Добрый день, уважаемые коллеги! Наш доклад будет посвящен теме производительности. Для начала мы представимся – Станислав Щербаков, ведущий программист компании «Петрович» и Александр Денисов, специалист по производительности компании «СофтПоинт».
Про «Петрович»

Станислав Щербаков: Сначала я расскажу пару слов о нашей компании, и о том, как наша деятельность связана с производительностью.
«Петрович» – это одна из крупнейших DIY-сетей в России. DIY – это известное английское сокращение Do It Yourself, соответственно, это крупная сеть гипермаркетов строительных товаров – товаров для стройки и ремонта. Наш оборот почти 50 млрд рублей в год (примечание: финансовые показатели, указанные в докладе, актуальны на момент выступления — сентябрь 2019).

Компания появилась в 1995 году. Сейчас у нас уже 19 магазинов и более 6 тысяч сотрудников. В день происходит порядка 20 тысяч отгрузок – каждые 4-5 секунд происходит одна отгрузка.

Из всех этих отгрузок порядка 40% проходит через наш сайт https://petrovich.ru/

Теперь немного расскажу про технологический стек, и подойдем уже к нашей основной теме.
- Все наши ИТ-системы интегрируются через шину. В качестве шины мы используем продукт MuleESB – это продукт, написанный на Java с использованием Spring. Он проповедует событийную модель. Грубо говоря, когда в любой системе происходит событие, она оповещает об этом шину, а шина оповещает все подписанные на это событие системы. Например, мы ведем справочник «Номенклатура» в отдельной 1С-ной базе. Если в какой-то элемент вносятся изменения – номенклатура записывается, зарегистрируется, сигнал об этом передается шине, а шина уже отдает сигнал всем, кто подписан, чтобы они забрали измененную номенклатуру.
- Пару слов про сайт. Backend сайта написан на PHP7, база на MySQL и PostgreSQL. Кроме этого мы используем Kafka, Redis и Elasticsearch. А frontend написан на TypeScript и React.
- Пару лет назад у нас появилась Big data, соответственно, мы используем дистрибутив Hortonworks.
- Большая часть нашей внутренней инфраструктуры обеспечивается программистами 1С – соответственно, у нас порядка 30 больших production-баз, самая огромная из которых весит более 7 Тб. Мы следим за здоровьем всех этих систем, собираем в Zabbix все показатели производительности, все данные о функционировании систем.
Про сами системы можно очень долго рассказывать, потому что есть еще WMS-системы и специализированные решения для торгового оборудования. Но перейдем уже непосредственно к теме производительности.
Так как у нас большие 1С-ные базы, которые используют Microsoft SQL, значит, нам часто приходится решать задачи, связанные с оптимизацией производительности. Об одной из них мы сегодня расскажем более подробно.
Про ГК «СофтПоинт»

Александр Денисов: Теперь пару слов о компании Софтпоинт и о том, как я вообще оказался на этой сцене.
Мы в компании Софтпоинт почти 15 лет занимаемся производительностью, помогаем нашим партнерам и коллегам выжимать максимум из их баз данных, заставляя их работать на максимально возможном пределе. С компанией «Петрович» в формате поддержки мы работаем уже 5 лет – следим за их системами в ежедневном режиме и даем какие-то оперативные рекомендации, если видим, что что-то можно улучшить, подкрутить. И иногда по их просьбе привлекаемся как приглашенные эксперты при расследовании каких-то сложных случаев. Об одном из таких случаев мы сегодня и расскажем.
Запуск отчета вызвал неожиданные «тормоза» по всей базе

