Каждый раз на конференции мы слышим много хороших докладов о том, как заниматься тестированием, а я вам сейчас расскажу, что делать, когда ничего из этого не поможет.
Меня зовут Крапивин Андрей, некоторые меня знают по статьям на Инфостарте. Одна из самых популярных – это «Не только автоматизация учета», о том, как мы участвовали в соревновании, сражались с шарпистами и питонистами. Нам надо было написать ботов для космических кораблей и отправить их на сражение. Мы написали их на 1С.
Вот пример нашего боя, мы тут синие. Очень скоро мы тут потеряем два корабля, потому что они просто куда-то улетят. Самое интересное, что в этом бою мы победим одним кораблем, а во всем соревновании у нас золотая медаль.
Вопрос – как это отладить? А вот здесь начинается самое интересное.
-
Здесь нет пошагового выполнения – программа уже пошла;
-
Нет никаких точек останова;
-
Все, что у нас есть – это отладка через «Сообщить». Мы выводим какие-то данные и на основе их решаем, что же делать дальше.
Как собрать информацию об ошибке в продакшен?
Эту ситуацию можно возвести в абсолют. Наши клиенты – это, в основном, удаленные системы, такие, к которым мы не можем быстро подключиться, зайти в конфигуратор и начать отладку.
Для отладки надо получить удаленный доступ. Если его дадут – хорошо, но недостаточно. Надо еще найти человека, у которого есть пароль от конфигуратора и надеяться, что включена отладка сервера.
Чтобы этого избежать и быстро решить проблему, нужно собрать максимальное количество информации, а именно:
-
контекст ошибок;
-
сами ошибки;
-
и, желательно, действия пользователя.
Об этом чуть подробнее.
Контекст. На самом деле, все просто. Это:
-
платформа;
-
конфигурация, ее версия (чтобы не тратить время, когда ты человека спрашиваешь: «Какая у вас версия конфигурации», а он отвечает: «8.3.13»)
-
идентификатор клиента;
-
идентификатор пользователя базы данных;
-
любые настройки.

Дальше собираем ошибки.
-
самое простое – это просто забрать информацию об ошибке;
-
постараться забрать цепочку исключений или стек вызовов;
-
и знать место возникновения ошибки.

Действия пользователя – выполняемые человеком запросы, любые действия. Про них часто забывают. Их желательно тоже знать, чтобы потом человека не спрашивать: «Что же ты такое нажал?» Он скажет: «Ничего, оно само».
Сбор логов
Первая часть отладки удаленных систем – это сбор логов. На этом я подробно останавливаться не буду, иначе мы не успеем перейти ко второй интересной части про анализ всех этих данных.

В прошлом году был хороший доклад Кашафутдинова Тимура «Логирование в приложениях», в котором все технические детали, на самом деле, были разобраны. Если кратко, то:
-
Логировать через «Сообщить» – плохая идея, потому что вряд ли пользователь обрадуется, когда ему на каждое действие будет выводиться «портянка» текста.
-
Писать в файл – тоже не очень хорошая идея, особенно если у вас клиент-серверный контекст.
-
Писать в регистр сведений может быть неудачно, потому что у вас могут быть блокировки (также не надо забывать про режим транзакций).
-
Хороший вариант – писать в журнал регистрации. Но я думаю, все знают, как долго из него можно данные вычитывать.
-
Идеальный вариант – если у вас есть какой-то внешний веб-сервис, в который вы эти данные можете отправить. Нам повезло, у нас такой был.
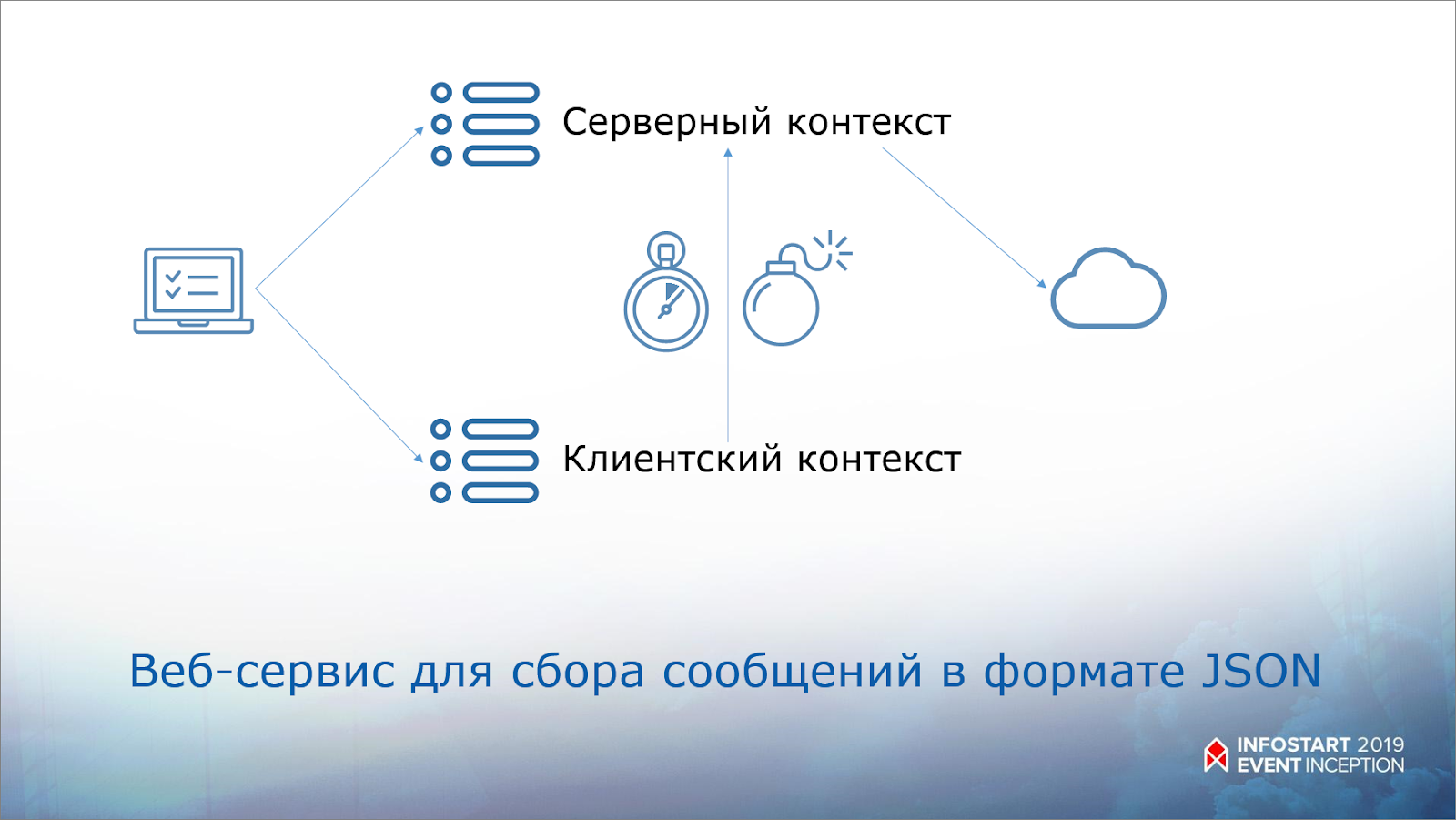
Как он работает? Пользователь запускает приложение, формируется два контекста – клиентский и серверный. Причем, это – стеки сообщений, чтобы не отправлять каждое сообщение, а отправлять их пачками.
Дальше по таймингу или по возникшему исключению контексты объединяются и отправляются в веб-сервис.
Примеры сбора логов

Вот так выглядит фиксация начала и конца сеанса. В процедуру начала сеанса можно подгрузить любые данные по используемым у пользователя настройкам – платформе, конфигурации, и т.д.

Вот таким образом мы собираем данные по работе с интерфейсом:
-
нажатия любых кнопок;
-
ввод в поля;
-
флажки/переключатели;
-
диалоги выбора файла и т.д.

