











Коллеги, приветствую! Наверное, всем хоть раз приходилось обновлять типовую конфигурацию с кучей доработок на новую версию релиза. При сравнении и объединении мы бережно переносим все доработанные вставки в код нового релиза, затем проверяем, чтобы общие модули, которые вызывались в доработках были на месте, нужные функции и процедуры не переименовались и никуда не переместились. Короче, приводим доработки к реалиям нового релиза.
И для большинства подобных задач есть полезные инструменты, позволяющие быстро найти и подсветить проблемные места в коде. Но есть место, куда инструментами не дотянуться. А именно, тексты запросов.
В двух словах проблема выглядит так: жил-был запрос, никого не трогал, работал как часы, как вдруг в новом релизе удалили или переименовали один из реквизитов справочника/документа/регистра, к которому этот запрос обращался. И с этого момента запрос становится «битым». При попытке открыть его в конструкторе запросов – ошибка. При попытке выполнить такой запрос в программе – ошибка.
Подобные рудименты в запросах я называю «призраками прошлого». Мы буквально обращаемся к метаданным, которые когда-то были, но после обновления перестали существовать.
Понятное дело, это безобразие нужно исправлять. Но какие методы обнаружения «битых» запросов сейчас существуют?
- Автоматизированное дымовое и сценарное тестирование
- Проверка всех функциональных цепочек тестировщиками / консультантами / аналитиками
- Обнаружение ошибок конечными пользователями в ходе работы.
Автоматизированное тестирование – это вещь, безусловно, очень крутая и полезная, но далеко не все могут себе позволить разработку тестов, покрывающих весь доработанный функционал.
Проверка релиза тестировщиками / аналитиками / консультантами – безусловно, действенный метод, но занимает много времени, и почти всегда в ходе этих тестирований что-то пропускается и остаётся незамеченным.
А вот конечные пользователи такие ошибки находят махом! Но согласитесь, заливать в продуктив недотестированный релиз с «битыми» запросами в коде – сложно назвать лучшим управленческим решением.
Теперь к делу… Я разработал решение, которое позволяет в автоматическом режиме найти большинство «битых» запросов, которые появились в результате перехода на новый релиз.
Суть решения довольно простая. Мы выгружаем в файлы три конфигурации:
- Наша доработанная конфигурация до обновления
- Конфигурация с типовым релизом, на который осуществляется переход
- Наша обновлённая на новый релиз конфигурация с перенесёнными доработками
Моя обработка сканирует все файлы модулей конфигурации и вытаскивает из них все тексты запросов, которые получается вытащить. Да, получается вытащить далеко не все, часть запросов у нас формируется динамически, из нескольких частей и т.д. Такие мы пропускаем.
Затем программа поочерёдно пытается создать объект запрос с текстом каждого найденного запроса и проверить, открывается ли такой запрос в конструкторе запросов. Если нет, то сохраняет текст ошибки.
Затем программа сканирует полученные ошибки и оставляет только те, в которых «Поле не обнаружено» или «Таблица не обнаружена». Вот они, «битые» запросы!
Но, к сожалению, всё не так просто. Типовые конфигурации, увы, кишат подобными запросами. При попытке открыть их в конструкторе, мы видим ошибку. Но дальше по коду идёт волшебная замена одной подстроки на другую (или другая подобная магия) и на выполнение попадает уже правильный запрос, который отлично работает.
Подобные запросы создают «шум», и среди них сложно найти реальные проблемы, поэтому мы и выполняем подобный поиск сразу в 3 конфигурациях, как я упоминал выше.
Предполагается, что наша конфигурация до обновления – уже многократно протестирована в бою и в ней всё хорошо. Поэтому ошибки, которые находятся в ней обработкой, мы будем считать «шумом».
Предполагается, что ошибки, которые программа находит в новом типовом релизе – это тоже шум. Ведь не могут же 1С-ники наделать ерунды. А даже если нет, к нашему обновлению это не относится.
Таким образом, просканировав две эти конфигурации, мы собираем базу «шума».
Затем приступаем к сканированию нашей обновлённой конфигурации с доработками, при этом указываем два файла с «шумами». Программа исключит идентичные ошибки из этих 2 файлов и оставит только «битые» запросы, которые возникли при переносе доработок в новый типовой релиз. Их будет не много, и их можно будет уже легко отсмотреть и проверить руками.
Условно данный метод можно представить в виде классической схемы пересечения трёх множеств.
