





Большие языковые модели (LLM), созданные на технологии "трансформер" (GPT), позволяют преобразовать вопрос, сформулированный на человеческом языке, в текст запроса к базе данных.
Кому это может быть полезно.
Во-первых, новичкам. Тем, кто только начинает изучать язык запросов. Задав, к примеру, вопрос: "как получить список товаров, общая сумма продаж которых превышает 10000", начинающий узнает, что условия задаются не только через ГДЕ
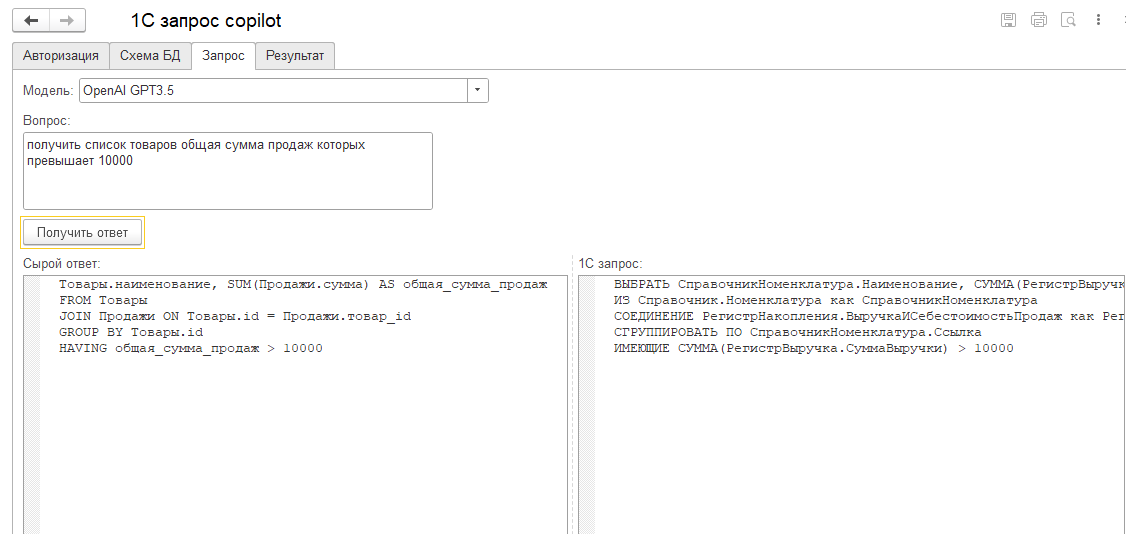
Эта обработка будет лучше любого учебника.
Она также пригодится и тем, кто в принципе знает язык запросов, но пользуется им не часто, и поэтому не держит в голове все конструкции. Обработка позволит не напрягать память и не прибегать к утомительной процедуре поиска в сети.
Самые опытные специалисты, те, кто пишет запросы каждый день и помногу, тоже найдут здесь кое-что для себя. Бывают ситуации, когда неохота ломать голову. В то же время, в простых с виду случаях даже опытные специалисты допускают ошибки. Вот например здесь:
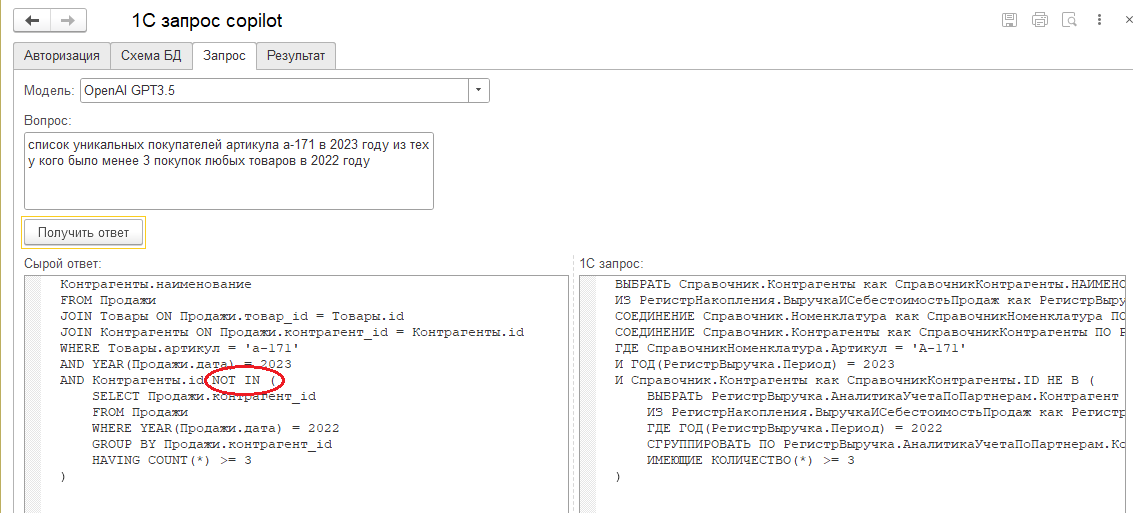
С первым и вторым условием все просто, продажи определенного артикула в 2023 году. А в третьем условии рука тянется написать "В" (контрагент в списке тех, у кого было менее 3 покупок), а надо писать "НЕ В" (контрагент не в списке тех, у кого было 3 покупки и более). Потому что с отсутствующими значениями надо быть внимательнее. Они часто "ломают" логику. Менее 3 покупок - это 2 или 1. А 0 покупок - это не менее 3. Большая языковая модель в этом случае будет вашим полезным ассистентом.
