







{kind=link}
Что такое полнотекстовый поиск, большинство специалистов знает и так, поэтому отдельно описывать это не будем, у MS SQL возможностей по сравнению с поиском 1С не меньше. Есть довольно интересная возможность – поиск с использованием синонимов или исключение определенных слов из поисковых выражений (стоп-листы). Файл полнотекстового поиска 1С хранится на сервере приложений, полнотекстовый поиск – есть часть базы данных. Полнотекстовый поиск SQL, по личному опыту, быстрее работает в случае, когда вам нужно найти большое количество слов, которые входят в искомую строку. Например, по строке неограниченной длины, когда длина строки может достигать 3-4х тыс символов и количество строк от 300 тыс, полнотекстовый поиск SQL работает существенно быстрее поиска 1С, если мы ищем строку из минимум 5 слов.
Полнотекстовый поиск SQL похож на оператор LIKE, однако по утверждению MS, LIKE работает медленнее по большому количеству неструктурированных данных, да и имеет существенно меньше возможностей для поиска, так же полнотекстовый поиск может индексировать не только строковые поля.
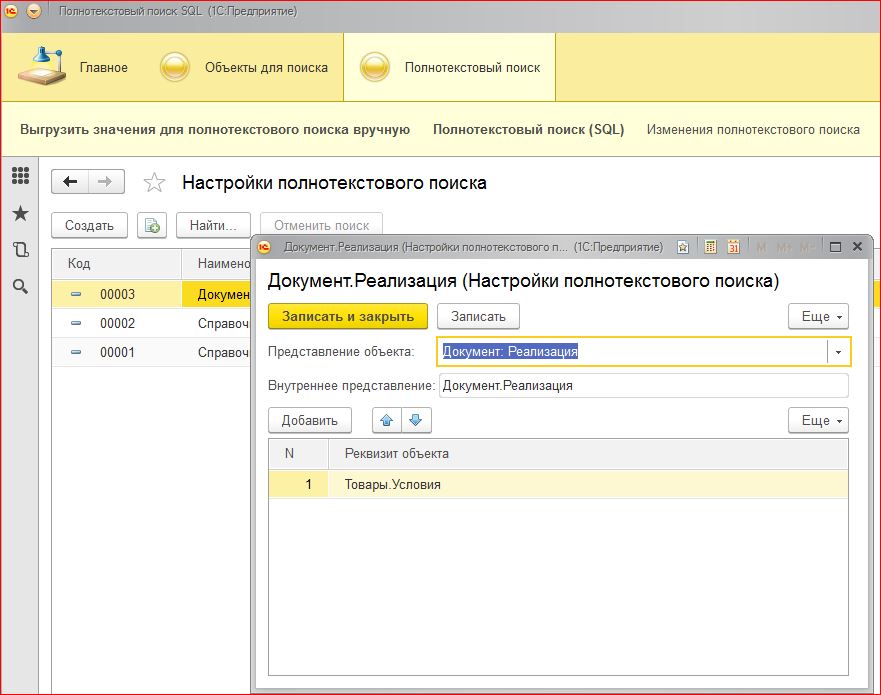
Основная идея работы – вынесение данных, которые подлежат полнотекстовому индексированию во внешнюю БД, по этой БД создается индекс с автоматическим обновлением. Во внешней базе содержатся внутренние идентификаторы объектов базы, тип и вид объекта метаданных, имя реквизита и номер строки для документов, что позволяет однозначно идентифицировать объект и свойство, которому принадлежит хранимая строка. В базе 1С есть план обмена, который регистрирует изменения в объектах и регламентное задание, которое помещает значения нужных свойств. Какие объекты и какие их реквизиты нужно индексировать – хранится в справочнике НастройкиПолнотекстовогоПоиска. Так же в базе есть обработка, которая формирует поисковый запрос на языке TSQL и отправляет его на сервер БД, затем она получает результат и, на основе хранимых во внешней таблице данных, ассоциирует строки результата с объектами в базе 1С, что в данном примере используется для поиска цен в документах Реализация и регистре сведений с ценами для справочника Номенклатура.
К публикации присоединены 2 файла: скрипт создания БД на MS SQL и файл выгрузки БД 1С 8.3.
