Обратите на текст запроса, который возвращает эта функция. В типовой УТ он используется порядка 500 раз. Его добавляют в отчеты, модули документов и так далее. Думаю, Вы уже догадались, если организация торгует штучным товаром и не объединяет товар в упаковки, то этот запрос просто возвращает число 1. Функциональная опция «ИспользоватьУпаковкиНоменклатуры», на подстановку не влияет.
Например, при формировании запроса по подбору заменил строки кода
ШаблонТекстаЗапроса = СтрЗаменить(ШаблонТекстаЗапроса,"&ТекстЗапросаКоэффициентУпаковки1",
Справочники.УпаковкиЕдиницыИзмерения.ТекстЗапросаКоэффициентаУпаковки("ЦеныНоменклатуры.Упаковка","ЦеныНоменклатуры.Номенклатура"));
На код
ШаблонТекстаЗапроса = СтрЗаменить(ШаблонТекстаЗапроса,"&ТекстЗапросаКоэффициентУпаковки1",1);
и подбор товаров стал работать в два раза быстрее.
Если Вам будет интересно, я напишу обработку для проверки – можно ли в Вашей базе заменить текст запроса на 1.
Понятно, что регистрация и обработка ошибки занимает определенное время поэтому необходимо ежедневно просматривать журнал регистрации и технологический журнал, непримиримо устранять источники ошибок. Воспользуемся результатами статьи //infostart.ru/public/825405/ пункт «Наиболее частые ошибки»
При анализе технологического журнала было выявлено много событий EXCP (Например, до 11 тысяч в час). Сравнил с журналом регистрации, выяснил — это фоновые задания, которые запускаются, например при «Быстром поиске» в списке заказов, в списке номенклатуры а затем прерываются: пользователь не дождался. В журнале регистрации фоновое задание отменено или прервано.
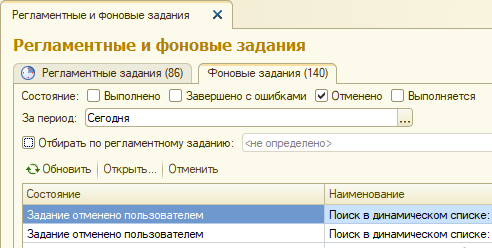
Очевидно, что незавершенных фоновых заданий должно быть меньше, а пользователи должны принимать решение о поиске более ответственно. Оптимизация динамического списка – в следующем пункте.
Кстати, некоторые RLS ограничения тоже выглядят лишними. В технологическом журнале их можно искать по слову "DUMMY".
Нужно отключать типовой поиск, который запускает фоновые задание. Кроме этого, обязательно нужно ограничивать период (для списка документов). Журнал документов за месяц открывается в двенадцать раз быстрее, чем за год. Динамическое считывание отключил: лучше один большой запрос, чем много маленьких. Все изменения нужно делать не в форме, а в коде. В общем, предлагаю такой вид процедуры в форме списка:
Процедура ПриСозданииНаСервере(Отказ, СтандартнаяОбработка)
Элементы.Список.ПоискПриВводе = ПоискВТаблицеПриВводе.Авто;
Элементы.Список.ПоложениеСтрокиПоиска = ПоложениеСтрокиПоиска.Нет;
Элементы.Список.Период.ДатаНачала = ДобавитьМесяц( ТекущаяДата(), -1 );
Элементы.Список.Период.ДатаОкончания = ДобавитьМесяц( ТекущаяДата(), 1 );
Список.ДинамическоеСчитываниеДанных = Ложь;
...
КонецПроцедуры
Для списка справочника номенклатуры потребовалось изменить модуль менеджера:
Процедура ОбработкаПолученияДанныхВыбора(ДанныеВыбора, Параметры, СтандартнаяОбработка)
Если Параметры.Свойство("СтрокаПоиска")
И ТипЗНЧ("Параметры.СтрокаПоиска") = Тип("Строка")
И СтрДлина(Параметры.СтрокаПоиска) = 1 Тогда
СтандартнаяОбработка = Ложь;
Возврат;
КонецЕсли;
...
КонецПроцедуры
При вводе одной буквы в списке теперь не запускается фоновое задание, а появляется окошко поиска. Добавление кода лучше видно при обновлении, чем изменение визуальной формы. Если работаете с расширениями конфигурации – используйте расширение. Не забудьте указать правильное имя элемента формы-списка и протестировать.
И наконец моя мечта сбылась !! Как известно, при объектном чтении элемента справочника программа 1С считывает и кеширует все реквизиты. Запрос в формате SDBL имеет вид: «SELECT ID, Version, Marked, PredefinedID…». Объектные чтения, которые происходят в форме элемента в событии ПриЧтенииНаСервере() неизбежны, но имеют другой формат запроса. Воспользуемся результатами статьи //infostart.ru/public/825405/ - с помощью GIT BASH суммируем все контексты по таким запросам.
