Что такое технологический журнал, для чего он нужен и какая информация в нем содержится - можно прочитать, на мой взгляд, в самой детальной статье Юрия Пермитина (ну и конечно же - ИТС).
Про Elasticsearch так же уже достаточно статей, что это и как это применять в мире 1С. Например, вот несколько ссылок:
Elastic + filebeat + ТЖ 1С
Взаимодействие 1С со сторонними продуктами
Перенос всех логов в Elasticsearch
В данной статье я подробно опишу возможности предложенного стека, особенности, нюансы.
Итак, все инструменты, в рамках стека - open source, а так же являются кросс-платформенными. Верхнеуровнево, архитектура решения выглядит следующим образом:
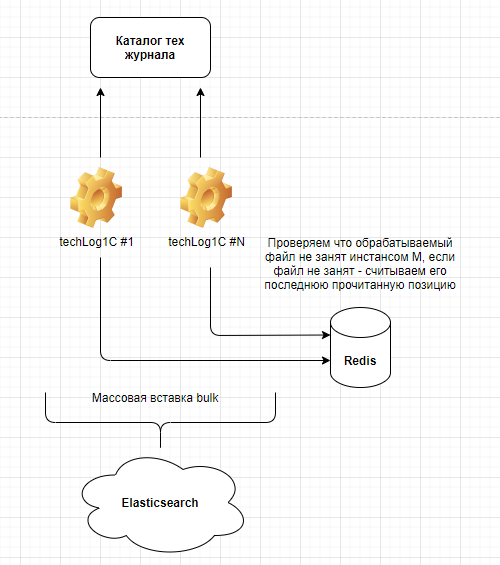
Что есть что на данной схеме:
Каталог тех. журнала 1С - каталог, в котором содержаться непосредственно логи. Уровень вложенности не важен, так как рекурсивно будут просмотрены все каталоги и прочитаны файлы с расширением *.log.
techLog1C - инстанс парсера. Одновременно может быть запущено несколько инстансов. Парсер принимает на вход массив файлов *.log производит парсинг, после чего отправляет данные в Elasticsearch. Парсер может работать многопоточно внутри своего инстанса а так же сам пишет логи в ходе своей работы (все это конфигурируется в файле settings.yaml - детальные настройки будет приведены ниже). Лучшей практикой является кейс, когда логи инкрементно забираются с продуктового сервера с некоторой периодичностью на служебную машину, где уже непосредственно стартует парсер. Такой подход не приводит к дополнительной нагрузке на продуктовый сервер.
Redis - NoSQL key-value СУБД. В стеке выполняет роль кэша, для хранения параметров файлов, которые обрабатываются в текущий момент времени и те, которые были обработаны (последняя позиция файла). Почему не используется простой текстовый файл? Все просто - парсер работает в многопоточном режиме, что требует доступ до файла в режиме записи из нескольких потоков. Redis позволяет решать следующие кейсы:
- Если файла тех. журнала уже нет, то при запуске парсера анализируются ключи в redis базе и проверяется существование файлов. Если файлы не существуют - ключи таких файлов удаляются.
- Так же при запуске еще одного инстанса парсера - будут пропущены файлы тех. журнала, обрабатываемые другими инстансами.
Несмотря на то, что redis все значения хранит в оперативной памяти - периодически служба производит запись на диск, в случае перезагрузки или сбоя службы - последние сохраненные значения будут восстановлены с диска.
Наиболее свежие и стабильные сборки redis осуществляются под linux, но и для windows есть сборки от Microsoft Open Tech.
Elasticsearch - используется как конечная точка хранения распарсенных логов 1С. Нереляционная база данных Elasticsearch позволяет достаточно оперативно получать необходимую информацию, используя поисковые обратные индексы. В связке с Kibana - можно строить выборки, используя декларативный KSQL язык запросов.
