



Использование LLM для программирования на 1С
Как и многие из вас, я пробую использовать LLM'ки для программирования на 1С. Для задач, связанных с интеграциями или чисто алгоритмических вопросов - это уже классно помогает.
Но большая часть нашей работы все же предполагает знание структуры метаданных 1С (а еще лучше с БСП и синтакс-помощника).
Встроенную в 1С выгрузку в xml-файлы я даже не рассматривал, очевидно, что объемы будут несовместимыми с контекстами LLM, даже с 1 млн токенов у Gemini. Описание структуры среднего документа/справочника само по себе не маленькое, а с избыточностью xml-разметки - это вообще жесть.
Первое время, пока не было популярности MCP, я использовал простой ручной подход:
 Внешней обработкой выгружал описание метаданных в markdown разметке (маркдаун хорошо понимают LLM'ки, а объемом сильно компактнее xml).
Внешней обработкой выгружал описание метаданных в markdown разметке (маркдаун хорошо понимают LLM'ки, а объемом сильно компактнее xml).
Выгружал конкретный объект и, опционально, связанные с ним объекты. Подставляя такой файлик в контекст запроса к LLM, получается сильно качественнее результат.
D последние месяцы только и разговоров что об MCP. Это классное решение, которое позволяет LLM'ке самой дозапрашивать данные.
Нужно было только мою ручную маркдаун-выгрузку обернуть в MCP-сервер с RAG'ом на векторной БД.
Ниже описание MVP-решения, которое можно далее дорабатывать под себя. Мне сильно не хватало подобной статьи, чтобы сэкономить бессонные ночи.
Демонстрация
Топовые LLM'ки неплохо знают некоторый собирательный образ типовых конфигураций 1С, поэтому и без MCP/RAG могут написать валидный код. Более наглядно будет на отраслевых конфигурациях, чей исходный код они либо не видели, либо видели крайне мало. На видео пример с Рарус Аптекой (УНФ):
Как это работает
Подготовка
Нужна машинка с установленным Docker и Docker Compose. Я делал все на linux, но подозреваю, что и на современных Windows c WSL может сработать. Я сразу не рассматривал локальные MCP через STDIO, мне кажется, это не удобно, не универсально. И хотелось в дальнейшем начать наконец использовать старую nvidia 1070 на домашнем сервере. Поэтому сразу делал remote MCP, хотя с ними свои нюансы. В общем, запускать можно хоть на удаленной, хоть на локальной машине, просто протоклол у MCP будет streamable HTTP (или SSE для Copilot)