Станислав Щербаков: Однажды к нам в техподдержку обратились с проблемой производительности, когда отчет вызывал «тормоза» по всей 1С-ной базе. Причем, эта 1С-ная база не очень большая – 1.5Тб в размере. В этой базе мы ведем оперативный учет всех подразделений Санкт-Петербурга, она работает 24/7.
Соответственно, мы начали проблему декомпозировать, разбирать дальше.
Сам отчет был построен на СКД, мы стали смотреть его запрос – подумали, что сейчас разберем его, найдем «узкие места», оптимизируем, и золотой ключик будет у нас в кармане.
Анализ плана медленного запроса
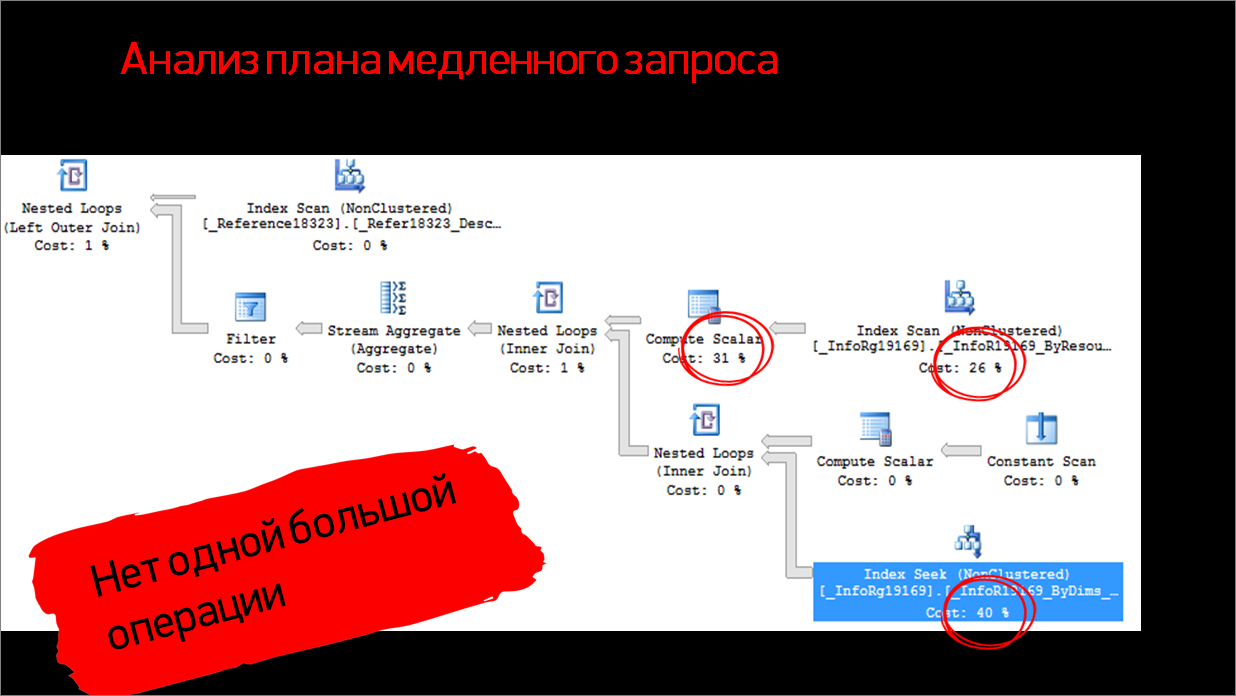
Мы стали смотреть на план запроса и увидели, что какой-то одной большой операции, которая бы отнимала больше 50% от всего, у нас нет. Время выполнения у нас поделилось между тремя большими операциями – Index Scan, Index Seek и Compute Scalar.
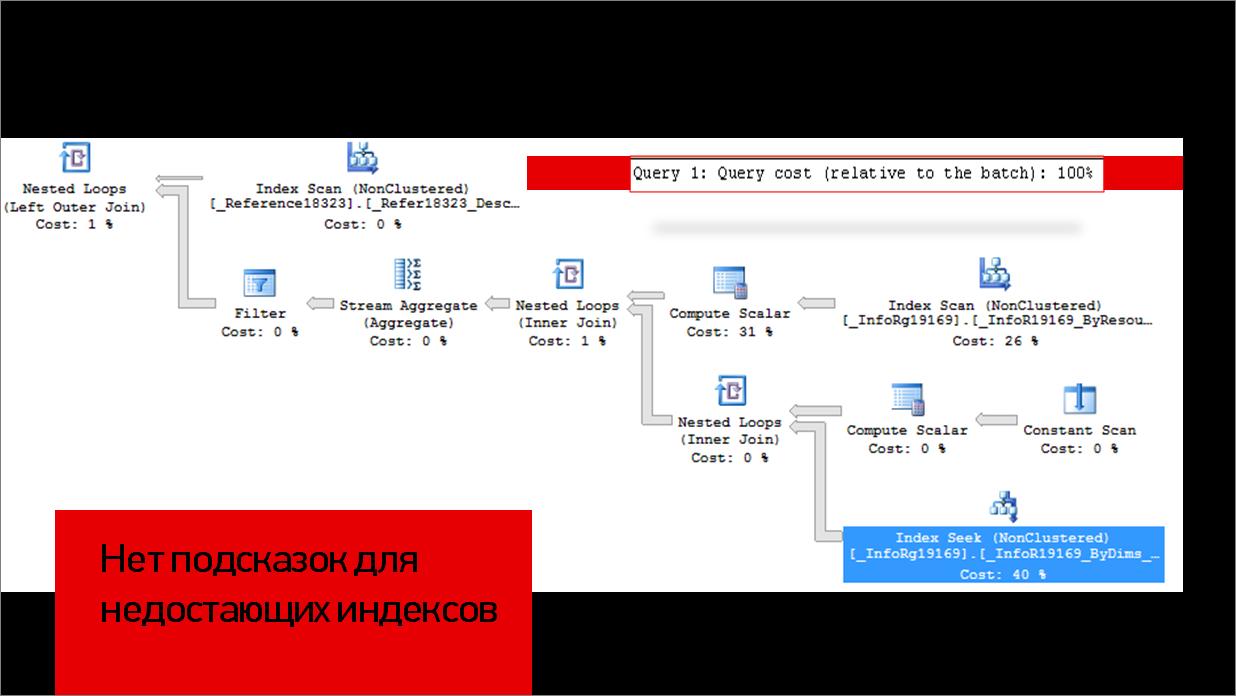
SQL не дает каких-то подсказок по неиспользуемым индексам.
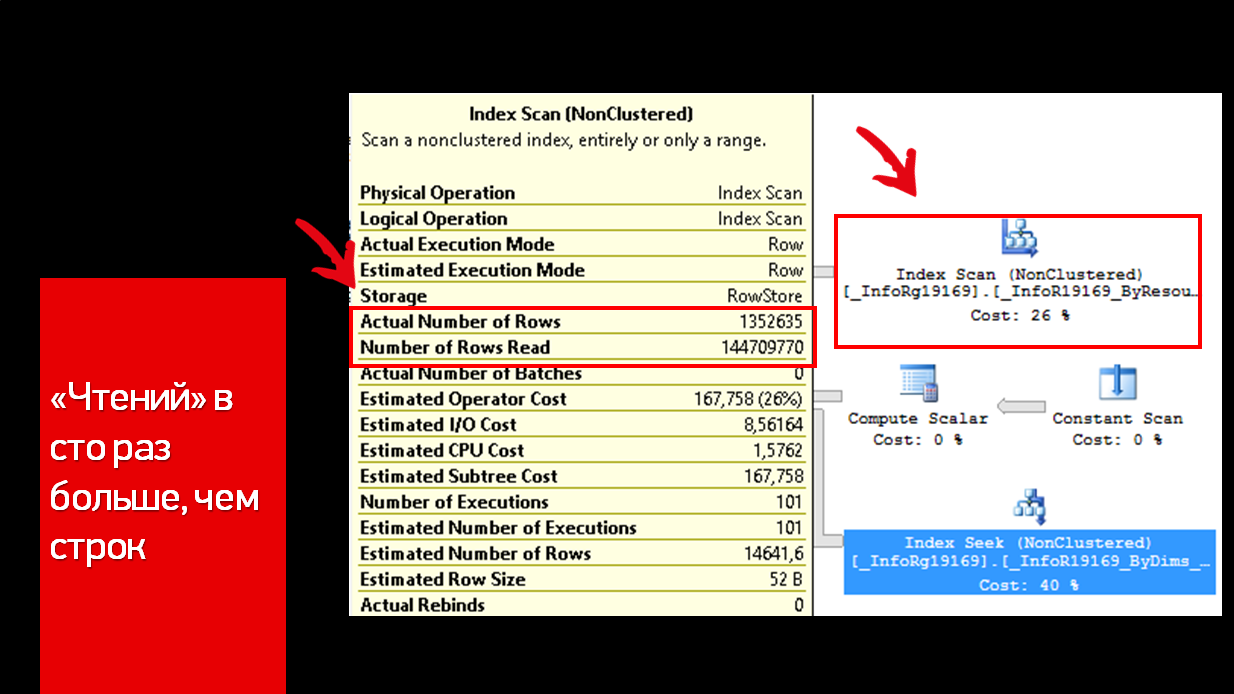
Одну подсказку все-таки нашли – в описании Index Scan видно, что записей получается в 100 раз меньше, чем фактически произведенного чтения. Вот одно из мест, где у нас скрылась неоптимальность.
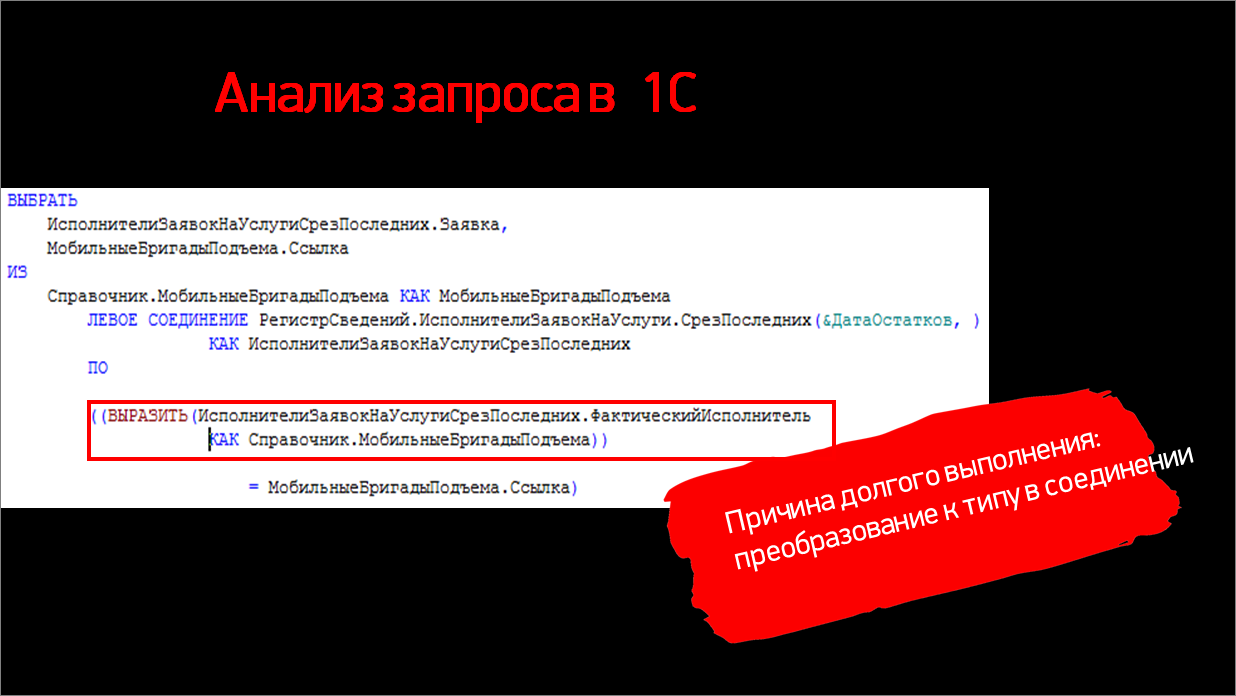
Теперь давайте взглянем на сам 1С-ный запрос и разберем, что тут происходит.
Здесь мы видим левое соединение справочника с виртуальной табличкой среза последних регистра сведений.
