








Обработка анализирует и удаляет помеченные на удаление справочники и документы, а так же документы без движений. Конечная цель - выполнить анализ и удаление ссылочных объектов быстро, незаметно и безопасно при параллельно работающих пользователях и на объемной базе.
Что послужило поводом для создания собственного решения:
Типовой механизм платформы "Удаление помеченных объектов" имеет два недостатка: работает очень медленно и требует монопольного режима.
Медленно потому, что:
1. пытается сделать все и сразу для всех объектов. Хотя есть возможность ручного выбора объектов, но ты же не будешь как дятел по одному объекту выбирать каждую минуту?
2. пытается найти и показать все ссылки на объект (хотя справедливости ради надо отметить в упр формах есть режим "Полное удаление" - там на это время не тратится, но опять же сразу для всех объектов)
Требует монопольного режима потому, что:
1С исходит из самого пессимистичного сценария - во время проверки на удаляемость какой ни будь пользователь может создать ссылку на удаляемый объект, а мы его уже поставили в очередь на удаление и через некоторое время удалили. Монопольный режим полностью исключает вероятность появления битых ссылок. Но как быть в случае работы пользователей с базой в режиме 7*24?
Другое решение - обработка с ИТС УдалениеПомеченныхОбъектов.epf (или DeleteMarkedObjects). Она позволяет анализировать и удалять в разделенном режиме. Но в ней используется все тот же встроенный в платформу метод ТаблицаСсылок = НайтиПоСсылкам(МассивКУдалению). Именно он работает крайне медленно. Даже если переписать обработку и подсовывать ей объекты по одному, она будет искать все ссылки на объект, на чем тратится безумное количество времени. Так же из-за большого временного лага между анализом и непосредственным удалением появляется довольно высокий шанс вклинивания какого ни будь Powered User и генерации битых ссылок. Битые ссылки - явление достаточно неприятное и трудно исправимое. И хотя средства лечения давно найдены (например //infostart.ru/public/98973/), но зачем нарываться?
Справедливости ради надо отметить одно очень интересное решение "Свертка базы SQL + Альтернативный контроль удаления помеченных" //infostart.ru/public/139651/. Но тут опять не без ложки дегтя. Оно довольно-таки платное. Кроме того мне показался сценарий автора слишком уж сложным и в итоге негодным для разделенного режима. Да, он сделал быстрый движок для анализа и удаления, быстрее чем в вышеупомянутых решениях, но все равно остается опасно большой временной лаг между анализом и непосредственным удалением, потому что он пытается за один раз удалить все по максимуму, а для этого требуется долгий алгоритм для выявления последовательных или закольцованных цепочек ссылок.
Я решил максимально ускорить процесс анализа удаляемости. Это можно сделать только за счет упрощения алгоритма. Приносим в жертву качество, получаем выигрыш в скорости и уменьшаем шансы появления битых ссылок. Под низким качеством я понимаю недообследованные до конца и потому оставленные неудаленными объекты. Что происходит в моей обработке: я анализируется последовательно каждый объект, если нахожу хотя бы одну ссылку на него, то перехожу к следующему объекту. Если ссылок не найдено, то сразу удаляю объект, а не накапливаю список для отложенного пакетного удаления. Если есть длинные цепочки последовательных ссылок, то пользователь интерактивно может повторить анализ/удаление несколько раз. Если есть закольцованные цепочки, то мой алгоритм их конечно же не разорвет, но каков процент таких цепочек обычно бывает в общей массе, особенно в массе удаляемых за прошлые периоды документов при свертке?! Окончательную зачистку можно сделать в монопольном доступе типовым механизмом "Удаление помеченных объектов" - он работает быстро при небольшом количестве помеченных.