На сервере это выглядит вот так.
Мы используем структурный лог. Это такой лог, куда вы, например, отправляете сообщение:
«Не удалось провести {{ТипДокумента}} №{{Номер}} от {{Дата}}»
Ключевые данные – ТипДокумента, Номер и Дата уходят дополнительным сообщением, чтобы их потом не пришлось разбирать.

И самое интересное – как мы работаем с исключениями:
-
мы в обязательном порядке их пишем в журнал регистрации, чтобы эти ошибки потом можно было хоть где-то достать;
-
и стараемся собирать целиком стек вызова этого исключения.
Подходы к логированию

Какие подходы мы используем при ведении логирования?
Желательно, чтобы логирование было с избытком. Пусть лучше там будет много информации, чем ее не хватит. Но нужно понимать, что эта система не бесплатна. Вызов функции логирования может достаточно сильно сказаться на производительности – она может упасть до 50%.
-
Поэтому первое, что начинаем использовать – это несколько уровней логирования. Вам не нужно писать много информации постоянно – только когда вы начнете заниматься отладкой.
-
Второе, что мы используем – это трассировка кода. Есть специальный скрипт, который в начало каждой процедуры и функции вставляет вызов логирования, которое запоминает название этой процедуры и входящие параметры.
-
Дальше – можно использовать отладку через логирование. Это такой интересный подход, когда вы просто запускаете программу и смотрите, что у вас высыпалось в лог. Если вам какой-то информации не хватает, вы ее добавляете, и пытаетесь решать проблемы просто с изучением этой информации.
-
И, конечно же, итерации. Вряд ли вы сразу сделаете идеально. Обязательно что-нибудь пойдет не так. Ничего страшного в этом нет.
Анализ логов
Данные мы собрали. Теперь займемся их анализом.
Clickhouse

Первая система, которую мы попытались использовать для анализа, это – Clickhouse (достаточно внезапно, наверное). Просто так получилось, что веб-сервис, который мы используем, умел сразу «из коробки» отправлять данные в Clickhouse.
Clickhouse – это база данных специального формата. Вот так выглядит ее веб-интерфейс.

Какие у Clickhouse плюсы и минусы?
Основные плюсы:
-
Аналитика – Clickhouse создан для того, чтобы собирать аналитику: мы можем посчитать, сколько у нас клиентов, какие комбинации клавиш они использовали;
-
SQL-подобные запросы – синтаксис там очень похож на SQL с небольшими доработками;
-
Есть возможность связи таблиц – если у нас в эту же систему идут логи веб-сервиса, мы можем соединить две таблицы и узнать всю картину.
Из минусов:
-
Скорость работы. Clickhouse очень неповоротливый, он любит обрабатывать большие данные – вы ему запрос отдали, он его покрутил, выдал в таблицу результат;
-
У него отсутствуют уведомления, как таковые;
-
Достаточно бедная система визуализации данных – это, в основном, таблица результата и еще две-три диаграммы.
Чтобы компенсировать минусы Clickhouse, его можно использовать совместно с сервисом Redash.
Вот так выглядит Redash:
-
у него очень большой набор диаграмм;
-
а также хороший сервис уведомлений – он интегрируется с Telegram, с почтой и со Slack.
Но, в любом случае, работать в Clickhouse для анализа логов не очень удобно, поэтому мы использовали следующее решение.
Elasticsearch

Это, конечно, же, Elasticsearch.
Вот так у него выглядит веб-интерфейс Kibana.

Какие у него получились плюсы и минусы?
Плюсы:
-
популярность – это, наверное, самый популярный стек для того, чтобы работать с логами;
-
найти по нему документацию, в том числе, русскоязычную, вообще не составляет никаких проблем – есть и статьи на Инфостарте;
-
достаточно простой формат отправки данных.
Из минусов:
-
по крайней мере, в той версии, которую мы пробовали, отсутствуют какие-то уведомления о событиях (в последних версиях, по-моему, в Kibana есть возможность интегрироваться со Slack и с Telegram);
-
обязательно нужно знать, что вы хотите найти, потому что у вас, по сути, будет большая простыня текста, из которой вы какими-то уточняющими запросами будете черпать информацию. Я видел большие статьи на wiki на тему: «когда в сервисе возникла такая-то ошибка, вам нужно сделать такие-то запросы и анализировать эти данные».
-
отсутствует настройка хоть каких-то прав доступа – у всех, у кого есть доступ в Kibana, есть доступ к вашим логам. Возможно, это плохо.
Graylog

Следующий движок, который мы попробовали – это Graylog. Он достаточно молодой, но набирающий популярность.
Вот такой у него интерфейс.

Какие у него плюсы и минусы?
-
основной плюс – уже появляется сервис уведомлений. Причем, уведомления там не только при превышении каких-то порогов, а можно просто при любом событии отправлять себе уведомления, например, об ошибке – возникла ошибка и вы сразу можете о ней узнать.
-
у него очень приятный интерфейс, и он сразу же собирает простенькую аналитику.
-
также у него есть возможность настроить права доступа.
Из минусов:
-
повторные уведомления. Когда вы получаете любую ошибку, которая возникла у пользователя, это хорошо. Но при групповом перепроведении документов вы получите к себе в Telegram поток сообщений. Даже при том, что у Graylog есть возможность сказать, что вы хотите получать сообщения раз в полчаса, не больше – полчаса пройдет, и вы получите оставшуюся порцию сообщений.
-
он бесплатный до определенного предела. Как только вы отправите в него слишком много данных, он уже будет просить с вас определенную сумму.
Все эти сервисы достаточно хорошие, мы бы, наверное, на этом и остались – аналитики сидели бы в Clickhouse, вертели бы данные, как хотят, а мы бы в Kibana анализировали, что у нас пошло не так. Но мы чуть-чуть поискали, и нашли сервис Sentry.
Sentry

Sentry – это, как раз «Часовой» (или «Страж»). Чем же он так отличается?
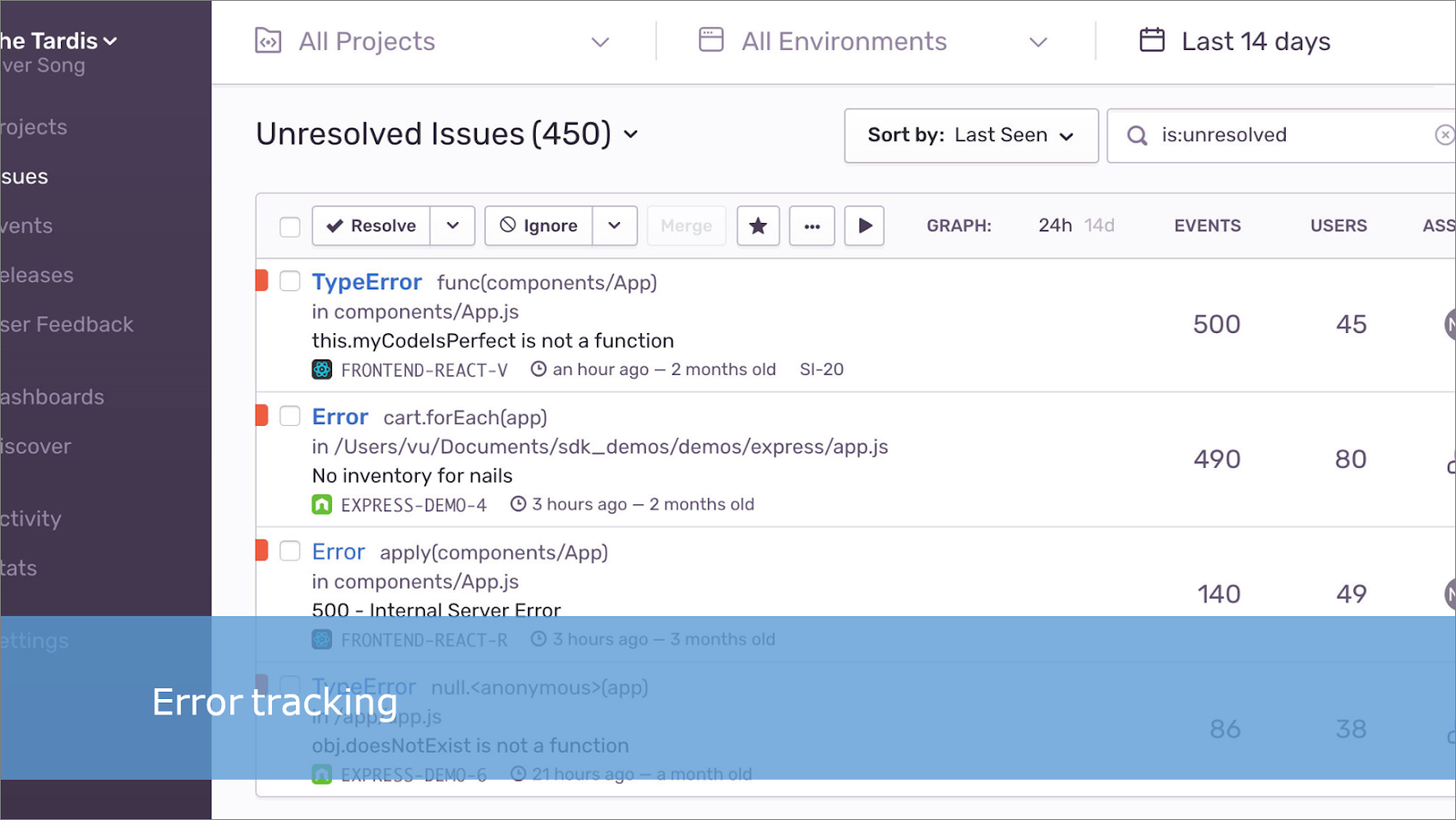
Во-первых, это трекер ошибок, сервис, который заточен именно на обработку ошибок. Вот такой у него веб-интерфейс.
У него огромная поддержка языков. 1С там, правда, нет, но – когда нас это останавливало?