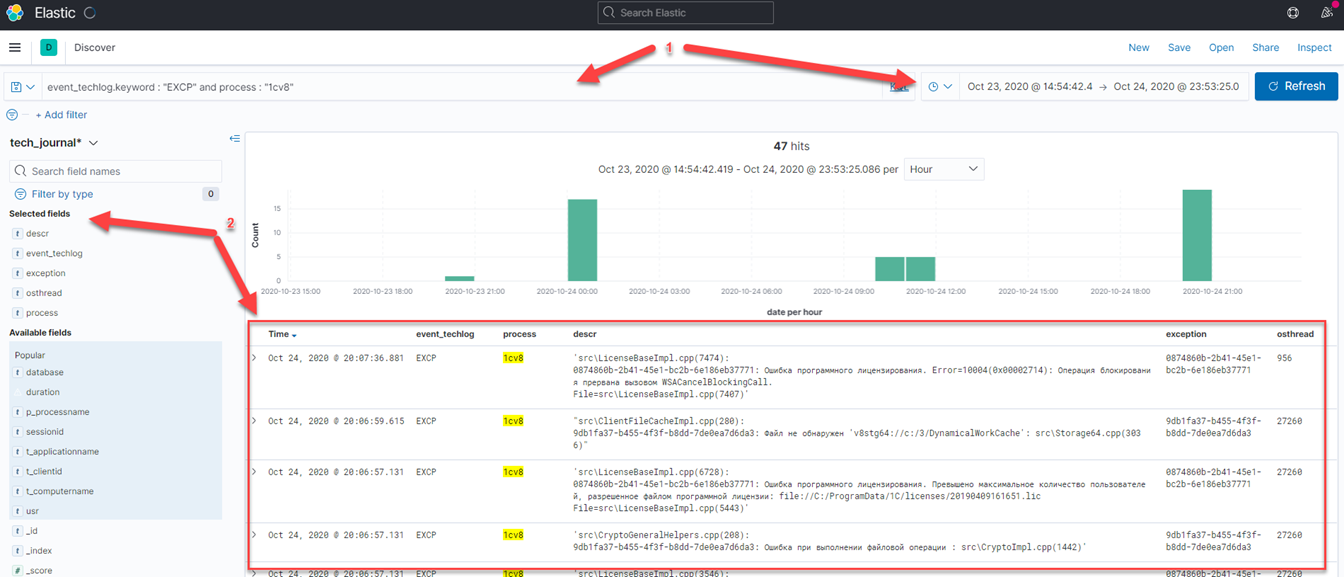
1. - Использование запросов KSQL
2. - Распарсенные поля, которые можно использовать в качестве выбранных полей.
При использовании расширения XPACK (30 day free trial) можно задействовать модуль машинного обучения (Machine Learning), что позволит выявлять аномалии и различные зависимости от показателей тех журнала и журнала операционной системы, например утечки памяти.
Описание настроек парсера
Все настройки указываются в файле settings.yaml
# Расположение логов тех журнала 1С
patch: "D:\\tmp\\1C_event_log\\1C_event_log"
#
# Параметры подключения к Redis
redis_addr: "localhost:6379"
redis_login: ""
redis_password: ""
redis_database: 0
#
# Параметры подключения к Elasticsearch
elastic_addr: "http://localhost:9200"
elastic_login: ""
elastic_password: ""
