Позволяет тестировать рабочие процессы на кластере серверов с любым количеством рабочих серверов. Получать сводный отчет по основным показателям за период тестирования.
Файлы
ВНИМАНИЕ:
Файлы из Базы знаний - это исходный код разработки.
Это примеры решения задач, шаблоны, заготовки, "строительные материалы" для учетной системы.
Файлы ориентированы на специалистов 1С, которые могут разобраться в коде и оптимизировать программу для запуска в базе данных.
Гарантии работоспособности нет. Возврата нет. Технической поддержки нет.
Вы можете заказать платную доработку или адаптацию этой разработки под вашу конфигурацию на «Бирже заказов».
0% комиссии — оплата напрямую исполнителю;
Исполнители любого масштаба — от отдельных специалистов до команд под проект;
Прямой обмен контактами между заказчиком и исполнителем;
Безопасная сделка — при необходимости;
Рейтинги, кейсы и прозрачная система откликов.
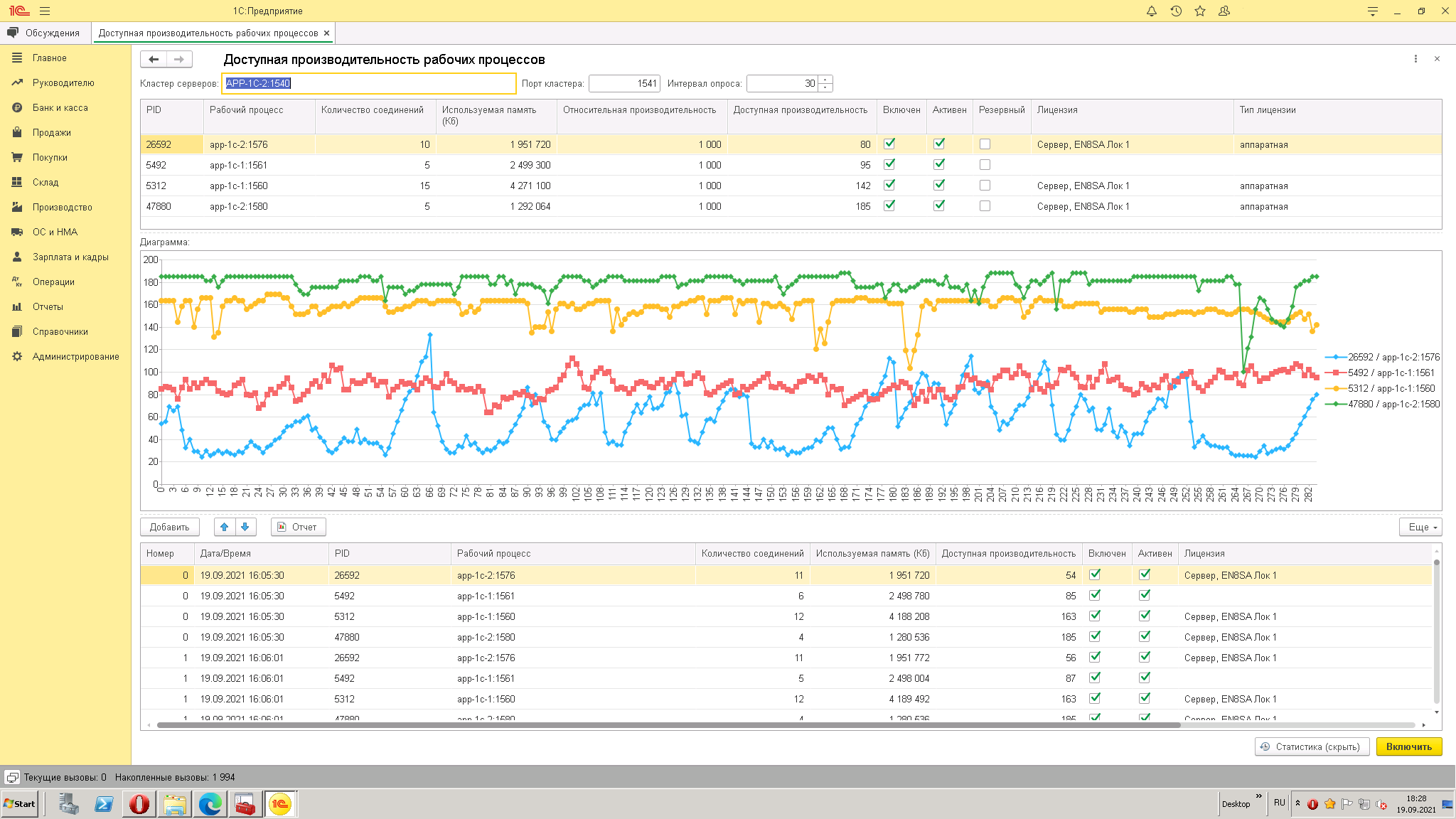
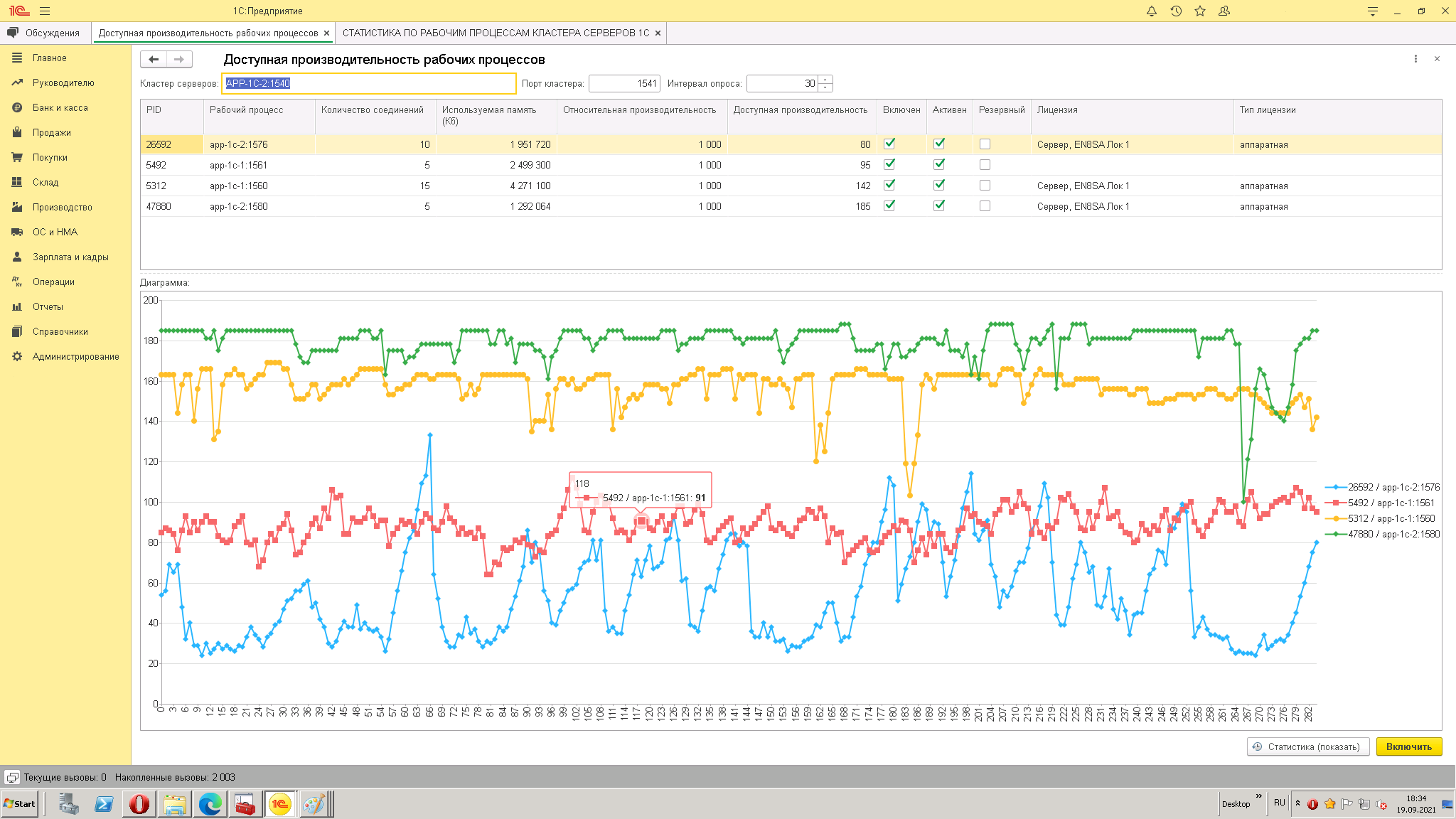
Все настройки выставляются автоматически, интервал опроса можно изменять (например, увеличить при наблюдении суточном и более).
