Меня зовут Егор Ткачев, я Agile-коуч, занимаюсь развитием Scrum-мастеров и владельцев продукта. Хочу рассказать об этапе Discovery – том, что происходит с задачей после возникновения идеи и перед взятием ее в разработку. Мы рассмотрим:
-
Что такое backlog.
-
Как структурировать работу до backlog, и почему это нужно делать.
-
Какие этапы важно не забыть, когда вы хотите себя прокачать в работе с backlog (PBR. AC. DOR. WSJF и другие наборы букв).
-
Отдельно поговорим про медицину и инструмент быстрого принятия решений Triage Tag.
-
И что можно сделать в ближайшей перспективе – с чего начать что-то менять.
Сразу предупрежу, что в докладе будет использоваться специальная терминология – Scrum, Kanban, Definition of Done, Definition of Ready, Product Backlog Refinement и так далее. Это будет небольшая теоретическая выжимка, а на мастер-классе мы будем рассматривать все это на практике.
Что такое Backlog продукта
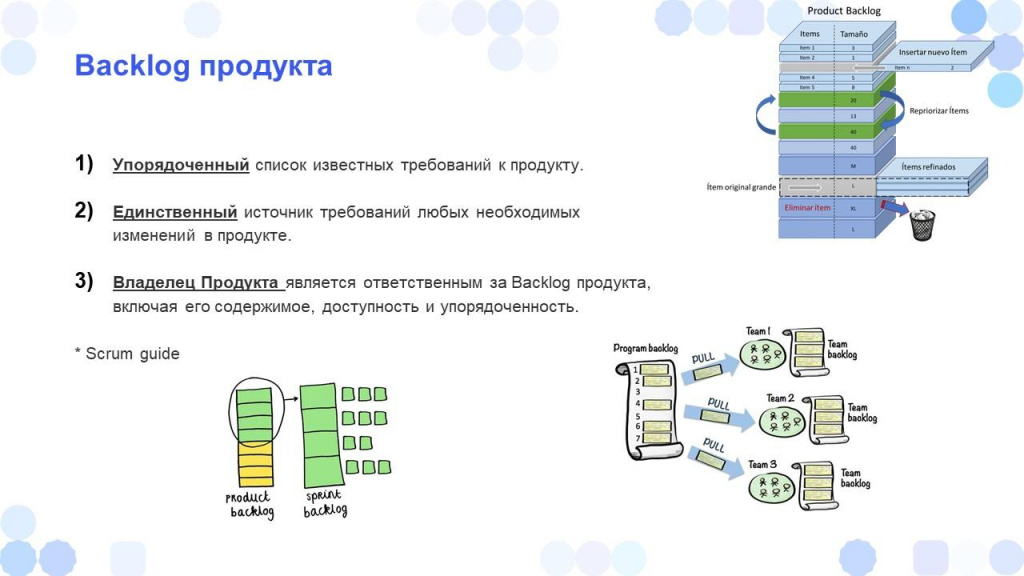
Согласно Scrum Guide, Backlog продукта – это:
-
Упорядоченный список всех известных требований к продукту.
-
Единственный источник требований.
-
За содержимое, наполненность и упорядоченность backlog отвечает владелец продукта.
У многих из вас, скорее всего, есть backlog. А знаете ли вы, сколько в нём задач? Больше 100? А может, 300 или даже 700? Однажды мои коллеги посетили одну компанию, где у владельца продукта backlog в Excel насчитывал более 700 строк. Перед отъездом они подарили ему скрипт, который автоматически удаляет из бэклога всё, что находится ниже сотой строки. Сначала владелец продукта расстроился, но потом сказал: «Респект!» Думаю, вы понимаете, почему.

Что в теории представляет собой backlog?
-
Backlog – это некая очередь, упорядоченная в первую очередь по ценности.
-
Он прозрачен для команды и для заинтересованных лиц заказчика.
-
Вокруг Backlog’а строятся обсуждения в Scrum-команде, в Kanban-команде, в ART-е SAFe.