В начале работы укажите свои данные для авторизации.
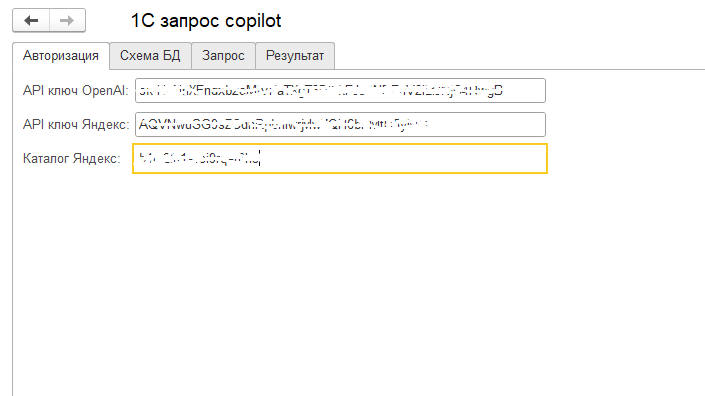
В настоящий момент есть два поставщика работоспособных моделей, предоставляющие доступ к ним через API. Это OpenAI и Яндекс. Для OpenAI достаточно указать API-ключ. Для Яндекса API-ключ и каталог. Получить ключи можно на сайтах: https://platform.openai.com/ и https://cloud.yandex.ru/ Использование больших языковых моделей стоит денег. Оплата рассчитывается, исходя из объемов того, что мы подаем на вход и что получаем на выходе. Если сравнивать с другими задачами, у нас это будет немного. Например, при подготовке данной статьи, я прогнал с десяток-другой запросов к двум моделям Яндекс. У меня вышло 13 рублей. И Яндекс и OpenAI предоставляют всем новым пользователям гранты. Т.е. зачисляют некоторую начальную сумму на счет. У Яндекс это 3000 рублей у OpenAI 18 долларов, если не ошибаюсь.
Далее нам потребуется схема базы данных. Использовать метаданные 1С как есть не получится по разным причинам, на которых я сейчас не буду останавливаться. Нужно некоторое промежуточное представление.
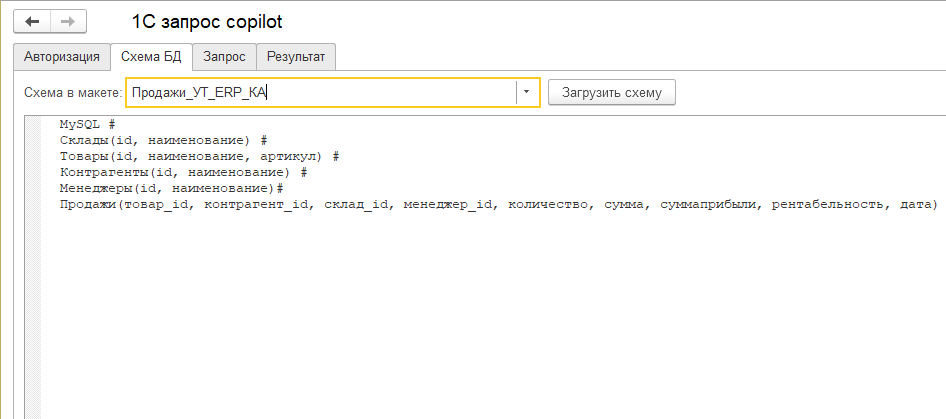
Почему MySQL. Если ничего не указывать, то на выходе можно получить "губы Никанора Ивановича" и "нос Ивана Кузьмича", т.е. смесь различных диалектов SQL. По моему опыту, запросы на MySQL формируются лучше прочих, но вы можете поэкспериментировать сами. # нужна, чтобы одно не "прилипло" к другому. OpenAI этим вроде бы не грешит, а у Яндекса я такое видел. В обработке есть макет с готовой схемой. Ее можно загрузить. Используя этот пример, вы сможете делать свои собственные схемы.