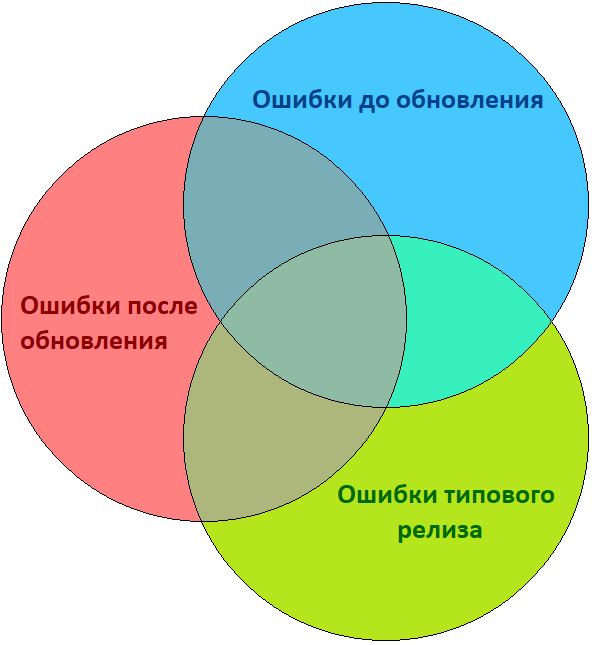
Как только мы удалим из множества «ошибок после обновления» пересекающиеся элементы из множеств «ошибок до обновления» и «ошибок типового релиза», мы получим объективную картину.
Да, данный инструмент не гарантирует нахождение всех проблем в запросах (хотя бы потому, что не может анализировать динамически формируемые запросы в коде), но совершенно точно помогает находить большинство «призраков прошлого» в запросах.
Скорость работы радует. Даже тяжелейшие конфигурации вроде ERPУХ последней версии сканируются примерно за 10 минут. Как минимум, рекомендую всем попробовать данный инструмент, а если понравится – взять на вооружение))
Пошаговая инструкция по применению инструмента «Анализ конфигурации: Поиск ошибок в текстах запросов»
Шаг 1. Нужно подготовить 3 базы. С конфигурацией до обновления, с конфигурацией после обновления и с типовым релизом, на который вы обновились. Заходим в каждую базу в режиме конфигуратора и выгружаем конфигурацию в файлы:
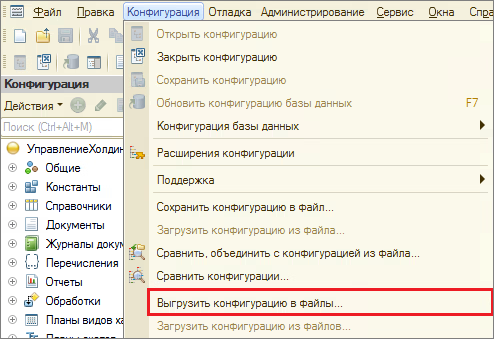
Далее указываем, в какую папку выгружаем конфигурацию. Каждую конфигурацию нужно выгрузить в отдельную папку.

Шаг 2. Запускаем базу с конфигурацией до обновления в режиме «1С Предприятия». Открываем нашу обработку.

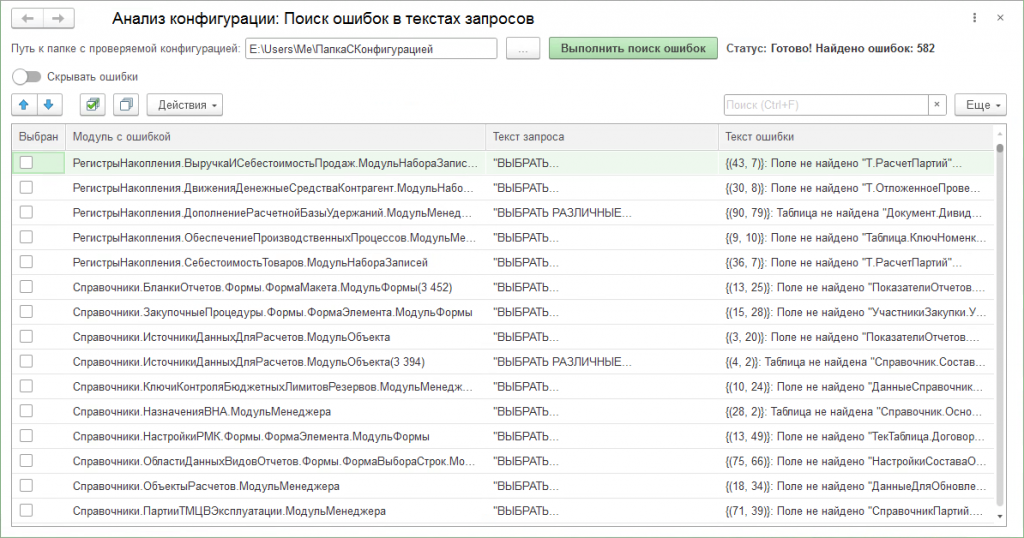
Указываем путь к папке, в которую мы выгрузили конфигурацию. Нажимаем «Выполнить поиск ошибок». Ждём.
