




Для начала надо понимать, что задача возникла не на ровном месте. Время от времени rphost росли до 20-30GB, или обнаруживались зависшие сессии в сутки, а то и более. "Проблемых" пользователей ловили через консоль, но помогало это относительно - пользователи через день уже не помнили что запустили, поиск по журналу за сутки занимал много времени и не всегда заканчивался успехом, в общем процесс надо было как-то ввести в управляемое русло.
Наверняка поставленную задачу можно решить другими способами и более эффективно и предложенное решение можно и нужно критиковать. Скажем это был неплохой повод изучить новые технологии и расширить горизонты :-). Ну и не пришлось отвлекать программистов 1С от основной работы - пиления бизнес-фич.
Статья - не полноценная инструкция по разворачиванию системы (и так получилась какая-то огромная для меня). Скорее описан подход к решению проблемы. И вопрос оптимизации этого подхода для меня скорее открыт, чем решен :-)
Структура решения вкратце
- "1C Remote Administation Client" (RAC) подключается к "1C Remote Administation Server" (RAS) и получает информацию о кластере 1С.
- Скрипт в Powershell запускает RAC, структурирует полученную от него информацию, и посылает ее в базу MySQL.
- В базе MySQL к полученным записям добавляется время получения этих записей.
- Grafana с помощью специфических запросов в MySQL визуализирует данные о кластере 1С.
- Использую Notification channels из Grafana рассылаем уведомления о проблемах заинтересованным лицам.
Как ставить и запускать службу RAC/MySQL/Grafana рассказывать не буду - информации достаточно.
Создаем базу MySQL для хранения данных:
CREATE DATABASE 1c_monitoring; ALTER DATABASE 1c_monitoring CHARACTER SET utf8 COLLATE utf8_general_ci;
Создаем таблицу сессий
use 1c_monitoring
create table sessions(
id serial primary key,
server varchar(255) NOT NULL,
clock timestamp,
uuid varchar(36) NOT NULL,
base varchar(255),
user varchar(255) ,
type varchar(255) NOT NULL,
started timestamp,
last timestamp,
sleep bool default false,
current BIGINT,
5min BIGINT,
total BIGINT,
duration_cur bigint(20),
duration_db_cur bigint(20)
);
Что бы работали запросы Grafana в базу MySQL необходимо убрать режим "ONLY_FULL_GROUP_BY", для этого нужно указать все необходимые (те что уже есть) режимы исключив "ONLY_FULL_GROUP_BY"
SET GLOBAL sql_mode = 'STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
Рекомендуется сделать специального пользователя MySQL для удаленных подключений к базе 1c_monitoring (у меня adm1c)
В Grafana через web-интерфейс прописываем созданную БД как Data Sources:
