Каким образом компания получает прибыль? Она предоставляет услуги, либо производит какие-то продукты – делает что-то, что потом покупает клиент. Это является источником прибыли. Соответственно, если исходить с этой точки зрения, то всю абсолютно деятельность компании, любые действия, совершаемые сотрудниками компании, можно условно поделить на два вида:
- Действия, которые добавляют ценность продукту,
- И действия, которые ценность продукту не добавляют.
Ценность – имеется в виду что-то полезное для заказчика, для потребителя этого продукта.
Все, что не добавляет ценности – это потери, с которыми надо всячески бороться. Потери бывают, если говорить укрупнено, двух видов:
- Те, которые можно устранить полностью в ноль.
- И те, которые нельзя устранить – их можно только минимизировать. Яркий пример потери, которую нельзя устранить – это бухгалтерский учет. Мы обязаны вести бухгалтерский учет, но само по себе наличие у нас в компании бухгалтерского учета никакой ценности нашему продукту для его потребителя не добавляет.
Инструменты для работы с потерями в Lean
Lean содержит в себе достаточно обширный набор инструментов, с помощью которых эти потери можно находить, классифицировать, бороться с ними.
Сама система изначально родилась на производстве, причем на классическом многопередельном MRP-производстве, но многие из этих инструментов могут быть с успехом применены и в работе офиса. Собственно, в компании, в которой я работал, с 2007 года идет процесс внедрения Lean, и достаточно много инструментов показали свою эффективность при использовании в офисе. Правда, не все.
Давайте вкратце рассмотрим те инструменты, которые мы пробовали внедрять. Все рассматривать не будем, только те, которые действительно смогут принести какую-то пользу при использовании в офисе.
Канбан

Первый инструмент – Канбан.
Про него, наверное, многие слышали, но, возможно, разное. По сути, Канбан представляет собой вытягивающую систему, когда в ходе какого-то процесса у нас идет постепенное преобразование продукта (либо информации) и по очереди – передача различным исполнителям.
- Есть система выталкивающая, когда тот, кто сделал, передает дальше, на следующий шаг.
- А есть система вытягивающая, когда тот, кто стоит следующим, говорит: «Дай мне в обработку». Канбан – это как раз вытягивающая система.
Где мы нашли для нее хорошее применение?
- Материалы;
- Комплектующие;
- Аксессуары;
- Расходные материалы, которые используются в работе ИТ-подразделений – мышки, клавиатуры, картриджи, всякая мелочь.
С помощью Канбан очень удобно управлять всем этим хозяйством, при этом не нужно затрачиваться на автоматизацию. Мы же часто страдаем от того, что «сапожник без сапог» – ИТ-шники всех вокруг автоматизировали, а на свои собственные процессы уже не хватает ни времени, ни желания. Канбан позволяет решить эту проблему.

На слайде показано, каким образом выглядит классическая карточка Канбан. Она содержит в себе:
- Название номенклатуры;
- Количество штук в упаковке;
- Даты передачи и поступления;
- Поставщик;
- И подпись.
Как это используется у нас?
- На склад приходит заявка на какую-то комплектующую, которая нужна сотруднику;
- Ему эту комплектующую приносят вместе с такой карточкой Канбан;
- Сотрудник в ней расписывается, что получил эту комплектующую;
- И эту карточку Канбан кладут в специальный ящик;
- В конце периода (недели или месяца) открывают этот ящик, сортируют все, что в нем лежит, и составляют на основании этого заказ поставщику, чтобы восполнить остатки.
Очень простая, понятная и удобная система. Экономит кучу времени и сил на организацию бесперебойного наличия материалов и комплектующих.
Супермаркет

