

{kind=link}
Здравствуйте, друзья!
Наверняка многие из вас слышали историю о замене лиц в видеороликах с использованием нейронных сетей. История получила бурное развитие, когда один из пользователей Reddit сделал программу, позволяющую делать deepfakes (видео с измененными лицами) без глубоких знаний в области машинного обучения и программирования.
Я решил провести собственный эксперимент.
Довольно быстро пришло понимание, что конфигурация компьютера довольно скромна для поставленной задачи, особенно видеоадаптер (NVidia GT730). Именно поэтому каждый просчет был на вес золота. Впервые удалось запустить процесс тренировки нейронной сети на CPU. Методом проб и ошибок была подобрана необходимая конфигурация настроек.
Однако по субъективным представлениям (точные замеры не производились в виду ограниченности ресурсов), распознавание лиц GPU происходило гораздо точнее. Сет, состоящий из около 9000 изображений обрабатывался более 4,5 часов (не самая ресурсоемкая операция). Я было принялся фильтровать контент подаваемый на вход вручную, но быстро понял, что перелопатить такой объем довольно трудоемко. По этой причине набор был скормлен целиком.
 Несложно заметить, что помимо лица основного персонажа, в каталог распознанных изображений попадают фрагменты с чужими лицами (вряд ли такие исходные данные благоприятно повлияют на обучение сети). И мало удалить файлы из каталога, к ним прилагается json-файл с перечнем всех фрагментов и координат областей.
Несложно заметить, что помимо лица основного персонажа, в каталог распознанных изображений попадают фрагменты с чужими лицами (вряд ли такие исходные данные благоприятно повлияют на обучение сети). И мало удалить файлы из каталога, к ним прилагается json-файл с перечнем всех фрагментов и координат областей.
Именно для автоматизации процесса полуавтоматического постмодерирования я решил привлечь 1С. Мои познания довольно скромны, но платформа позволила быстро набросать решение задачи. Наверняка в нём не хватает ряда проверок и красоты кода, но создание заняло минимум времени и работает.

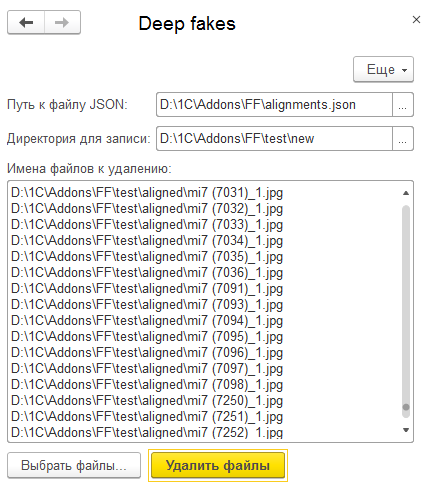
Цикл обработки состоит из 4 простых шагов:
- Задаем путь к исходному файлу json (с координатами распознанных фрагментов);
- Выбираем директорию для записи новых файлов;
- Выбираем список файлов, которые мы хотели бы удалить из сета для обучения;
- Жмем большую желтую кнопку :)
В результате в директории для сохранения создается новый файл json и директория с фрагментами. Такие данные уже куда лучше подойдут для обучения сети.
Протестировано на платформе версии 8.3.11.2954
Вступайте в нашу телеграмм-группу Инфостарт