elastic_maxretries: 10
elastic_bulksize: 2000000
#
# Правила формирования индекса Elasticsearch
# Пример: "tech_journal_{event}_yyyyMMddhh", где event - CONN, EXCP, etc...
elastic_indx: "tech_journal_{event}_yyyyMMddhh"
#
# Типы событий тех журнала, которые могут содержать длинные строки '...' и переносы строк \n
tech_log_details_events: "Context|Txt|Descr|DeadlockConnectionIntersections|ManagerList|ServerList|Sql|Sdbl|Eds"
#
# Путь, где будут распологаться логи программы
patch_logfile: "D:\\tmp\\techLogData\\log"
#
# Глубина фиксации ошибок при работе программы:
# 1 - только ошибки
# 2 - ошибки и предупреждения
# 3 - ошибки, предупреждения и информация
log_level: 3
#
# Уровень параллелизма
maxdop: 14
#
# 0 - отключена сортировка файлов по размеру, 1 - сортировка по убыванию, 2 - сортировка по возрастанию
# полезно включать при массовых операциях, для равномерного распределения файлов по потокам
sorting: 0
Служба Redis может быть запущена на другой машине в сети, так же как и инстанс Elasticsearch. Для этого используются параметры redis_addr, elastic_addr. Redis из коробки поддерживает аутентификацию, в то время как Elasticsearch по умолчанию полностью открыт для доступа. Задать базовую аутентификацию для Elasticsearch можно через nginx.
Redis содержит внутри себя 16 баз данных, их нумерация целочисленная от 0 до 15. Рекомендуется задать параметр redis_database для случаев, когда в вашей организации уже используется Redis и необходимо изолировать существующие базы.
Параметры elastic_maxretries, elastic_bulksize - позволяют управлять поведением массовой вставки в индексы Elasticsearch. Elasticsearch имеет ограничения на операции массовой вставки bulk api. Из версии к версии они меняются. Ключевыми факторами, влиящими на успешную массовую загрузку являются - дисковая подсистема и процессор, помимо, конечно же объема пакета данных, отправляемых в массовом запросе. Операция bulk может выполняться параллельно из нескольких сеансов. В случае большого суммарного объема данных, которые отправляются сеансами - может произойти ситуация, когда Elastic просто не успеет обновить карту индексов и произвести индексацию загружаемых документов, что непременно приведет к ошибке и остановке службы Elasticsearch. Чтобы избежать этого - рекомендуется подбирать объем данных, отправляемых одним сеансов (в байтах), за что отвечает параметр elastic_bulksize. elastic_maxretries - число попыток повторной отправки пакета, в случае возникновения ошибок загрузки одного пакета данных.
Правило формирования наименования индекса можно задавать в параметре elastic_indx. Предложенного варианта формирования вполне достаточно для большинства случаев.
Параметры событий, которые могут содержать длинные строки с символами переноса строк лучше сразу указать в tech_log_details_events. По умолчанию, в настройках приведен перечень таких параметров, но если считаете, что указаны не все - их можно внести в настройки. Такой подход значительно сокращает время на парсинг файлов, но и несет в себе существенный минус - в случае появления нового параметра в событиях, например, с выходом новой версии платформы, может возникнуть проблема при формировании полей индексов в Elasticsearch в следствии некорректного парсинга.
Программа так же ведет логи своей работы, но не пишет их в Elastic, т.к. любой из инструментов стека может оказаться недоступен. Глубина логирования задается параметром log_level. По умолчанию он = 3 - то есть полная информация о поведении программы. Логи пишутся в формате json, что упрощает процедуру анализа впоследствии.
Парсер, как было указано ранее, может работать многопоточно, что особенно полезно когда у вас много логов, они тяжелые (например, включен полный тех журнал), или же вам необходимо произвести первоначальное чтение существующих логов. Количество потоков указывается в параметре maxdop. При использовании параметра sorting можно ускорить операцию чтения исторических логов. Если задать значение параметра = 2 (по возрастанию размера файла), то операции создания карты индекса будут производиться быстрее, т.к. файлы меньшего объема и содержат небольшое количество документов. Но лучшей практикой является описание карты индексов внутри map файлов, которые использует парсер (см. каталог maps). При таком подходе, при создании нового индекса, будет полноценно создаваться карта, а затем в индекс будут загружаться документы, что позволит исключить операции переформирования карты при каждой вставке документа. Тем более, что операция переформирования карты - достаточно дорогостоящая и блокирующая при операциях массовой вставки.
Особенности настройки Elasticsearch
Elasticsearch работает на JVM, поэтому очень требователен к настройкам памяти. По умолчанию размер кучи установлен в 1Gb, что крайне мало при массовой операции вставки документов в индексы Elasticsearch.