В продолжение этой темы – инструмент «Супермаркет». Что это такое?
Чтобы мы могли называть склад супермаркетом, нужно выполнить одно условие. Для каждой номенклатуры, которая может на нем храниться, нужно установить два значения – минимум и максимум. Это – классическая модель управления запасами, когда у нас есть:
- Некий максимальный уровень, больше которого не должно быть;
- И некий минимальный уровень, при котором мы совершаем заказ.
Когда у нас остатки доходят до минимального уровня, мы делаем заказ так, чтобы они восполнились до максимального, а от минимального до нуля – это тот запас, который мы можем расходовать, пока товар не приехал. За это время мы доходим до нуля, но в дефицит не проваливаемся.
Самое сложное здесь – это правильно посчитать эти уровни. Кому интересно – это классическая задача теории управления запасами, можете поискать в интернете про формулу Уилсона и ее модификации.
5С

5С – это интересный и достаточно спорный инструмент, в общем-то, рационализация рабочего пространства, состоящая из пяти действий. В чем заключается суть?
- В том, что рабочее место нужно содержать в чистоте;
- Инструменты, принадлежности должны быть разложены на определенных местах, а не как попало;
- Для всего должны быть стандарты;
- Все должно лежать в определенном порядке;
- И нужно постоянно заниматься совершенствованием.

Вот пример, как может выглядеть рабочее место, где используется 5С. Кто-нибудь видит какие-то проблемы на этой картинке? На этой картинке все нормально. Это – хороший пример 5С.

Вот эта картинка – тоже 5С. Есть ли здесь какие-то проблемы?
На этой картинке вообще все абсолютно плохо и совершенно бессмысленно. От того, что у вас на рабочем столе мышка будет лежать на 5 сантиметров левее или правее, не изменится вообще ничего.
- Когда у нас на производстве есть какие-то посты, на которых за одним и тем же столом посменно могут работать разные люди, там да, там 5С работает, потому что человек, не задумываясь о том, на каком он посту, тянет руку и не глядя, берет нужный ему инструмент, лежащий на своем месте.
- А в офисе крайне редко так бывает, чтобы несколько людей работали за одним столом, за одним компьютером, под одной учетной записью.
Когда у нас внедряли 5С, была попытка сделать стандарты рабочих столов компьютеров, включая расположение ярлыков по зонам – решили, что это все должно быть стандартизировано. Когда это дошло до ИТ-подразделения, мы им первым делом показали рабочий стол нашего инженера сети передачи данных, который состоял из черной консоли с зеленым маркером приглашения. После этого от нас отстали.
Всеобщая эксплуатационная система

Еще один интересный инструмент – это «Всеобщая эксплуатационная система». Изначально он был придуман для промышленного оборудования – для станков. Не принципиально, какие станки, но этот инструмент всегда ассоциируется с какими-то станками, с производством, с цехом.
Оказалось, что все принципы «Всеобщей эксплуатационной системы» замечательно применяются для серверного и телекоммуникационного оборудования.