И он OpenSource. Вы можете скачать его по ссылке https://github.com/getsentry/sentry и быстро себе поставить. Он написан на Python, соответственно, его можно доработать.
Также его можно использовать на сайте https://sentry.io/ – можете там зарегистрироваться, чтобы его «потыкать».
Как передать данные в Sentry?

Как все это работает?
-
первым делом из всего многообразия логов вам нужно выделить только исключения;
-
далее их нужно отправить в какую-нибудь систему, которая их преобразует в требуемый формат (у нас для этого используется 1С);
-
и после этого отправляете их в Sentry.

Например, вот так. Это – пример обработки сообщения. Надо выделить:
-
ошибку;
-
пользователя, у которого она возникла;
-
и контекст.

После этого просто собираете JSON и отправляете его по HTTP.
Важные сущности – Event и Issue.
Уведомление об ошибке
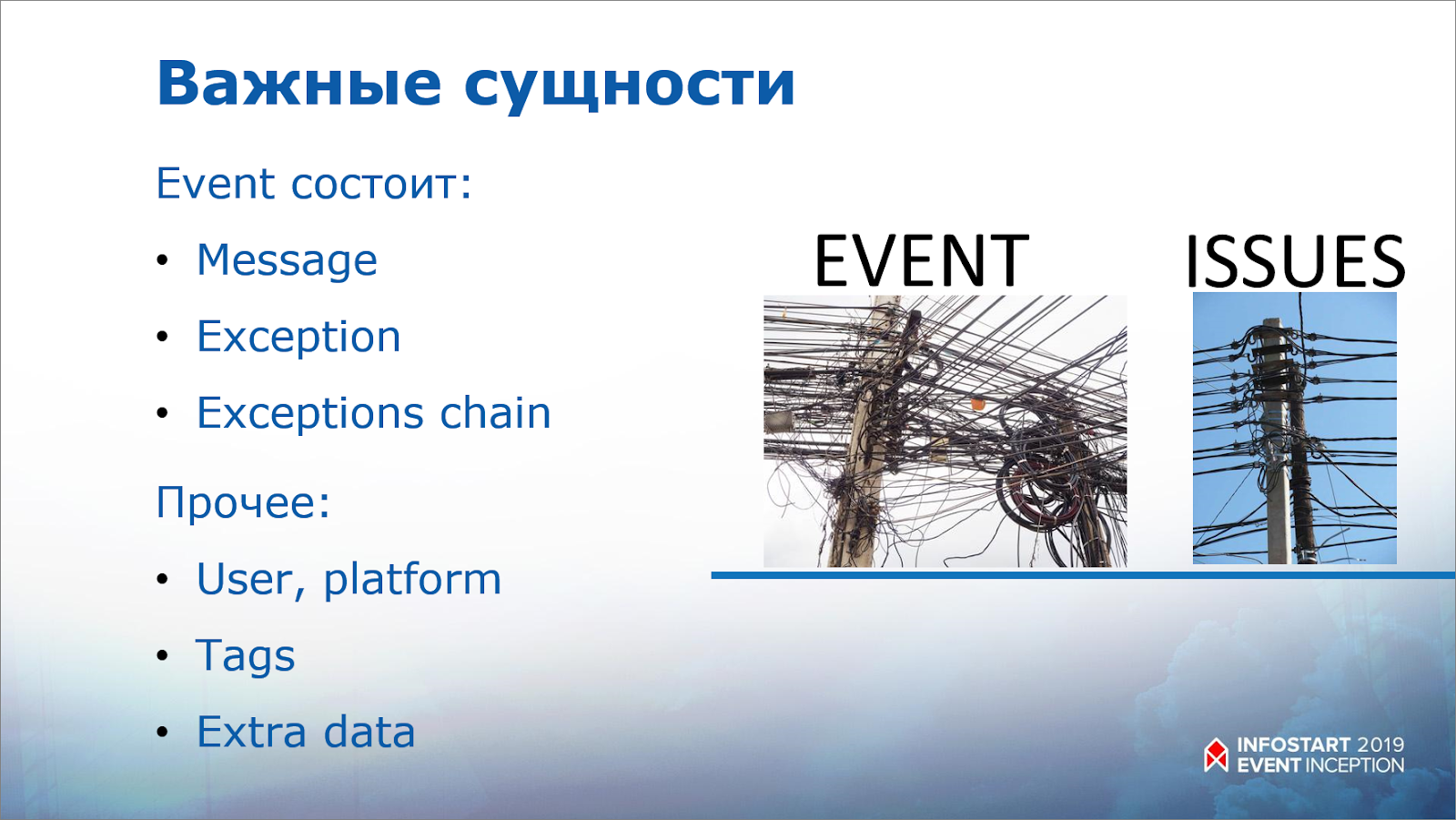
Теперь возникают две важных сущности Sentry.
-
Первая сущность – это Event (событие). То, что мы отправили в Sentry на предыдущем шаге, это будут, как раз, события. Они должны содержать в себе:
-
сообщения;
-
описание исключений;
-
или описание цепочки исключений.
-
-
Sentry анализирует эти три параметра и собирает из них задачу (Issue).
Дополнительно можно отправлять данные:
-
о пользователе;
-
платформе, которой он пользуется;
-
добавлять теги;
-
и любые дополнительные данные.

Вот так выглядит уведомление об ошибке, которое приходит к нам в Slack.
Самое важное, что вы получаете уведомление только о новых задачах – не событиях, а задачах.
Дальше вы можете эти задачи либо разрешать, либо игнорировать. Например, если ошибка возникла один раз, и вы сейчас ничего с этим делать не хотите, вы просто ставите эту задачу на игнорирование, пока она не возникнет еще 10 раз (или у 10 пользователей).
Как анализировать ошибки с помощью Sentry?