Шаг 3. Дожидаемся результатов.
Выбираем в меню «Действия» - «Сохранить файл со всеми ошибками (для исключений)»
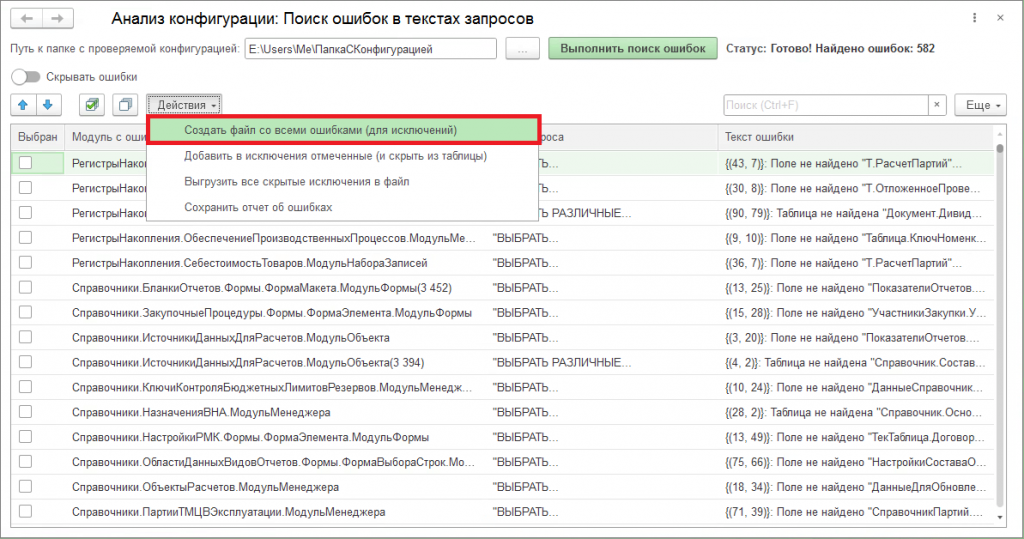
Сохраняем ошибки в файл, назовём его, например, ШумДоОбновления.mxl.
Шаг 4. Открываем базу с типовой конфигурацией нового релиза в режиме «1С Предприятия». Повторяет шаги, аналогичные шагам 2 и 3. В результате получаем файл ШумНовогоРелиза.mxl.
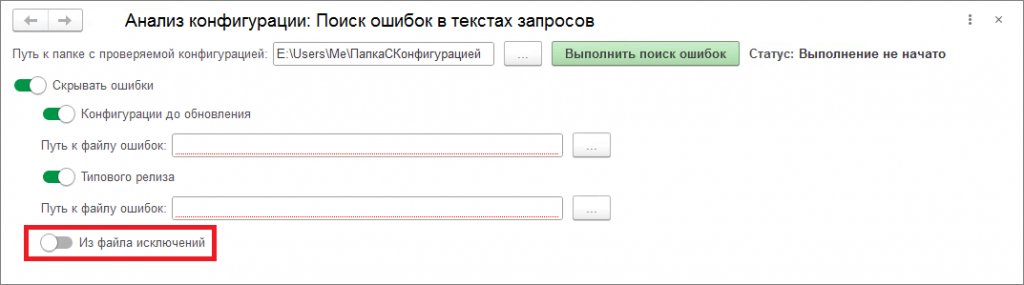
Шаг 5. Запускаем базу, обновлённую на новый релиз с перенесёнными доработками в режиме «1С Предприятия». Запускаем обработку. Указываем путь к папке с выгруженной конфигурацией. Но в этот раз нажимаем на выключатель «Скрывать ошибки».

Появляются варианты, отмечаем выключатели «Конфигурации до обновления» и «Типового релиза».
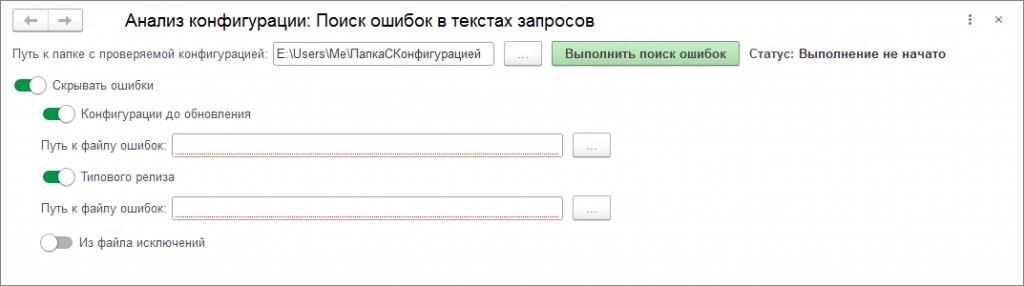
Выбираем подготовленные ранее файлы с шумами. Нажимаем «Выполнить поиск ошибок». В итоге на последнем шаге программа исключит все ошибки «шумов» из итогового результата.
