Назина |
Замена
Важная функция регулярных выражений — не только найти текст, но и заменить его на другой текст! Простейший вариант замены — слово на слово:
RegEx: Ольга
Замена: Макар
Текст был: Привет, Ольга!
Текст стал: Привет, Макар!
Но что, если у нас в исходном тексте может быть любое имя? Вот что пользователь ввел, то и сохранилось. А нам надо на Макара теперь заменить. Как сделать такую замену? Через знак доллара. Давайте разберемся с ним подробнее.
Знак доллара в замене — обращение к группе в поиске. Ставим знак доллара и номер группы. Группа — это то, что мы взяли в круглые скобки. Нумерация у групп начинается с 1.
RegEx: (Оля) \+ Маша
Замена: $1
Текст был: Оля + Маша
Текст стал: Оля
Мы искали фразу «Оля + Маша» (круглые скобки не экранированы, значит, в искомом тексте их быть не должно, это просто группа). А замнили ее на первую группу — то, что написано в первых круглых скобках, то есть текст «Оля».
Это работает и когда искомый текст находится внутри другого:
RegEx: (Оля) \+ Маша
Замена: $1
Текст был: Привет, Оля + Маша!
Текст стал: Привет, Оля!
Можно каждую часть текста взять в круглые скобки, а потом варьировать и менять местами:
RegEx: (Оля) \+ (Маша)
Замена: $2 - $1
Текст был: Оля + Маша
Текст стал: Маша — Оля
Теперь вернемся к нашей задаче — есть строка приветствия «Привет, кто-то там!», где может быть написано любое имя (даже просто числа вместо имени). Мы это имя хотим заменить на «Макар».
Нам надо оставить текст вокруг имени, поэтому берем его в скобки в регулярном выражении, составляя группы. И переиспользуем в замене:
RegEx: ^(Привет, ).*(!)$
Замена: $1Макар$2
Текст был (или или):
Привет, Ольга!
Привет, 777!
Текст стал:
Привет, Макар!
Давайте разберемся, как работает это регулярное выражение.
^ — начало строки.
Дальше скобка. Она не экранирована — значит, это группа. Группа 1. Поищем для нее закрывающую скобку и посмотрим, что входит в эту группу. Внутри группы текст «Привет, »
После группы идет выражение «.*» — ноль или больше повторений чего угодно. То есть вообще любой текст. Или пустота, она в регулярку тоже входит.
Потом снова открывающаяся скобка. Она не экранирована — ага, значит, это вторая группа. Что внутри? Внутри простой текст — «!».
И потом символ $ — конец строки.
Посмотрим, что у нас в замене.
$1 — значение группы 1. То есть текст «Привет, ».
Макар — просто текст. Обратите внимание, что мы или включает пробел после запятой в группу 1, или ставим его в замене после «$1», иначе на выходе получим «Привет,Макар».
$2 — значение группы 2, то есть текст «!»
Вот и всё!
А что, если нам надо переформатировать даты? Есть даты в формате ДД.ММ.ГГГГ, а нам нужно поменять формат на ГГГГ-ММ-ДД.
Регулярное выражение для поиска у нас уже есть — «\d{2}\.\d{2}\.\d{4}». Осталось понять, как написать замену. Посмотрим внимательно на ТЗ:
ДД.ММ.ГГГГ
↓
ГГГГ-ММ-ДД
По нему сразу понятно, что нам надо выделить три группы. Получается так: (\d{2})\.(\d{2})\.(\d{4})
В результате у нас сначала идет год — это третья группа. Пишем: $3
Потом идет дефис, это просто текст: $3-
Потом идет месяц. Это вторая группа, то есть «$2». Получается: $3-$2
Потом снова дефис, просто текст: $3-$2-
И, наконец, день. Это первая группа, $1. Получается: $3-$2-$1
Вот и всё!
RegEx: (\d{2})\.(\d{2})\.(\d{4})
Замена: $3-$2-$1
Текст был:
05.08.2015
01.01.1999
03.02.2000
Текст стал:
2015-08-05
1999-01-01
2000-02-03
Другой пример — я записываю в блокнот то, что успела сделать за цикл в 12 недель. Называется файлик «done», он очень мотивирует! Если просто вспоминать «что же я сделал?», вспоминается мало. А тут записал и любуешься списком.
Вот пример улучшалок по моему курсу для тестировщиков:
-
Сделала сообщения для бота — чтобы при выкладке новых тем писал их в чат
-
Фолкс — поправила статью «Расширенный поиск», убрала оттуда про пустой ввод при простом поиске, а то путал
-
Обновила кусочек про эффект золушки (переписывала под ютуб)
И таких набирается штук 10-25. За один цикл. А за год сколько? Ух! Вроде небольшие улучшения, а набирается прилично.
