Итак, сегодня поговорим об интеграциях. В рамках этой статьи мы будем рассматривать интеграцию, как некоторую техническую функцию, как интеграцию объектов конфигурации безотносительно вложенной в них бизнес-логики. На самом деле от бизнес-логики интегрируемых систем никуда не денешься и при разработке каждой новой интеграции о ней думать необходимо, но во-первых бизнес-логика всегда идет поверх платформенных сущностей и только дополняют, но не заменяют ее, а во-вторых бизнес-логика всегда разная и в ней сложно выявить какие-то общие закономерности. Это, кстати, не означает, что мы будем рассматривать только случай обмена между идентичными конфигурациями (это случай минимальной зависимости интеграции от бизнес-логики). Скорее, это означает, что мы постараемся абстрагироваться от уровня бизнес-логики и будем говорить об объектах только в том смысле, в котором о них думает платформа, а если объект во время своего движения из системы в систему претерпевает какие-то модификации, обогащения или тому подобное - мы будем считать их ничтожными, т.е не способными повлиять на наши обобщения т.п.
В принципе, основным местом любой программы является предсказуемость/стабильность результата. В этом смысле от обмена мы прежде всего ждем гарантий предсказуемости, согласованности и воспроизводимости. Если мы изменяем документ в УТ - мы хотим быть уверены, что этот документ приедет в бухгалтерию, при этом либо целостность всех его ссылок будет гарантирована какими-то свойствами самого обмена, либо документ будет содержать все необходимое "на борту" (как например выгрузка объектов по ссылкам в конвертации). Если обобщать, то:
если имеются интегрированные системы А и Б, при этом состоянию А1 системы А соответствует состояние Б1 системы Б и состоянию А2 соответствует состояние Б2 соответственно - то интеграфия - это функция (программа), отслеживающая переход системы А из состояния А1 в А2 и обеспечивающая перевод системы Б из состояния Б1 в состояние Б2.
При этом есть важное замечание: подразумевается, что для системы А состояния А1 и А2 - валидные, т.е. мы не рассматриваем случаев, когда перевод системы в новое состояние выполнено нелегитимным способом: есть битые ссылки, была прямая запись в SQL или тому подобные случаи. Для системы Б требование только одно: валидность состояния Б1, а обеспечение валидности состояния Б2 - это полностью ответственность обмена. Иными словами:
не должно быть такого валидного изменения системы А, которое приведет к тому, что обмен переведет систему Б в невалидное состояние
Какие же возможны варианты? Все богатство случаев с битыми ссылками, не хватающими остатками, разными ставками НДС и прочим и прочим можно свести к трем следующим вопросам:
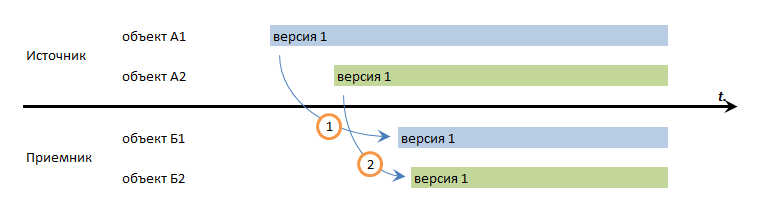
- Если в базе-источнике объекты были записаны в порядке: сначала А1, затем А2, гарантируем ли мы, что в базе-приемнике объекты запишутся в соответствующем порядке: Б1, затем Б2? Или мы можем записать сначала Б2, затем Б1?
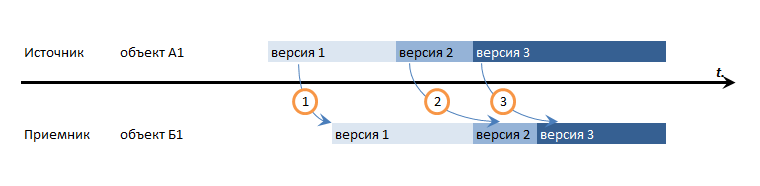
- Если в базе-источнике объект изменялся дважды: из Версии1 перешел в Версию2, затем в Версию3, гарантируем ли мы, что в базе-приемнике этот объект запишется в соответствующем порядке: 1 - 2 - 3? Или, при каких-то условиях, мы можем пропустить версию 2 и перевести объект в приемнике из версии 1 сразу в версию 3?
- Если в базе-источнике объекты А1 и А2 записаны в одной транзакции - гарантируем ли мы что в базе-приемнике мы запишем соответствующие им Б1 и Б2 в одной транзакции? Или мы можем себе позволить выделить один из них, который мы запишем первым и таким образом он будет существовать в базе-приемнике без "напарника"?