Как это работает на уровне интерфейса:
1. Если БД на SQL, то на закладке "Настройки SQL" указываем параметры подключения к SQL. Нажимаем кнопку "Проверить подключение к SQL". Если все ОК то при последующем заполнении таблицы на закладке "Объекты поиска" будет выдана информация о размерах таблиц:
Вес одной записи, KB
Total table size, KB
Index size, KB
Data size, KB
Unused space, KB
2. На закладке "Настройки SQL" выбираем способ удаления: средствами 1С или SQL. Понятное дело, если ваша база файловая, то вариант один. Если база на SQL, и у вас нет предрассудков против использования не-1С-методов, выбирайте второй вариант. При этом скорость удаления будет существенно выше засчет сокращения накладных расходов, связанных с работой сервера 1С и вызовом предопределенных процедур в модуле удаляемого объекта.
Для режима "Удалять средствами SQL" можно включить режим "Записывать в журнал регистрации событий". При этом журнал будет заполняться по аналогии с типовым удалением средствами 1С, только в поле "Комметарий" будет пометка "Удалено средствами SQL".
3. На закладке "Объекты поиска" нажимаем кнопку "Заполнить".
В список попадают справочники и документы с ненулевым количеством объектов БД, отсортированные в обратном порядке по колонке "Кол помеченных" (или по колонке "Вес одной записи, KB", если база на SQL)- это чтобы сразу было видно с кого начать анализ/удаление.
Для документов подсчитывается количество объектов без движений в колонке "Кол без движений". Это могут быть проведенные документы с очищенными движениями как часть кампании по сворачиванию базы.
Если у вас база на SQL и на закладке "Настройки SQL" указаны верные параметры подключения к SQL, то будут заполнены колонки с размерами в килобайтах.
Единственная колонка "Можно удалять" будет заполнена на этапе удаления, который можно запустить в режиме имитации.
4. Устанавливаем галочки в колонке "Пометка". Можно воспользоваться кнопками групповой установки или снятия пометок. Если выделить несколько строк, то действие снятия/пометки будет для этих строк. Если выделена только одна строка, то действие снятие/пометка будет для всего списка.
5. После выбора объектов МД можно переходить к поиску соответствующих объектов БД - кандидатов на анализ и удаление. Для этого нажимаем кнопку "Заполнить" на закладке "Помеченные на удаление" и/или "Документы без движений". На закладке "Документы без движений" можно указать отбор по периоду для документов.
6. На закладке "Схема анализа" нажимаем кнопку "Заполнить". На этом этапе для каждого анализируемого объекта МД готовятся тексты запросов типа "ВЫБРАТЬ ПЕРВЫЕ 1 1 ИЗ всех таблиц, у которых есть поля со ссылками на этот объект МД".
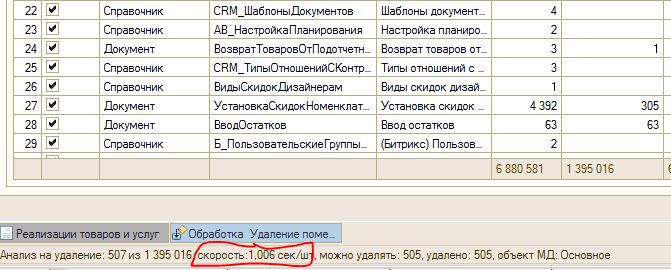
7. Нажимаем кнопку "Анализ (удаление)". Дальше идет вопрос "Одновременно удалять?". Если ответить НЕТ, то будет выполнена имитация удаления, и в таблице "Объекты поиска" будет заполнена колонка "Можно удалять".
Основные фишки на уровне кода:
1. Для определения наличия хотя бы одной ссылки на удаляемый объект выполняется пакет запросов ко всем таблицам, где есть поля с типом удаляемого объекта, например, вот некоторые примеры запросов:
ВЫБРАТЬ ПЕРВЫЕ 1 1 ИЗ Документ.АвансовыйОтчет.Прочее КАК Т ГДЕ Т.Субконто1 = &Параметр ИЛИ Т.Субконто2 = &Параметр ИЛИ Т.Субконто3 = &Параметр ИЛИ Т.СубконтоНУ1 = &Параметр ИЛИ Т.СубконтоНУ2 = &Параметр ИЛИ Т.СубконтоНУ3 = &Параметр
...
