Для чего это можно использовать? Например:
-
Менеджеры сдают в бухгалтерию первичные документы: оригиналы счетов-фактур, товарных накладных, актов, ТТН и т.д. Бухгалтерия проверяет оформление первичных документов и отмечает, что комплект документов сдан менеджером. Контроль сданных первичных документов лежит на бухгалтере и отнимает ресурсы. Решение: присоединенные по штрихкоду отсканированные документы можно контролировать, сформировав отчет.
-
При предоставлении документов по требованию, например, налоговой инспекции, бухгалтер спускается в архив и занимается поиском необходимых документов по нужному контрагенту за период. Расшивает папку и делает копию. Затем сшивает обратно и сдает в архив. Это занимает много времени и необходимо иметь либо копировальный аппарат рядом с архивом либо переносить копировальный аппарат к архиву. Решение: печать копий документов для инспекции можно выполнить из 1С, отобрав документы за период по нужному контрагенту.
Используемое ПО:
Платформа 8.3.6.2152
Конфигурация Управление торговлей, редакция 11.1 (11.1.10.94)
Сервер 1С x32 Linux Debian
Серыер СУБД x64 Postgresql 9.2
Необходимые пакеты на сервере 1С под Linux.
-
ImageMagick 6.7.7-10 2014-03-08 Q16 http://www.imagemagick.org. С помощью ImageMagick будем выполнять преобразования изображения.
Для установки ImageMagick выполнить команду в терминале sudo apt-get install imagemagick -
Zbarimg. http://zbar.sourceforge.net/. Чтение штрих-кодов на изображениях.
-
Tesseract OCR 0.10 https://code.google.com/p/tesseract-ocr/
С этим пакетом мы будем распознавать текст на изображении, если штрих-код по какой-либо причине не прочитался, попытаемся распознать номер документа.
Для установки выполнить команду в терминале sudo apt-get install tesseract-ocr. Для поддержки русского языка нужно скачать со страницы https://code.google.com/p/tesseract-ocr/downloads/list пакет Russian Language Data for Tesseract. В моем случае это https://tesseract-ocr.googlecode.com/files/tesseract-ocr-3.02.rus.tar.gz.
Качаем на сервер 1С, выполнив команду:
wget https://tesseract-ocr.googlecode.com/files/tesseract-ocr-3.02.rus.tar.gz
С помощью Midnight Commander копируем содержимое папки tessdata архива в папку /usr/share/tesseract-ocr/tessdata/. -
GPL Ghostscript 9.05 (2012-02-08) debian :-( http://www.ghostscript.com/
Будем конвертировать страницы из PDF файла в картинку JPG. Поставляется с системой.
Подготовка.
-
Создаем общий ресурс на файловом сервере и монтируем его к каталогу на сервере 1С, потому что на сервере под Linux мы можем использовать только локальные пути. Создадим каталог на сервере 1С:
mkdir /mnt/share/
И примонтируем общий ресурс:
mount -t cifs -o username=DOMAIN\\USER,password=PASSWORD,dir_mode=0777,file_mode=0777 //192.168.x.x/SHARE/ /mnt/share/
Выделенное нужно подменить на необходимые значения.
Для автоматического монтирования при перезагрузке сервера нужно эту команду прописать в файл /etc/rc.local.
-
Настроим сканер: сохранение файлов на общий ресурс и качество сканирования: цветное; 400х400 dpi; Текст; PDF; Качество высокое.
-
Сканируем документы. В моем примере документы сканируются комплектом по каждой реализации товаров. Соответственно в одном файле комплект к одной реализации товаров. Это счет-фактура, торг-12, акт, ТТН, доверенность. Счет-фактура кладется сверху, поэтому штрихкод мы будем считывать с нее.
Обработка в 1С.
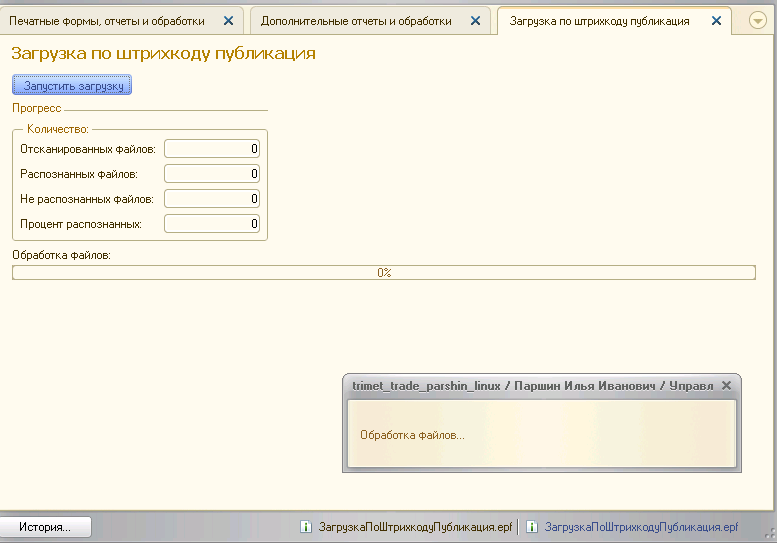
Обработка подключается как дополнительная. Реализован запуск фонового задания, чтобы пользователь мог выполнять другую работу. Также реализовано отображение прогресса. Полный код, считаю, приводить бессмысленно, т.к. можно посмотреть в БСП. В двух словах - как это сделано.