Обратим внимание на приведение к типу – у нас есть ресурс составного типа, поэтому в соединении используется ВЫРАЗИТЬ. Это – ключ к тому, почему была проблема. Добавлю, что по нашему ресурсу у нас есть индекс. Дальше разберем, почему он не используется и что здесь происходит.
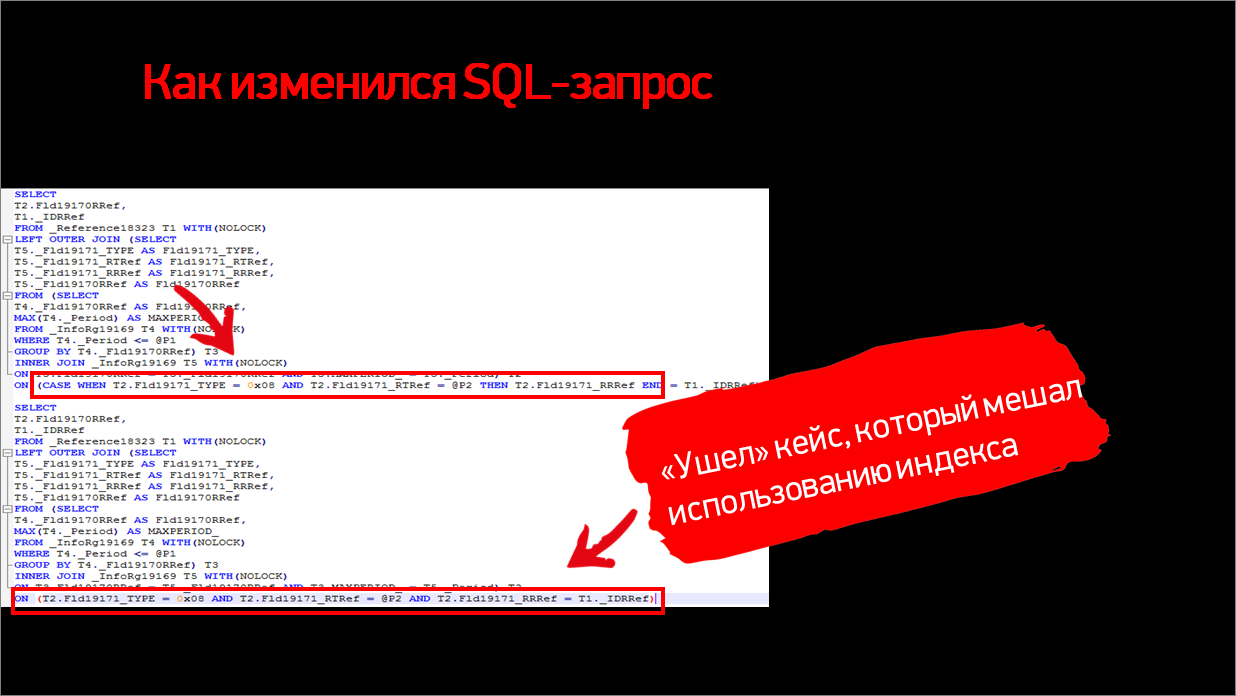
Сверху – вариант неоптимального запроса, как он был только что представлен в конструкции ВЫРАЗИТЬ. У нас на SQL ВЫРАЗИТЬ превращается в CASE для явного приведения к типу. И эта конструкция уже не дает использовать индекс.
Давайте поговорим, почему это происходит.
Функция CASE оборачивает наши поля, которые покрыты индексом, и можно провести хорошую аналогию с книгой и с оглавлением. Допустим, если мы хотим найти конкретную главу и знаем ее точное название целиком, то по названию и оглавлению мы быстро ее находим. Но если мы знаем только то, что у нас третья буква слева – это «г», то найти нам будет уже намного проблематичнее. Придется просканировать все оглавление, и только тогда мы сможем понять, какие нам нужны главы.
Такая же история и внутри SQL-сервера. В данном случае, когда мы применяем функцию CASE к полям, даже покрытым индексом, индекс полноценно не используется. Такая же штука может произойти и с другими функциями. Например, DATEADD (ДОБАВИТЬКДАТЕ), любые арифметические операции в запросе и т.д.
Важно отметить, что здесь мы использовали ВЫРАЗИТЬ именно внутри соединения. Мы все видели рекомендации на ИТС про необходимость приведения к типам при получении данных в полях, но эти рекомендации нужно читать внимательно – к соединениям и к условиям это никоим образом не относится. Там, получается, что применять ВЫРАЗИТЬ нельзя.