-
Задачи Backlog’а на ближайшие три спринта должны быть заранее тщательно проработаны: разобраны, уточнены и подготовлены к работе – мало ли, владелец продукта заболеет или в отпуск уйдет, работа всё равно должна продолжаться.
-
Backlog должен быть упорядочен: по ценности, зависимости и рискам.
Но так ли это на самом деле? Зачастую совсем далеко от реальности.
Как структурировать работу до backlog
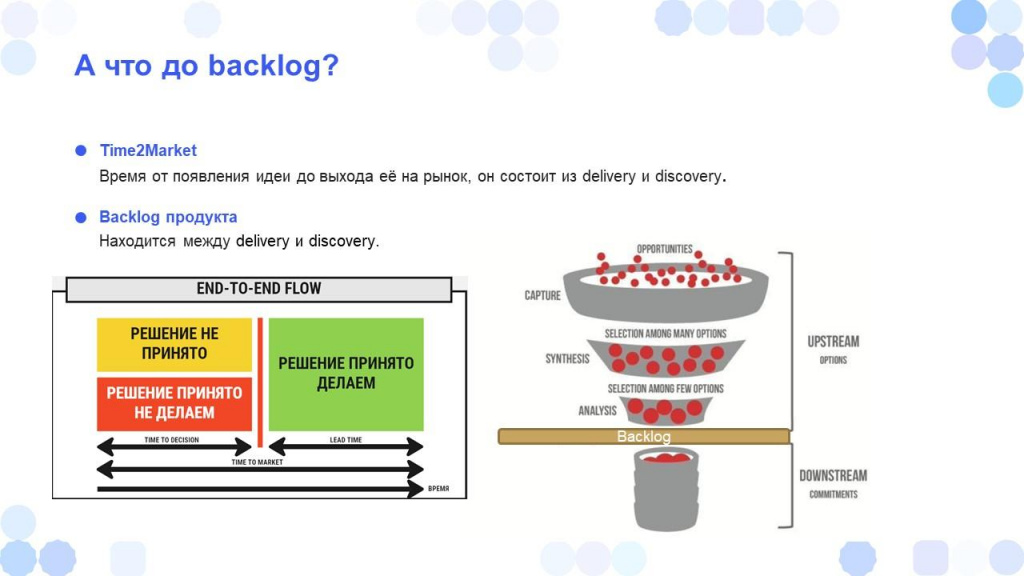
Во многих компаниях есть сложности с time to market – от появления у клиента идеи до ее реализации в продукте проходит слишком много времени.
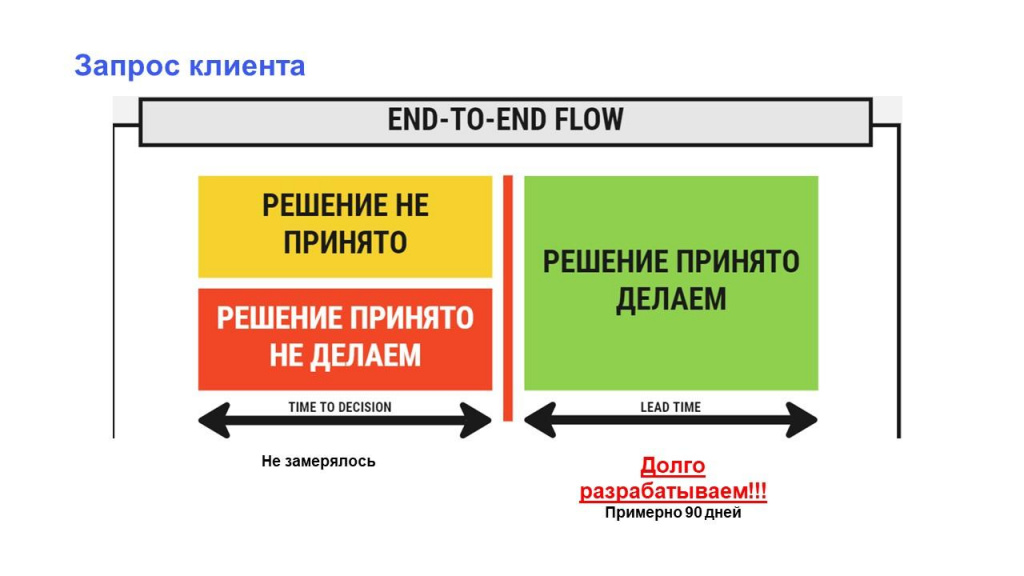
Недавно был у одного клиента. Говорит: «Что-то у нас всё слишком долго делается» – «А долго – это сколько?» – «Ну... просто долго, не нравится».