Запуск фонового задания и отображение прогресса позаимствованы из библиотеки стандартных подсистем (2.3.1.75). Запускается фоновое задание с помощью метода: ДлительныеОперации.ВыполнитьПроцедуруМодуляОбъектаОбработки. Пример реализации запуска фонового задания можно посмотреть в обработке БСП “ГрупповоеИзменениеРеквизитов”.
Отображение прогресса реализовано с помощью подключения обработчика ожидания и вызова метода ДлительныеОперации.СообщитьПрогресс и ДлительныеОперации.ПрочитатьПрогресс. Пример в обработке БСП “УдалениеПомеченныхОбъектов”.
Теперь об обработке отсканированных файлов.
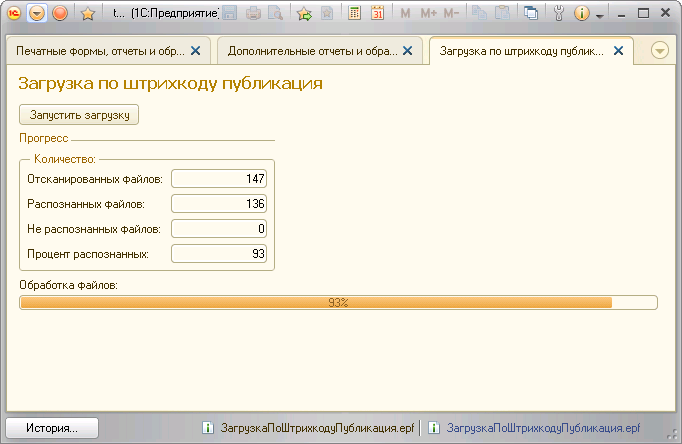
Все преобразования изображений происходят через временные файлы, которые после завершения обработки удаляются. Обработка происходит в цикле по массиву файлов, найденных в /mnt/share/.
Приступим.
Сконвертируем первую страницу pdf файла в jpg и будем работать уже с jpg файлом. Так удобнее.
gs -q -sDEVICE=jpeg -dBATCH -dNOPAUSE -dFirstPage=1 -dLastPage=1 -r400 -sPAPERSIZE=a4 -sOutputFile=out.jpg in.pdf
В 1с вызываем так:
ЗапуститьПриложение("gs -q -sDEVICE=jpeg -dBATCH -dNOPAUSE -dFirstPage=1 -dLastPage=1 -r400 -sPAPERSIZE=a4 -sOutputFile=" + ВремФайл + " " + Файл.ПолноеИмя, , Истина). Где ВремФайл - куда (jpg), а Файл.ПолноеИмя - откуда (pdf).
Параметры для gs. (Подробно тут: http://www.ghostscript.com/doc/9.06/Use.htm):
-q ‘quiet’ - уменьшает количество выводимых сообщений.
-sDevice - Выбор устройства, которое будет сохранять или отображать результат. Список доступных можно посмотреть в справке: gs --help.
-dBATCH -dNOPAUSE - Отключение интерактивного взаимодействия.
-dFirstPage=1 -dLastPage=1 - Страницы с и по.
-r400 - Разрешение изображения. Т.к. мы сканируем в 400DPI, то и конвертируем в такое же разрешение.
-sPAPERSIZE - Зададим формат листа.
-sOutputFile - Результирующий файл
Так как счет-фактура печатается в альбомной ориентации, а сканируется в портретной, то полученный jpg файл повернем на 90 градусов против часовой стрелки:
ЗапуститьПриложение("MAGICK_THREAD_LIMIT=1 convert -rotate -90 " + ВремФайл + " " + ВремФайл, , Истина);
MAGICK_THREAD_LIMIT - ставим ограничение на использование процессора чтобы не слишком сказывалось на работе пользователей в 1с.
-rotate -90 - поворот на 90 градусов против часовой стрелки.
Вырежем область из полученного изображения счета-фактуры, в которой останется только штрихкод и номер документа. Работа с меньшими изображениями происходит гораздо быстрее. Это на случай, если не удается прочитать штрихкод, то попробуем распознать номер документа.

ЗапуститьПриложение("MAGICK_THREAD_LIMIT=1 convert -strip " + ВремФайл + " -crop 1200x450+200+80 +repage " + ИмяВременногоФайлаИзображенияКроп, , Истина);
-strip - не сохраняем данные профиля изображения.
-crop - область для вырезки. 1200х450 это размер вырезаемого изображения в пикселях. +200+80 это координаты, откуда отсчитывать размер вырезаемого изображения. Эти значения привязаны к разрешению изображения. Область для вырезки нужно взять с небольшим запасом, т.к. документы не всегда ровно захватываются податчиком на сканере или пользователь не аккуратно положит их.