Всего шесть основных принципов. Давайте на них остановимся чуть подробнее.
Стандартизация.
У нас в компании разрабатываются:
- СОК (стандартные операционные карты)
- КОО (карты обслуживания оборудования).
Что они из себя представляют?
- Это такой небольшой документ, обычно на несколько страниц.
- Формат у него может быть различный – это может быть презентация в PowerPoint, Excel – не принципиально.
- По сути, похоже на комикс: картинка и к ней – поясняющий текст. Упор на иллюстрацию, на графическое представление. Например, есть сервер, который нужно обслуживать – менять для него термопасту, смазывать вентиляторы и чистить от пыли:
- Процесс разборки сервера и его обслуживания просто фотографируется,
- К этим фотографиям делается описание, где каждое действие расписывается:
- Открутить вот эти болты, снять крышку;
- Открутить болт, снять процессор;
- Вот так пасту снять;
- Вот так намазать;
- Вот здесь продуть.
- И рядом с каждой операцией еще и фиксируется время – сколько времени должна занимать эта операция.
В результате, обслуживание упрощается, так как всегда есть шпаргалка, к которой можно обратиться. И если ты этот сервер давно не обслуживал и не помнишь, как у него выкрутить какой-то винтик, который сразу не видно – у тебя всегда под рукой есть такая шпаргалка. Очень полезная вещь.
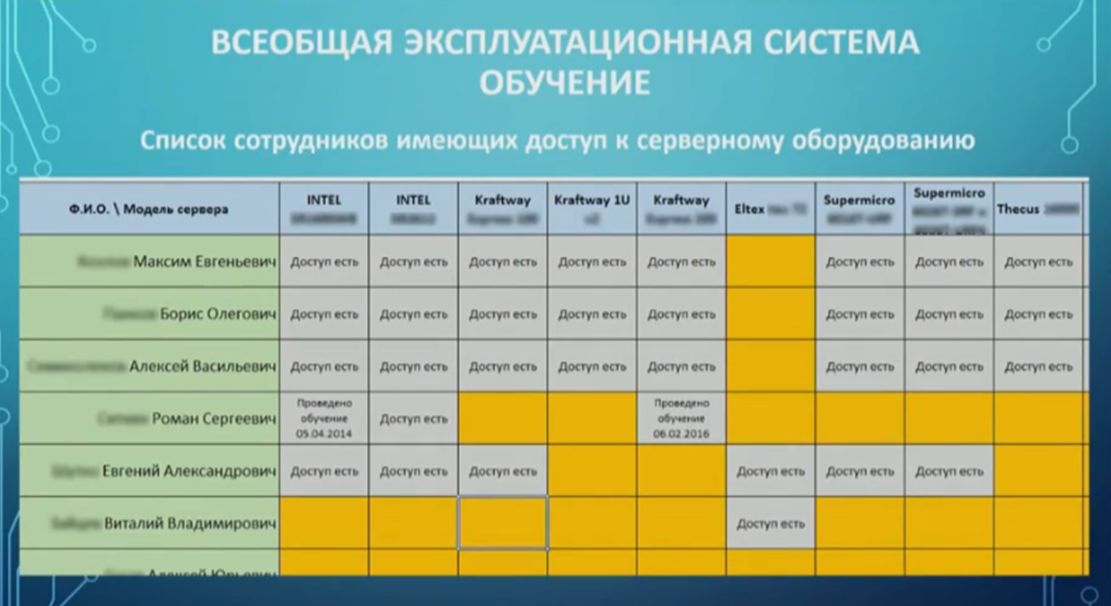
Следующий пункт – это обучение.
Проводится обязательное обучение, как внутреннее, так и внешнее.