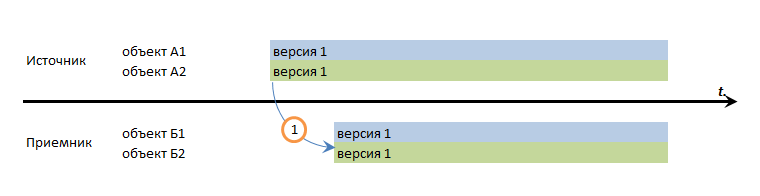
В зависимости от того, какие ответы на эти вопросы вы даете - вы получите следующие виды гарантий целостности данных
Транзакционная последовательность
Этот уровень последовательности похож на то как SQL сервер делает бэкапы: он просто хранит лог транзакций и в случае необходимости накатывает их последовательно на БД.
Это единственный вариант, который гарантированно разрулит вообще все возможные недоразумения, включая перекрестные ссылки. Но в 1С он не достижим: мы не можем контролировать начало и фиксацию транзакции в 1С с тем, чтобы повторить тоже самое в источнике. Можно конечно попробовать опуститься на уровень SQL, но этот путь полон граблей и мы тут в общем про 1С, а не про MS SQL.
Хронологическая последовательность
Такой обмен точно гарантирует последовательность записи объектов, в том числе версий одного объекта. т.е. если вы в источнике завели номенклатуру с наименованием "Педжак", потом увидели ошибку и исправили - обмен в точности повторит ваши действия: в приемнике сначала будет записана первая версия номенклатуры - затем вторая, не зависимо от того была ли ошибка исправлена через секунду или через год, и происходил ли обмен между изменениями или нет. Это же можно сказать и о разных объектах одного типа и о разных объектах разного типа: все будет выполняться точно так, как это было выполнено в источнике.
Как реализовать.
Нужно складывать все версии всех объектов в отдельное место, не допуская никаких пропусков, подобно тому, как это делает подсистема Версионирование объектов и на стороне приемника воспроизводить эту последовательность.
Плюсы.
Этот обмен с высокой долей вероятности разрулит перекрестный ссылки (если они организованы пользователем, а не кодом в одной транзакции). Также он справится с жесткими последовательными переходами (это пояснено чуть ниже).
Минусы.
Во-первых, этот алгоритм сильно зависит от системного времени если есть вариант что кто-то куда-то что-то перенес - пиши пропало. Во-вторых, это довольно ресурсоемкая история: нужно где-то хранить все версии всех объектов, нужно их передавать и записывать. Невозможно использовать многопоточность. Проблема снежного кома: если обмен по каким-то причинам споткнется на одном объекте - он вынужден будет остановить всю работу до того как кто-то не разберется с тем что же там случилось, а очередь будет тем временем расти.
Что вообще может пойти не так
На самом деле, случаев когда ни один уровень гарантии последовательности (кроме транзакционной или хронологической) не может обеспечить согласованность данных больше чем кажется.
- Во-первых это перекрестные ссылки. Если А ссылается на Б, а Б на А и вы не предприняли никаких специальных мероприятий - падение почти гарантировано, стоит только попытаться получить что-нибудь через соответствующий реквизит при записи этого объекта или в параллельном потоке.
- Во-вторых это последовательные состояния: иллюстрируется проще всего статусами документов: если у вас где-то написано, что документ должен сначала быть записан в статусе "новый", а потом может перейти только в "проверенный", а далее только в "на исполнение", то если вы передадите новый документ, а далее попытаетесь передать сразу версию на исполнение - у вас будет нарушение последовательности. Без специальной логики, отключающей проверку для обменов не обойтись. Собственно отсюда все эти костыли с "ОбменДанными.Загрузка".
- В-третьих это состояние влияющих объектов. Если для проведения документа вы используете, например, какой-то признак контрагента, то мало того что этот контрагент в базе приемнике должен быть. Он еще и должен находится в том же самом состоянии, в котором он находился в базе-источнике в момент проведения. Обратите внимание: не в самом актуальном состоянии, а в точности в том, в котором он был в момент проведения.
- В-четвертых это логические зависимости бизнес-уровня: например, если у вас есть всего один пиджак и он находится на складе1, вы его перемещаете на склад2, далее на склад3 - ни один алгоритм уровня ниже хронологической последовательности не способен гарантировать такой кульбит с первого раза.