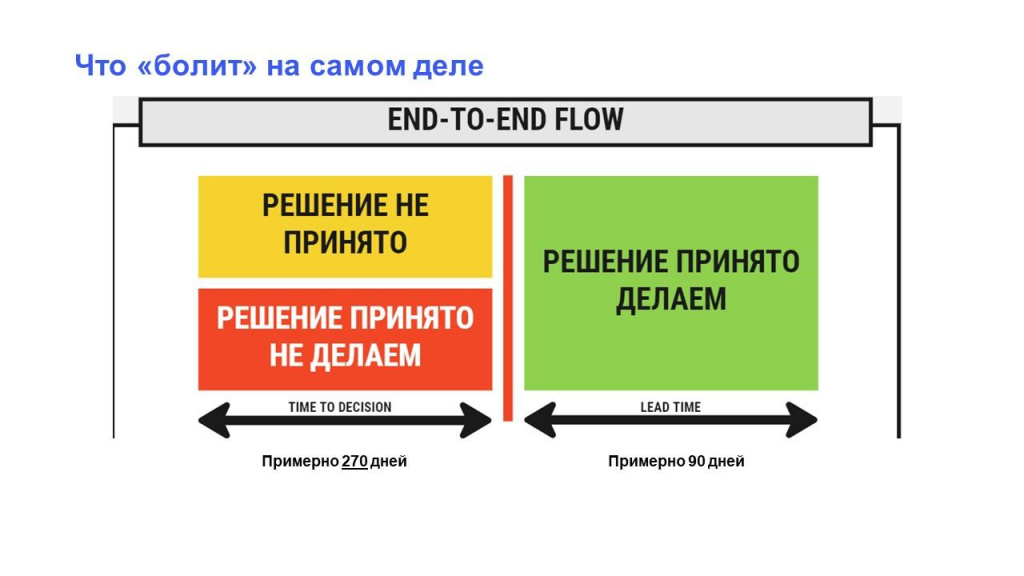
Начинаем смотреть. В разработке (Delivery) задачи находятся 90 дней. В целом – неплохо. Возвращаемся к клиенту: «У вас Delivery – 90 дней. Это долго?» – «Как 90? У меня time to market – два года» – «Подожди. А проблема точно в разработке?»
Начинаем копать глубже. Смотрим Discovery – оказывается, там задачи висят 270 дней. Очевидно, куда стоит направить внимание – не на Delivery, а на Discovery.
И действительно, внятный и формализованный процесс Discovery – с понятным флоу, критериями перехода между этапами, Definition of Done, WIP-лимитами – это редкость.
Обычно задачи в Backlog появляются стихийно – просто потому что их кто-то создал. И очень часто задача консультанта, либо Scrum-мастера, либо Agile-коуча, либо Service Request Manager заключается в том, чтобы формализовать этот процесс, выстроить, сделать его понятным.
И здесь сразу же возникает одна из наиболее частых развилок:
-
либо выстраиваем процесс «как надо»;
-
либо идем по пути «как у вас принято» – а это многие компании воспринимают, как «У нас нет практики отказа от задач на этапе Discovery. Мы все обязаны дотащить до бэклога».
А между тем суть Discovery как раз в другом: в нормальной практике минимум 60% идей должно быть выкинуто, потому что Discovery – это исследование.
Сегодня у генерального директора появилась идея в бане, завтра он заходит в офис и вдохновлённо делится с командой: «Есть гениальная мысль!»
Команда бросает всё и начинает срочно её реализовывать. А на следующем обзоре генеральный спрашивает: «А где инкремент?» – «Так мы же занимались вашей идеей...» – «Я просто хотел, чтобы вы её записали и поизучали, а не сразу в разработку бросались.