Как он работает пошагово – рассказывал в упомянутой статье, повторяться не буду. Специалисты, которые профессионально занимаются анализом технологического журнала, используют свои привычные скрипты. Они тоже смогут воспользоваться этими результатами: достаточно добавить фильтр по тексту запроса. Простая идея, но подобных примеров поиска не встречал. В своей базе нашел несколько случаев объектного чтения и с удовольствием их устранил.
Как Вы понимаете, такие запросы работают без ошибок на уровне СУБД и на уровне 1С, но если полученные поля типа хранилище значений не используются, то трафик СУБД-1С можно уменьшить.
Сначала в программе 1С выберем SDBL-имена для полей типа хранилище значений. У меня получился примерно такой код для внешней обработки:
&НаСервере
Процедура ПриСозданииНаСервере(Отказ, СтандартнаяОбработка)
ПоляТипаХранилище = "";
СтруктураБазы = ПолучитьСтруктуруХраненияБазыДанных();
Для каждого СтрокаСтруктурыБазы Из СтруктураБазы Цикл
Для каждого СтрокаСтруктурыПолей Из СтрокаСтруктурыБазы.Поля Цикл
СтрокаТЧ = Объект.ТабличнаяЧасть1.Добавить();
СтрокаТЧ.ИмяТаблицыХранения = СтрокаСтруктурыБазы.ИмяТаблицыХранения;
ЗаполнитьЗначенияСвойств(СтрокаТЧ, СтрокаСтруктурыПолей);
Если СтрНайти(СтрокаСтруктурыБазы.Метаданные, "Справочник.") > 0
И СтрНайти(СтрокаСтруктурыБазы.Метаданные, "ТабличнаяЧасть") = 0
И СтрокаСтруктурыПолей.ИмяПоля <> "" Тогда
ИмяСправочника = СтрЗаменить(СтрокаСтруктурыБазы.Метаданные, "Справочник.", "");
МетаСправочник = Метаданные.Справочники[ИмяСправочника];
Реквизит= МетаСправочник.Реквизиты.Найти(СтрокаСтруктуры.ИмяПоля);
Если Реквизит <> Неопределено
И Реквизит.Тип.СодержитТип( Тип("ХранилищеЗначения") ) Тогда
ПоляТипаХранилище = ПоляТипаХранилище + ?(ПоляТипаХранилище="","","|") + СтрокаСтруктуры.ИмяПоляХранения;
КонецЕсли;
КонецЕсли;
КонецЦикла;
КонецЦикла;
Объект.ПоляХранилищ = "cat *.* | egrep '\.(" + ПоляТипаХранилище + ")\b' --color -A3 -B3";
КонецПроцедуры
Итоговая строка имеет вид cat *.* | egrep '\.( ПоляТипаХранилище)\b' --color -A3 -B3 Копируем в командную строку GIT BASH и запускаем.
В этой функции запрос к таблице периодического регистра будет быстрее запроса к срезу последних.
ВЫБРАТЬ РАЗРЕШЕННЫЕ
МАКСИМУМ(Цены.Период) КАК Период
ИЗ
РегистрСведений.ЦеныНоменклатуры КАК Цены
ГДЕ
Цены.ВидЦены В(&ВидыЦен)
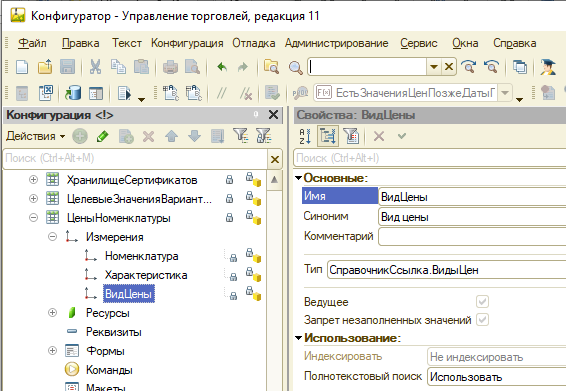
В регистре ЦеныНоменклатуры включено использование Среза последних. Поэтому запросы используют разные таблицы данных в качестве источника. Для измерения «ВидЦены» включен признак «Ведущее», поэтому индексирование недоступно, индекс в регистре существует, НО индекс в таблице среза НЕ существует, о чем честно написано в документации https://its.1c.ru/db/metod8dev/content/1590/hdoc. Поэтому любые отборы по второму (третьему) измерению без условий на предыдущие измерения в таблице среза цен вызывают сканирование таблицы. Это нужно иметь ввиду.
P.S. На логотипе статьи часы с подводной лодки. Символизируют секунды. Мой коллега плавал.
Вступайте в нашу телеграмм-группу Инфостарт