Хороший помощник при анализе высоко нагруженных серверов с максимальными пиковыми нагрузками в периодах.
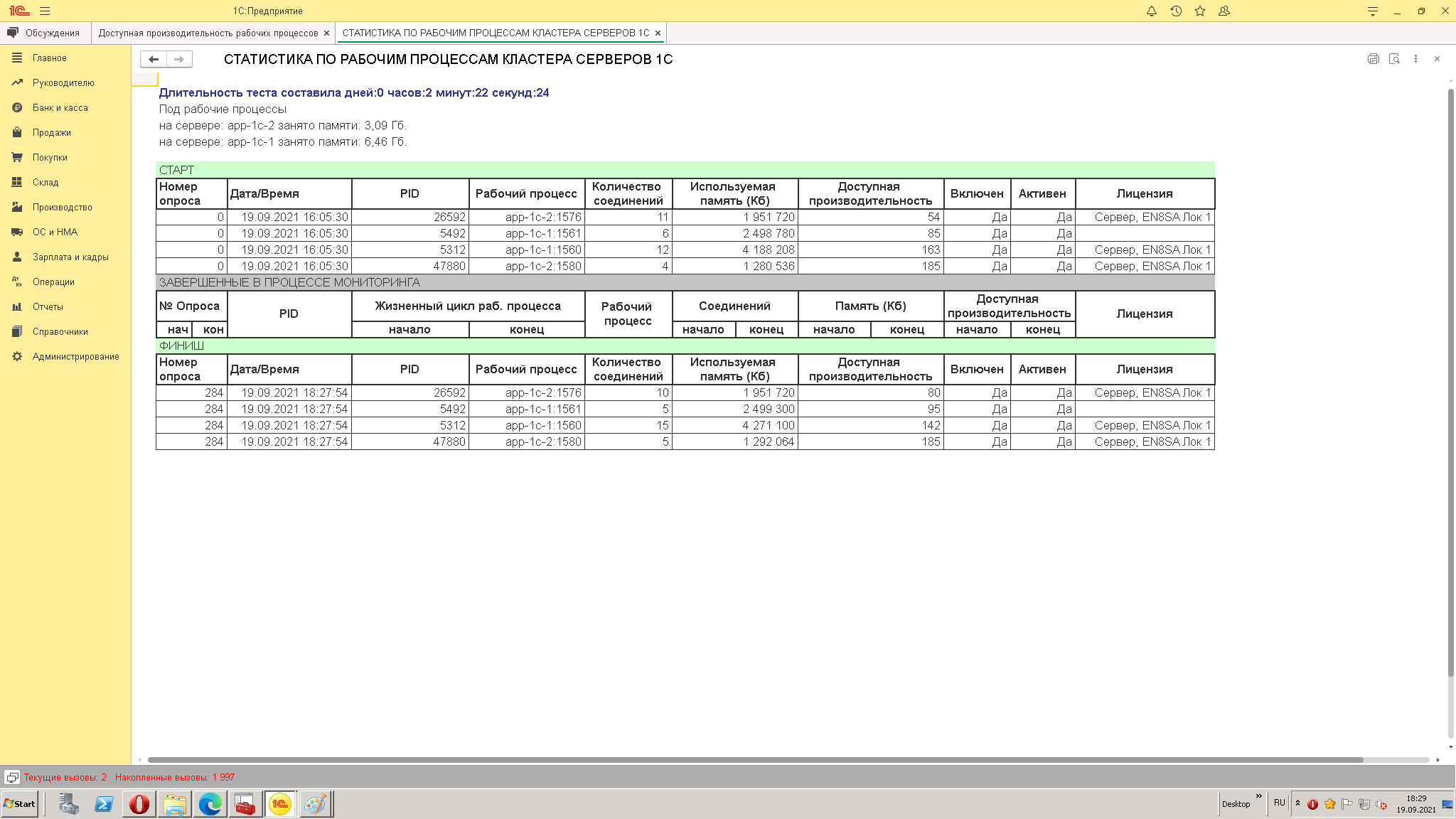
Добавлена возможность сохранять статистику и формировать по ней отчет. Исправлен вывод графика производительности при завершении процессов (или создании новых) в процессе мониторинга.