Я думаю, проще разобрать на примере простенькой конфигурации.
У пользователя возникла ошибка. Как эту ошибку можно анализировать с помощью Sentry? Самое простое – создать задачу, куда отправить текст этой ошибки.
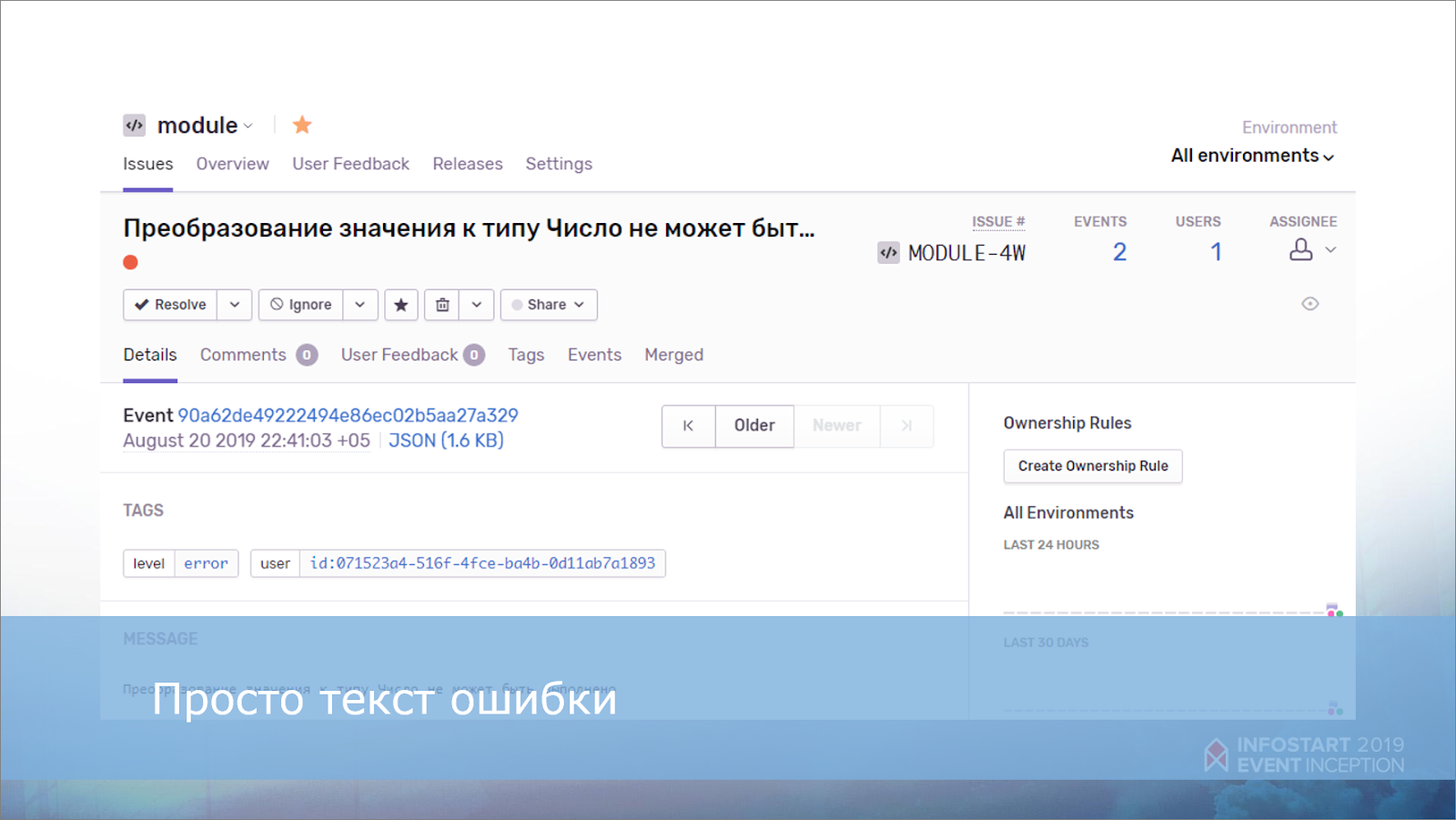
Задача в Sentry будет выглядеть вот так.
В строке заголовка мы уже сразу видим дополнительную аналитику – сколько раз и у каких пользователей возникла эта ошибка.
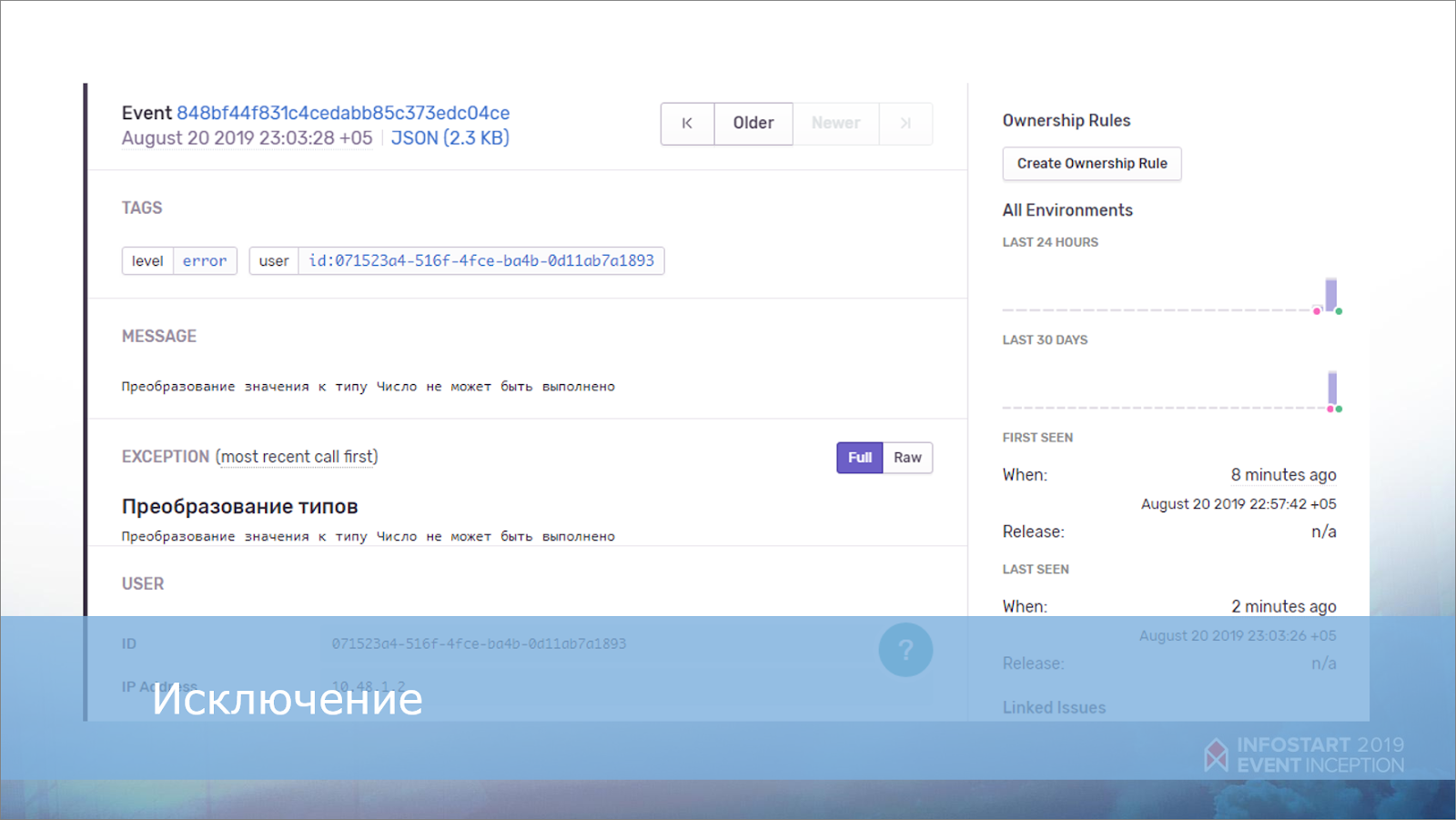
Смотрим, что еще здесь есть:
-
ниже выводится описание исключения, которое мы собрали из нашего сообщения об ошибке;
-
справа мы видим два графика, как часто эта ошибка вообще появлялась:
-
за последний месяц;
-
и за последние 24 часа.
-
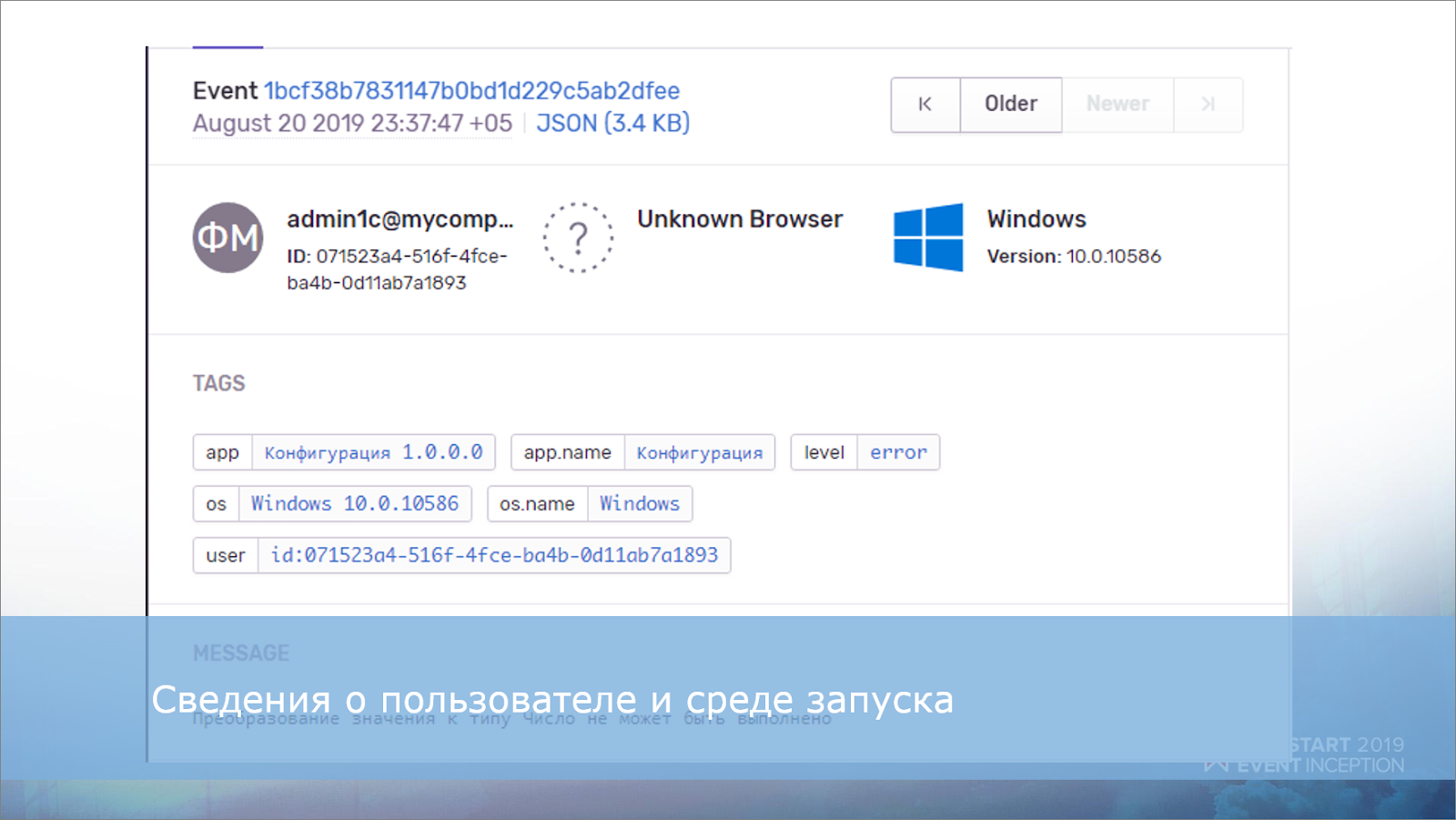
Что еще можно вытянуть из сообщения об ошибке 1С?
Самое простое – это собрать в качестве данных о событии сведения о пользователе и о среде запуска.