Основная рабочая страница выглядит так:
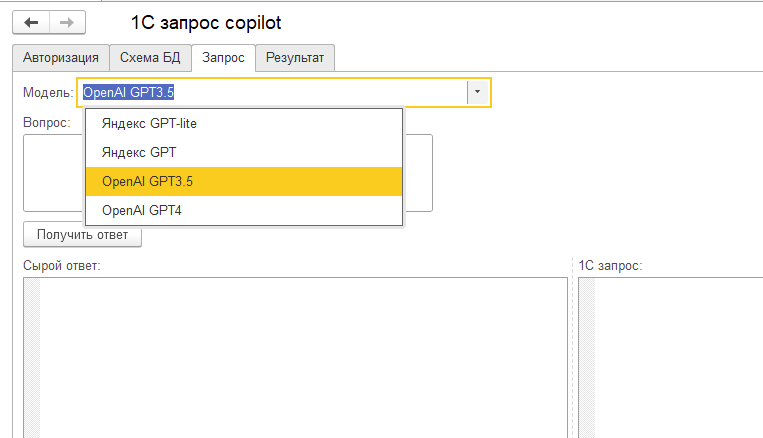
На данный момент доступны 4 языковые модели. Две модели от Яндекса, одна попроще и подешевле, другая подороже и посильнее, и две модели от OpenAI, с таким же раскладом. Модель Яндекс GPT-lite не годится для работы. Сначала я не хотел включать ее в список. Но потом решил оставить для того, чтобы вы могли получить более полное представление о работе различных языковых моделей и на практике убедиться в том, что в данном случае размер имеет значение. Для получения осмысленных результатов, используйте полную модель от Яндекса. В случае с OpenAI ситуация прямо противоположная. Лучше использовать "младшую" модель OpenAI GPT3.5 Она не только дешевле, но еще и немного лучше справляется с работой. И это опять же доказывает, что размер имеет значение. Не вдаваясь в технические подробности, скажем, что у OpenAI GPT3.5 и OpenAI GPT4 размер примерно одинаков.
Выбрав модель, вы задаете свой вопрос на естественном языке и получаете "сырой" ответ от языковой модели. Чтобы получить из сырого ответа текст запроса на языке 1С последовательно применяются две функции ПолучитьИсправленныйОтвет() и ПолучитьТекстЗапроса1С(). Первая не имеет отношения к 1С. Она исправляет некоторые общие недостатки. Например, текст ответа от модели Яндекса будет содержать не только собственно текст запроса SQL, но и пояснения, по большей части бесполезные. Соответственно возникает задача выделить из всего этого сам запрос. Вторая функция решает две задачи. Она транслирует элементы заданной нами схемы запроса в настоящие объекты метаданных. А также эта функция представляет собой относительно простой транслятор из SQL в язык запросов 1С. Я не задавался целью получать всякий раз 100% работающие запросы. Все же это инструмент разработчика, и тут важнее идея. Но вы можете подойти сколь угодно близко к этим 100%, если усовершенствуете этот транслятор.
Визуализацию результатов выполнения запроса я все же добавил.
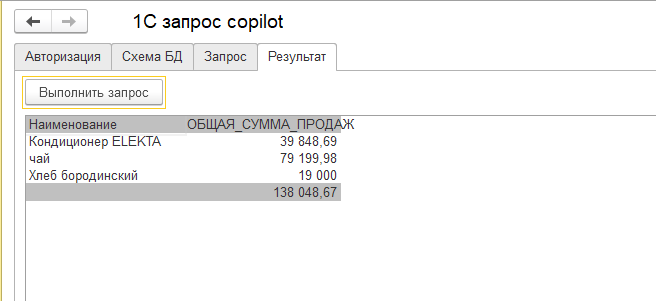
Эта технология новая. По моим наблюдениям, отношение к ней у разных людей драматически противоположное. У одних она вызывает эйфорию, у других категорическое неприятие. Истина, как водится, посередине. Надеюсь, что данный инструмент поможет вам получить личный опыт и сформировать взвешенное отношение к этой технологии.
Тестировал на 8.3.23.1912.
Управляемые формы.
UPD 07.02.2024
Добавлены две модели GigaChat от Сбера. Это не изменило количество работоспособных моделей. Их по прежнему три: полная модель от Яндекса и две модели от Open AI. Тем не менее, возможность убедиться в этом самостоятельно, а не с чьих-то слов будет не лишней.
UPD 09.03.2024
Добавлена модель от Google Gemini pro. На данный момент пользование этой моделью бесплатно. Для нее установлено ограничение в 60 запросов в минуту, что в нашем случае вполне приемлемо. Спешите воспользоваться!
UPD 15.03.2024
Добавлены три модели от Anthropic. Anthropic - это стартап, основанный выходцами из OpenAI. Они дают стартовый грант в 5$. Этого вполне достаточно для того, чтобы ознакомиться с возможностями этих моделей.
Вступайте в нашу телеграмм-группу Инфостарт