Что у нас получилось после того, как мы убрали ВЫРАЗИТЬ? Получилось, что запрос у нас ускорился в 8 раз.
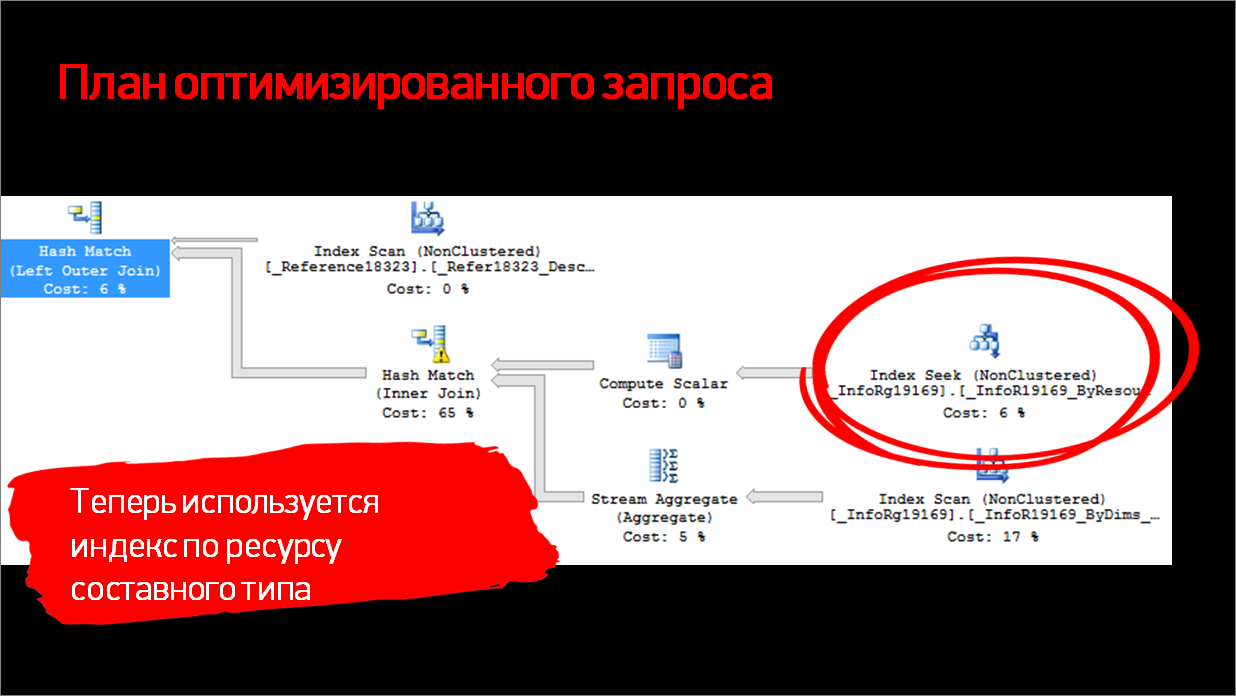
Давайте посмотрим, какой получился план запроса, и убедимся, что действительно индекс начал использоваться.
Действительно, теперь в плане есть Index Seek.