Так вот, когда цикл заканчивается, я пишу в блог о своих успехах. Чтобы вставить список в блог, мне надо удалить нумерацию — тогда я сделаю ее силами блоггера и это будет смотреться симпатичнее.
Удаляю с помощью регулярного выражения:
RegEx: \d+\. (.*)
Замена: $1
Текст был:
1. Раз
2. Два
Текст стал:
Раз
Два
Можно было бы и вручную. Но для списка больше 5 элементов это дико скучно и уныло. А так нажал одну кнопочку в блокноте — и готово!
Так что регулярные выражения могут помочь даже при написании статьи =)
Статьи и книги по теме
Книги
Регулярные выражения 10 минут на урок. Бен Форта — Очень рекомендую! Прям шикарная книга, где все просто, доступно, понятно. Стоит 100 рублей, а пользы море.
Статьи
Вики — https://ru.wikipedia.org/wiki/Регулярные_выражения. Да, именно ее вы будете читать чаще всего. Я сама не помню наизусть все метасимволы. Поэтому, когда использую регулярки, гуглю их, википедия всегда в топе результатов. А сама статья хорошая, с табличками удобными.
Регулярные выражения для новичков — https://tproger.ru/articles/regexp-for-beginners/
Итого
Регулярные выражения — очень полезная вещь для тестировщика. Применений у них много, даже если вы не автоматизатор и не спешите им стать:
-
Найти все нужные файлы в папке.
-
Grep-нуть логи — отсечь все лишнее и найти только ту информацию, которая вам сейчас интересна.
-
Проверить по базе, нет ли явно некорректных записей — не остались ли тестовые данные в продакшене? Не присылает ли смежная система какую-то фигню вместо нормальных данных?
-
Проверить данные чужой системы, если она выгружает их в файл.
-
Выверить файлик текстов для сайта — нет ли там дублирования слов?
-
Подправить текст для статьи.
-
...
Если вы знаете, что в коде вашей программы есть регулярное выражение, вы можете его протестировать. Вы также можете использовать регулярки внутри ваших автотестов. Хотя тут стоит быть осторожным.