Партионно-последовательная
В этом типе обмена фиксируется некий промежуток времени и изменения в рамках него (партию изменений) и обмен гарантирует последовательность партий, но не последовательность объектов внутри партий. Например, если были записаны два объекта А и Б в следующих версиях: А1, далее объект Б1, далее объект А2 - нужно просто запомнить, что есть изменения объектов А и Б и обработать их внутри одной пачки изменений. Таким образом можно точно утверждать, что по завершении сессии обмена данными в приемнике будут присутствовать объекты А и Б, версий 2 и 1 соответственно, но вот порядок того как их записал обмен не гарантируется никак.
Здесь может показаться, что так работают типовые обмены, но это не совсем так: в типовых обменах используется логика выгрузки "НомерСообщения меньше или равно", что соответствует всем изменениям на момент выгрузки, а не каким-то отдельным партиям. Механизм регистрации изменений, если его понимать как "НомерСообщения равно" работает почти так, но опять же не совсем: если изменения попадут в партию1, затем в партию2 - они вычистятся из партии1, что может нарушить ссылочную целостность.
Как реализовать.
Если вы хотите строгую реализацию - вы должны организовать нечто вроде регистрации изменений 1С, но без функции удаления новых изменений из старых партий. Если готовы на компромиссы - просто используйте типовую регистрацию изменений.
Плюсы.
Основным плюсом этой истории являет значительно оптимизированная ресурсоемкость при частых изменениях и нечастых обменах: не нужно хранить безумное число копий одного и того же объекта, не нужно записать в приемнике по 100 раз то, что можно записать однажды. Также, если говорить о переходе от логики "НомерСообщения меньше или равно" к логике "НомерСообщения равно" есть некое ослабление эффекта снежного кома: во-первых объекты имеют тенденцию к "утеканию" из ранних партий, во-вторых, ограниченность каждой партии способствует продвижению вперед при проблемах: валится один конкретный кусочек, вместо большого снежного кома.
Минусы.
С перекрестными ссылками придется попрощаться. Многопоточность можно применять ограниченно: только внутри одной партии данных, а это значит что партия должна быть достаточно большой, что в свою очередь означает что обмен должен быть довольно не частым. Ну и в целом накапливание проблем (одна партия сбоит - остальные ждут) никуда не делось. В полный рост встает проблема последовательности перехода.
Последовательность основанная на данных
Этот алгоритм точно знает, что бизнес-логика такова, что одни объекты надо прогружать раньше чем другие (например, номенклатуру раньше поступлений, поступления раньше реализаций) и гарантирует эту последовательность. Вообще, в "чистой" реализации, этот принцип должен быть доведен до следующего абсолюта:
- записываем в источнике объекты А1 и Б1
- обмен знает, что объекты А приоритетнее объектов Б и начинает загрузку объекта А в приемник
- в это время в источнике записывается объект А2
- обмен, закончив загрузку объекта А1 игнорирует тот факт, что объект Б1 записан раньше и руководствуюсь более высоким приоритетом объекта А2 - начинает загрузку объекта А2
На практике же, обмены редко бывают онлайновыми и скорее всего, последовательность основанная на данных будет применяться внутри какой-то сессии обмена (а это собственно и есть уровень гарантий Конвертации данных)
Как реализовать
Реализовать довольно просто: нужно иметь табличку приоритетов и табличку изменений и грузить изменения, отсортированные по приоритетам. Номера сообщений при этом можно выкинуть, не обращать на них никакого внимания.
Плюсы.
Возможно какое - никакое преодоление накапливания проблем. Если имеется ошибка в объекте с 50-м приоритетом - это будет тормозить только объекты с приоритетом 51 и ниже, объекты с приоритетом 49 и выше смогут загружаться, пока проблема не решена. (в типовых обменах это так работать не будет: база-источник не в курсе проблем базы-приемника и будет упорно выгружать все)
Минусы.
Зависимость от конкретной конфигурации: вы не сможете взять обмен написанный для одной компании и применить его в другой, поскольку кастомизированные объекты будут иметь свои особенности. Плюс, все теже самые, что в партионно-последовательном: перекрестные ссылки, последовательности перехода, отсутствие многопоточности (при чем принципиальное: если партионную последовательность можно было хоть как-то разбить по типам и распаралелить внутри одного пакета, то тут параллелить можно только в рамках одного типа, а если это окажется какой-нибудь регистр - ничем хорошим это не закончится).