И в предикатах видим наш ресурс _Fld19171, который теперь используется.

Замечательно. Запрос оптимизировали, казалось бы, сейчас отчет будет быстрее выполняться, жалобы должны уйти. Но почему-то жалобы остались. Плюс, как мы говорили, отчет влиял еще и на другие системы – и вызывал «тормоза» по всей базе. Тут мы попросили помочь с расследованием коллег из Софтпоинта.
Нестандартные ожидания на блокировках
Александр Денисов: Нас периодически привлекают, как приглашенных экспертов для расследования каких-то сложных случаев. И этот случай действительно оказался сложнее, чем виделось в самом начале. Казалось бы, тормозит обычный отчет – один пользователь ждет, пока он выполнится, ну и пускай подождет. Отчеты в 1С по своей сути не могут заблокировать других пользователей. Но в этот раз почему-то вместе с отчетом ждали и другие пользователи базы данных.
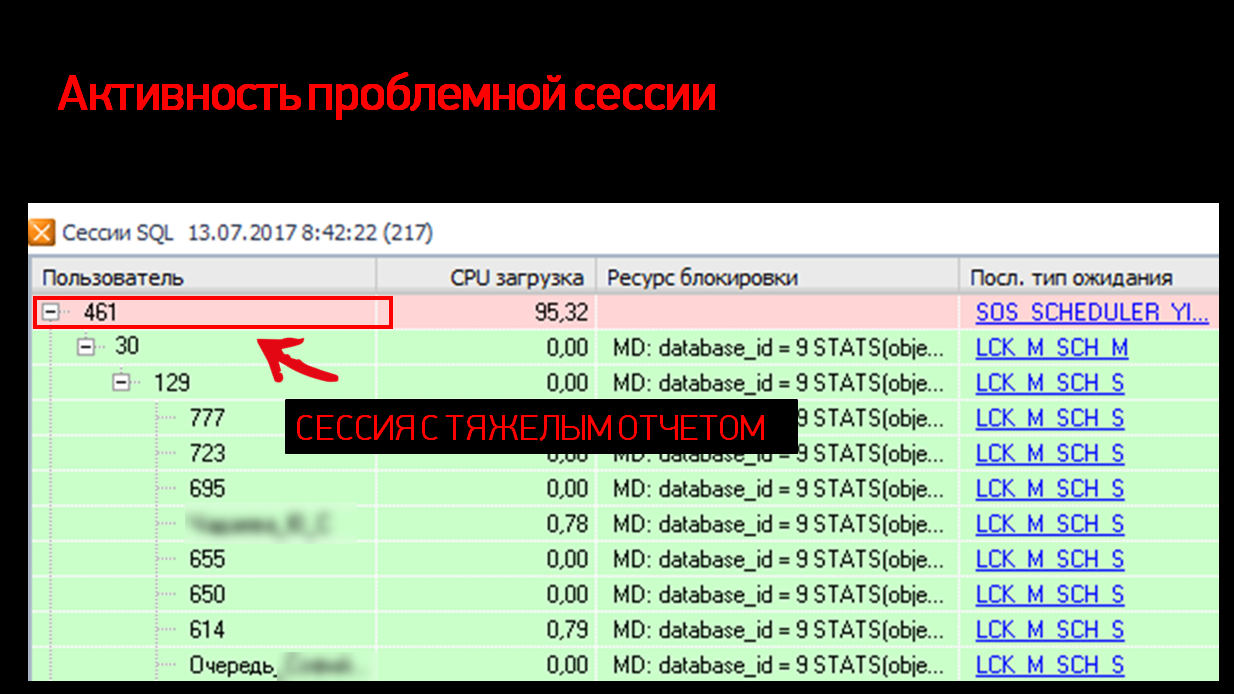
Первым делом, когда поступила заявка, мы начали с того, что просто посмотрели – что происходит на сервере в момент выполнения отчета?
На рисунке выше показаны SQL-сессии в момент инцидента. Видно, как они выполняются, какие ожидания и т.д.
Картина оказалась довольно неожиданной. В самом топе по нагрузке на CPU, как мы и ожидали увидеть, наша сессия с отчетом – видно, что 99% процессора съедено, он что-то считает, что-то выполняет – ничего необычного.
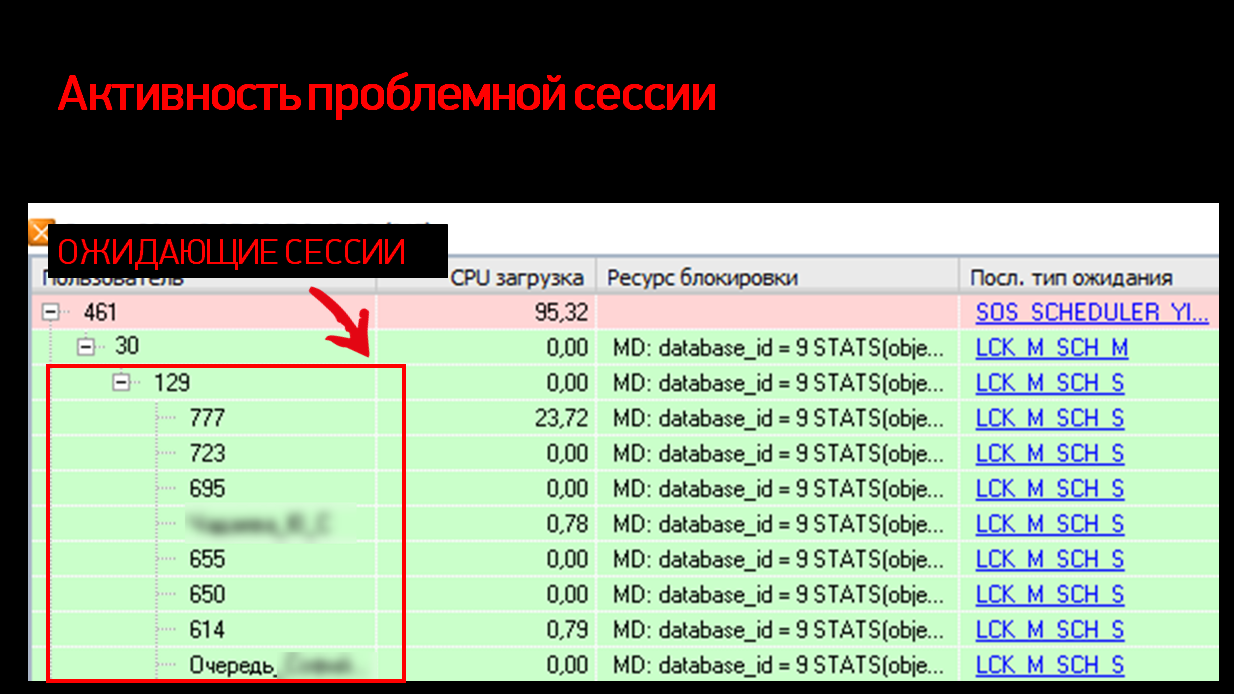
Но под этим отчетом у нас собирается очередь ожидания. Казалось бы, это – нормальный, обычный отчет. Все знают, что в 1С отчеты выполняются в режиме NOLOCK, т.е. с грязным чтением. Они по определению сами игнорируют наложенные блокировки и никого не ждут – и в то же время не накладывают собственных блокировок и никого не могут подвесить. А здесь вместо этого какая-то небывальщина и выглядит странно.
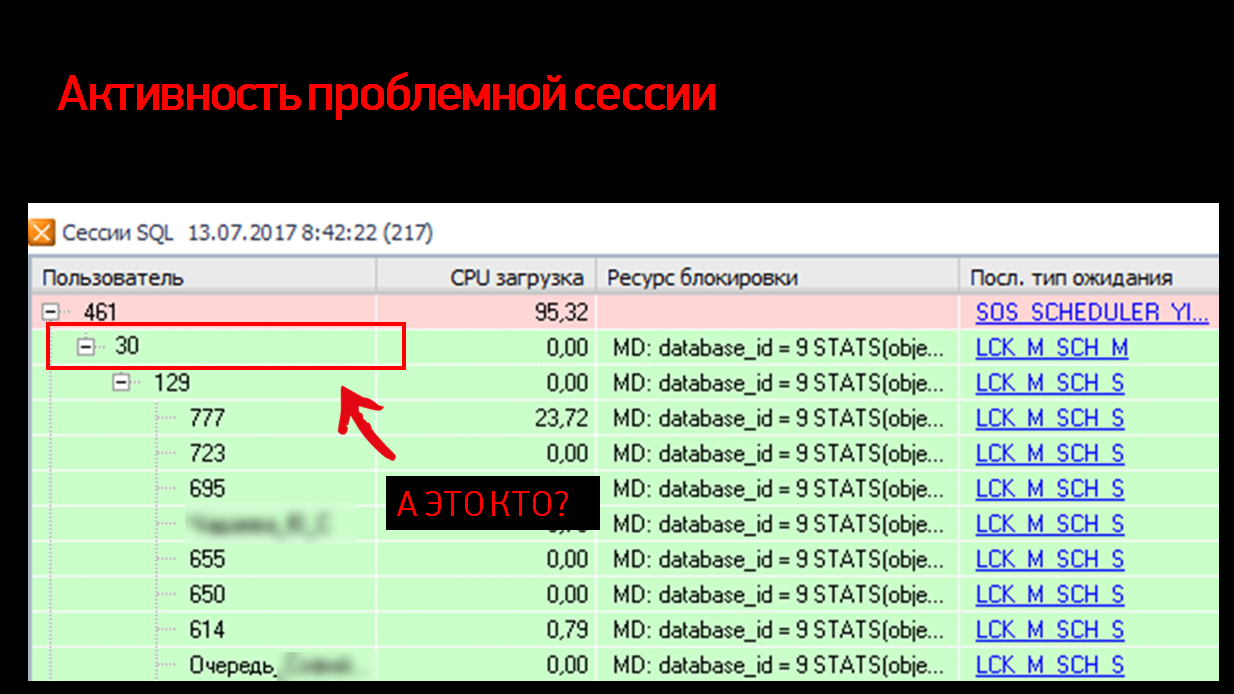
Продолжили разбираться дальше. Если посмотреть внимательнее, видно, что все сессии висят не на нашей 461-й сессии, а на сессии уровнем ниже – с номером 30. Какая-то непонятная сессия, тип ожидания у нее еще SCH M (Schema Modification) – его видно в самой правой колонке.
Если бы у нас было какое-то обычное ожидание, как при проведении документа или изменении данных, мы бы не удивлялись, что оно «подвешивает» всех остальных.
Как это обычно выглядит? В колонке с типом ожидания будет либо U-блокировка (блокировка на Update), либо X-блокировка (эксклюзивная блокировка на данных). Все понятно, все логично.
Вместо этого у нас здесьблокировка модификации схемы. Кто-то просто в разгаре рабочего утра, в 8:42, не моргнув глазом, меняет схему. А схему в 1С мы можем поменять одним легальным способом - сделав реструктуризацию ИБ из конфигуратора, что никак не совмещается со 100 активными пользователями.
Смотрим дальше – в ресурсе блокировки у нас ключевое слово STATS (статистики). И с этого момента становится более-менее понятно, что вообще здесь происходит.
Небольшое отступление. Что такое статистика?