Порядок работы:
- Создаем скриптом базу данных для поиска. Рекомендую использовать скрипт, т.к. он создает и таблицу в БД, структура которой нужна для базы 1С из нашего примера. Скрипт нужно будет подправить в части пути к файлам на SQL сервере.
- Переводим свойство базы (базы MS SQL) Collation в Cyrrilic_CI_AS, как у всех БД 1С.
- Создаем новый логин в MS SQL с авторизацией SQL и делаем его владельцем (dbo) для нашей базы.
- Разворачиваем БД 1С.
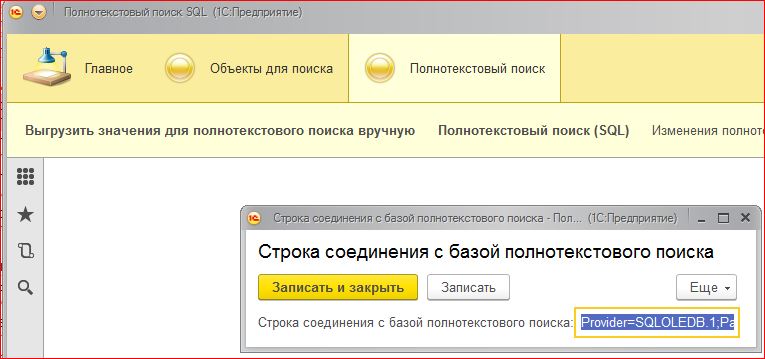
- Настраиваем в ней строку соединения с внешней базой данных Полнотекстовый поиск \ Сервис \ Строка соединения с базой полнотекстового поиска. Строка соединения будет иметь вид: Provider=SQLOLEDB.1;Password=Пароль;Persist Security Info=True;User ID=Пользователь;Initial Catalog=ПолнотекстовыйПоиск;Data Source=СерверБД. Где Пароль и Пользователь – данные учетки, которую мы создали в MS SQL, СерверБД – сервер MS SQL и ПолнотекстовыйПоиск – имя внешней БД с данными для полнотекстового индексирования.
- Теперь зайдем в Объекты для поиска \ Создание тестовых данных. Эта обработка может создать тестовые данные или зарегистрировать в плане обмена уже имеющиеся. В скачанной вами копии базы данные есть, поэтому выберем кнопку Перерегистрировать.
- Зайдем в Полнотекстовый поиск \ Выгрузить значения для полнотекстового поиска вручную. Эта команда выгрузит во внешнюю базу данных все объекты зарегистрированные в специальном плане обмена согласно справочнику НастройкиПолнотекстовогоПоиска.
- Теперь самое время зайти в нашу таблицу и проверить, попали ли в нее данные из базы 1С. Если таблица заполнена, значит вы все сделали верно, если нет – нужно проверять, почему это не произошло.
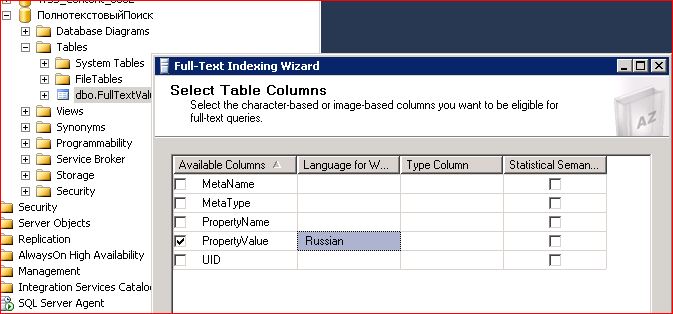
- Теперь создадим полнотекстовый индекс и хранилище для него в MS SQL. Для этого в MS SQL management studio развернем структуру созданной БД и в контекстном меню нашей единственной таблицы выберем пункт Full Text Index \ Define full text index. В качестве уникального индекса нужно указать созданный скриптом PK_FullTextValues, в качестве индексируемой колонки – PropertyValue, от автоматической регистрации изменений откажемся и установим Track changes в Manual, для нашей работы авторегистрация не нужна, а в дальнейшем – сами решите, как вам пересчитывать полнотекстовый индекс. Далее укажите имя каталога для хранения полнотекстовых данных. Регламенты для заполнения тоже указывать не нужно. В результате в вашей базе в Storage \ Full text catalog должен появиться объект, имя которого вы только что задали.
- Теперь заполним полнотекстовый индекс, для этого в контекстном меню нашей базы выберем Full Text Index \ Start Full Population.