Клонируете репозиторий, переходите в папку проект и запускаете скрипт, который запустит сборку докер-образов и затем сами контейнеры:
git clone https://github.com/FSerg/mcp-1c-v1.git
cd mcp-1c-v1
./start.sh
В зависимости от скорости машинки и интернета это может быть от нескольких минут, до десятков минут. В основном из-за того что библиотека SentenceTransformers, которая используется для генерации эмбеддингов, будет скачивать torch, cuda (итоговый image получается 6+ Гб).
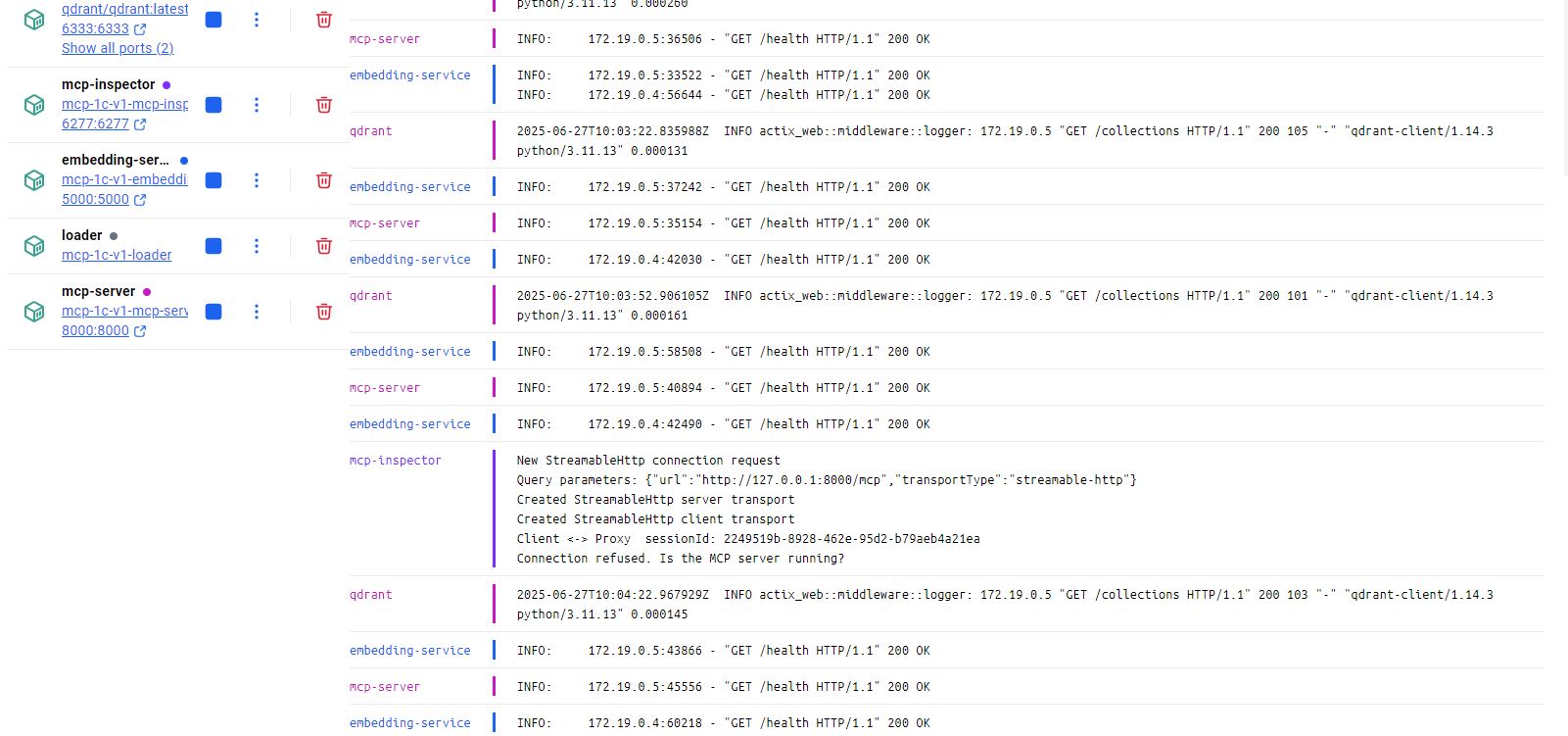
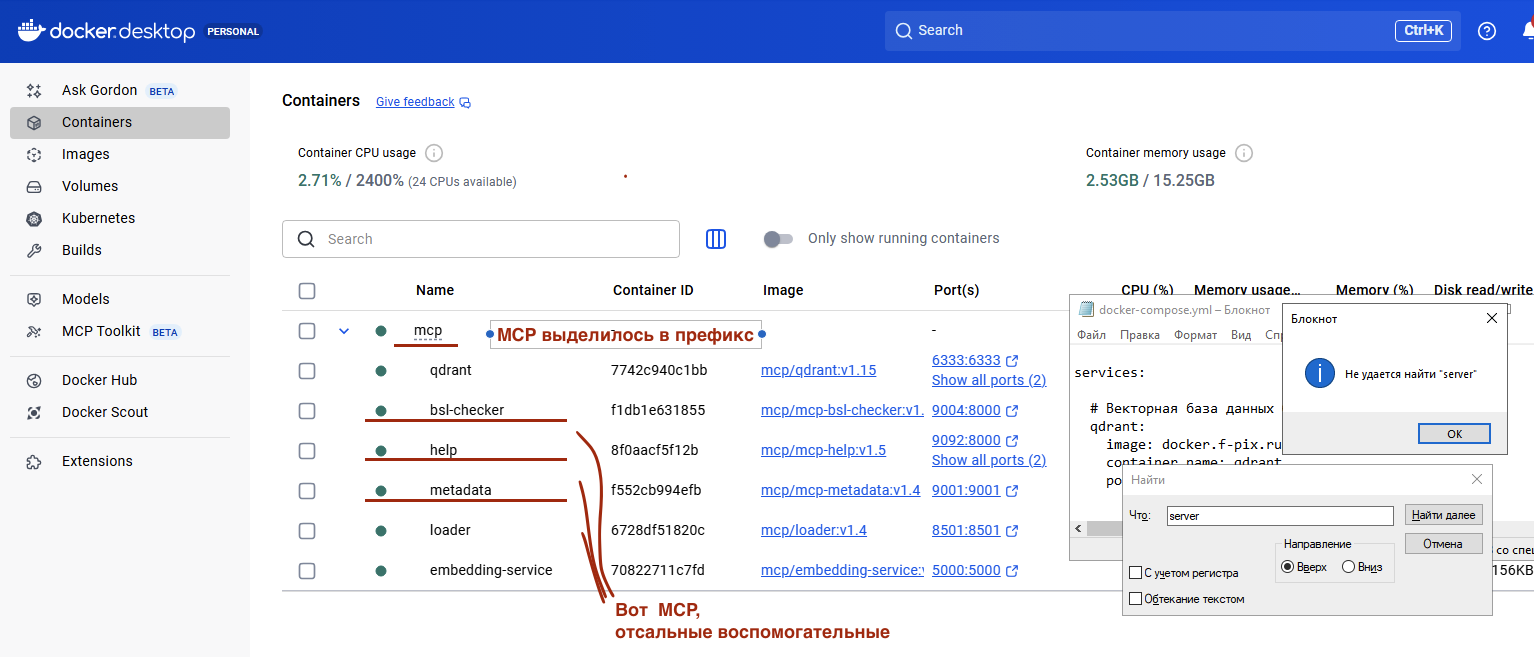
В результате запустится несколько докере-контейнеров:
- Qdrant - векторная база данных Qdrant
- Embedding Service - сервис генерации эмбеддингов (векторов)
- Loader - веб-интерфейс для загрузки описания объектов метаданных 1С в Qdrant
- MCP Server - сам MCP-сервер
- Inspector - веб-интерфейс для тестов/отладки MCP
После того как image'ы сбилдятся и запустятся контейнеры, нужно в первую очередь проследить за логами контейнера embedding-service:
docker-compose logs -f embedding-service
чтобы убедиться, что он полностью запустился (поднялся http-сервис на 5000-порту). При первом запуске он скачивает модель эмбеддингов с сайта hugginface и были с этим проблемы (боюсь меня просто блочили за активность).
По умолчанию в embeddings/config.json прописана легковесная модель all-MiniLM-L6-v2, которая дает приемлемый результат. После того как с ней все запуститься и будет работать, то можно поменять в конфиг и прописать модельку по-современней и по бенчмаркам более крутую Qwen/Qwen3-Embedding-0.6B, которая дает более качественные эмбеддинги, соответственно более точный поиск на менее четкий запрос (нужно будет перезапустить контейнер embedding-service).

Теперь выгружаем описание конфигурации с помощью внешней обработки: ПолучитьТекстСтруктурыКонфигурацииФайлами.epf
В обработке два параметра:
- сколько выгружать объектов каждого типа (делал чисто для тестов, чтобы не выгружать сразу все объекты), поставьте 9999, если выгружаете всё.