Составляется вот такая матрица, в которой зафиксировано, какой сотрудник с каким оборудованием может работать, потому что он прошел по нему обучение, и мы уверены, что он его знает и не сломает.
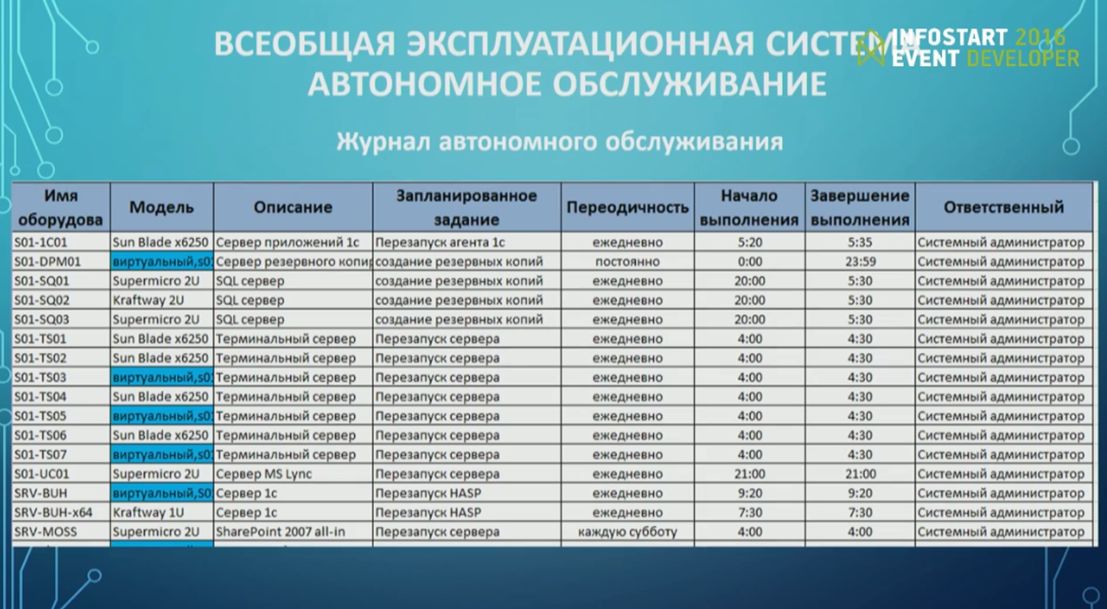
Следующий пункт – это автономное обслуживание.
Предполагается, что оборудование нужно обслуживать максимально автономно. В случае с ИТ это как раз просто – у нас должны быть скрипты, которые сами обслуживают оборудование. Выглядит это так, как на скриншоте – планируются определенные работы, которые выполняются на оборудовании. Для этого устанавливается регламент:
- С серверов баз данных снимаются резервные копии;
- Остальные сервера перезагружаются.
И дальше люди должны просто контролировать, что этот регламент исполняется.
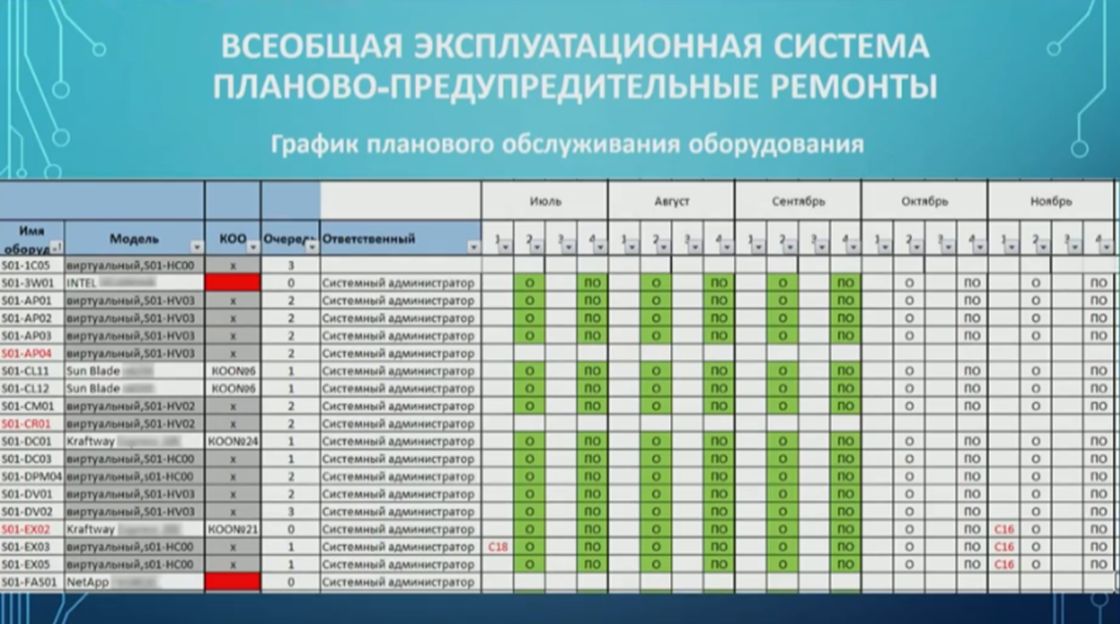
Дальше – планово-предупредительные ремонты.
То, что для классического станка – планово-предупредительный ремонт, для серверного оборудования – чистка от пыли, замена термопасты, и, кроме того, работы, связанные с программным обеспечением.
По каждой единице оборудования понедельно планируются операции:
- Обозначение «О» – это установка обновлений;
- Обозначение «ПО» – плановое обслуживание (плановая перезагрузка и еще несколько вариантов).
Суть в том, что эту работу нужно планировать.
- Должен быть составлен график ее выполнения
- И дальше, системный администратор или другое ответственное лицо настраивает соответствующие скрипты и сценарии, которые обеспечивают исполнение всего этого.