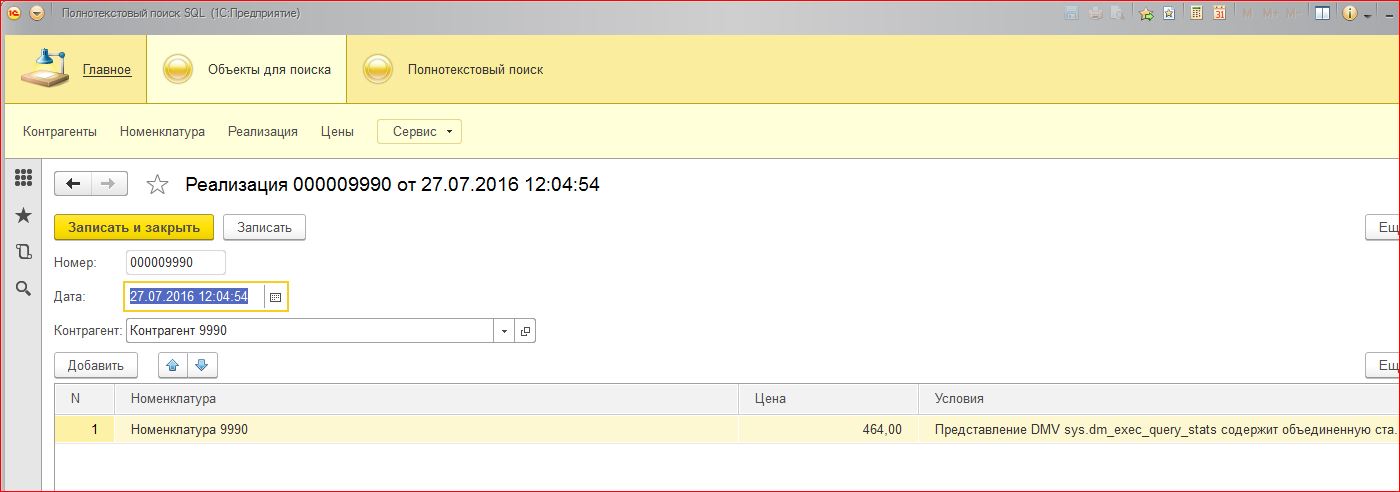
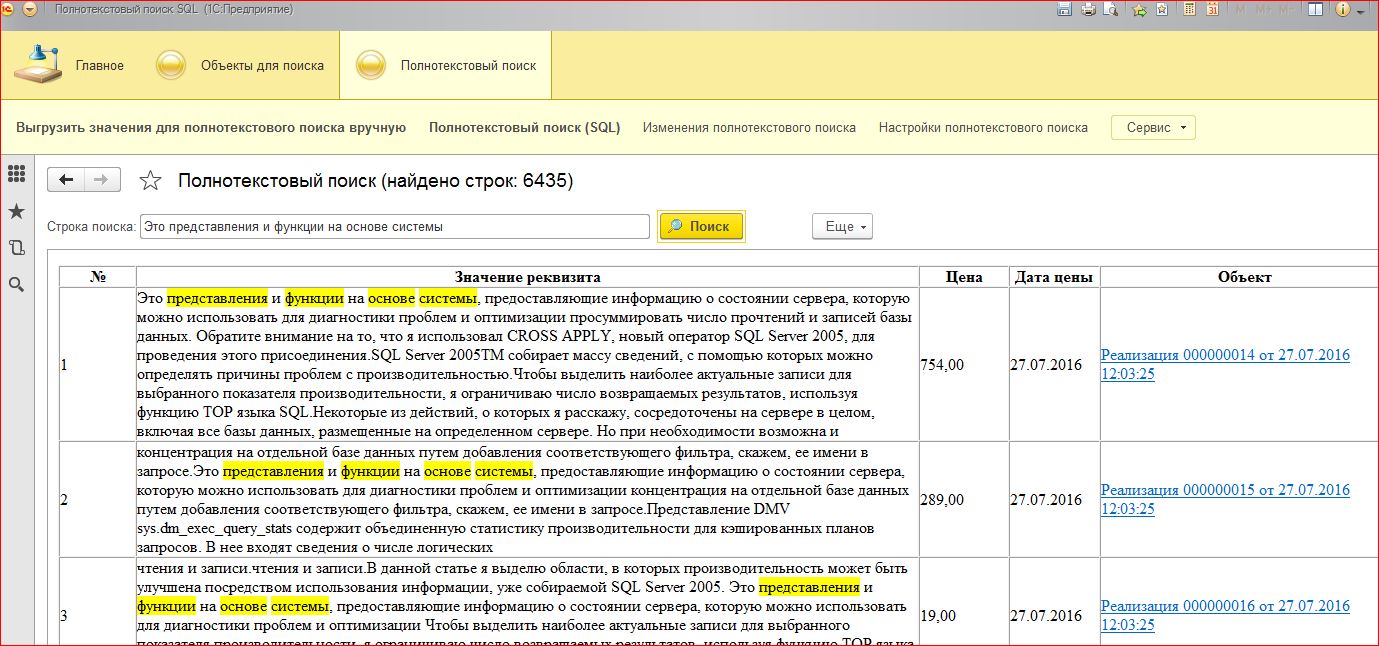
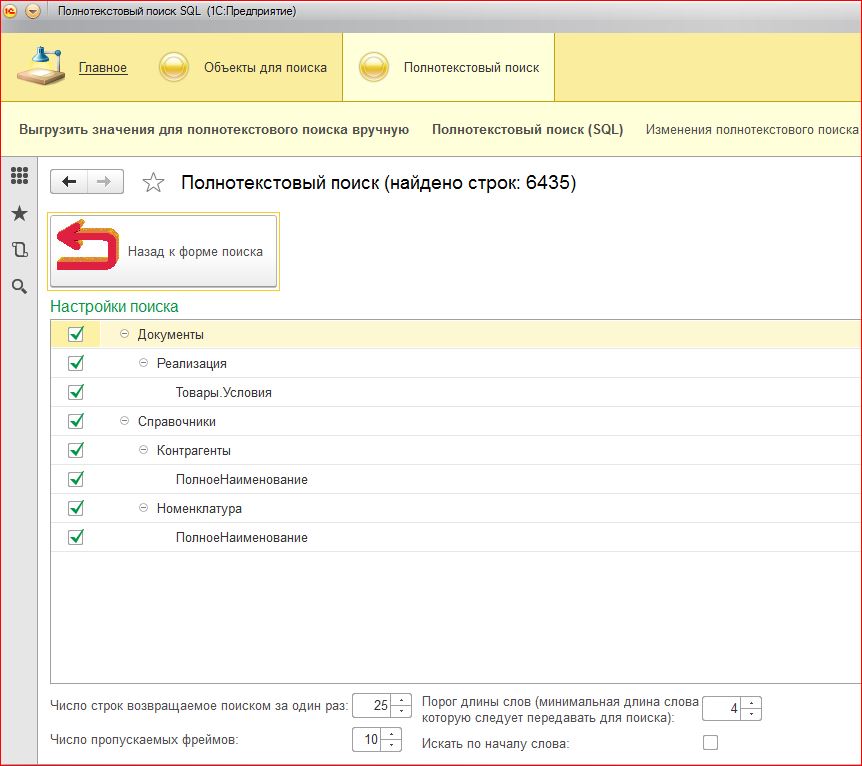
- Теперь перейдем в нашей базе 1С в Полнотекстовый поиск \ Полнотекстовый поиск (SQL) и введем часть строки, скопированной из табличной части реализации или полного наименования номенклатуры. Обработка выведет данные в формате таблицы HTML с подсветкой слов, которые она нашла. Так же обработка выдаст цены на номенклатуру, из реализаций или регистра с ценами.
- Обработку поиска можно настраивать, для этого нужно зайти в Еще \ Настройки полнотекстового поиска. На этой закладке можно настроить предметную область поиска, число записей на страницу, интервал пропуска сразу нескольких страниц при перелистывании и минимальную длину слова для поиска.
Все, удачных экспериментов!
Требования к ПО:
- 1С 8.3.8
- MS SQL 2012. (можно использовать и более ранние варианты, но тогда в обработке полнотекстового поиска придется заменить Offset и Fetch next на альтернативные выборки, например с использованием функции Count).
Пример настройки полнотекстового поиска скриптаим можно посмотреть тут: http://www.sql.ru/faq/faq_topic.aspx?fid=426
Вступайте в нашу телеграмм-группу Инфостарт