Последовательность Шредингера или согласованность в конечном счете
Это алгоритм, который пытается протолкнуть объекты в порядке близком к хронологическому, но если у него не получается - порядок может измениться и попытки "проталкивания" будут продолжены до успешного завершения. Когда все процедуры обмена завершатся - состояние всех объектов в приемнике будет соответствовать таковому в источнике. Иными словами мы принципиально плевать хотели на любую последовательность и гарантируем только одно: конкретный объект будет записан в своей последней версии. Ну или хотябы будет попытка это сделать )
Иными словами, этот алгоритм пытается решать проблемы записи методом наподобие генетического алгоритма: если есть проблемы - проталкиваем те данные, которые могут быть записаны, надеясь, что в определенный момент, под влиянием произошедших изменений в других данных (битые ссылки перестанут быть битыми, остатки появятся и т.п.) или под влиянием внешних обстоятельств (нагрузка на базу станет меньше, пользователи пойдут на обед) ошибки сами собой исчезнут. Например, если в алгоритме последовательности основанной на данных - обмен настроен таким образом, что знает что поступления надо писать раньше реализаций (иначе с остатками может не срастись), то алгоритм согласованности в конечном счете - не в курсе какой из документов надо писать первым, но если будут проблемы - он попробует и так и сяк. При этом может показаться, что это какая-то автоматизация хаоса, и в некотором смысле оно так и есть, но иногда это единственная возможность: например, если будут пытаться записаться два перемещения - то алгоритм последовательности на данных принципиально не способен справиться с такой ситуацией, а этот справится.
Как реализовать
Нужна табличка с изменениями и их статусами. Важно, чтобы в табличке лежала только одна, последняя версия каждого объекта, без промежуточных. Выбирать в произвольном порядке и пытаться писать. Не получилось - в следующий раз получится. Понятно, что интервалами между попытками и количеством попыток стоит управлять, а за объектами превысившими лимит попыток должны следить чьи-то глаза.
Плюсы
Можно развернуться с многопоточностью. Если у вас центральная база и 300 узлов - многопоточность - это то, без чего ваш обмен будет проходить с периодичностью раз в неделю. Также этот алгоритм абсолютно не накапливает проблемы: если один объект не записывается - из-за него могут страдать только непосредственно связанные с ним объекты, а не те, что имеют гипотетическую связь. Производительность на несколько порядков (да, именно в 10-100 раз) выше чем жестко-последовательные алгоритмы.
Минусы
Все теже самые, что преследуют нас давно: перекрестные ссылки и последовательности перехода. Но есть еще одна, довольно неприятная: битые ссылки. В условиях, когда последовательность гарантируется по принципу "потом, когда-нибудь, может быть" - неизбежно будут возникать ситуации когда один объект не успел, а второй, ссылающийся на первый - обошел его на повороте и пришел раньше. Вариантов разрешения проблемы битых ссылок просматривается несколько:
- Бизнес-логика конфигурации должна быть предельно толерантна к битым ссылкам. Например, если при проведении документа и что-то зависит от ставки НДС - она не должна доставаться через ссылку от номенклатуры - ставка должна присутствовать в самой таб.части документа. С одной стороны это жесткая денормализация, с другой если известное правило разработки типовых: если документ перепроводится без изменения - его движения не должны измениться - и это правило сильно способствует толерантности к битым ссылкам (хотя полной гарантии не дает).
- Необходимо исключить те участки кода, которые такой толерантностью не обладают. А это, предже всего, логика проведения. И, если мы говорим об идентичных конфигурациях, - проведение это то от чего отказаться не легко, а очень легко! Просто передавайте движения как есть.
- Можно просто позволить коду падать: согласованность в конечном счете - штука предельно гибко реагирующая на неудачи и при падании она попробует позже, к тому времени соответствующая ссылка появится. Но тут стоит понимать, что если на 100 попыток записи 1 неудача - это приемлемый уровень, и при нем производительность этого обмена, вместе с падениями даст 100 очков вперед любому другому, пусть даже работающему без сбоев (такое кто-то видел?). Но если каждый объект записывается с 10-го раза - это уже не то к чему стоит стремиться.
- Можно попробовать поиграть в проверку битых ссылок. Самый простой вариант - выполнить запрос к соответствующей таблице данных и посмотреть - есть ли там данные. Но такие проверки угробят всю производительность.