Не забывайте о шутке: «У разработчика была одна проблема и он стал решать ее с помощью регулярных выражений. Теперь у него две проблемы». Бывает и так, безусловно. Как и с любым другим кодом.
Поэтому, если вы пишете регулярку, обязательно ее протестируйте! Особенно, если вы ее пишете в паре с командой rm (удаление файлов в linux). Сначала проверьте, правильно ли отрабатывает поиск, а потом уже удаляйте то, что нашли.
Регулярное выражение может не найти то, что вы ожидали. Или найти что-то лишнее. Особенно если у вас идет цепочка регулярок.


сайт https://regexcrossword.com/
https://habr.com/ru/post/545150/
https://regex101.com/r/cO8lqs/25
https://devanych.ru/technologies/shpargalka-po-regulyarnym-vyrazheniyam
http://sajgak.ru/site/php/shpargalka-regularnie-virageniya-pcre/
https://j4web.ru/java-regex/validatsiya-imeni-fajla-kartinki-s-pomoshhyu-regulyarnogo-vyrazheniya.html
https://prog-time.ru/poleznye-regulyarnye-vyrazheniya-gotovye-regulyarnye-vyrazheniya/
https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%83%D0%BB%D1%8F%D1%80%D0%BD%D1%8B%D0%B5_%D0%B2%D1%8B%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D1%8F
https://github.com/cpr1c/RegEx1C_cfe
https://github.com/alexkmbk/RegEx1CAddin
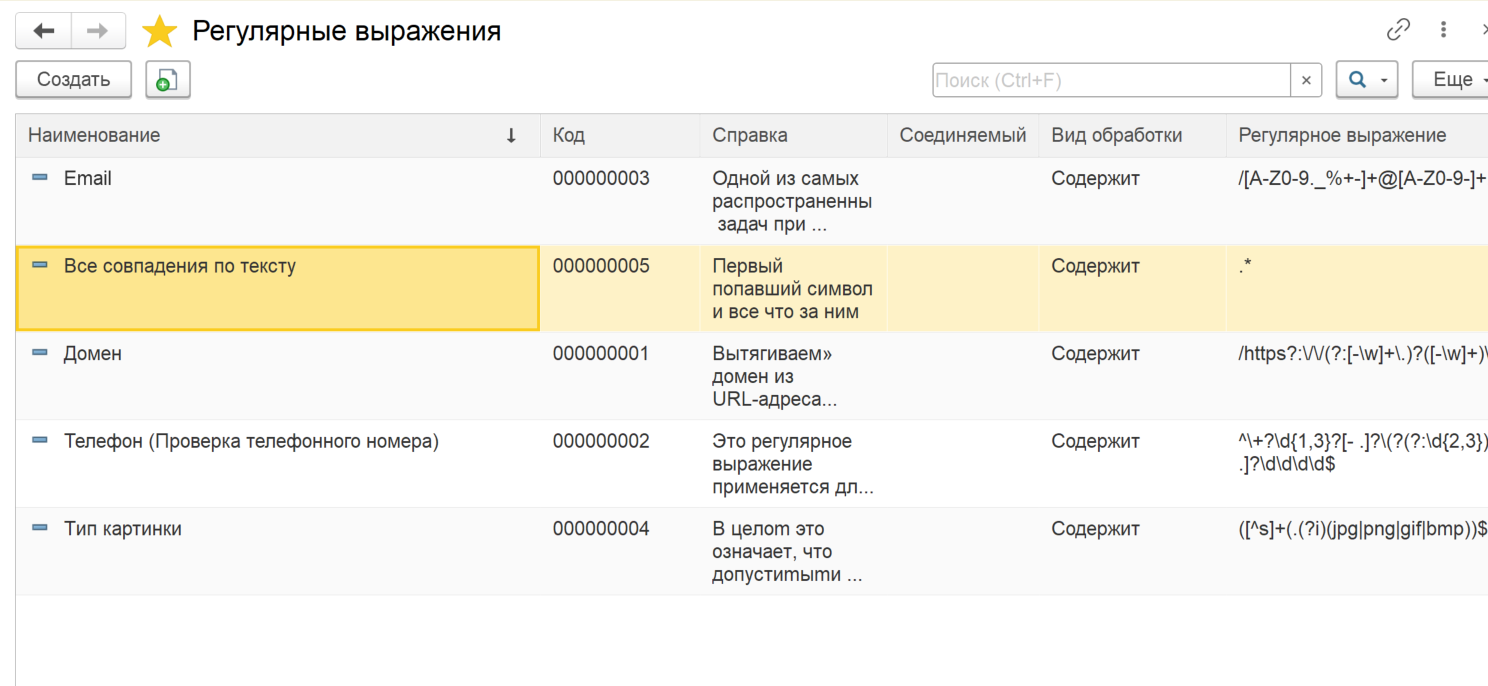
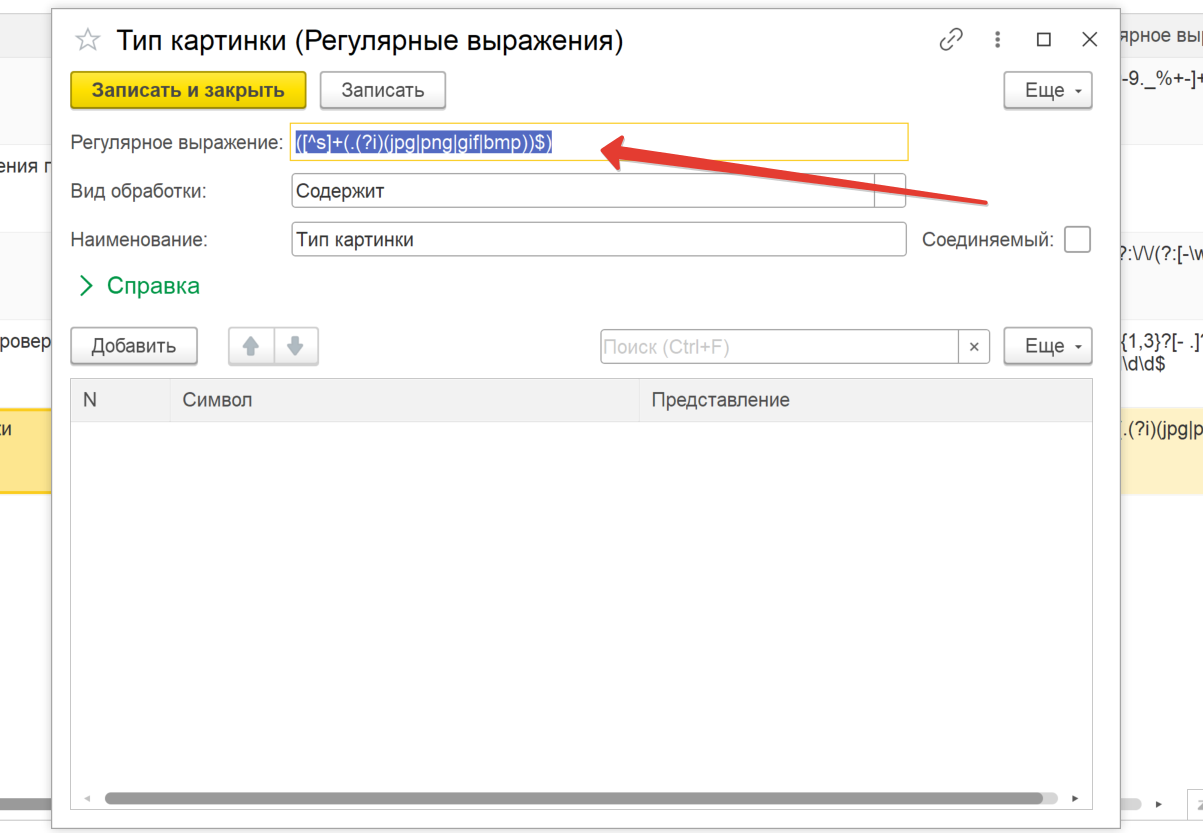
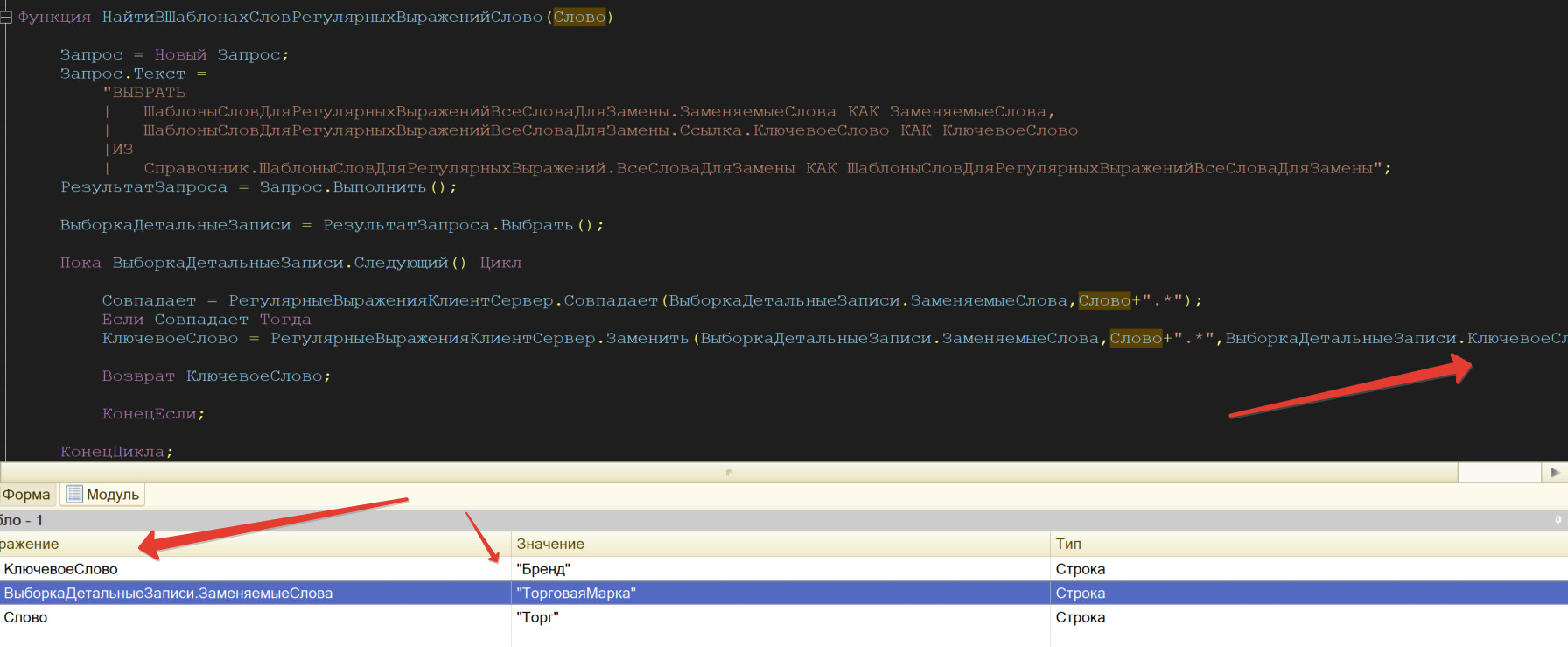
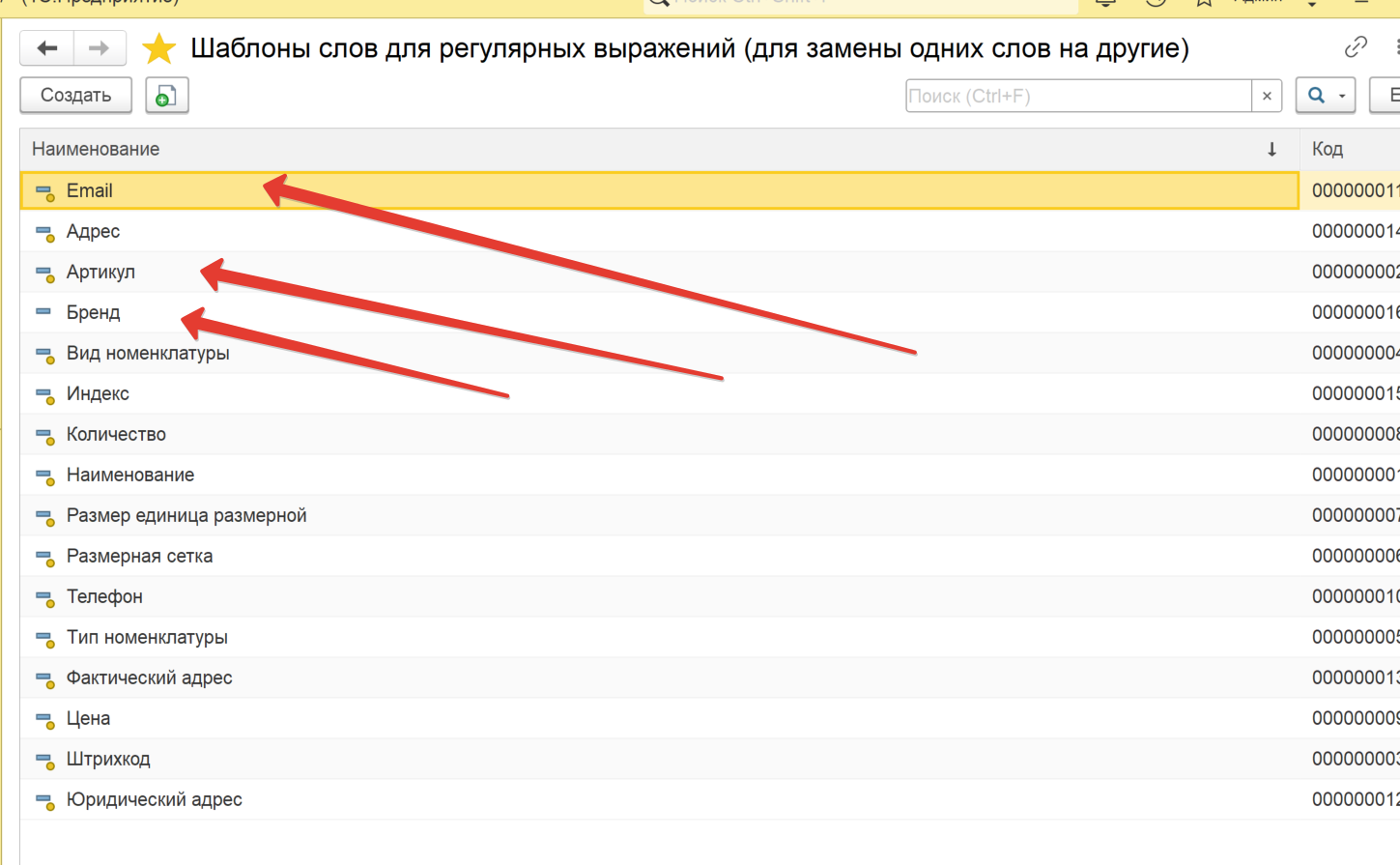
Суть разработки - дополнить существующие решения для использования как бы шаблонизации слов, к примеру, есть какое-то одно слово, его нужно заменить на какие-то другие слова. Список слов неограничен, можно заменять одни на другие по типу по выражению или каким то другим образом, на видео я очень подробно все объясняю, если непонятно, спрашивайте, обязательно пообщаемся!
Тестирование проводилось на 1С:Предприятие 8.3 (8.3.22.1704).
В архиве база с примером и расширение конфигурации, если нужно как-то по другому тестировать и познавать :)