Это и есть яркий пример того, что процесс Discovery либо не выстроен вообще, либо не отделён от Delivery.
А ведь в Delivery всё обычно более-менее прозрачно: есть понятный поток – от «To Do» до «Done» (в Scrum) или более детализированные этапы в Kanban (аналитика, разработка, тестирование, UAT и т.д.). Есть визуализация – можно показать бизнесу, где находятся задачи, где возникают узкие места. Есть возможность измерять ключевые метрики:
-
Customer Lead Time – от взятия обязательства до возврата результата клиенту.
-
System Lead Time – сколько времени задача реально находится в системе.
-
Cycle Time – длительность любого этапа, по которому вы договорились. Хотим мерить отдельно in progress? Давайте мерить in progress. Хотим мерить отдельно аналитику, разработку, тестирование? Мерим отдельно аналитику, разработку, тестирование.
-
Touch Time – сколько времени реально тратится на активную работу над задачей.
Когда у вас есть исторические данные по Delivery, вы можете на основе этих метрик давать SLA: сколько времени нужно на разные типы задач.
А представьте, что будет, если то же самое сделать с Discovery? Например, вы знаете, что для появления в Backlog’е одной задачи вам нужно рассмотреть 10 идей – каждая идея проходит понятные этапы, на каждом этапе понятные критерии отсева, понятные Definition of Done. В этом случае владельцу продукта или менеджеру не потребуется воевать с бизнесом и объяснять ему на пальцах, почему та или иная идея не будут реализованы – у вас для этого есть конкретные данные.
Было бы вам проще? А такое действительно бывает.
Подумайте – есть ли у вас задачи, которые берутся в работу, но ценность для бизнеса по ним либо равна нулю, либо непонятна вообще? А ведь разработка – самый дорогой этап. Не лучше ли отсеивать такие задачи заранее – на уровне Discovery?
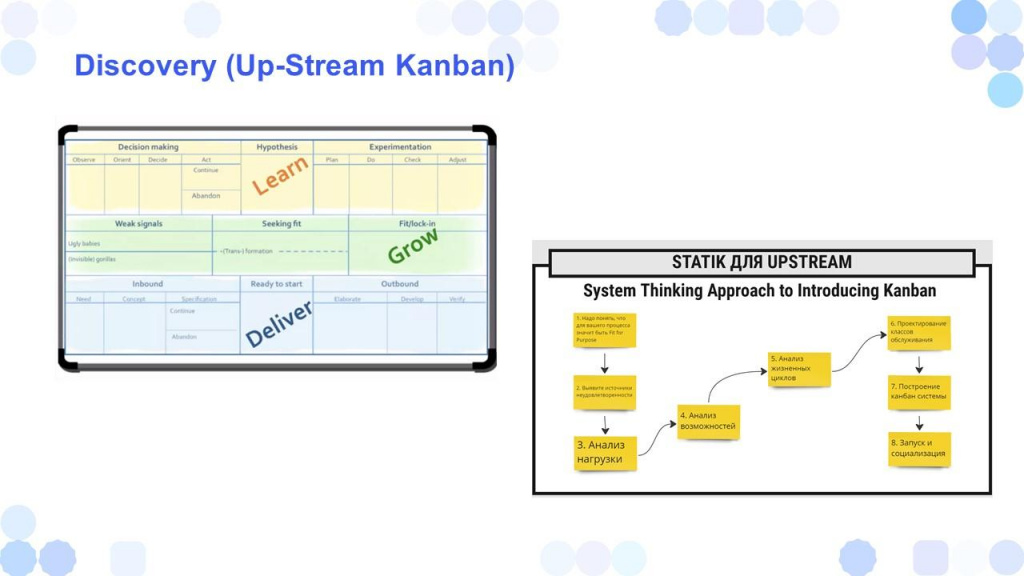
Несмотря на то, что у каждой компании свои, кастомные Discovery и Delivery-процессы, для их построения есть универсальные подходы. Один из них – это STATIK (Systems Thinking Approach to Introducing Kanban), стандартный Kanban-воркшоп, применимый как к Delivery, так и к Discovery. С его помощью вы можете:
-
собрать неудовлетворенности заказчика и команды;
-
определить источники нагрузки;
-
зафиксировать входы, выходы, жизненные циклы;
-
понять, как в действительности работает процесс.
