

{kind=link}
Поставили задачу: необходимо организовать инвентаризацию в сети книжных магазинов.
На первый взгляд, ничего сложного - заливаем в терминал сбора данных данные по остаткам (или всю номенклатуру), проводим инвентаризацию, получаем данные, заполняем пересчет товаров. Однако, при тестировании данной схемы выявились недостатки:
- Огромный список номенклатуры, даже с учетом разбиения позиций на группы, в терминал необходимо загружать порядка 20 000 записей. К сожалению, в магазине стандартная обработка работы с ТСД из Розницы формировала список номенклатуры для загрузки больше часа. Список можно было бы уменьшить, загружая в терминал только товары, числящиеся на остатках, но этот вариант оказался неприемлем из-за большого количества пересорта.
- Стандартное заполнение факта пересчета товара данными, полученными с терминала, работало очень медленно. Используется медленный алгоритм - читается строчка с штрихкодом товара, ищется соответствующая строчка в текущем документе "Пересчет товаров", заполняется факт, затем следующая строчка. Не очень быстрый компьютер + 10 000 строчек в документе = 8 часов работы алгоритма.
Для решения первой проблемы было придумано загружать в терминалы заранее сформированную базу данных. Для решения второй написана обработка, заполняющая факт по данным, полученным из терминала.
Итак, что же из себя представляет обработка обмена данными с терминалом CipherLab?
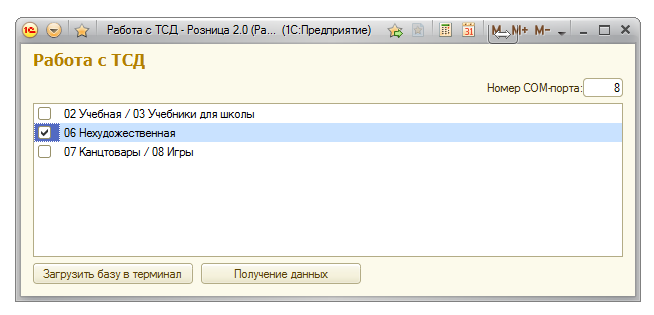
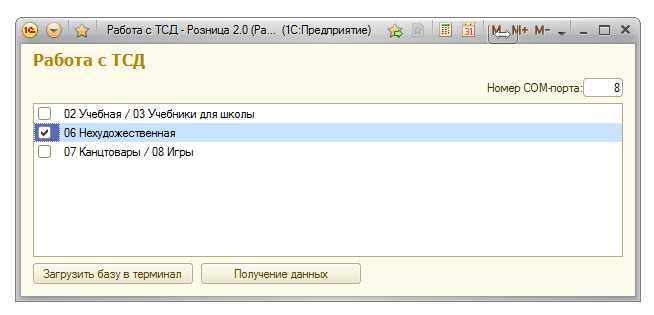
Поле для ввода номера COM-порта, через который идет общение с терминалом, список номенклатурных групп, и две кнопки - "Загрузить базу в терминал" и "Получение данных".
Список номенклатурных групп заполняется автоматически из макетов обработки, которые в свою очередь заранее загружены программистом в виде двоичных данных.
Если добавить макет с именем, первый символ которого "г" (группа) , он будет отображаться в списке групп номенклатуры для загрузки. Имя группы берется из поля "Синоним" макета. Сам макет представляет из себя двоичный файл с данными по этой группе, файл создается заранее программистом и отформатирован в соответствии с требованиями ТСД. Для загрузки или выгрузки данных обработка вызывает утилиты производителя, работающие из командной строки. DataRead.exe считывает данные с ТСД, DLookup.exe загружает базу данных. Эти утилиты также хранятся в самой обработке в макетах.
Для загрузки базы в терминал нужно подключить терминал сбора данных к компьютеру, затем перевести его в режим загрузки базы данных, выбрать нужную номенклатурную группу и нажать на кнопку "Загрузить базу в терминал".
Для получения данных подключаем ТСД к компьютеру, переводим терминал в режим выгрузки данных, выбираем номенклатурную группу, нажимаем на кнопку "Получение данных". На жестком диске компьютера создастся папка "C:\DATA_FROM_TERMINAL", в ней появится текстовый файл с данными инвентаризации, название файла будет соответствовать названию номенклатурной группы. Теперь можно обрабатывать полученный файл другими средствами.
Во всех случаях не забывайте правильно выставлять номер com-порта, через который идет соединение с терминалом!