- И дальше его задача – просто контролировать, что все отрабатывает в срок и без ошибок.
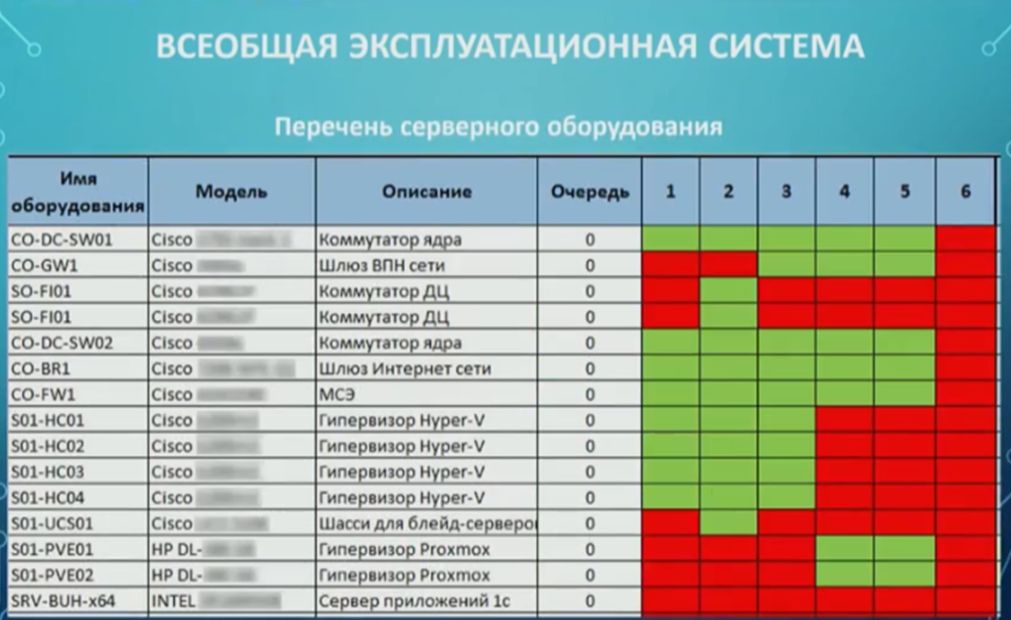
И для того, чтобы понимать, насколько по конкретной единице оборудования уже внедрены принципы «Всеобщей эксплуатационной системы», делается вот такая табличка. Поскольку оборудования много, и сразу по всем пунктам выполнить работы не получается, оборудование ранжируется:
- Для него присваивается понятие «очереди»;
- А также обозначается его состояние по этим самым 6 принципам:
- Зеленым отмечается, если принцип на данной единице оборудования внедрен;
- Красным – если не внедрен;
- Если по какой-то причине оборудование специфическое и принцип неприменим, закрашиваем серым.
Мы для себя выделили три очереди – нулевую, первую и вторую. Ранжирование производится по цене простоя:
- Нулевая очередь – это элементы сетевой инфраструктуры и какие-то базовые ключевые сервисы, типа службы каталогов. Если отказали они, то встало почти все.
- Первая очередь – это то оборудование, на котором висят прикладные системы, критичные для бизнеса.
- И вторая очередь – это различные вспомогательные системы, без которых можно обойтись.
Вот эта картинка, особенно в динамике, позволяет очень хорошо видеть свой прогресс, куда мы вообще движемся и насколько мы близки к идеалу. Соответственно, ставится задача:
- К определенному периоду внедрить все 6 принципов на всем оборудовании нулевой очереди;
- Дальше – на оборудовании первой очереди;
- И т.д.
Защита от ошибок