| Name | MySQL 1C |
|---|---|
| MySQL Connection | |
| Host | mysql:3306 |
| Database | 1c_monitoring |
| User | adm1c |
| Password | Ну понятно |
На сервер с кластером 1С ставим mysql-connector-net и подключаем PowerShell скрипт, который раз в 5 минут считывает для каждой активной сессии имя пользователя, Память(текущая),Память(5 минут), Память(Всего) и время старта сессии и вставляет из в БД (скриптик приложен - как-то страшно его показывать, т.к. выглядит... не идеально)
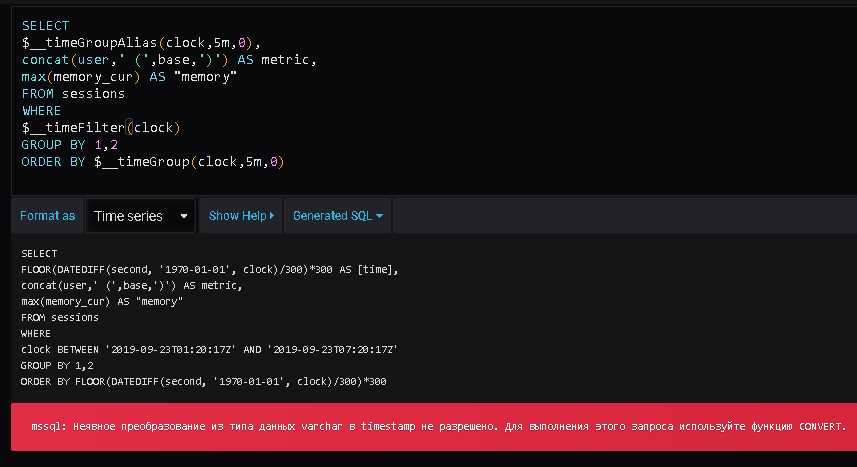
Данные в БД мы получили - приступаем к визуализации. Добавляем в Grafana dashboard, в него panel, в разделе metrics вводим запрос к графане (синтаксис там SQL-подобный с использованием специальных агрегатных функций Grafana, которые начинаются с "__"):
SELECT
$__timeGroupAlias(clock,5m,0),
concat(user,' (',base,')') AS metric,
max(Current) AS "memory"
FROM sessions
WHERE
$__timeFilter(clock) and
server = 'SRV-BASE'
GROUP BY 1,2
ORDER BY $__timeGroup(clock,5m,0)
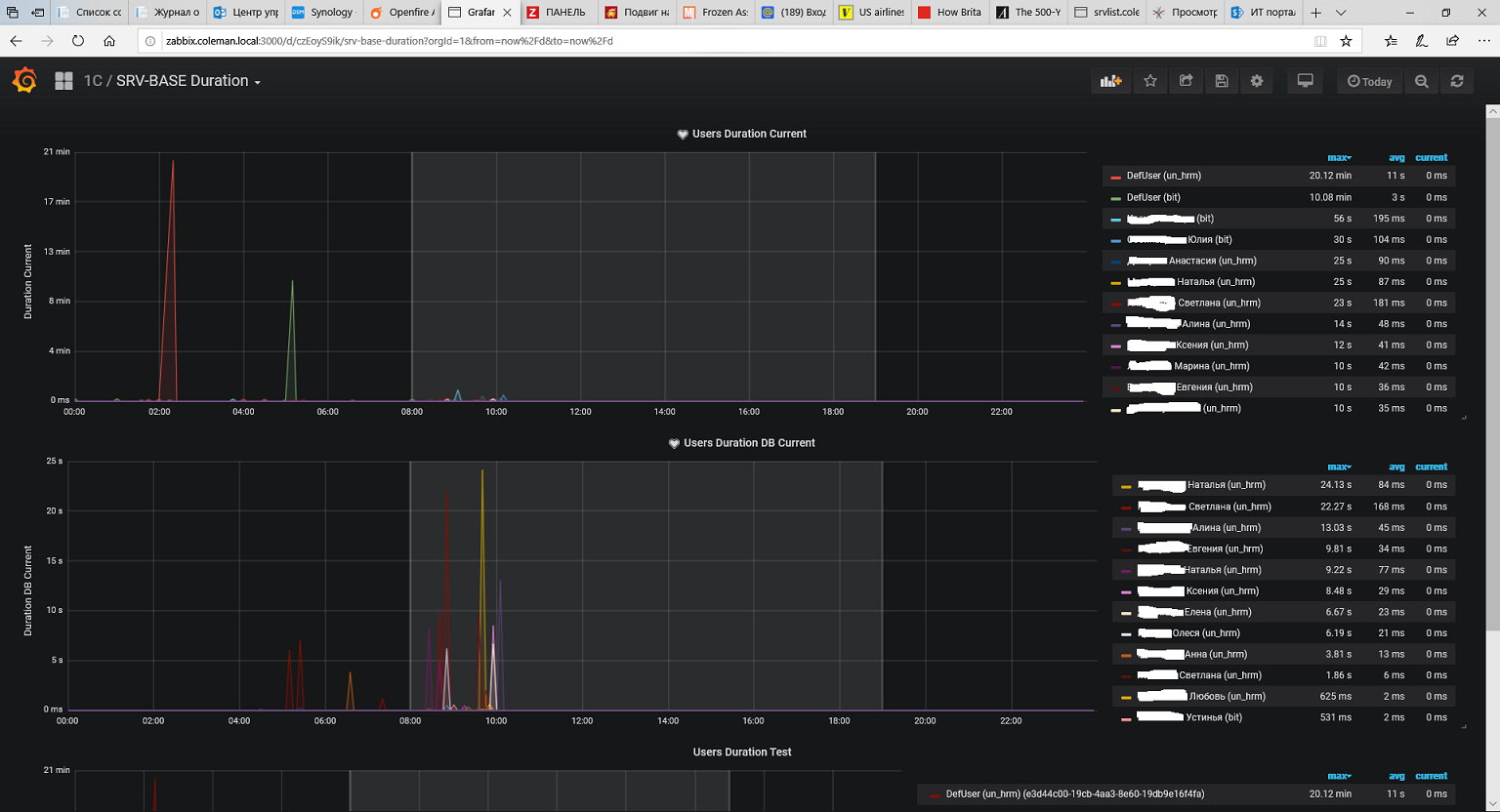
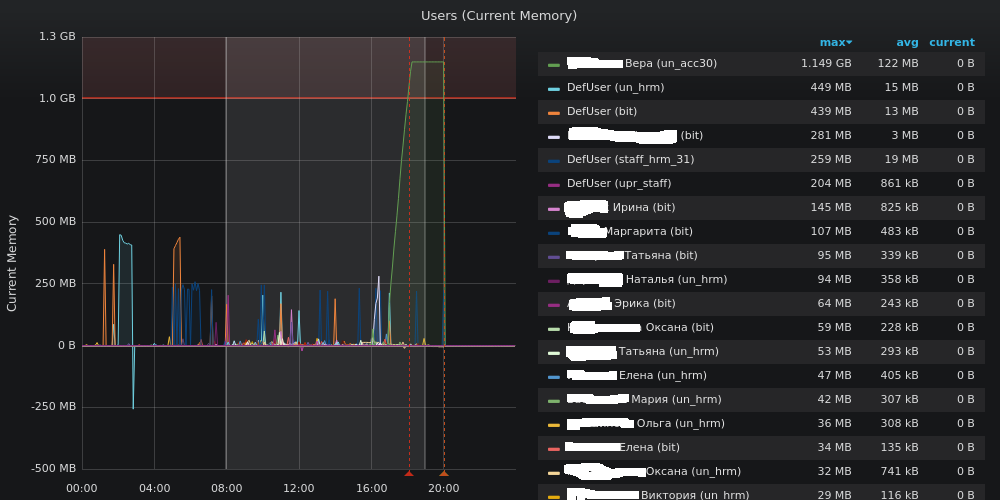
Ну и после некоторого кряхтенья получаем график использования памяти в разрезе пользователей:
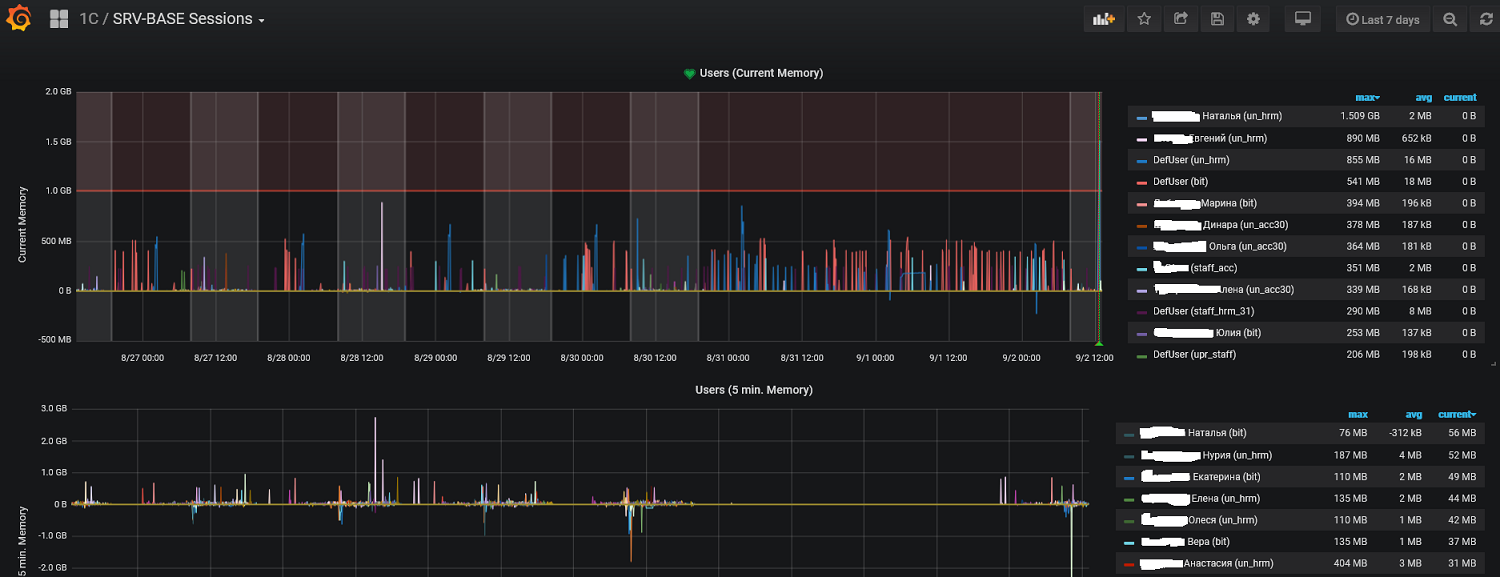
Подобным же образом визуализировали время сессий.
