



{kind=link}
Подпоследовательности
Пусть у нас есть последовательности АБВГДЕЖЗ и АВБГДЖ. Общая подпоследовательность это например АГЖ, она есть в обеих последовательностях: АБВГДЕЖЗ и АВБГДЖ. При этом АБВ не входит в АВБГДЖ - не тот порядок букв, и поэтому АБВ не общая подпоследовательность для АБВГДЕЖЗ и АВБГДЖ. Общих подпоследовательностей много, среди них есть самые длинные - наибольшие.
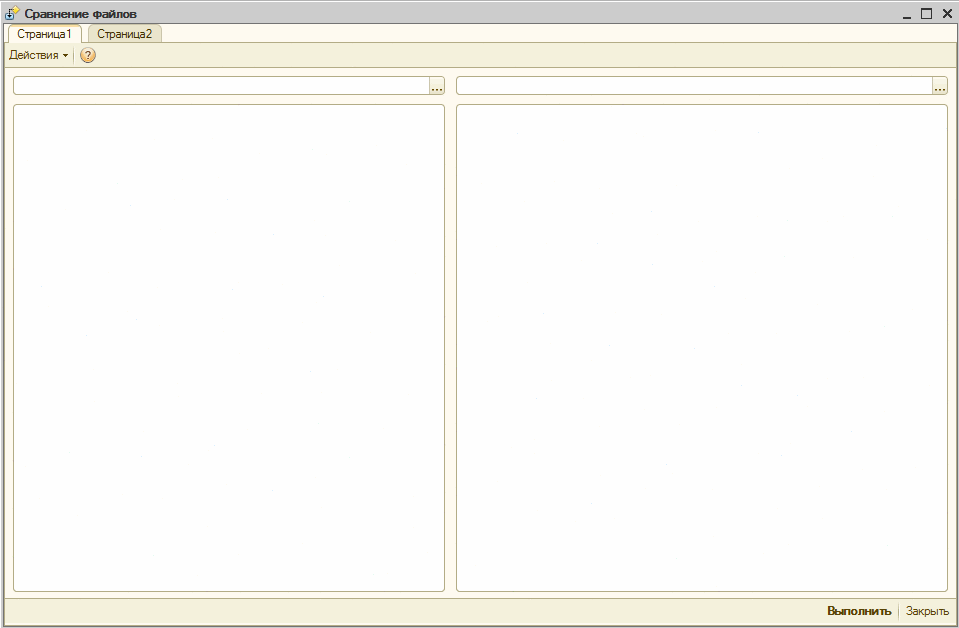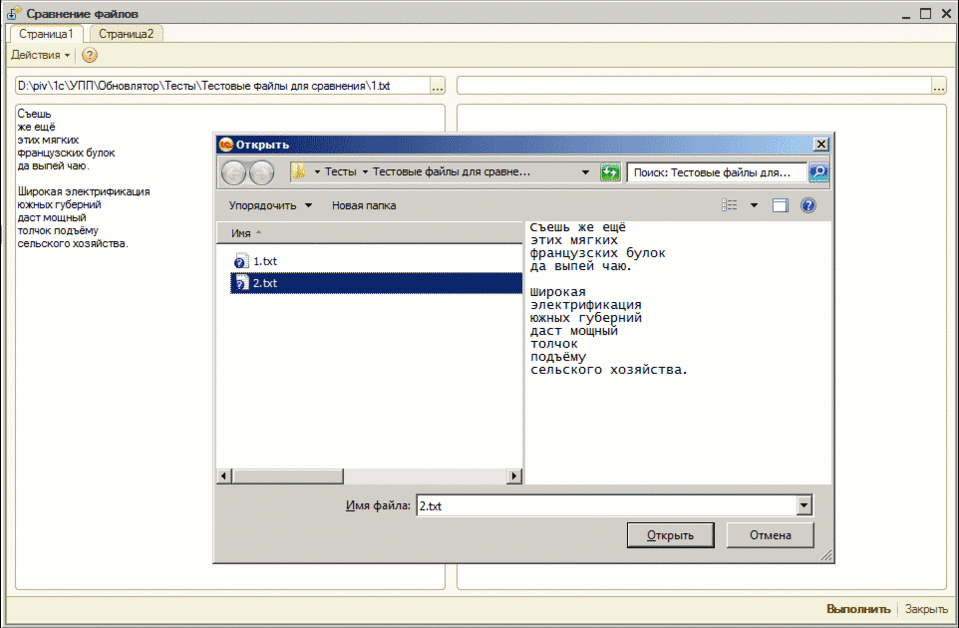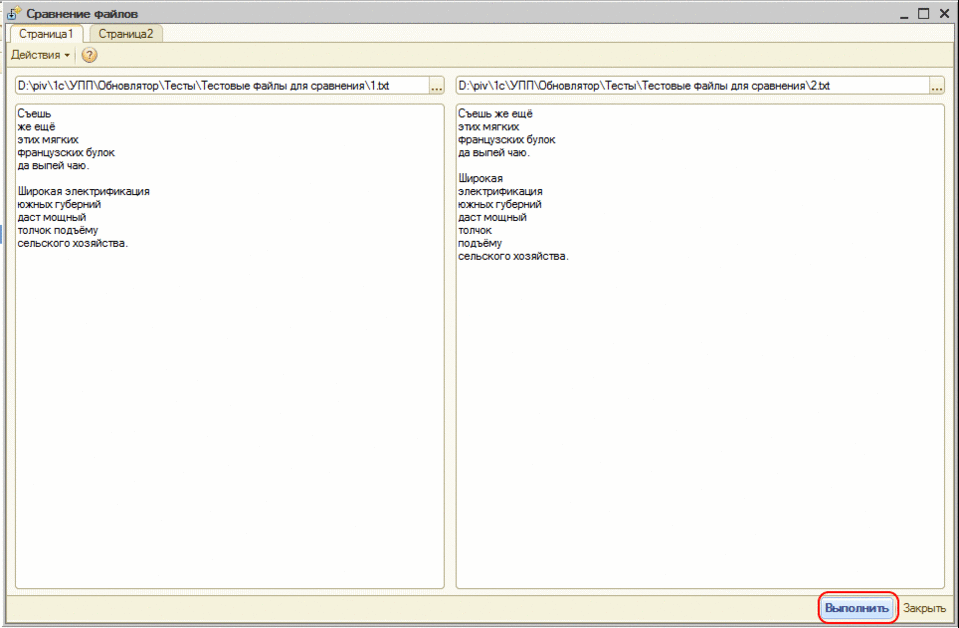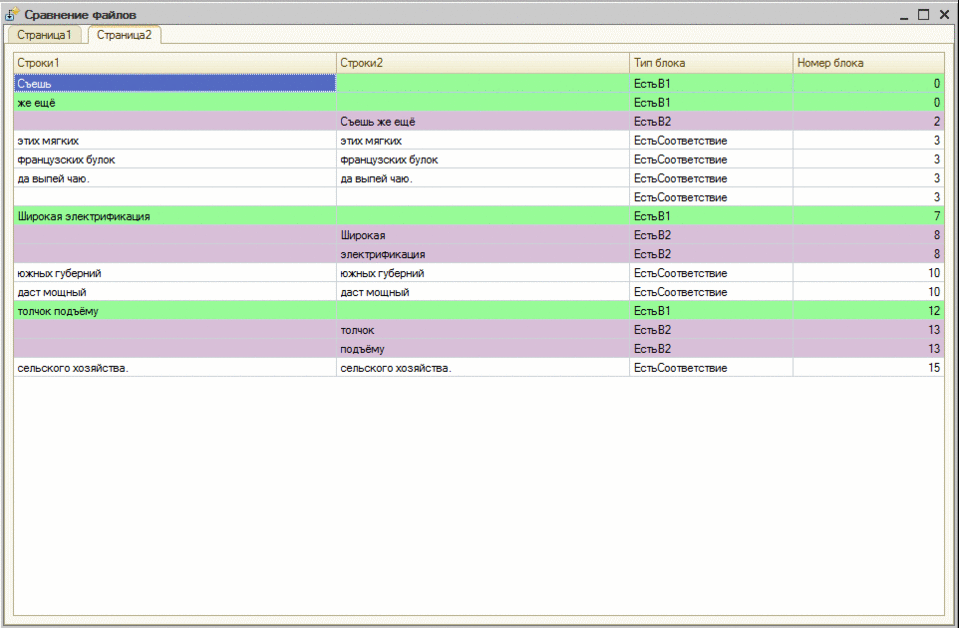
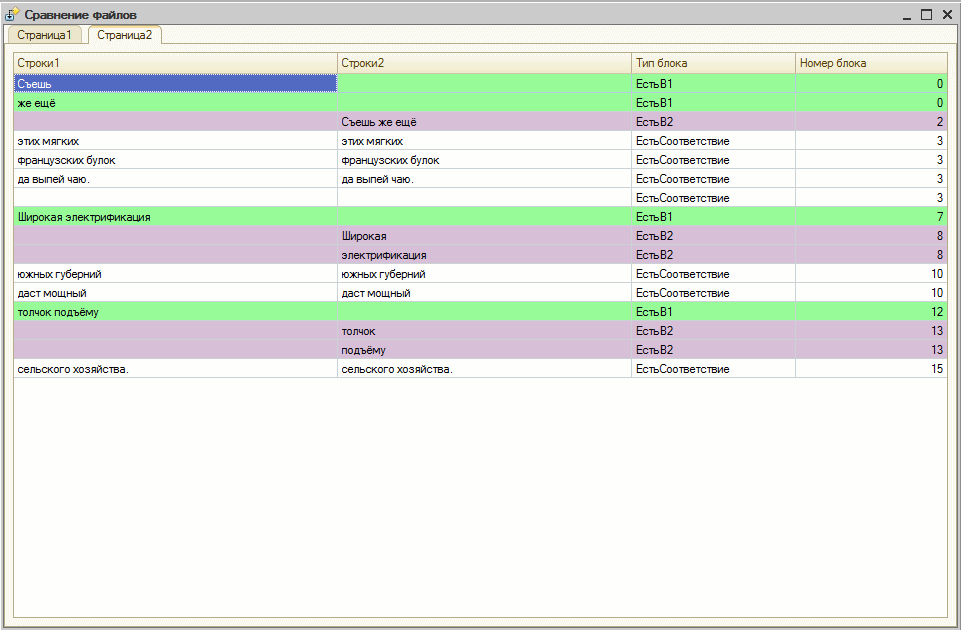
Когда мы смотрим на сравнение двух текстов, фактически мы смотрим на наибольшую общую подпоследовательность строк (сопоставленные строки), а добавленные/удаленные - это те что не вошли в неё.
Алгоритмы и понятия я почерпнул из http://foxford.ru/wiki/informatika/naibolshaya-obschaya-podposledovatelnost.
Подготовка