Небольшое отступление. Поговорим немного про то, что вообще такое статистики, и зачем они нужны. Разберем эту тему чуть подробнее.
Говоря про то, зачем нужны статистики, я буду говорить про MS SQL Sever, но на самом деле, в PostgreSQL это тоже примерно так же работает, с небольшими изменениями.
Так вот – все мы сегодня слышали уже в предыдущих докладах, что язык SQL у нас декларативный, он говорит, что нужно получить.
При этом как СУБД будет получать эти данные – она решает сама. Конечный способ получения и обработки данных описывается в плане запросов. План – это пошаговая инструкция, куда посмотреть, что сделать, с чем объединить. Повторюсь, СУБД строит этот план самостоятельно.
И когда СУБД строит план запроса, ей нужно сделать какие-то решения. Например, у нас есть три классических способа соединения данных:
- Nested loops – вложенные циклы;
- Hash math;
- И Merge Join
У каждого из них есть свои плюсы и минусы.
- Кто-то хорошо работает на больших массивах данных, когда и слева, и справа у нас большие объемы. Но зато требует много ресурсов, много оперативки.
- Кто-то, наоборот, хорошо работает на маленьких объемах, работает очень экономно, но зато проседает на больших объемах.
И в итоге эффективный выбор нужного оператора – это очень большая проблема. Я в своей практике видел сотни раз, когда из-за ошибки оптимизатора, который выбирает неправильный вариант соединения данных, запрос проседает в сотни раз (было полминуты, получилось 10 минут) – из-за того, что выбрался Nested loops, когда не надо было или наоборот.
Так вот, что нам нужно знать для того, чтобы выбрать правильный вариант соединения данных?
Нам нужно знать, сколько у нас данных будет в каждой из соединяемых сторон. Как у нас сервер может это узнать? Тут у нас как раз включается статистика.
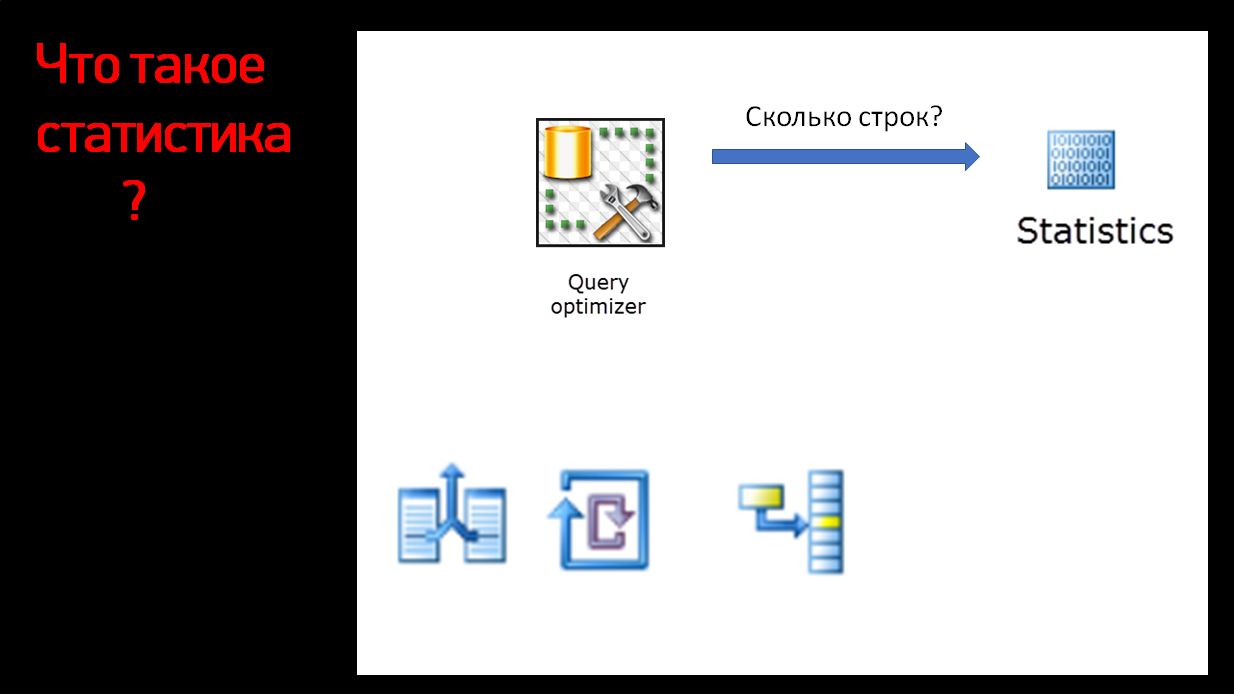
Статистика – это специальный объект в базе данных. Если вы раскроете в Object Explorer объекты, которые у вас есть, у вас будут таблицы, индексы и отдельно будет папка «статистики».
Статистики физически хранятся в базе, это такие гистограммы. Статистика говорит, сколько у нас значений в каком-то диапазоне.
Соответственно, статистика нужна, чтобы SQL Server знал, сколько ему строк вернется.
Он спрашивает: «Сколько у нас Ивановых в базе данных?» И статистика ему отвечает: «Ивановых у нас 10 тысяч».
«А Бахрушиных сколько будет?» – «Примерно пять человек».
Там, конечно же, не для каждого целые числа, но примерные значения мы получаем.
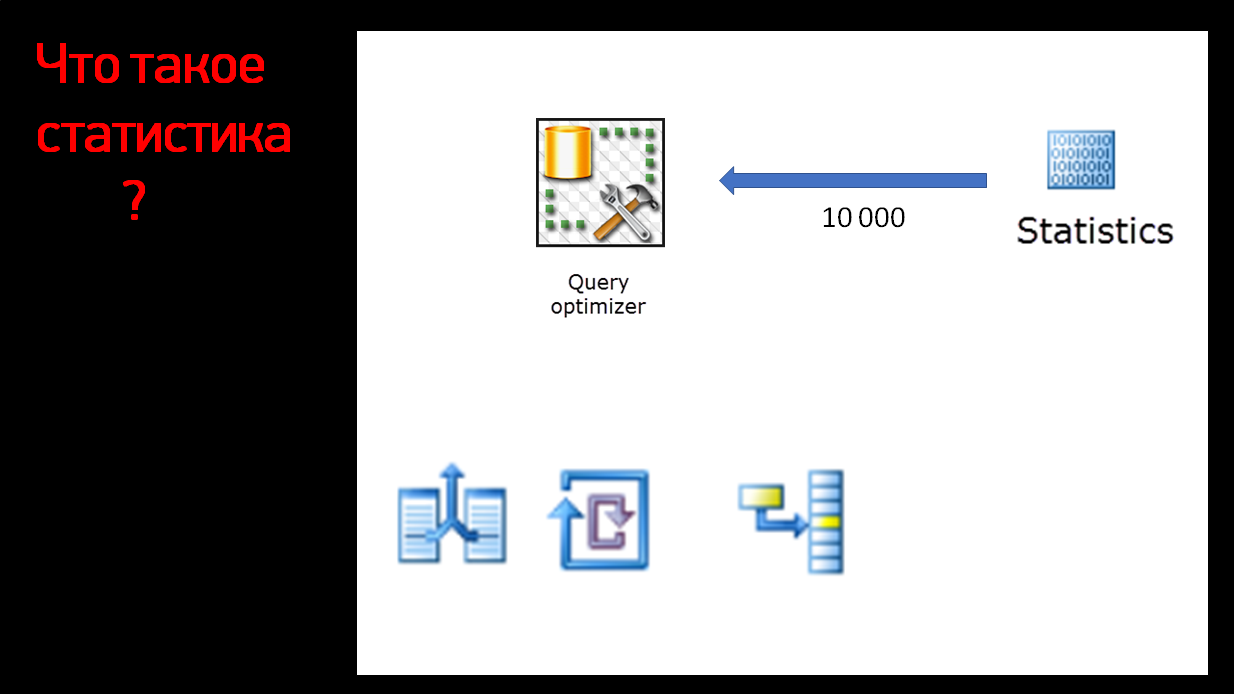
Сервер SQL спрашивает у статистики, сколько ему вернется строк, статистика ему отвечает.

Сервер SQL после этого решает, что в этом конкретном случае поможет Hash math, и выбирает правильный план. Все здорово, пользователь получает быстрый результат запроса, DBA радуется, что у нас экономятся ресурсы. Все счастливы и довольны.
Но должна же быть какая-то ложка дегтя.
Конечно, она есть. Дело в том, что статистики в SQL-сервере не обновляются с изменением данных. Данные меняются, а статистика остается на каком-то заранее посчитанном уровне.
Чем дольше мы работаем без пересчета статистики, тем быстрее они перестают отвечать актуальным данным. Они возвращают те же самые значения, которые совершенно не попадают в реальное распределение.
Соответственно, оптимизатор начинает ошибаться, и мы получаем неправильный, неэффективный план.