- сколько выгружать описаний составных типов (если у какого-то объекта более 10-20 типов, то лучше выгрузить это как "составной" тип)

Обработка сформирует zip-архив в котором будет табличка objects.csv c перечнем всех объектов и рядом пачка маркдаун-файлов с описанием каждого объекта.
Открываем веб-интерфейс сервиса загрузки http://youraddress:8501 и загружаем полученный zip-архив.
Загрузчик создаст в векторной БД Qdrant коллекцию 1c_rag. В процессе загрузки векторизуются только внутр.названия объектов и их синоним. А сами подробные описания объектов сохраняются в БД как часть метаданных коллекции.
В моем первом подходе я векторизовывал всё описание объектов большими моделями типа jinaai/jina-embeddings-v3. Это требовало больше ресурсов, но смысла не имело, потому что оказалось, что по запросу "расходная накладная" в пространстве векторов описание (вектор) условного "расходного ордера" будет ближе чем расходной накладной, в силу более сложной структуры первого. Быстро стало понятно, что даже поиск по ключевым словам даст лучше результат, но все равно сделал на векторах, потому что разные LLM'ки по-разному формулируют запросы объектов и векторизация дает некоторую универсальность.
Перед переходом к IDE, осталось убедиться, что MCP-сервер работает:
- Можно через веб-интерфейс MCP-инспектора
http://youraddress:6274 - Или любым http-клиентом, типа Postman, Insomnia, curl:
http://youraddress:8000/search
{
"query": "Расходная накладная",
"object_type": "Документ",
"limit": 3
}

Использование
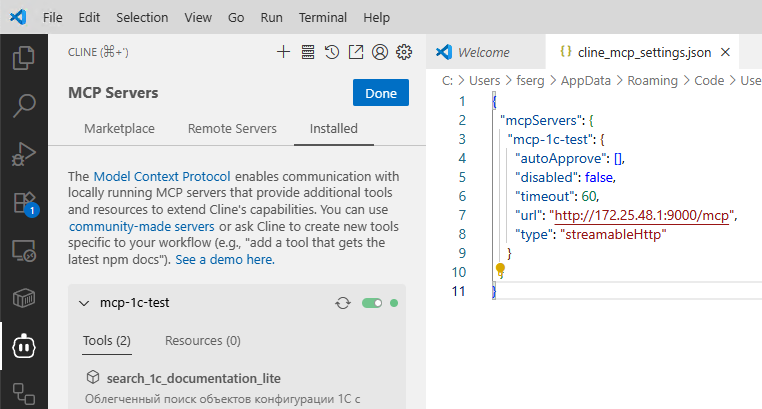
Все, можно прописать MCP в настройках проекта вашей IDE. В Cursor'е и в плагинe RooCode для VSCode агенты уже поддерживают streamable http протокол MCP, поэтому там прописываем такой адрес: http://youraddress:8000/mcp
Для Copilot в VSCode нужно прописать вариант адреса с поддержкой более старого протокола SSE: http://youraddress:8000/mcp/sse
Хотя на сайте Microsoft говориться, что поддерживается и streamable http, но на практике не работает. И в последних версиях плагина Cline для VSCode тоже заявлена поддержка streamable http, а по факту оба протокола не заработали с Cline.
