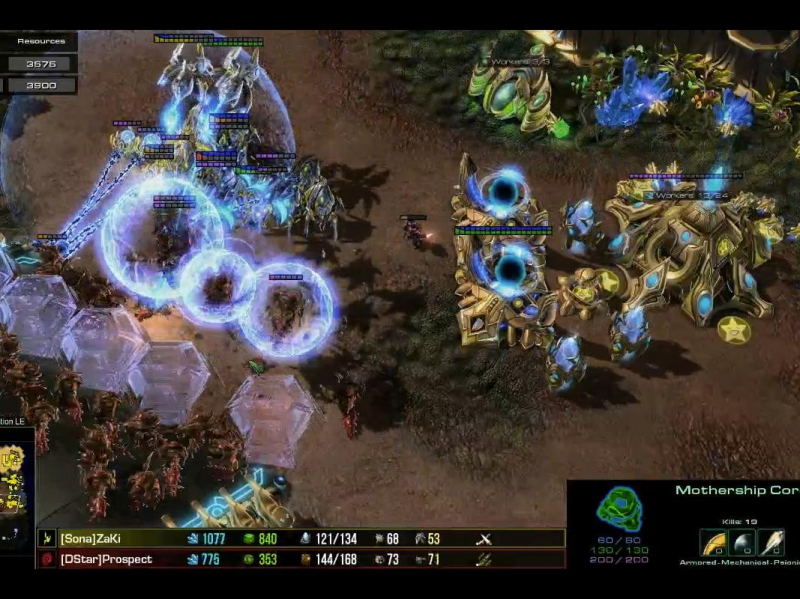
Лаборатория DeepMind разработала нейросетевое приложение AlphaStar для игры в StarCraft II. Ему удалось победить профессиональных игроков с разгромным счетом 10:1.
Сложнее шахмат
StarCraft II – стратегия в реальном времени, и боты для игры в нее разрабатываются достаточно давно. Но пока им не удавалось достичь выдающихся результатов.
Открытый API для StarCraft II разработчики из Blizzard выложили еще летом 2017 года. Но создателям ботов до недавнего времени это не слишком помогало.
Дело в том, что StarCraft, как и практически любая крупная компьютерная стратегия – это игра с закрытой информацией. К тому же здесь нужно решать множество задач одновременно, и нет единственного пути достижения успеха.
Наследник AlphaGo
DeepMind входит в состав холдинга Alphabet, созданного корпорацией Google. Специалисты компании разработали знаменитую нейросеть, которая смогла обыграть профессиональных игроков в го. Эта древнекитайская игра считается сложнее шахмат, ведь в ней значительно больше возможных ходов и комбинаций.
В 2016 году DeepMind заключила партнерское соглашение с Blizzard, чтобы разработать систему искусственного интеллекта для победы в легендарной стратегии. Разработчики подчеркивали, что StarCraft II, выпущенный в 2008 году, является идеальной средой для обучения искусственного интеллекта.
Как это работает
AlphaStar использует методы обучения с учителем и глубокого обучения с подкреплением. Нейросеть тренировали на анонимизированных записях игр реальных игроков.
Система на их основе создала решение, которое позволило побеждать встроенные алгоритмы StarCraft II на максимальном уровне сложности в 95% случаев. Затем AlphaStar играл сам с собой, чтобы стать еще эффективнее.
Сначала AlphaStar пытался победить сам себя, создавая как можно больше относительно дешевых юнитов. Со временем нейросеть поняла, как противостоять таким атакам, и стала совершенствовать экономическое развитие, чтобы строить более продуктивных и сильных бойцов. После 14 дней самостоятельной игры (это эквивалентно 200 годам игры в StarCraft II) разработчики решили опробовать AlphaStar в боевых условиях.
Безусловная победа
В рамках эксперимента потягаться с AlphaStar решили два профессиональных игрока в StarCraft II. TLO (Дарио Вунш из Германии) проиграл нейросети всухую со счетом 5:0. MaNa (Гжегожу Коминчу из Польша) удалось выиграть одну партию, остальные пять завершились в пользу AlphaStar. При этом нейросеть в среднем совершала меньше действий в секунду, чем профессиональные игроки.
Видео о том, как AlphaStar играет в StarCraft II, разработчики опубликовали на YouTube. Посмотрите на нейросеть в деле:
Маленькое «но»
Объективно говоря, у AlphaStar было преимущество. Для игроков части карты закрывал туман войны, а нейросеть получала сразу все данные. Это позволяло системе переключаться между фрагментами карты и контролировать все происходящее.
Когда в рамках демонстрационного матча с MaNa для нейросети также применили туман войны, нейросеть проиграла человеку. Но разработчики системы отметили, что версия AlphaStar, которая самостоятельно двигает карту и исследует территории, обучалась этому всего семь дней. Если эксперимент расширить, результат мог бы быть иным.