Статистики нужно обновлять. Как мы можем это сделать?
У нас есть три варианта:
- Либо мы вручную запускаем UPDATE STATISTIC. Есть специальная команда в Management Studio – выполняем обновление статистик, все пересчитывается.
- Второй вариант – мы делаем регулярное перестроение индекса (REBUILD). Вместе с этим соответствующая статистика тоже пересчитается.
- И есть третий вариант, для ленивых администраторов. Есть специальный процесс, который называется автоапдейт статистик. Это – специальный компонент, который сидит в памяти и следит за состоянием всех статистик в вашей базе данных. При превышении какого-то порога он решает что уже пора, хватит это терпеть, статистику нужно пересчитать, и он ее обновляет.

Отлично, обновили знания, возвращаемся обратно.
Активность проблемной сессии
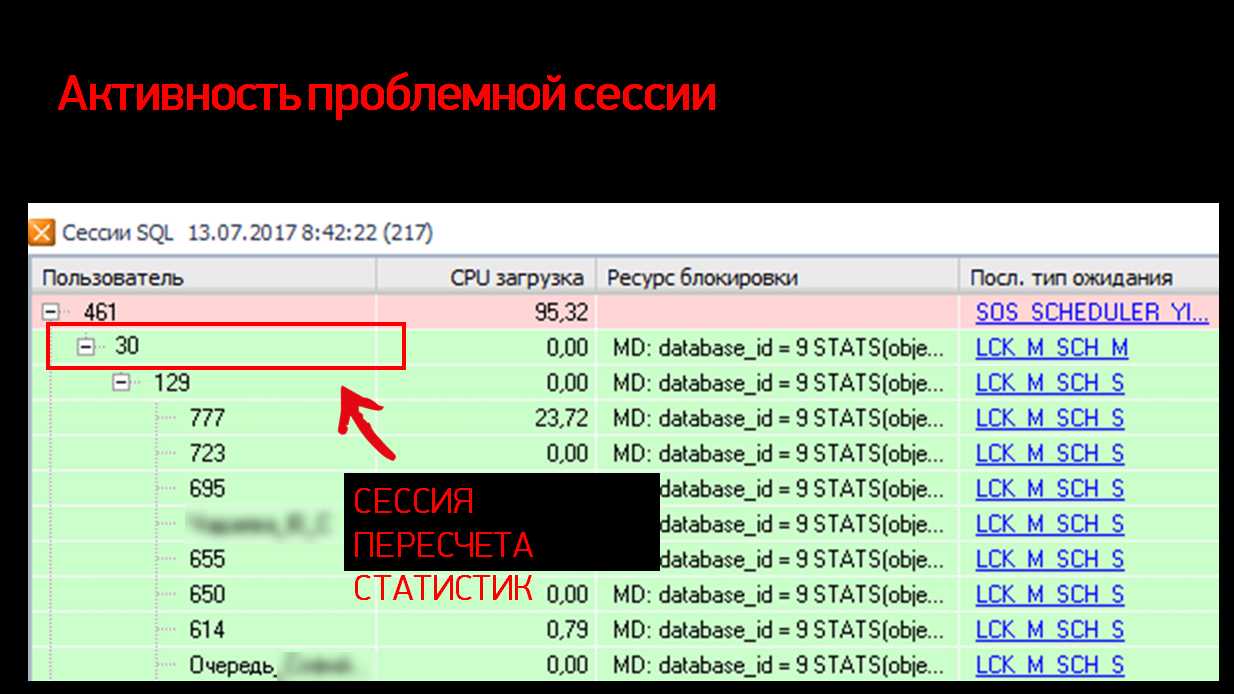
Небольшие вводные данные. В этой базе у нас, как и во всех базах по умолчанию, были включены автоапдейт статистик и асинхронный пересчет статистик.
Соответственно, в той ситуации, которую мы видим на скриншоте, как раз этот автоапдейт статистик и сработал.
Смотрите сами:
- у нас есть тяжелый запрос, который что-то выполняет, читает очень много данных, которому явно нужно знать распределение данных для того, чтобы построить план.
- У нас есть под ним какая-то странная сессия с номером подключения 30. Надо знать, что все подключения SQL сервера с номерами до 50 – это, как правило, служебные подключения. На них ни администратор, ни пользователь повлиять не могут. Они появляются сами собой, сами собой закрываются и делают все, что хотят.
- У нас есть ожидания на модификации схемы – как я уже говорил, статистика физически хранится в схеме (это реальный объект схемы).
- И у нас есть ожидания – блокировки на чтении схемы, которые ждут, когда уже изменение закончится и все стабилизируется.
Получается, что этот наш проблемный запрос начал выполняться, увидел, что статистика устарела, запустил дочерний процесс пересчета статистик и продолжил выполнять свой запрос.
Перестроение статистик перечитало таблицу, подготовило новую статистику и готово уже подменить старую статистику на новую, заменить ее. Все классно, но для того, чтобы подменить статистику, нам нужно дождаться, пока закончатся все запросы, которые работают с этим объектом. А такой запрос как раз есть – это наш исходный тяжелый запрос.
Получается, что этот дочерний процесс ждет, пока закончится долгий запрос и держит блокировку схемы.
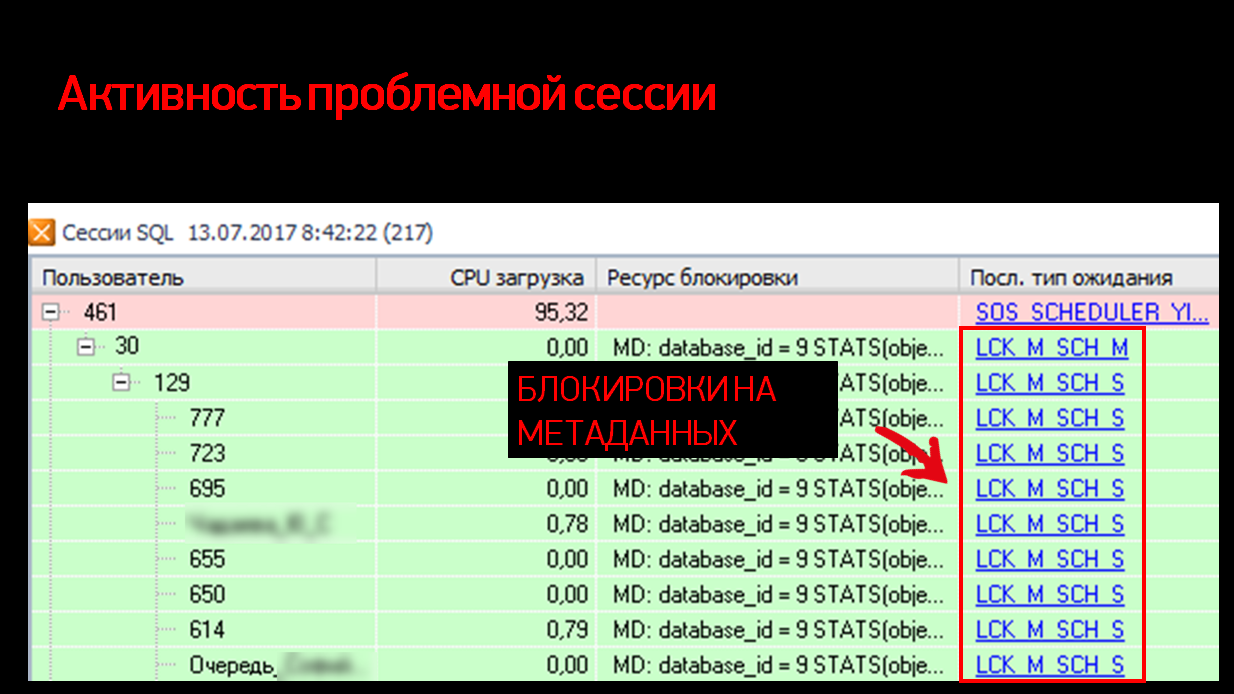
В это время появляются другие запросы, которые говорят: «У нас устарела статистика, куда нам посмотреть». И вот эта 30-тая версия говорит: «Сейчас у нас статистика будет, подождите, я ее поменяю». И получается, что весь этот паровоз ждет, пока долгий запрос окончательно не сформируется. Очень неочевидная история. Получается, что отчет, который выполняется без транзакции с NOLOCK, все равно собрал после себя какое-то большое дерево ожидания.
Факторы риска