Сведения о пользователе будут выглядеть вот так.
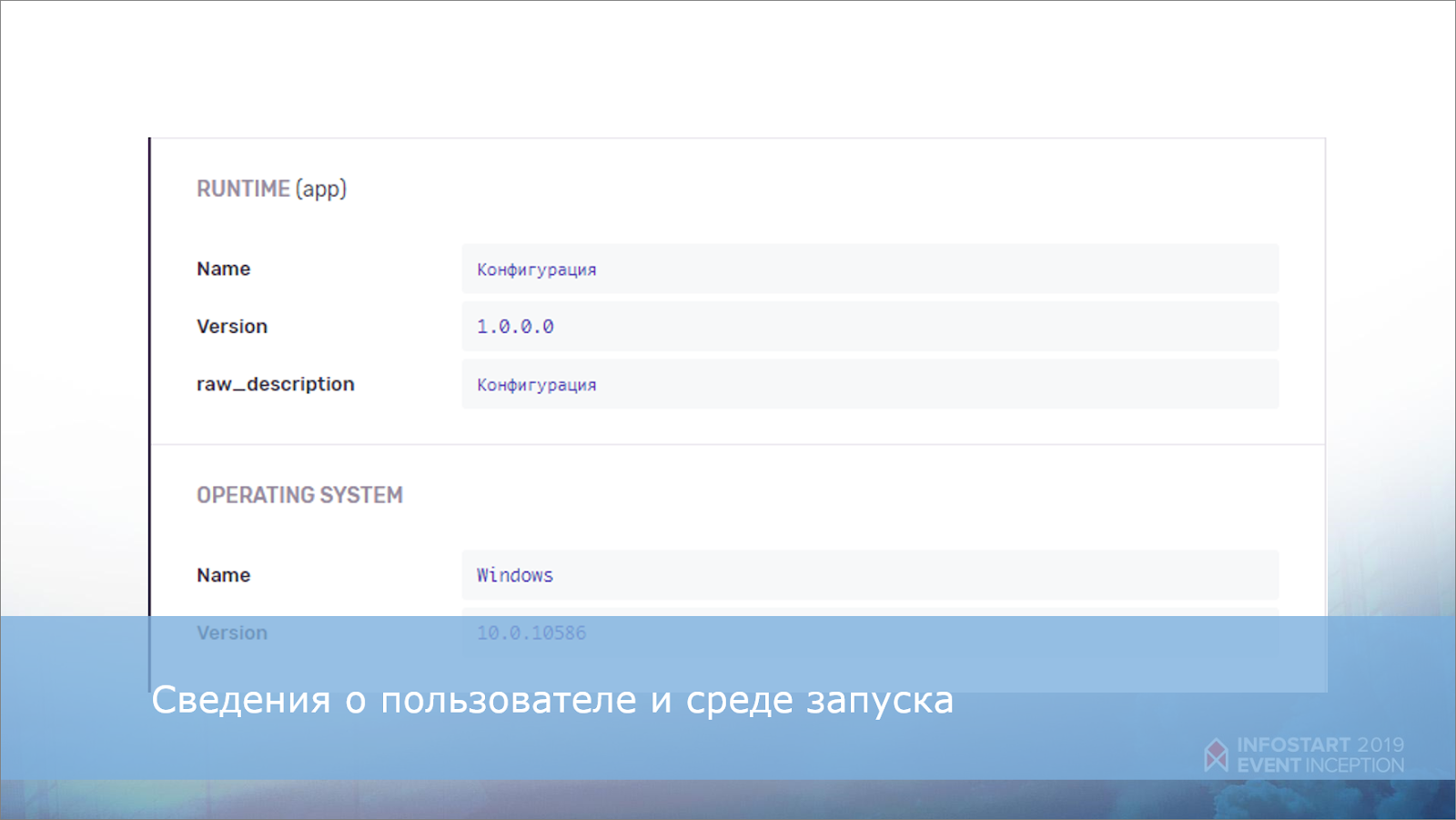
О среде запуска – вот так.
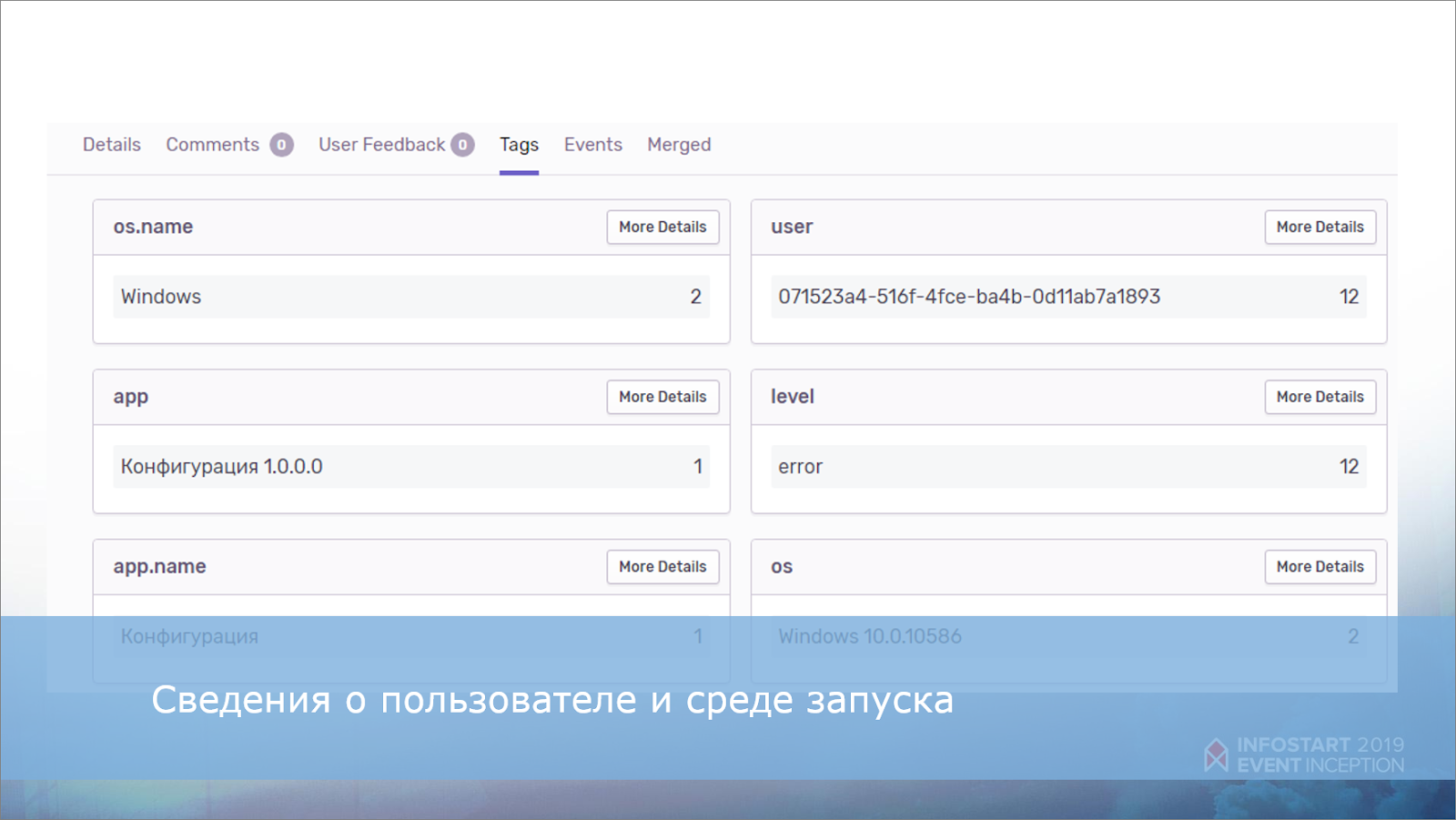
Эту же информацию можно также использовать в качестве тегов.
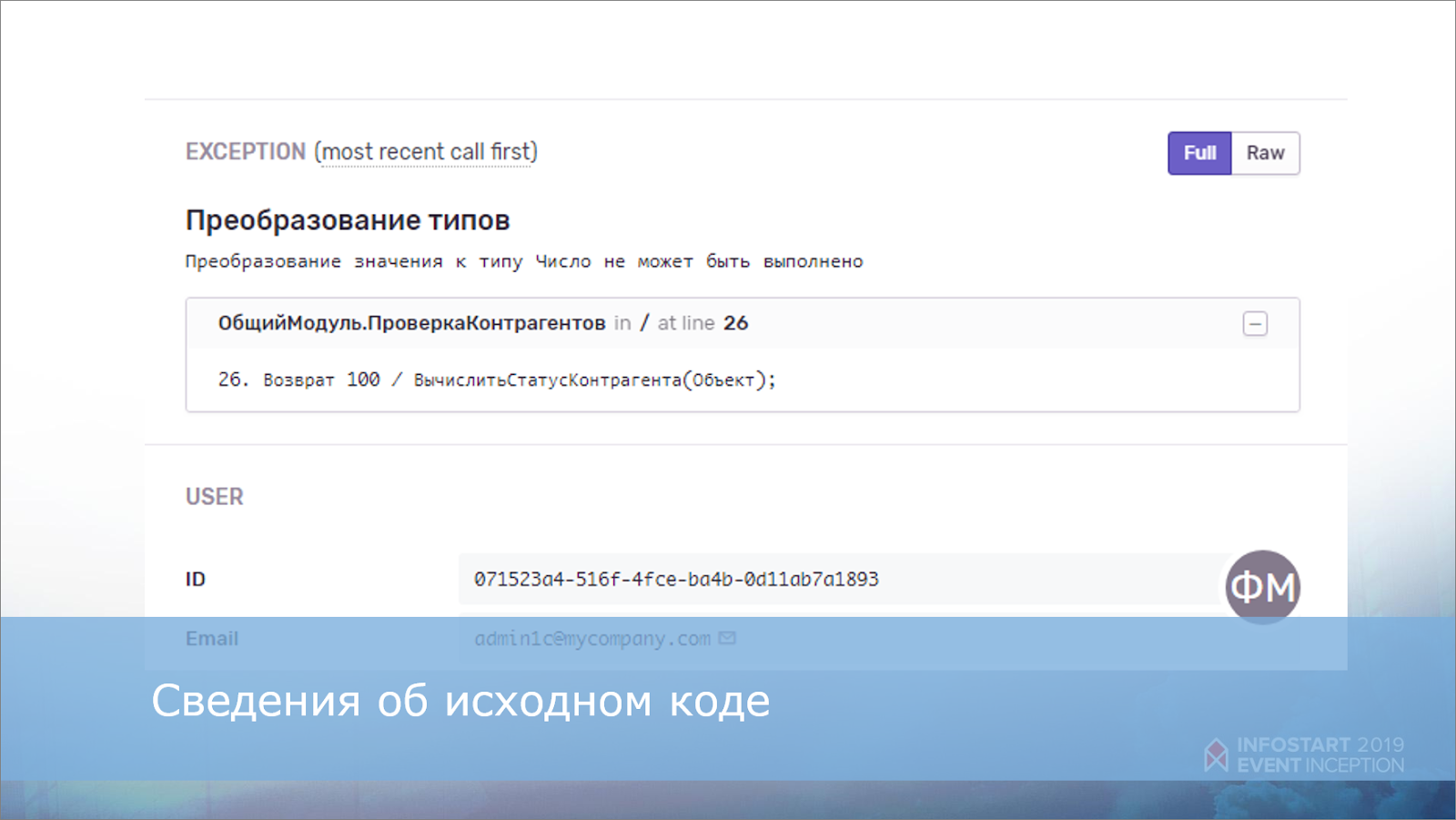
Еще очень полезная информация, которая содержится в информации об ошибке – это строка кода. Отправляем ее тоже, получаем такую картину.
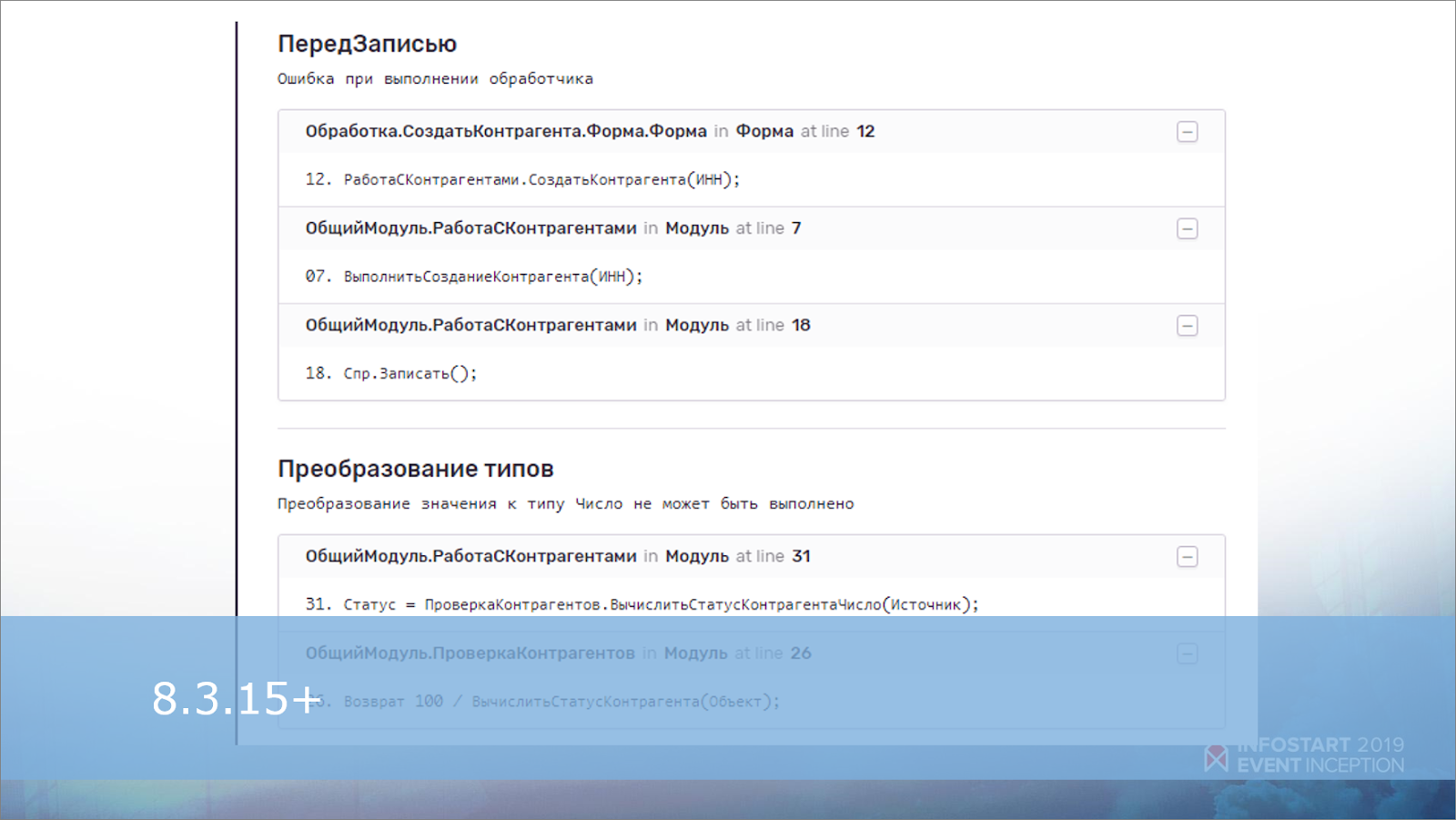
Те, у кого 8.3.15, могут для исключения вывести в «Информацию об ошибке» полный стек ее возникновения.