О транспортном уровне
Вообще, транспортный уровень не такая интересная тема, но скажем пару слом и о нем. Лучшие результаты достигаются при отделении друг от друга процессов транспорта и распаковки от процессов применения изменений т.е. в результате работы транспортного слоя мы уже должны видеть что нам предстоит сделать в части записи и иметь возможность манипулировать этими задачами не на уровне одной большой черной коробки. Фактически, если использовать складскую аналогию, принятая в 1С тактика такова:
- подгоняем грузовик изменений
- один кладовщик начинает пересчитывать товар поштучно (грузовик ждет)
- если где-то не хватает одной штуки - загружаем все обратно в грузовик и отправляем обратно
Сами понимаете, на складах это так не работает. Работает так:
- подгоняем грузовик изменений
- разгружаем, принимаем по паллетам, отпускаем грузовик
- паллеты удобно раскладываем в зоне приемки, назначаем каждой паллете по группе кладовщиков, один считает второй носит, третий укладывает.
- если есть проблемы - проблемные позиции откладываются, с ними разбираемся отдельно
В этом смысле, алгоритм принимающий решение о том что грузить, в какой последовательности и что делать при фэйлах должен иметь перед собой картину того что предстоит сделать. Это может быть таблица (регистр сведений) вида: тип объекта, идентификатор объекта, данные объекта и всякая мета-информация вроде того откуда и когда этот объект пришел и сколько раз и с каким результатом его пытались записать.
Графовая согласованность
Представляет собой развитие алгоритма согласованности в конечном счете, решая его основную проблему: битые ссылки. В целом алгоритм такой же, но перед загрузкой очередного объекта, все присутствующие в нем ссылки проверяются в таблице ожидающих загрузки. Такая проверка гарантирует отсутствие битых ссылок (за исключением случая перекрестных/кольцевых ссылок) и даже больше: она автоматическим и динамическим образом выстроит граф записи объектов, напоминающий модель последовательной согласованности основанной на данных, но только если в том случае последовательность понимается жесткой и поддерживается даже в случае отсутствия фактических пересечений в данных - графовая согласованность самонастраивается на фактических связях.
Как реализовать
Так же как согласованность в конечном счете, с дополнительной проверкой ссылочной целостности
Плюсы
Высокая производительность (оценить выше/ниже согласованности в конечном счете не так просто, поскольку дополнительные затраты на проверку графа в одном случае могут нивелироваться отсутствием некоторого количества неудачных попыток в другом), учет связей между объектами при независимости реализации от условий конкретной конфигурации.
Минусы
Это нереализуемо на 1С: реляционная БД не позволит выстраивать граф с приемлемой производительностью. Для этого потребуются noSQL решения вроде ElasticSearch.
Отдельная боль - это перекрестные (а возможно и кольцевые) ссылки. Такие ситуации на практике встречаются довольно часто, но в силу особенностей их использования в бизнес-логике, как правило, не вызывают проблем. Алгоритм обнаружения таких ссылок не прост, но в общем не бином Ньютона, а после того как они обнаружены, можно попробовать следующие варианты (если не брать вариант с решением проблемы на уровне бизнес-логики):
1. Собрать все такие закольцованные объекты в транзакции по группам закольцованности (от проверок битых ссылок и/или исключений перед/при записи это не спасет, но никто другой битых ссылок не увидит)
2. Попытаться таки записать объекты с битыми ссылками: если один записать удастся - остальные подтянутся
3. Далее очень аккуратно: намеренно испортить объект: найти и заменить битую ссылку на пустую, разорвать таким образом кольцо, затем записать остальные объекта, затем вернуть "испорченный" реквизит на место. Это весьма спорный шаг, но разработчики КД2 считали иначе (они так делают со всеми битыми ссылками, даже не возвращая их назад).
R03;R03;R03;R03;R03;R03;R03;
Заключение
Как наверно уже понятно, обмен, не основанный на бизнес-логике не может гарантировать полной консистентности данных. Единственный путь для того чтобы гарантированно согласованно переводить систему из одного состояния в другое - повторять бизнес-логику системы в обмене. Естественно, при этом обмен начнет валиться по бизнесовым причинам, что требует отдельных ресурсов на поддержку этих обменов. Но по правде говоря, такой уровень гарантий никому не нужен. Обмены основанные на принципе согласованности в конечном счете, хоть и имеют очевидные провалы в гарантиях, но по факту являются настолько быстрыми, что этого никто не успевает замечать, а когда успевает - ответить раз в месяц на вопрос "а что значит Объект не найден?" гораздо проще чем поднимать упавший в очередной раз по остаткам обмен. Ну и производительность обмена на согласованности в конечном счете просто завораживает: 300 узлов 1С:Розница поддерживаются с актуальностью в 5 - 10 минут, самостоятельно исправляя свои же ошибки.