ВЫБРАТЬ ПЕРВЫЕ 1 1 ИЗ РегистрНакопления.ВзаиморасчетыСПодотчетнымиЛицами КАК Т ГДЕ Т.ФизЛицо = &Параметр
...
ВЫБРАТЬ ПЕРВЫЕ 1 1 ИЗ РегистрБухгалтерии.Хозрасчетный.Субконто КАК Т ГДЕ Т.Значение = &Параметр
...
ВЫБРАТЬ ПЕРВЫЕ 1 1 ИЗ РегистрБухгалтерии.Хозрасчетный КАК Т ГДЕ Т.ВалютаДт = &Параметр ИЛИ Т.ВалютаКт = &Параметр
Конечно, если поле с условием не проиндексировано, то выполняться такой запрос будет медленно, и чем больше таблица, тем медленнее запрос, потому что SQL в запросе будет тупо перебирать все записи таблицы - выполнять команду Table Scan. Конечно самое лучшее, это на время свертки базы в конфигураторе установить у таких полей признак Индексировать. Если такой возможности нет, то остается только одно - начать удаление объектов МД с самым большим показателем "Вес одной записи", т.к. они будут ссылаться на остальные не такие большие таблицы.
Чтобы определить самые тяжелые запросы, на закладку "Схема анализа" я добавил кнопку "Замерить запросы". По завершению замера будет заполнена колонка "Время запроса". По ней можно понять, каких Индексов не хватает.
2. При удалении средствами SQL удаляются записи в таблицах:
Основная
ТабличнаяЧасть
ТаблицаИзменений
ЖурналДокументов
Последовательность
РегистрСведений (по ведущему измерению)
Например, так выглядит пакет SQL запросов для удаления одного документа, у которого несколько табличных частей, который участвует в планах обмена и в журналах документов и в последовательностях, а одна из последовательностей участвует в планах обмена, и есть регистр сведений с ведущим измерением, ссылающимся на этот документ:
DELETE FROM _Document430 WHERE _IDRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _Document430_VT10847 WHERE _Document430_IDRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _Document430_VT10887 WHERE _Document430_IDRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _Document430_VT10899 WHERE _Document430_IDRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _Document430_VT10920 WHERE _Document430_IDRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _Document430_VT10925 WHERE _Document430_IDRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _Document430_VT10943 WHERE _Document430_IDRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _Document430_VT10950 WHERE _Document430_IDRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _DocumentChngR10960 WHERE _IDRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _DocumentJournal12795 WHERE _DocumentRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _DocumentJournal23761 WHERE _DocumentRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _DocumentJournal22967 WHERE _DocumentRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _DocumentJournal23751 WHERE _DocumentRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _DocumentJournal12946 WHERE _DocumentRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _Seq17875 WHERE _RecorderRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _Seq17867 WHERE _RecorderRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _Seq17869 WHERE _RecorderRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _Seq17864 WHERE _RecorderRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _SeqChngR29764 WHERE _RecorderRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
DELETE FROM _InfoRg13934 WHERE _Fld13935_RRRef = 0xa6dce0cb4ed5f61711e03b64f2ff7e57
И не забывайте, что при массированном удалении объектов база под SQL не уменьшается, а увеличивается за счет разрастания журнала транзакций (*.ldf). За этим надо следить и периодически сжимать, например командой DBCC SHRINKFILE
3. По ходу испытаний выяснилось, что метод Метаданные.НайтиПоПолномуИмени() очень медленно работает, причем только под 8.2. Под 8.3 видимо его оптимизировали. Но все равно пришлось его переписать по своему - см. Функция МетаданныеНайтиПоПолномуИмени()
В общем кому надо, пользуйтесь!
Вступайте в нашу телеграмм-группу Инфостарт
{kind=link}