+repage - После вырезки размер канваса оригинального изображения не изменяется. Этим параметром устанавливаем размер канваса к вырезанному размеру. Это как shrink БД.
Приступим к чтению штрихкода. Тут все просто. Zbarimg читает штрихкод и выводит результат в xml-файл.
ИмяВременногоФайлаXML = ПолучитьИмяВременногоФайла("xml");
ЗапуститьПриложение("zbarimg -q --xml " + ИмяФайлаИзображения + " > " + ИмяВременногоФайлаXML, , Истина);
Через ЧтениеXML считываем распознанный штрихкод из xml файла. Если считать штрихкод не удалось, например, плохое качество печати или сканера, присутствует шум на изображении, то попробуем уменьшить негативные факторы. Тут к нам на помощь приходит imagemagick с параметром motion-blur. Он сглаживает изображение сдвигая его под указанным углом. Подробнее тут http://www.imagemagick.org/Usage/blur/. Мы будем двигать вертикально.

ЗапуститьПриложение("MAGICK_THREAD_LIMIT=1 convert -strip -motion-blur 10x30-90 " + ИмяВременногоФайлаИзображенияКроп + " " + ИмяВременногоФайлаИзображенияБлур, , Истина);
-motion-blur radiusxsigma+angle - РадиусXОтклонение-Угол. С этими параметрами нужно экспериментировать.
И снова попытаемся считать штрихкод с помощью zbarimg из ИмяВременногоФайлаИзображенияБлур. Если считать не получилось, то пробуем распознать номер документа с помощью Tesseract OCR. Сначала вырежем область номера документа из изображения чтобы уменьшить количество распознаваемых символов и как следствие различного мусора в тексте.
![]()
ЗапуститьПриложение("MAGICK_THREAD_LIMIT=1 convert -strip " + ИмяВременногоФайлаИзображенияКроп + " -crop 800x150+400+300 +repage " + ИмяВременногоФайлаИзображенияКроп, , Истина);
Сконвертируем в grayscale. Так лучше отрабатывает tesseract.
ЗапуститьПриложение("MAGICK_THREAD_LIMIT=1 convert " + ИмяВременногоФайлаИзображенияКроп + " -colorspace gray " + ИмяВременногоФайлаИзображенияКроп, , Истина);
И пробуем распознать номер
ЗапуститьПриложение("tesseract " + ИмяВременногоФайлаИзображенияКроп + " " + ИмяВременногоФайлаТекст, , Истина);
ИмяВременногоФайлаТекст - Текстовый файл для вывода результатов.
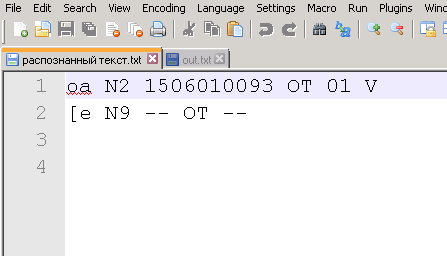
И тут мы должны найти в тексте номер документа. Я сделал так. Считываем построчно текст из файла. Каждую строку разбиваем на массив подстрок и проверяем элемент массива на длину. Номера счетов-фактур у нас содержат дату и номер. например: ТР1507250003. Если длина подходит, то пробуем найти документ по номеру.
Контроль присоединенных файлов можно выполнить с помощью отчета, который выбирает документы, если в присоединенных файлах отсутствует файл содержащий в наименовании определенный текст. Например “Комплект документов”. Это наименование мы задаем при присоединении файла к документу.
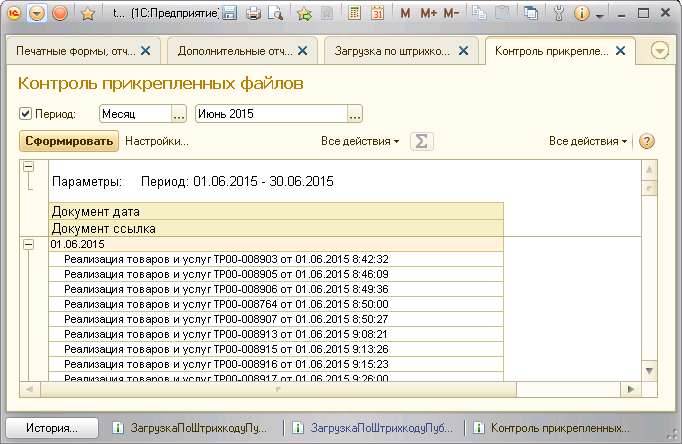
Предлагаемая обработка без доработок подойдет не каждому, т.к. многое зависит от качества принтера, сканера и нумерации документов. Поэтому смотрите идеи и дорабатывайте под себя. Нужно отметить, что процент считываемых штрихкодов очень высок! И вообще переходите на электронный документооборот.
Вступайте в нашу телеграмм-группу Инфостарт