Если версия платформы ниже 8.3.15, тогда нужно просто аккуратно собирать цепочку исключений.
-
вы вызываете исключение – обработали на верхнем уровне;
-
потом дописываете информацию на всех следующих уровнях;
-
и результат отправляете в Sentry.
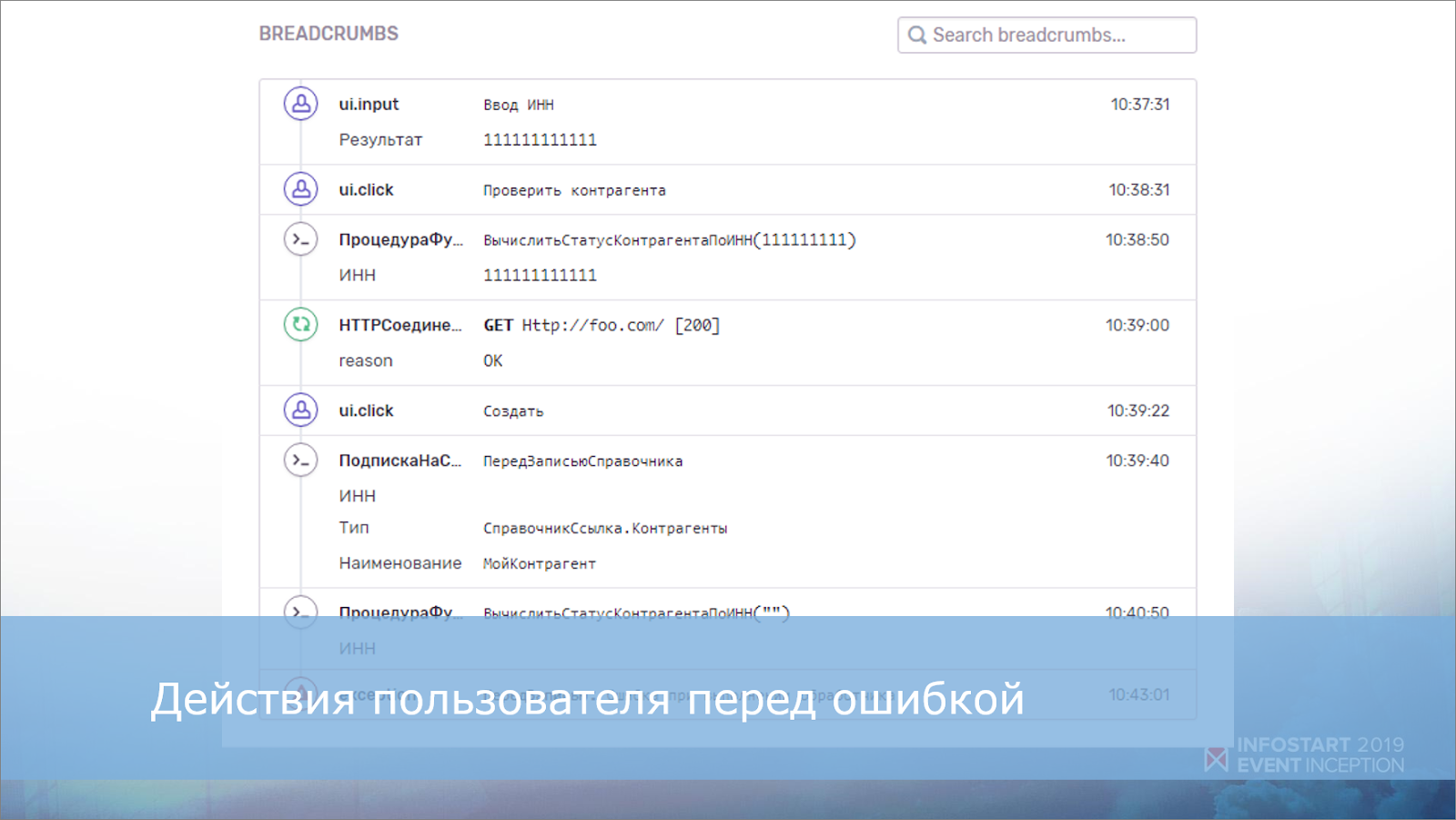
И большой блок информации, которая нам поможет разобраться, в чем же дело – это действия пользователя перед ошибкой.
Работа с issues
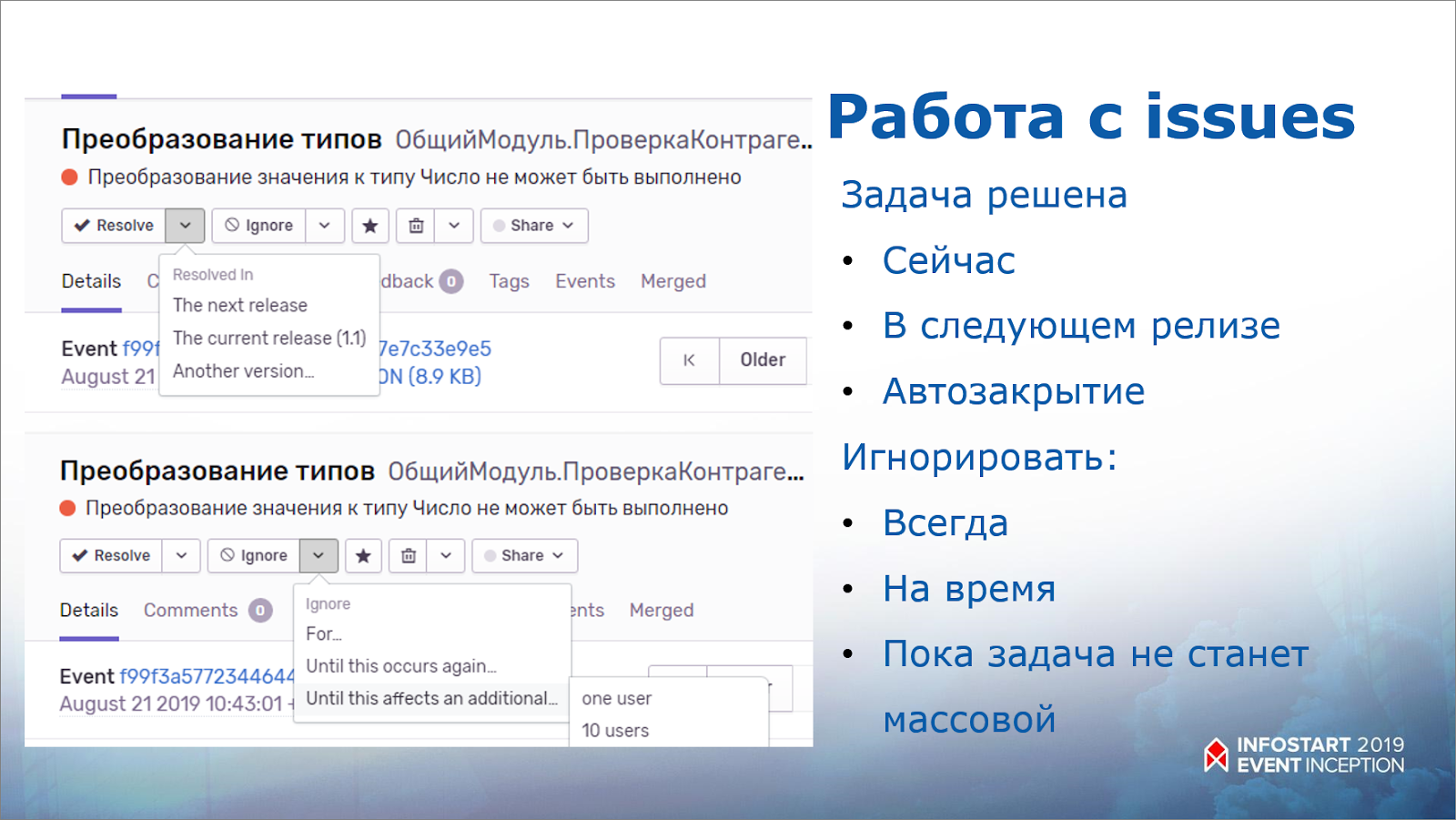
Хорошо, данные мы отправили. Начинаем с ними работать.
Задачу можно или разрешить, или проигнорировать:
-
Если мы говорим, что ее разрешаем, тут есть дополнительные условия – мы говорим, что решаем ее прямо сейчас или в следующем релизе. Если мы отметим, что решим задачу в следующем релизе, то до этого релиза нам уведомления приходить не будут. Мы говорим: «В этом релизе мы задачу не решаем, решим ее в следующем», и все, нас сервис больше не уведомляет.
-
Можно проигнорировать, если задача не массовая. Зачем решать проблему у одного пользователя? Пусть задача возникнет у 10 тысяч пользователей, тогда, может быть, будет интересно.
Почему Sentry?