Инструмент представляет собой обработку для проведения свёртки или обрезки баз данных. Работает на ЛЮБЫХ конфигурациях (УТ, БП, ERP, УНФ, КА и т.д.). Поддерживаются серверные и файловые базы, управляемые и обычные формы. Может выполнять свертку одновременно в несколько потоков. А так же автоматически, без непосредственного участия пользователя.
Решение в Реестре отечественного ПО
Расширение позволяет без изменения кода конфигурации выполнять проверки при вводе данных, скрывать от пользователя недоступные ему данные, выполнять код в обработчиках. Не изменяет данные конфигурации, легко устанавливается практически на любую конфигурацию на управляемых формах.
Роли… Вы тратите много времени и сил на подбор ролей среди около 2400 в ERP или 1500 в Рознице 2, пытаясь понять какими правами они обладают? Вы все время смотрите права в конфигураторе или отчетах чтоб создать нормальные профили доступа? Вы хотите наглядно видеть какие права дает профиль и редактировать все в простом виде? А может хотите просто указать подсистему и дать права на просмотр и добавление на объекты и не лезть в дебри прав и чтоб обработка сама подобрала нужные роли? Все это теперь стало возможно! Обновление от 17.04.2026, версия 1.4.1, работает в 1С:ФРЕШ!
Расширение «Оперативное проведение» в 4 раза уменьшает время проведения документов и закрытия месяца. Является комплексным решением проблем 62 и 60 счетов. Оптимизирует проведение при включенной функциональной опции «Раздельный учет НДС». Используется в более 10 организациях уже 2 года. Совместимо с конфигурацией Бухгалтерия 3.0 (+КОРП).
Данная обработка позволит Вам легко и просто, а главное - быстро, выполнить сравнение данных между ЛЮБЫМИ базами (и РИБ, по правилам конвертаций) по контрольным суммам выбранных объектов баз 1С, работающих на платформах 8.3 и выше. Удобный и понятный интерфейс в виде "мастера". Высокая скорость сравнения достигается за счет специального алгоритма расчета контрольной суммы объекта/записи и сравнения по данным суммам объектов 2х баз через файл. Имеется возможность выбора реквизитов, по которым система будет сравнивать объекты. Сравнение количества записей в движениях документов, возможность сравнивать данные по правилам конвертации и не только! Выбор объектов конфигурации для КАЖДОГО узла в отдельности с индивидуальным отбором для каждого объекта конфигурации, работа с FTP, сохранение или загрузка настроек, сохранение или загрузка результата сравнения, регистрация на обмен объекта и его движений. (Обновление от 12.11.2024, версия 2.2-2.5)
Решение представляет собой набор из 6 обработок для 1С по удалению организаций и справочников из базы по фильтрам, документов по фильтрам, универсальное сжатие данных, очистка битых движений регистратора, удаление устаревших регистров сведений, удаление устаревших документов "Электронное письмо входящее" и "Электронное письмо исходящее"
Конфигурация Комплексная автоматизация 1.1 (и УПП 1.3 тоже) хранит файлы и изображения в справочнике Хранилище дополнительной информации в реквизите Хранилище типа ХранилищеЗначений. Та же история с ВложениямиЭлектроннойПочты. Но при этом присоединенные файлы в Электронном документообороте хранит в томах на диске. Эта доработка позволяет использовать стандартный механизм хранения файлов, изображений и вложений электронных писем в томах на диске. При этом можно разделить тома хранения по объектам конфигурации.
Здравствуйте. Кроме красивых графиков не понятно назначение обработки.
Приведите пожалуйста пример или лучше некую методику использования обработки для выявления и затем устранения узких мест.
Буду очень благодарен...