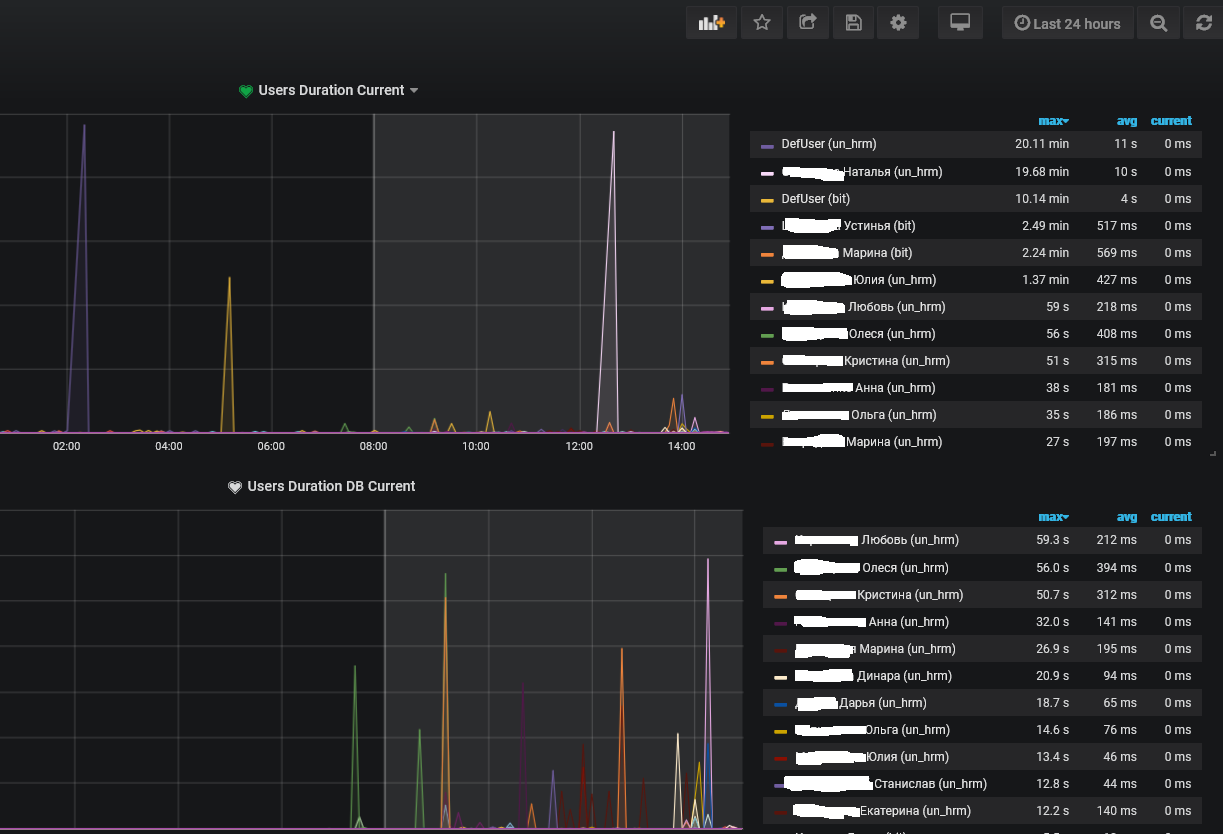
Ну как бы здорово - видим кто ест всю память, у кого сессии зависли (по факту скорее фоновые задания, запущенные во время работы), для регламентов видим какие регламенты вдруг стали выполняться сильно дольше. Но оперативности, к сожалению, нет. Если никто не посмотрит на dashboard (а туда начинают смотреть когда пользователи начинают жаловаться), то никто и не дернется. Зато получили профили использования ресурсов и можно реагировать, если что-то идет не так.