На этой основе вы можете построить Discovery-процесс, аналогичный по структуре вашему Delivery.
Есть один важный нюанс: если в классическом Kanban для Delivery мы задаём WIP-лимит – одну цифру на колонку, то в Discovery лучше использовать двойной лимит — минимальный и максимальный. Только так вы можете выстроить по-настоящему вытягивающую систему.
Например, если количество тикетов в колонке backlog опускается ниже минимального WIP-лимита, мы понимаем, что надо вытянуть задачи из предыдущего столбца. Такой подход помогает избежать ситуаций, когда ваш backlog «под завязку» заполнен задачами, которые нужно сделать «вчера».
Конечно, попытки «впихнуть» все равно будут. Чтобы управлять этим, заведите ускоренную полосу (fast track) – но с четкими, прозрачными правилами. У одного из клиентов, например, было всего два критерия для fast track:
-
Невыполнение задачи настолько критично, что может остановить бизнес.
-
Соотношение «время до дедлайна/объем работы»< 0.5. Если больше – задача подождет.
Все прозрачно. Бизнес быстро понял, что «впихнуть» просто так уже ничего не получится.
Какие этапы важно не забыть
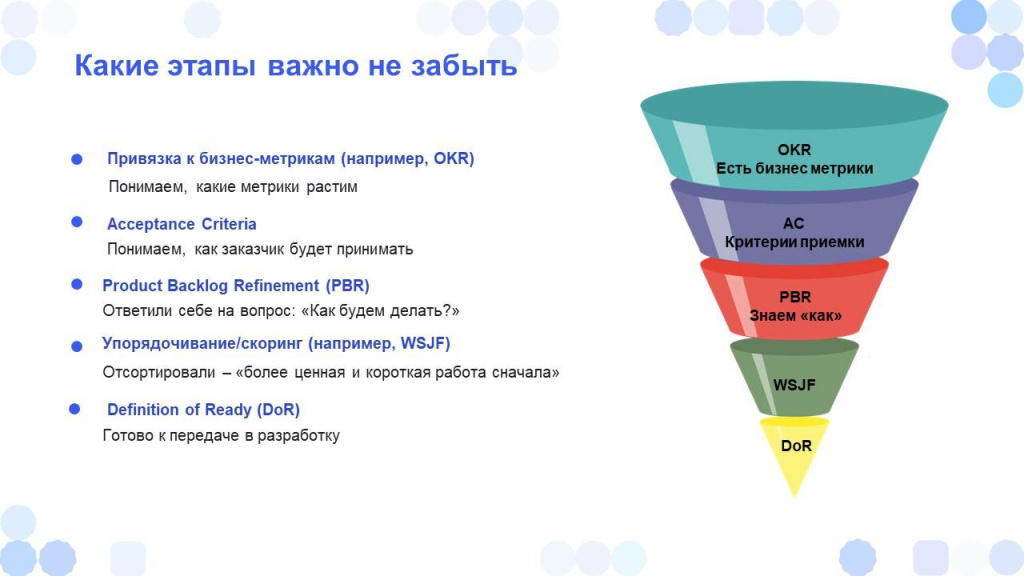
Давайте рассмотрим ключевые элементы, которые важны практически для любой компании, любого флоу, любого продукта, сервиса, системы на этапе Discovery.
Начну снизу вверх по уровню зрелости процессов:
-
Definition of Ready (DoR) – четкий, понятный критерий готовности к передаче в разработку. С его помощью команда Delivery понимает, что задача полностью готова к началу работы и может быть быстро реализована.
-
WSJF (Weighted Shortest Job First) – одна из простейших моделей для приоритизации «более ценная и короткая работа сначала». Считается как стоимость задержки (Cost of Delay), деленная на трудоемкость. Поддается автоматизации, оперирует всего четырьмя переменными, и отлично подходит для принятия решений на потоке Discovery.