1. Запускаете обработку с установленными значениями по умолчанию (в большинстве случаев, кроме тех что мониторят несколько дней подряд. Тогда нужно увеличить интервал)
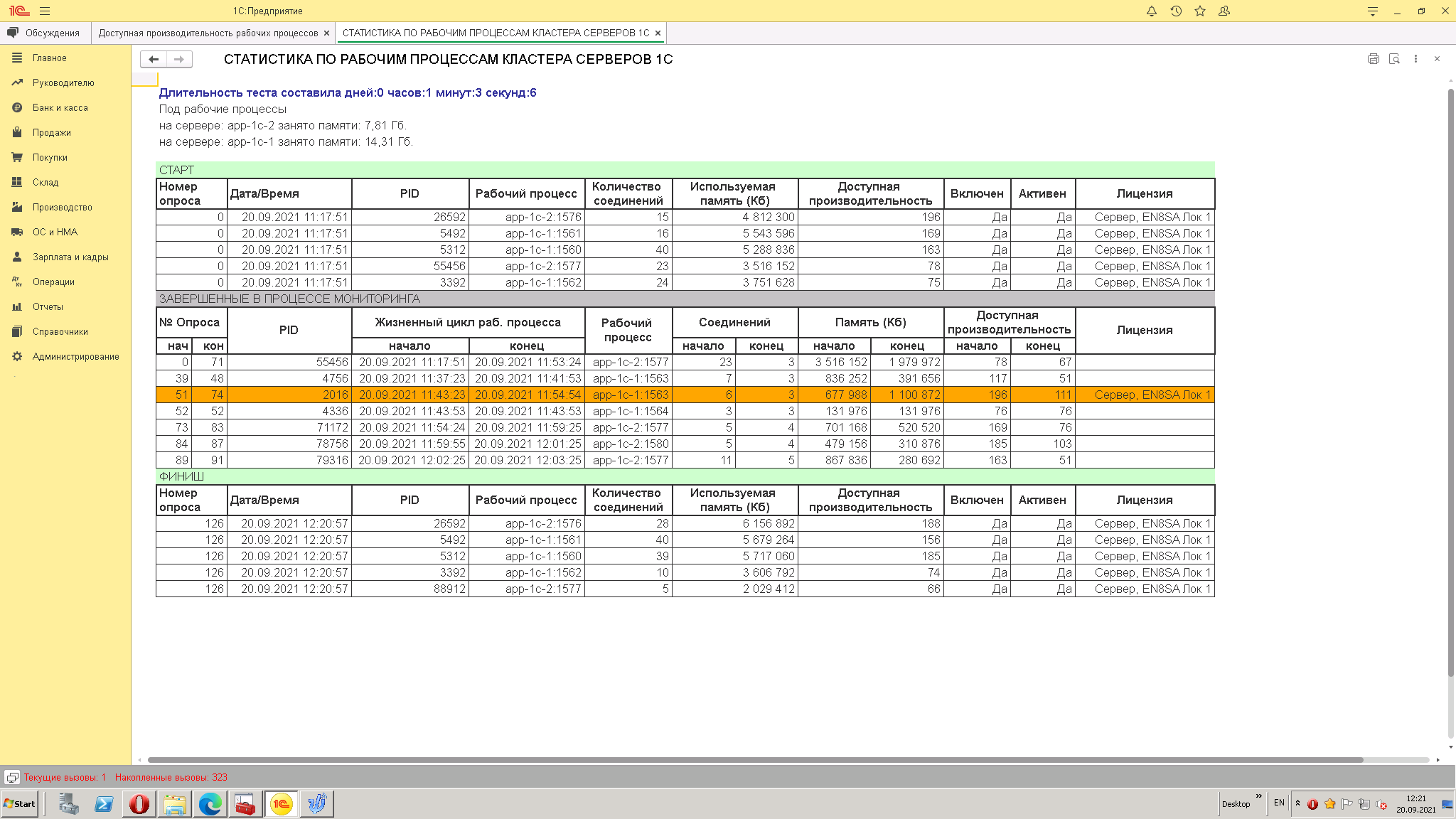
2. Через нужный вам отрезок времени формируете отчет и смотрите основные показатели
А) Память занимаемую рабочими процессами на серверах кластера