Но все это меняется каждый день, и новые модели и MCP развивается (появляется авторизация и прочее). В след за этим и IDE'шки и плагины релизятся буквально каждый день. То что не работает сегодня - заработает завтра и наоборот :)
Для VSCode Copilot .../YourProject/.vscode/mcp.json
{
"servers": {
"my-1c-mcp-server": {
"url": "http://youraddress:8000/mcp/sse"
}
}
}
Для Cursor .../YourProject/.cursor/mcp.json
{
"servers": {
"my-1c-mcp-server": {
"url": "http://youraddress:8000/mcp"
}
}
}
Для VSCode RooCode .../YourProject/.roo/mcp.json
{
"mcpServers": {
"My1C": {
"type": "streamable-http",
"url": "http://youraddress:8000/mcp"
}
}
}
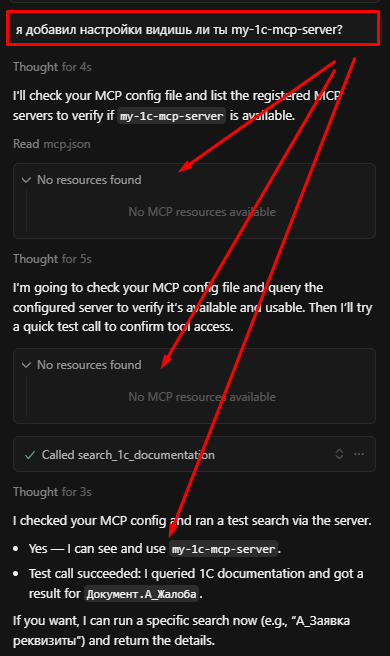
Топовые LLM'ки, такие как Gemini Pro, Claude Sonnet сами иногда догадываются об использовании MCP-сервера, если в запросе есть упоминание об 1С. Но лучше явно это указать в промпте (или в правилах):
Обязательно используй MCP-сервер для поиска описания структуры данных 1С.
Ломающее мой мозг наблюдение: LLM'кам не всегда достаточно простого упоминания типа "следуй спецификации из файла...". Зачастую нужно усиливать это прилагательными, чтобы получать более качественный результат. Например, "следуй спецификации из файла внимательно" или "следуй спецификации из файла строго". Это может звучать странно, но это действительно помогает.
Можно при загрузке описаний метаданных указать имя коллекции векторной БД.
Таким образом в Qdrant можно загрузить описания разных конфигураций, например:
- - 1c_ut
- - 1c_unf
...
А когда MCP будете прописывать в настройках конкретного проекта, например Cursor, то можно указать имя коллекции через заголовок:
.../YourProject/.cursor/mcp.json
{
"servers": {
"my-1c-mcp-server": {
"headers": {
"x-collection-name": "1c_unf"
},
"url": "http://youraddress:8000/mcp"
}
}
}
Т.е. один инстанс MCP-сервера можно подключать к разным проектам для работы с метаданными разных конфигураций 1С

Вайб-кодинг — ИИ пишет за вас в 1С
Решение «Вайб-кодинг» внедряет искусственный интеллект прямо в 1С: пишет корректный код, анализирует метаданные и помогает автоматизировать проектные задачи. Поддерживает GPT-4, Llama, Claude и Gemini.
Проверено на следующих конфигурациях и релизах:
- Управление нашей фирмой, редакция 3.0, релизы 3.0.11.169, 3.0.10.235
- Управление торговлей, редакция 11, релизы 11.5.22.67, 11.5.17.221
- Бухгалтерия предприятия, редакция 3.0, релизы 3.0.176.38, 3.0.169.18
- Розница, редакция 3.0, релизы 3.0.11.169, 3.0.10.235
Вступайте в нашу телеграмм-группу Инфостарт

{kind=link}