Защита от ошибок – называется замечательным японским словом «пока-ёкэ».
Применимо везде. Здесь нужно помнить простой принцип: «Если пользователь может совершить ошибку, он ее совершит» – это закон Мёрфи для ИТ.

Этот принцип можно использовать при проектировании интерфейсов:
- Интерфейсы должны быть такие, чтобы пользователь ошибиться не мог.
- Везде должны быть проверки на корректность данных. Вспоминаем прекрасную историю про запуск ракеты, когда датчик угловой скорости забили не той стороной. Там еще и провода специально были определенной длины, чтобы при вставке не той стороной провода не хватало. Подпаяли провода, матеря тупых конструкторов, которые не могли провода подлиннее сделать.
- Еще пара замечаний касаемо разработки на 1С. Особенно при использовании не своего функционала рекомендуется реализовывать параноидальные проверки для параметров, полученных в функциях и процедурах, особенно для тех параметров, которые могут не передаваться (для них заданы значения по умолчанию).
- Всегда помним про динамическую типизацию – проверяем типы значений;
- Также помним про Неопределено, потому что если должна приходить ссылка, а придет Неопределено, то когда мы попытаемся обратиться «по точке», получим ошибку.
Кайдзен

Есть еще такая штука – Кайдзен. По сути, это процесс непрерывного совершенствования
Идея этого инструмента заключается в том, что можно долго, тщательно планировать какое-то крупное изменение, выполнять много работы, а потом его внедрить и сразу получить прирост производительности на много процентов. А можно постепенно, каждый день, делать какие-то маленькие точечные улучшения. По чуть-чуть, но каждый день, все время, несколько раз в день. И тогда суммарный количественный накопительный эффект существенно превысит любые разовые прыжки.

Каким образом работает Кайдзен?
Создаются Кайдзен-команды – термин японский, мне ближе все-таки термин «Рабочая группа». Обязательно собираются люди из разных подразделений. Это очень важный момент. Внутри одного подразделения Кайдзен работать не будет. Должны быть люди из разных подразделений.
Часто технику Кайдзен используют для решения проблемы. И проблемы у нас чаще всего возникают не внутри подразделения, а на стыке, между подразделениями, когда идет передача, и каждый валит какие-то проблемы на соседнее подразделение: «Это они нам не предоставили, это они не отработали. Мы заявку разместили, а они ничего не сделали».
Для того, чтобы такие проблемы решать, собирается команда.
- Чтобы она получила полномочия, а не «просто так» посидели, издается приказ по предприятию за подписью руководителя, либо распоряжение о создании этой команды.
- Лидер команды наделяется необходимыми полномочиями;
- Собираются, придумывают решение, реализовывают его, все это документально оформляется. Суть в том, что это должно быть ежедневной регулярной работой. Можно вести листы проблем, которые возникают, и потом создавать кайдзен-команды для решения конкретных проблем. У нас регулярно создаются команды, ставятся задачи. Например, «в три раза сократить время размещения заказа», «в два раза уменьшить складские остатки». Могут создаваться большие команды, до 10 человек, которые могут работать по несколько месяцев. В них могут включаться руководители, они придумывают какие-то идеи, пробуют их реализовывать, и, чаще всего, задача решается.
- По итогам решения, если все получилось и есть экономический эффект, нужно всех премировать.
- И выделено важное условие – что нужно проводить изменения таким образом, чтобы обратно откатиться было нельзя. Эти изменения нужно фиксировать регламентами, либо в информационной системе. Логику работы перестроили – все, работаем по-новому. Хочешь – не хочешь, по-старому уже не получится, вариантов не будет.
Быстрая переналадка

Быстрая переналадка – еще одно понятие в бережливом производстве. Оно опять же касается оборудования, когда нужно перестраивать производственные линии, но также его можно применять и в ИТ.
Есть тут кто-нибудь, кто еще не использует серверную виртуализацию? У меня для вас один совет – начните ее использовать. Это – очень хороший инструмент.
- Накладные расходы на саму виртуализацию минимальны, при этом куча бонусов по лицензированию, по возможностям изменения параметров, по созданию изолированных сред и т.д.;
- Кроме этого, рекомендуется использовать какие-то специальные программы-контейнеры – тот же Docker или Vagrant;
- Используйте образы для развертывания систем.
Технологий, которые позволяют ускорить процессы, связанные с развертыванием инфраструктуры, с развертыванием рабочих мест – очень много.
Представьте себе, вам необходимо изменить конфигурацию сервера или добавить ему памяти:
- Если сервер аппаратный – пошли в серверную, выключили, вынули из стойки, сняли крышку, вставили планку, закрыли крышку, вставили обратно, включили.
- А если сервер виртуальный – зашли в «Менеджер управления виртуальными машинами» и передвинули ползунок.
Разница по времени очевидна.