-
XMX/XMS рекомендуется установить равным половине оперативной памяти, доступной физической/виртуальной машине. Например, если у вас 16Gb, то возможный вариант настройки: -Xms8G -Xmx8G Документация
-
Очистка старых индексов (использование index lifecycle policy). Чем детальнее технологический журнал - тем сильнее будет расти его объем, а значит и индексы в Elasticsearch, это может привести к нехватке свободного места на дисках, где хранятся индексы. Лучшая практика - спустя N дней удалять индексы. Все что необходимо - задать политику жизненного цикла индексов https://www.elastic.co/guide/en/elasticsearch/reference/current/set-up-lifecycle-policy.html После этого задать темплейт, который будет включать индексы тех журнала
PUT _template/tech_journal_template
{
"index_patterns": ["tech-*"],
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "tech_journal_policy"
}
}
Но при таком подходе - политика применится только к вновь создаваемым индексам. Чтобы ее применить к уже существующим, нужно выполнить следующий запрос:
PUT tech_*/_settings
{
"index.lifecycle.name": "tech_journal_policy"
}
Известные проблемы:
- circuit_breaking_exception, [request] Data too large, data for [<reused_arrays>] would be larger than limit of: Измените параметры XMX/XMS
- es_rejected_execution_exception: rejected execution of coordinating operation Уменьшите уровень параллелизма (maxdop), подберите оптимальный размер блока на единицу bulk операции (elastic_bulksize), увеличьте параметр elastic_maxretries в settings.yaml файле.
- Долгая индексация, update mapping index. После загрузки каждого документа - если не задана карта индекса - карта создается, что создает накладные расходы, при количестве документов > 1 млн, обновление карты может не уложиться в таймаут по умолчанию (30 сек.). Поэтому, рекомендуется создавать map карты индекса (см. каталог maps)
Производительность
При включенном тех журнале, содержащем следующие настройки:
<?xml version="1.0" encoding="UTF-8"?>
<config xmlns="http://v8.1c.ru/v8/tech-log">
<log location="S:\1C_event_log\all" history="25">
<event>
<eq property="Name" value="EXCP"/>
</event>
<event>
<eq property="Name" value="CONN"/>
</event>
<event>
<eq property="Name" value="PROC"/>
</event>
<event>
<eq property="Name" value="ADMIN"/>
</event>
<event>
<eq property="Name" value="SESN"/>
</event>
<event>
<eq property="Name" value="CLSTR"/>
</event>
<property name="all"/>
</log>
<log location="S:\1C_event_log\tlocks" history="1">
<event>
<eq property="Name" value="TLOCK"/>
</event>
<event>
<eq property="Name" value="TTIMEOUT"/>
</event>
<event>
<eq property="Name" value="TDEADLOCK"/>
</event>
<property name="all"/>
</log>
</config>
суммарный размер лог файлов за сутки составляет 4,3 Gb. Инстанс парсера, запущенный при настройке 14 потоков на отдельной машине core i3 (v gen) с 16 Gb оперативной памяти, не ssd - обработал логи за 19 минут (bulk size - 200mb). При инкрементном запуске парсера каждую минуту - скорость обработки инкрементных данных варьируется от 5 до 14 секунд.
Самым оптимальным - является запуск парсера с одновременным включением тех журнала. В настройках тех журнала нужно указывать только те события, которые вам действительно нужны, а так же использовать отборы событий по параметрам, например - duration, p:processName и.т.д. Это позволит сократить объемы выходных логов, что положительно скажется на парсинге и хранении логов внутри Elasticsearch.
Резюме
Парсер является полностью открытым, расположен на:
https://github.com/NuclearAPK/go-techLog1C
Можно поучаствовать в его совершенствовании и оптимизации.
Так же буду рад конструктивным замечаниям и предложениям.
Вступайте в нашу телеграмм-группу Инфостарт