Почему же все-таки стоит пользоваться Sentry?
-
Сервис Sentry, в отличие от всех остальных, дает фокусировку на ошибках. Никто не полезет в логи, пока не возникнет проблема (если вы не занимаетесь аналитикой).
-
Он позволяет вытянуть максимальный контекст в короткое сообщение.
-
И у него хорошая оптимизация хранения данных. То есть, он не хранит всю подряд информацию, если произошло повторное событие – он просто стыкует его в одно.

И почему еще следует пользоваться Sentry?
У них на главной странице сайта есть надпись: «Серьезно, перестаньте надеяться, что пользователи сообщат вам о своих ошибках».
Могу рассказать пример из практики. Был конец рабочего дня, часов 20. Мне в Slack приходит сообщение, что у пользователя ошибка. Конец рабочего дня – я ничего не стал делать, прихожу на следующий день – там у пользователя уже 15 попыток, но информации от него до сих пор нет. Мы нашли менеджера клиента, позвонили ему, он говорит: «У меня все хорошо». В итоге на службу поддержки клиент обратился только через неделю – к этому моменту у него было уже 150 попыток сделать действие.
Что нужно сделать?

Что нужно, чтобы начать этим пользоваться?
-
Начинайте собирать логи:
-
возьмите библиотеку Logos;
-
пишите данные в журнал регистрации;
-
собирайте технологический журнал.
-
-
Если вы хотите только искать данные, то можете пользоваться:
-
Elastic Search;
-
или Graylog.
-
-
Если вам нужна аналитика, то тут вам, скорее всего, поможет:
-
Clickhouse;
-
или, например. Graphite.
-
-
Если вы хотите аккуратно работать с ошибками, тогда подойдут сервисы:
-
Sentry;
-
Rollback;
-
а также у Google есть сервис для работы с ошибками.
-
Материалы
Я постарался собрать материалы, какие есть по логированию. Здесь есть и статьи с Инфостарта, и готовые библиотеки:
-
Logos для 1C – https://github.com/silverbulleters/logos-1c
-
ТЖ в Elastic – //infostart.ru/public/1073101/
-
ЖР в Elastic – //infostart.ru/public/545895/
-
ЖР в Clickhouse – //infostart.ru/public/951551/
-
Graylog и 1С – //infostart.ru/public/1011440/
-
Google Analytics – //infostart.ru/public/723481/
-
Google Cloud Platform – //infostart.ru/public/796913/
А это – мои материалы:
-
Наш веб-сервис «Метрика» – https://github.com/KrapivinAndrey/Metrika, можете на него посмотреть. Может быть, найдете вдохновение.
-
А также база, которая занимается тем, что подготавливает сообщения для Sentry – https://github.com/KrapivinAndrey/1C_Sentry.
Вопросы:
-
Расскажи по поводу действий пользователя – они отображается в Sentry, но это же не часть контекста исключения. Каким образом они собираются, показываются?
-
Эти данные у нас собираются во внешний веб-сервис. И есть специальная база 1С, которая следит за потоком именно ошибок в этом веб-сервисе. Причем, данные у нас разделены – в один поток мы пишем ошибки, а во второй поток – все действия пользователя. Как только эта база находит ошибку, она дополнительно подключается ко второму потоку и забирает из него последние 10 событий по ID пользователя. А потом передает эти данные в Sentry.
-
А как получить стек вызовов для исключения?
-
В платформе 8.3.15 в «Информации об ошибке» есть возможность посмотреть целиком стек ее возникновения. Это – места возникновения ошибки с указанием исходной строки кода. Это то же самое, как вы при отладке в конфигураторе ставите точку останова и там есть кнопка «Стек вызовов». Теперь тот же самый стек вызовов можно увидеть в информации об ошибке при возникновении исключения. Это в 8.3.15 «из коробки».
-
Каждое действие пользователя записывается в 1С?
-
Не в 1С, а в отдельный веб-сервис. 1С здесь, наверное, не потянет. Особенно, если писать в журнал регистрации. А если это сторонний веб-сервис, то почему бы и нет. Каждое действие пользователя (нажатие на кнопку, изменение поля ввода, диалог) складывается в специальные стеки, которые по таймауту отправляются в веб-сервис.
-
Ты показывал куски кода, которым все это отправляется в Sentry – это закрытое решение или все это есть в той базе, которая выложена у тебя на GitHub?
-
База интеграции с Sentry выложена на GitHub, можете ее скачать и посмотреть.
****************
Данная статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT 2019.

Вступайте в нашу телеграмм-группу Инфостарт