

Если у вас есть необходимость найти номенклатуру или элементы других справочников, у которых имеется схожее наименование, то эта обработка предназначена именно для вас.
Изначально обработка писалась для того, чтобы находить схожие по наименованию элементы справочника "Номенклатура", но потом я решил сделать ее универсальной. Обработка написана как для управляемых, так и для обычных форм.
Теперь она может искать по любому справочнику не только по наименованию, но и другим строковым реквизитам.
Возникает вопрос: что значит "схожесть" наименований? Если два элемента названы одинаково то очевидно что схожесть очевидно присутствует. Но часто бывает, что пользователи делают ошибку и функция НайтиПоНаименованию не срабатывает. В Итоге создается два элемента справочника, которые являются по сути одним предметом.
Какие ошибки заполнения могут быть?
1. Замена схожих внешне латинских символов кириллицей и наоборот, например буквы "С". Внешне это выглядит одинаково, но функция НайтиПоНаименованию такого не найдет.
2. Перестановка слов.
3. Синтаксические ошибки
4. Неполное название.
Данная обработка позволяет это найти с некоторыми оговорками.
Принцип работы обработки основан на использования оператора "ПОДОБНО" в запросе к справочнику. Она составляет необходимый шаблон поиска, согласно настройкам.
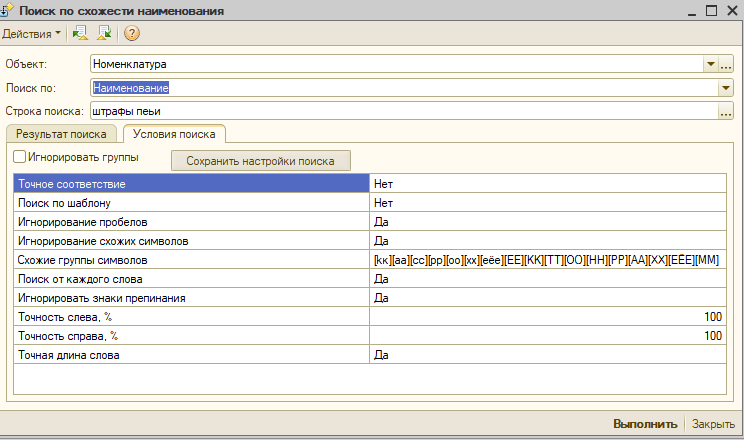
Настройки работают следующим образом.
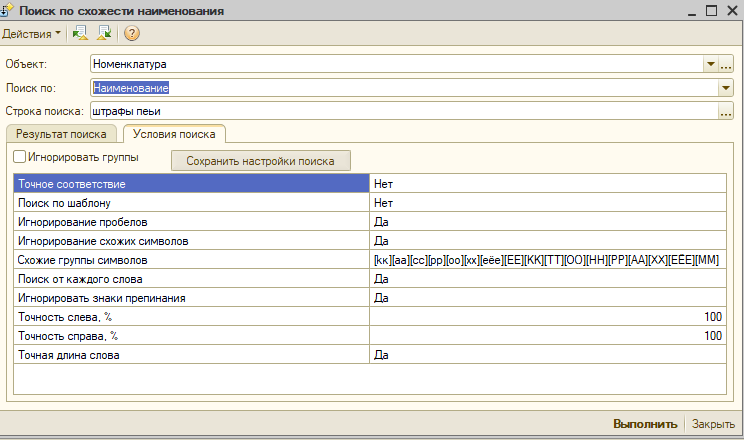
"Поиск по шаблону" - настройка, которая выполняет запрос по шаблону заданному в строке поиска. При включенной настройке остальные не работают.
"Точное соответствие" - Ищет по точному соответствию строки поиска.
"Игнорирование пробелов" - пробелы при поиске заменяются на "%"
"Игнорировать знаки препинания" - знаки препинания при поиске заменяются на "%"
"Игнорирование схожих символов" - настраивает поиск так, символы, которые визуально можно спутать считались одинаковыми. Например, слова "слава" и "cлaвa" считались одинаковыми. Хотя это не так. Первое слово полностью набрано на кириллице, а во втором символы "c","а" - набраны на латинице. При выключенной настройке найдутся оба слова.
"Схожие группы символов" - это и есть набор, в котором указаны символы, которые могут быть ошибочно набраны. Группы этих символов выделяются в скобках "[]". Их можно дополнить при необходимости.
"Поиск от каждого слова" - разбивает предложение, набранное в строке поиска на слова и ищет по каждому слову, используя все настройки, кроме "Игнорирование пробелов" и "Игнорировать знаки препинания", поскольку они и будут разбивать предложение на подстроки.
"Точность слева" и "Точность справа", "Точная длина слова" - работают совместно. Они применимы для каждого слова в предложении.
"Точность слева" и "Точность справа" - показывает, сколько букв в процентном выражении слева и справа от половины длины слова будут оставлены, а остальные будут не учитываться.
При этом параметр "Точная длина слова" говорит о том, как будет сопоставлена средняя часть слова.
Пример: "Точность слева" = 80,Точность справа" = 80. "Точная длина слова" = Да.
Возьмем строку поиска: "Самый вкусный арбуз".
Поставим настройку "Поиск от каждого слова" - "Нет". Тогда обработка будет искать по всей строке писка, но при этом в каждом слове будут сопостовляться не все буквы, а только их часть по такому шаблону:
"С___й вк___ый а___з". И кроме наименования "Самый вкусный арбуз" найдется например "Сытый вкусный артуз" и прочие элементы у которых будет одинаковое число букв с одинаковым началом и окончанием. Если выберем "Точная длина слова" = Нет. Тогба шаблоп поиска будет таким "С%й вк%ый а%з". И кроме элемента "Самый вкусный арбуз", "Сытый вкусный артуз" и прочих, ранее найденных, найдутся те, у которых длина слова не совпадает, но совпадают начало и окончание. Например "Сый вкоторый арз".
Обработка тестировалась на 1С:Предприятие 8.3 (8.3.24.1368). На некоторых версиях более младших может работать некорректно, т.к. в них нет функций работы с регулярными выражениями. Но доработать это не сложно. Вам надо исправить только функцию "ЭтоБуква" в модуле объекта, которая возвращает ИСТИНА, если символ является буквой.
Удачи!
Проверено на следующих конфигурациях и релизах:
- Управление производственным предприятием, редакция 1.3, релизы 1.3.245.2
Вступайте в нашу телеграмм-группу Инфостарт