Вот иллюстрация того, как должна выглядеть быстрая переналадка.
Нужно тщательно подготовить все заранее, потому что когда машина подъезжает к пит-лейну, никто не бежит с колесом, все уже стоят наготове и ждут. Все, что можно сделать по предварительной подготовке к выполнению операции, нужно сделать до того, как сервис остановлен или выключен (если это требует выключения, либо остановки сервиса).
Картирование потока.

Возвращаясь к определению бережливого производства, суть метода «Картирование потока» заключается в том, что у нас есть:
- Действия, операции, которые увеличивают ценность – создают ценность для потребителя;
- И те, которые не создают ценности.
Что позволяет сделать картирование потока?
- Мы берем некий поток – это некая итерация процесса, не обязательно всего, а какой-то части – последовательность каких-то действий, выполняемых различными участниками.
- Мы берем специального человека, даем ему секундомер. Он берет этот секундомер и замеряет время, затрачиваемое каждым участником процесса на выполнение каждого действия. И все это на листочке фиксирует.
- Этот замер производится несколько раз. Нужно выбирать потоки, которые выполняются часто.
Классический пример – согласование договора. На входе в поток у нас проект договора, на выходе – подписанный договор. Если компаний много, в день может приходить по несколько штук договоров. Это процесс, который повторяется часто.
- Фиксируются полностью все действия, которые возникают внутри;
- И дальше эти действия классифицируются по принципу создания ценности:
- Когда юрист проверяет договор, это создает ценность, потому что он снижает наши риски.
- Когда договор лежит в папке у секретаря, ожидая подписи начальника – это не создает ценности, потому что это – потери времени на ожидание.
- Соответственно, когда мы все действия разложили на те, которые добавляют ценность и не добавляют ценность, мы считаем время:
- У нас есть время выполнения каждой операции. Мы его суммируем и получаем общее время выполнения потока;
- А также у нас есть общее время тех операций, которые добавляют ценность;
- И тех, которые не добавляют ценность.
- Отношение вот этой длины, когда мы создаем ценность, к общей длине потока, определяет коэффициент его эффективности.