-
PBR (Product Backlog Refinement). В Scrum он называется грумингом, но термин не прижился, потому что груминг – это стрижка животных. Суть PBR заключается в декомпозиции – вы больших слонов нарезаете на маленькие составляющие, чтобы ответить себе на вопрос «Как будем делать?» Причем большинство компаний разбивает этот процесс на два этапа:
-
сначала бизнес-аналитик разбивает эпик на story;
-
затем команда превращает story в конкретные задачи – оценивает их, и на этом основании происходит обратная оценка story и эпика, после чего – приоритизация.
-
-
Acceptance Criteria (AC) – критерии приемки, про которые многие забывают. Когда бизнес приходит с идеей вроде «давайте поедем на Северный полюс на сломанных лыжах», команде важно не просто согласиться, а задать главный вопрос: «Как вы будете принимать результат? По каким признакам поймете, что всё работает как надо?» Очень часто бизнес на этом сыпется и говорит: «Давайте тогда не будем делать».
-
И, конечно, привязка к бизнес-метрикам (например, OKR). Независимо от того, какую систему целеполагания вы используете – KPI, OKR или управление по целям (MBO) – если идея, проект или фича не привязаны к бизнес-ценности, их делать не нужно. Они не несут ценности бизнесу. Исключение – технические инициативы (энейблеры), багфиксы и техдолг. Но даже для них можно – и нужно – находить связи с бизнес-целями. Например, если баг мешает пользователям оформить покупку, его устранение прямо влияет на выручку – а значит, несет очевидную ценность.
Зачем нужен Triage Tag

В военной медицине есть простая техника – Triage Tag. Когда в военный госпиталь приносят раненого, врач смотрит: «Этого – срочно оперировать на стол. Этот – подождет, а этому уже ничем не помочь».
Такой простейший скоринг на уровне интуиции внедрить довольно просто. Главное – чтобы у вас под каждый из типов задач были четко определены критерии оценки. Чтобы на вопрос: «А почему именно так?» для каждого из трех типов задач – был понятный и обоснованный ответ, который можно заранее придумать, формализовать и описать.
Единственное, Triage чуть сложнее согласовывать с бизнесом, но тоже возможно.
Что можно сделать в ближайшей перспективе
Основная мысль моего доклада – не занимайтесь, пожалуйста, локальной оптимизацией. Если у вас «болит» в одной точке, не стоит лечить только ее. Смотрите шире – хотя бы на половину системы.
Если вы устранили одно бутылочное горлышко – это лишь сместит проблему дальше по потоку. Система может заработать чуть быстрее, но все равно будет тормозить. Поэтому подходите к изменениям системно – управляйте всем потоком создания ценности.

Возникает логичный вопрос – с чего начать?
-
Первое, что надо сделать: создайте понятную цепочку ценностей до бэклога и дальше бэклога в виде Value Stream Mapping (VSM) – карты создания ценности. Отслеживайте путь от появления идеи в голове клиента, сотрудника или стейкхолдера – до момента, когда клиент реально получит ценность. Где-то между этими двумя точками и будет ваш backlog либо очередь задач.
-
Определите критерии готовности к взятию в работу (DoR) – в Kanban эту точку называют «первая точка взятия обязательств». Найдите тот момент, когда:
-
бизнесу все еще нужно решение;
-
а команда уже может быстро начать реализацию. Это и есть зона Definition of Ready, где задача считается «готовой к разработке».
-
-
Наполните Discovery теми этапами, которых команде не хватает. У вас же в любом случае есть какие-то этапы, согласно которым задачи попадают в backlog – скорее всего, часть этих этапов сконцентрирована в голове у заказчика, часть – у владельца продукта. Перенесите все это в любой трекер – в Jira, Trello, Kaiten, Asana или хотя бы в Excel. И начните там собирать метрики. Как только вы отразите Discovery визуально, сразу заметите, что данных не хватает. Это нормально. Но даже минимального набора метрик уже достаточно, чтобы делать первые прогнозы. В идеале – накопите данные за 6–12 месяцев. Тогда можно будет строить оценки с погрешностью 5–7%, а это уже хороший уровень точности.