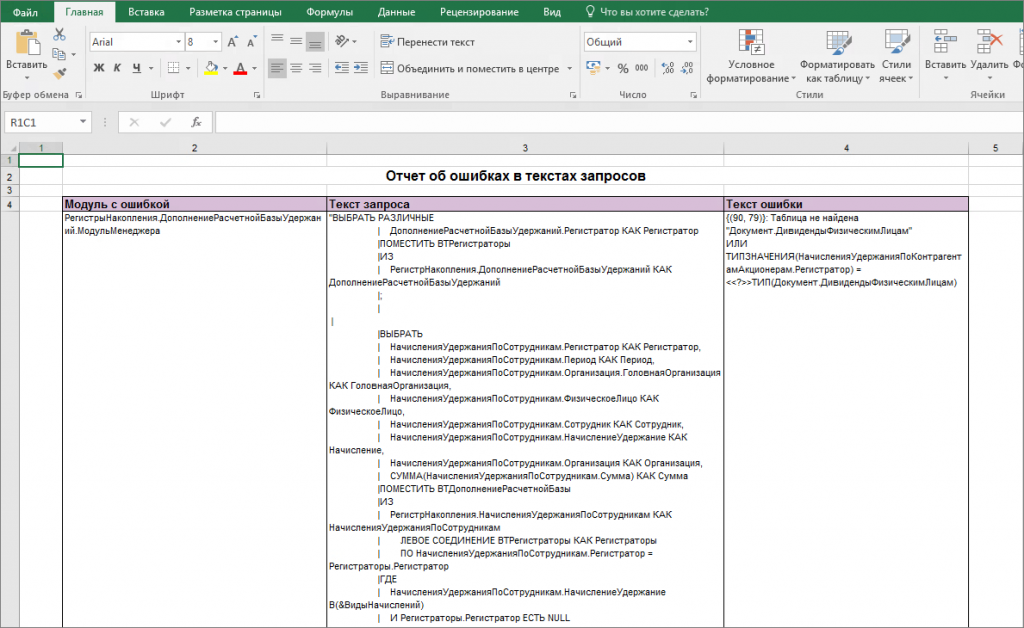
Оставшиеся ошибки можно сохранить в удобный отчёт в Excel для последующего анализа.
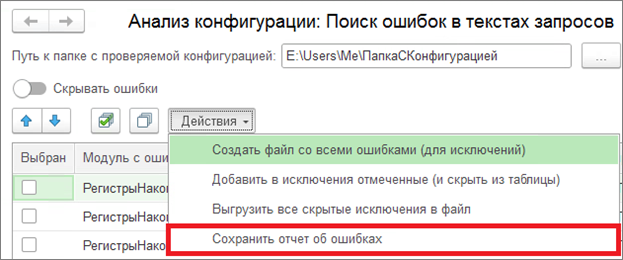
Также есть возможность формировать собственный файл со списком ошибок-исключений. Для этого можно отмечать ошибки, которые вы не считаете ошибками, чекбоксами в списке.
Далее выбираем меню «Действия»:
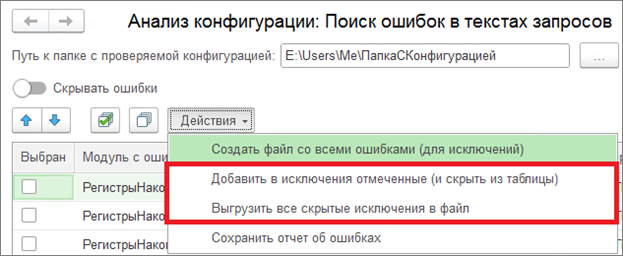
Сначала нажимаем «Добавить в исключения отмеченные». После нажатия данные строки скроются из списка. Далее выбираем пункт «Выгрузить все скрытые исключения в файл».
Данным файлом также можно в дальнейшем пользоваться, включив данный флажок:
Ну и на этом у меня всё! Всем удачи и берегите своё время) Надеюсь, данная обработка вам в этом поможет)
ОБНОВЛЕНО 04.03.2025:
Выложена версия 1.1. В новой версии обработки я разработал алгоритм, который позволяет находить не только первую ошибку в запросе, а все ошибки. Алгоритм умеет пропускать первую ошибку в запросе, если она вида "Поле не обнаружено" или "Таблица не обнаружена". Теперь качество поиска ошибок будет ещё выше, даже если доработка затронула запрос, попадающий в список "шумов"). За идею данного функционала спасибо DmitriyV
Проверено на следующих конфигурациях и релизах:
- 1С:ERP Управление предприятием 2, релизы 2.5.20.93
Вступайте в нашу телеграмм-группу Инфостарт