Когда мы впервые начали использовать у себя такой подход и считать какие-то массовые потоки, у нас получились какие-то совершенно пугающие цифры. По тем потокам, с которых мы начинали работу, когда все это запускалось, у нас коэффициент эффективности был меньше процента, иногда доли процента. Хотя казалось, что все хорошо, что компания сертифицирована по СМК, процессы все прописаны, высокий уровень внутренней автоматизации. Но когда мы посмотрели на все эти процессы под другим углом, оказалось, что местами все весьма печально, и есть куча потерь, связанных с неэффективной работой, с огромными ожиданиями. Это – хороший инструмент, который позволяет выявить такие ситуации.
Была ситуация, когда прокартировали какой-то поток и выяснилось, что огромное количество времени тратится на то, что какой-то сотрудник вручную сводит какие-то данные – из нескольких табличек собирает все это в одну. Мы это элементарно автоматизировали и огромные потери времени сразу же ушли. Когда его спросили: «Почему ты молчал?», он ответил: «Но я же всегда так работал, я понятия не имел, что здесь можно что-то сделать». Когда спросили у его начальника: «Почему он молчал?», он ответил: «Но он же всегда так работал и не жаловался».
Этот инструмент позволяет выявить такие места, где есть резервы для улучшений, и операции, которые можно сократить.
Им достаточно просто пользоваться, потому что после того, как мы собрали все данные, у нас есть некое графическое представление. Никакой жесткой нотации для него нет. Например, можно рисовать вот таким образом:
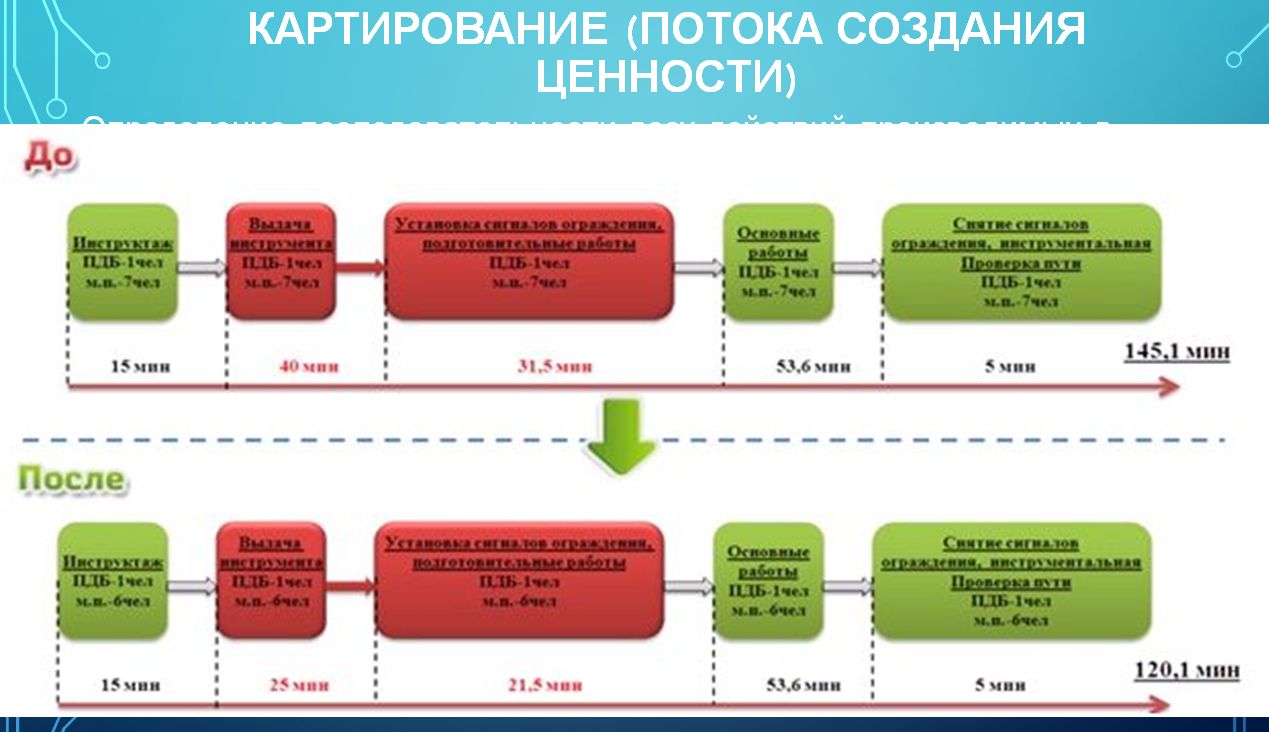
Или вот таким образом:

Смысл в чем?
- Сначала мы собираем эту карту.
- Потом ищем точки, где мы можем улучшить – нам необходимо избавиться от красных квадратов, либо уменьшить их длительность.
- После того, как мы определили мероприятия, которые можно сделать, мы их делаем.
- После того, как сделали – повторно картируем. Смотрим результат, сравниваем – достигли/не достигли, насколько выросла эффективность.
- После того, как прошло какое-то время, желательно вернуться и прокартировать еще раз и посмотреть, а не свалились ли мы обратно.
Если говорить про основные инструменты, которые приносят пользу при офисной работе из инструментария бережливого производства – то это, пожалуй, все. Естественно, их намного больше. В сети вы можете найти про них огромное количество информации – тема вообще достаточно большая и интересная.
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2016 DEVELOPER.