-
Найдите того, кто может сказать «Нет» заказчику. Если таких нет, почитайте статью «5 способов сказать "нет" стейкхолдеру». Или, если вы работаете по Scrum, возьмите кого-то, кто на два уровня выше команды, и поставьте его владельцем продукта. Пусть он сам ведет переговоры с бизнесом. А команда в это время должна работать спокойно, без давления.
-
Настройте декомпозицию – понятную заказчику и команде (от эпика до story, и от story до тасков).
-
Используйте WSJF для приоритизации – более ценную и более короткую работу сначала.
Вопросы и ответы
Кто должен быть драйвером изменений в Discovery-процессе? Потому что внедрять продуктовую идеологию в Delivery ребятам реально интересно. А вот Discovery обычно никому не интересно – там люди деньги зарабатывают.
На этот вопрос есть два ответа:
-
Если мы идем из парадигмы Scrum, то ответственность за Discovery лежит на владельце продукта и команде, потому что Discovery в Scrum встроен в работу всей команды, а конкретная реализация – уже вопрос договоренности. Но на практике этот процесс чаще всего тянет владелец продукта.
-
Если мы идем в парадигме Kanban либо в парадигме SAFe, то там выделяется отдельная роль – Service Request Manager, менеджер запросов. Это тот человек, который объективно на цифрах говорит заказчику обоснованное «Нет», и это его основная функция.
Как научиться говорить заказчикам «Нет»? Вы говорили, что нужно прочитать статью или привлечь человека на два уровня выше. Но если люди на два уровня выше не заинтересованы в том, чтобы решать эти проблемы? Они говорят: «У вас есть команда, есть свой руководитель, разбирайтесь сами».
Единственный язык бизнеса – это цифры. Неважно, сколь умными и прокачанными вы будете, насколько логические цепочки выстроите, пока вы не покажете на цифры и не ткнете носом заказчика в то, что предлагаемая «шикарная» идея – пустая трата ресурсов, вас просто не услышат. Поэтому метрики – наше все.
Как тогда добыть эти цифры? Объясню на примере из практики с 1С-командами. Когда я начинаю рассказывать 1С-разработчикам про продуктовый подход, то слышу в ответ: «Это всё работает только где-нибудь во фронтенде, в крупных компаниях, а у нас в 1С – своя специфика. Нам никакие исследования не нужны, это пустая трата времени». Что делать в такой ситуации?
Как только у бизнеса появляется какая-то гениальная идея, мы сразу задаем вопрос: «А в чем здесь бизнес-метрика? Зачем мы это делаем? Чтобы заработать? Чтобы сэкономить? Сколько, на ваш взгляд, эта идея принесет?» Даже если ответ – пальцем в небо, мы эту цифру фиксируем. Главное – потом обязательно замерить реальный результат и сравнить его с ожиданиями. Без упреков, просто по фактам.
Со временем, после нескольких таких сравнений, бизнес сам начинает задумываться: «А может, лучше пусть аналитик посчитает?» – и это тоже подойдет. Никто сразу не даст конкретной цифры. Это эволюционная практика, но она одна из самых значимых для роста зрелости команды и компании в целом, потому что оценка уже идет не по принципу «неважно, во что это обойдется, просто берем и делаем», а по всей цепочке создания ценности.
Вопрос по поводу человека, который будет стоять между владельцами автоматизируемых процессов и командой – выполнять роль реквест-менеджера. Может ли он быть аналитиком, и насколько глубоко ему нужно погружаться в предметную область конкретных бизнес-процессов?
Даже если он на старте не владеет этой предметной областью, его быстро погрузят – и он сможет включиться в работу за месяц-полтора. Но если он уже будет погружен, это даст чуть более быстрый старт.
Другое дело, что бизнес-аналитику, возможно, потребуется помощь именно с встраиванием важных этапов в процесс Discovery, чтобы не забыть бизнес-ценность, бизнес-метрики, декомпозицию, оценку. А в целом бизнес-аналитик будет довольно выгодно смотреться на этой позиции.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Анализ & Управление в ИТ-проектах.