Сначала сделали оповещение группы 1С по почте используя стандартный функционал Grafana рассылки уведомлений через электронную почту. Для этого надо сконфигурить Notification channels для работы с почтовым сервером, а потом настроить Alert Rules. Как-то вот так:
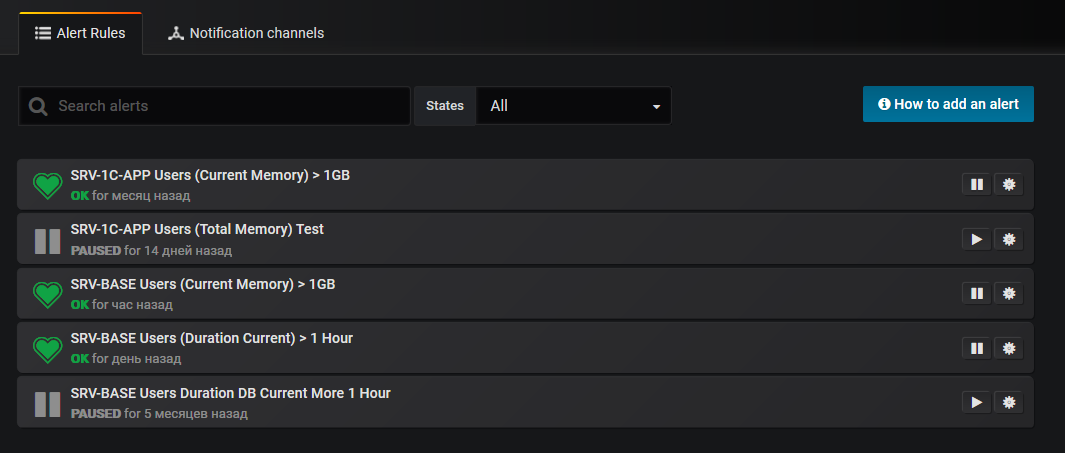
Теперь группе поддержки 1С стало сложнее пропустить предупреждение. Но если мы предупреждаем "одинэсников", то почему не сообщить сразу пользователю, что он каким-то образом запустил некую ресурсоемкую задачу? Если пользователь сразу отреагирует, то и группе поддержки 1С будет проще. В каких-то ситуациях можно не реагировать (все знают что запущена тяжелая обработка - "бобёр выдыхай"), в каких-то надо срочно прерывать задачу, в каких-то надо ставить на рефакторинг функционал и сразу понятно кто будет бизнес-заказчиком этого рефакторинга.
Вишенка на торте - используем webhook в Grafana (через все тот же Notification channels)! Grafana при включенном алерте посылает json с описанием проблемы на webhook сервер. Сервер берет из json пользователя, сервер, базу и время или размер сессии, шлет это все в bash-скрипт, который сопоставляет имя пользователя и его почту используя внутрикорпоративный портал, формирует сообщение и посылается на почту пользователю.
Пользователь получает что-то вроде:
Добрый день, <Имя пользователя>, согласно данным системы мониторинга 1С сегодня (17.06.2019) в 20:01 наблюдалось аномальное потребление Вами ресурсов сервера 1С SRV-BASE в информационной базе un_acc30 - 1095.84 MB. Большая просьба максимально детализовано сообщить какие операции в 1С в это время вы совершали и было ли что-то необычное (тормоза, вылет) во время работы. Информацию просьба направлять на ITSupport.
У нас поставлены 2 хука на превышение памяти на сессию больше 1GB и на продолжительность сессии более суток. Скрипты написаны на bash и если будут кому интересны приложу. Выглядят тоже ужасно + наша специфика с определением e-mail (пользователи создаются с русским ФИО в качестве username и за их e-mail'ами приходится дополнительно лазить на внутрикорпоративный портал).
Ну собственно всё. 3 месяца ушло на то, чтобы убедить пользователей не пугаться и сразу сообщать что было запущено и что с этим сделать.
В результате отловили ошибки в фоновых заданиях на формирование печатных форм (которые висли), оптимизировали пачку регламентов (которые работали часами), научили пользователей использовать более легкие отчеты вместо монстроидальных и отучили запускать тяжелые отчеты с большим периодом и широкой выборкой.
Теперь вот надо определить следующее узкое место, которое можно замониторить через Grafana...
UPD. 26/09/2019 Уважаемый @klimov_andrey, как автор упомянутых скриптов, модифицировал скрипт загрузки данных в Grafana. Теперь скрипт
- проверяет запущены ли RAS и 1С агент
- проверяет совпадают ли версии 1С агента и RAS и, в случае если они отличаются, устанавливает RAS нужной версии.
- В 8.3.15 изменился формат вывода данных из-за чего старый скрипт не грузил данные. Исправлено.
- Шлет на почту сообщения об ошибках
Вступайте в нашу телеграмм-группу Инфостарт