Какие факторы риска для того, чтобы это произошло?
- Во-первых, это должны быть достаточно большие таблицы, чтобы они долго пересчитывались, чтобы этот процесс пересчета статистик занял какое-то время, и мы это заметили.
- Дальше – чем реже у вас пересчитываются статистики, тем больше вероятность, что у вас автоапдейт статистик сработает. Если вы сами не занимаетесь этой работой, то кто-то займется ею за вас.
- И третье, что здесь сыграло ключевую роль – это то, что в OLTP-системе выполняются долгие OLAP-запросы. Это – неудивительная история для 1С, она тем и славится, что у нее и OLTP, и OLAP-нагрузка выполняются.
Почему это важно, почему это «выстрелило»?
Вернемся назад. Вот наша 30-я сессия, которая «висит». Если бы у нас 461-я сессия проводила какой-то короткий документ, то 5 секунд ожидания – ерунда, никто бы не заметил.
Вся проблема в том, что этот блокирующий запрос выполнялся долго. Именно поэтому мы эти блокировки и заметили.
Чтобы не попасть в такую ситуацию, нужно следить за статистиками, если есть возможность, выносить аналитику на какие-то дополнительные сервера или ноды.
Решение проблемы

Как мы в данном случае решили эту проблему?
Мы просто отключили автообновление статистик. Звучит довольно страшно, потому что статистики нужны. Но дело в том, что мы сделали регулярное задание пересчета статистик.
Получилось, что, с одной стороны, каждую ночь у нас пересчитываются статистики – мы знаем, когда это происходит.
С другой стороны, для нас в этой ситуации автоапдейт статистик работал как мина замедленного действия. Совершенно непонятно, когда она сработает и в какой момент. Это будет, скорее всего, для нас неожиданно и неудобно.
Поэтому мы эту неожиданную плавающую проблему просто отключили. И возложили проблему пересчета статистики на наши плечи и сами с ней эффективно справляемся.
После этого поведение системы стало более стабильным. Мы теперь знаем, когда нам ждать блокировок, когда их не ждать, и все это теперь отлично работает.
Выводы
Какие выводы из всей этой ситуации
- Мы начали с оптимизации 1С-ного запроса, причем, увидели, как простая конструкция приведения к типу (ВЫРАЗИТЬ), но примененная в соединении (такая же ситуация могла случиться, если бы она была в условиях), у нас испортила весь запрос. Не только не улучшила, уменьшив выборку, но и ухудшила ситуацию. Здесь нужно понимать, что к рекомендациям нужно относиться внимательно, рекомендации относительно ВЫРАЗИТЬ в запросах есть только относительно полей самого запроса.
- Да, а на стороне сервера SQL получилось так, что инструмент, который призван облегчать жизнь администратору и программисту, а он, наоборот, ее усложнил. Тут тоже нужно помнить, что любые облегчающие вещи работают в 90% случаев, но везде есть какие-то «дыры» в абстракциях, какие-то исключения. Просто нужно про это помнить, не забывать. И не полагаться вслепую на какие-то автоматические вещи. Думать головой.
Вопросы:
- Как правильно – одно задание на асинхронный и автоматический пересчет статистики или вообще ни одного задания не использовать?
- Есть такой знаменитый американский SQL-блогер Пол Рэндалл - он еще был среди авторов первых версий SQL Server. Он любит на такие вопросы отвечать: «in depends». Все всегда зависит от ситуации. На самом деле есть много факторов. Все зависит от базы, от нагрузки и т.д. Если у вас есть регламентное окно каждую ночь – круто. Вы каждую ночь просто пересчитываете статистики и индексы. Лучше статистику пересчитывать, когда в базе никто не работает. Если у вас вообще никакого времени для технологического окна никогда нет, и у вас есть выбор, что делать (это вообще-то и есть Highload), то приоритет должен быть у статистик. Потому что если мы перестраиваем индексы, делаем Rebuild, они лежат на диске лучше, мы читаем чуть поменьше. Но с нашими скоростями дисков – это не такой большой выигрыш. Если же мы перестраиваем статистики, они влияют на качество ваших планов, насколько эффективно работает ваш запрос. Это – то, за что стоит бороться. Поэтому, если есть выбор, предпочтение нужно отдавать в пользу статистик. Более того, есть разные таблицы, с которыми мы работаем с разной интенсивностью, и если у вас есть DBA или эксперт по техвопросам, то, наверное, автоматическое асинхронное обновление статистики нужно выключать. Надо оставлять выборочно: по этой таблице – раз в час обновляем, по этой таблице – раз в день, а эту вообще можно не пересчитывать.
- Возвращаясь к пересчету статистики – если делать пересчет статистики во время работы, не в ночное окно, вы же процедурный кэш тоже сбрасываете? Как вы решаете эту проблему?
- Он сам сбрасывается. При пересчете статистик все планы, которые основывались на этой статистике, сразу помечаются, как устаревшие. Они не удаляются сразу, вы можете их в кэше увидеть, но на них ставится флаг, что они устаревшие. И при следующем обращении к этому плану он будет автоматически перекомпилирован. Если вы не доверяете этому механизму, если у вас маленький кэш, если у вас небольшая нагрузка, можно вручную сбрасывать. Если у вас большая система, я бы этот кэш пожалел, потому что он уже наработан кровью и потом ваших пользователей – сбрасывать просто так его не стоит.
- Я про то, что фирма «1С» рекомендует после обновления статистик делать сбрасывание кэша командой DBCC FREEPROCCACHE.
- Здесь фирма «1С» скорее перестраховывается. Знаете, в математике есть «необходимое» и «достаточное». У 1С рекомендации достаточные – чтобы все работало всегда, в любых условиях, без шанса на сбой в каких-то экзотических окружениях. И иногда такая перестраховка оказывается избыточной. Вы-то свои условия знаете. Вы можете убедиться, что при пересчете статистик планы обновляются. Соответственно, можете сами принять решение.
****************
Данная статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT 2019.

Вступайте в нашу телеграмм-группу Инфостарт