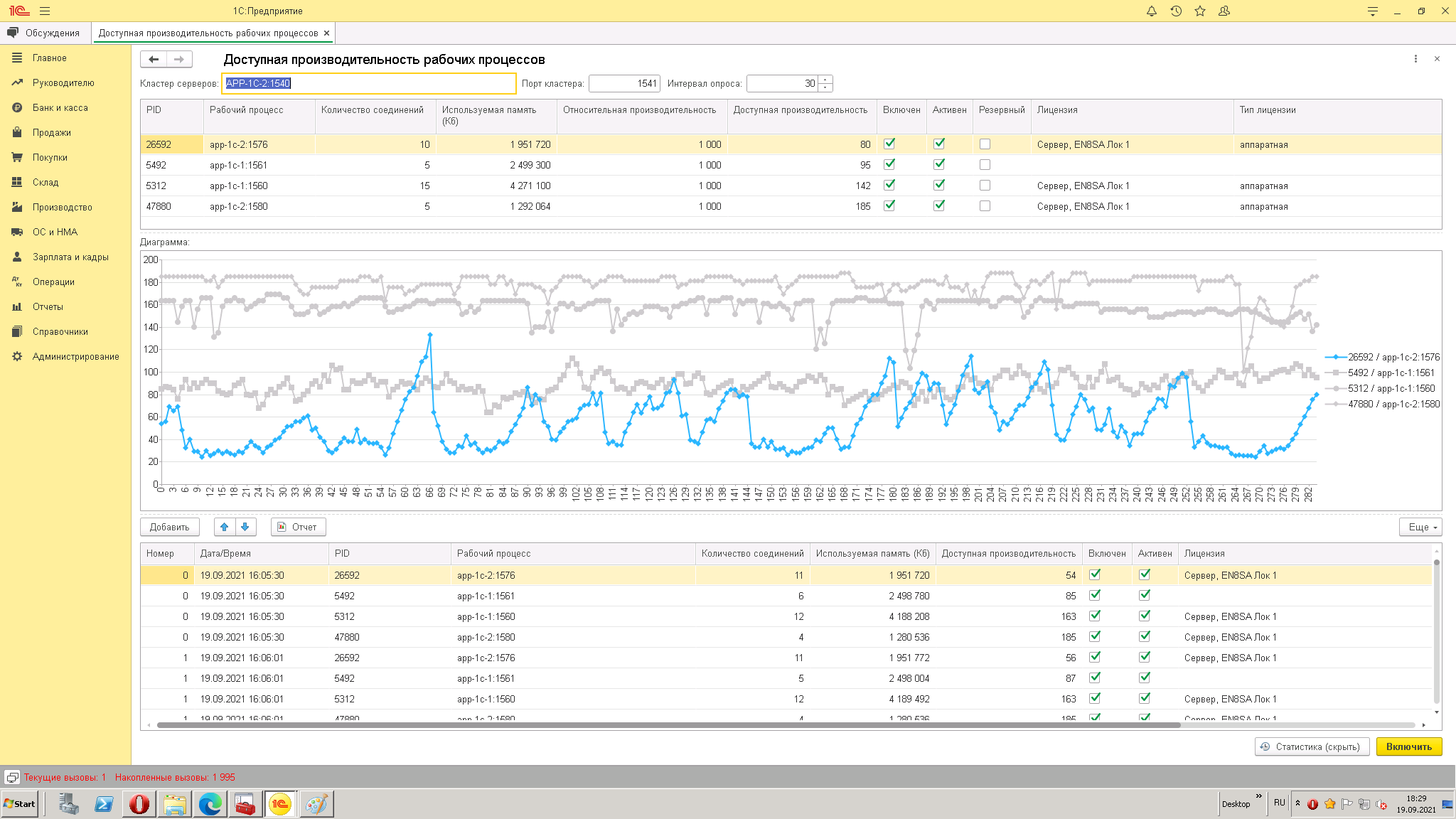
Б) Завершенные в процессе мониторинга рабочие процессы. Оранжевым маркером будут выделены те, на которых были клиентские соединения (т.е. это потенциально аварийная ситуация)
В) Сравнение состояния РП на начало теста и на его завершение
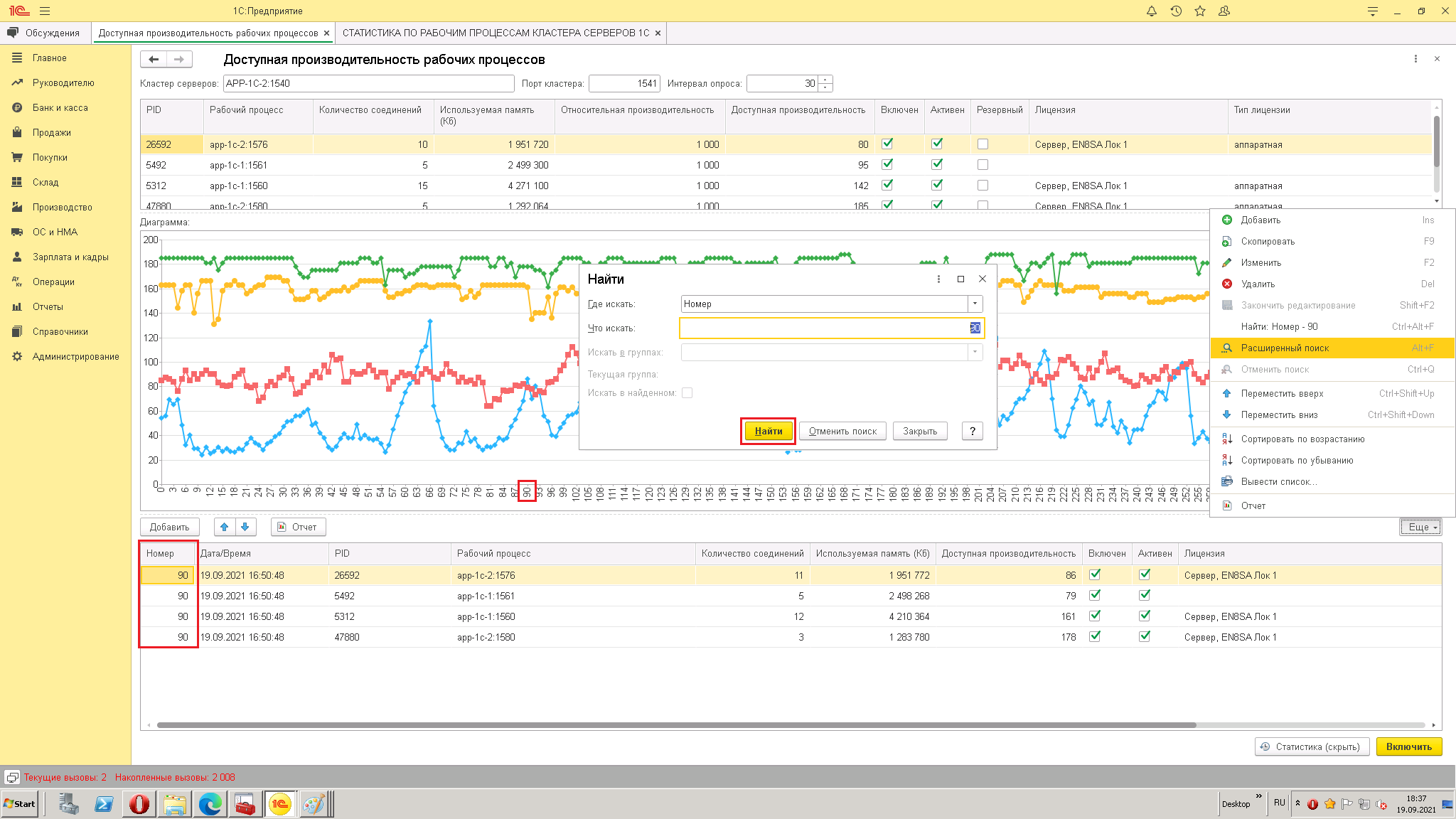
3. Делаете выводы по нижним пикам производительности, смотрите отметку времени в таблице статистика и уже по ЖР смотрите причину провала производительности (или счетчики на серверах операционной системы и её журнал событий)
Пардон конечно за поздний ответ, но думаю и другим пригодится в контексте обновления обработки.






{kind=link}