Перед тем как сравнить тексты, их разбивают на строки и хешируют. За функцию хеша спасибо //infostart.ru/public/100845/, возможно встроенная в платформу SHA256 была бы быстрее, но в этой публикации использование очевидное, а узкое место в быстродействии всей обработки не здесь.
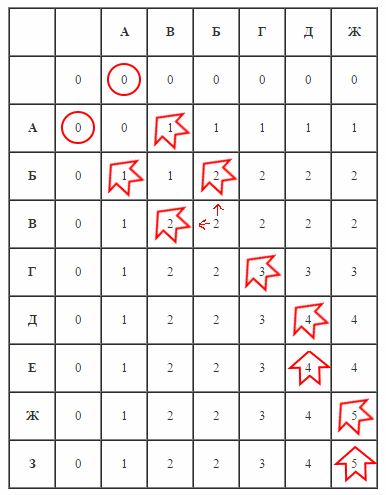
Потом строится таблица длин подпоследовательностей такого вида:
|
|
А |
В |
Б |
Г |
Д |
Ж |
|
|
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
А |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
|
Б |
0 |
1 |
1 |
2 |
2 |
2 |
2 |
|
В |
0 |
1 |
2 |
2 |
2 |
2 |
2 |
|
Г |
0 |
1 |
2 |
2 |
3 |
3 |
3 |
|
Д |
0 |
1 |
2 |
2 |
3 |
4 |
4 |
|
Е |
0 |
1 |
2 |
2 |
3 |
4 |
4 |
|
Ж |
0 |
1 |
2 |
2 |
3 |
4 |
5 |
|
З |
0 |
1 |
2 |
2 |
3 |
4 |
5 |
Потом надо от последней ячейки вернуться к слою с нолями шагая либо в стороны на клетки с таким же значением, либо по диагонали если пришли в тупик.

Обратите внимание, что на пересечении Б и В получилась развилка - выбор зависит от того, как написан алгоритм. Дав возможность менять выбор пути при построении дерева можно сделать удобнее сравнение модулей*
*Сейчас пример построить не смог, но раньше встречал - когда добавленный код перемешивался с типовым т.к. встречались одинаковые куски.
Реализация всего этого в приложенной обработке. Надеюсь, вам было также интересно узнать всё это, как и мне.
Быстродействие
Конечно, использовать 1с в качестве числодробилки - не самая лучшая идея и быстродействие ожидаемо проигрывает существующим утилитам, но некоторая оптимизация была проведена. Во первых оказалось плохой идеей использовать для хранения таблицы таблицу значений и обращаться к колонкам по имени - после замены её на двумерный массив всё ускорилось. Во вторых - запись циклов одной строкой дала ещё двойное ускорение. Сейчас файлы длинной 1000 строк сравниваются у меня примерно за 3 секунды. Вероятно, можно улучшать этот показатель, но для моих дальнейших задач этого хватает. Для файлов большей длины используйте её с осторожностью.
Вступайте в нашу телеграмм-группу Инфостарт