Хочу рассказать о Patroni, и том, как мы его используем в нашей компании. У нас баз на порядок больше, чем заявлено в названии доклада, но 200 баз – рабочий, самый нагруженный контур, расскажу о нем.

Немного о себе и нашей компании:
-
Я работаю в крупной международной французской компании Mazars (АО «Мазар»).
-
Наша компания занимается аутсорсингом, аудитом, бухгалтерским сопровождением. Клиенты у нас в основном иностранные, но и российские присутствуют.
-
У нас много баз 1С самого разного размера.
-
Мы используем и любим PostgreSQL.
Расскажу предысторию, как все начиналось.
Раньше у нас в компании все базы 1С были развернуты на Windows и MS SQL – тогда практически все 1С-ники очень боялись Linux, и фирма «1С» тоже способствовала тому, чтобы использовать решения Microsoft SQL.
Но с течением времени в нашей инфраструктуре начали появляться решения из мира Linux – мониторинг Zabbix, ElasticSearch, Docker. В этих Linux-oriented-системах мы начали использовать PostgreSQL.
На одной из конференций Инфостарта я увидел выступление Антона Дорошкевич, где он рассказывал о своем опыте работы с PostgreSQL в 1С – Антон стал нашим идейным вдохновителем, чтобы попробовать PostgreSQL в реальной работе c 1C.
Вначале мы перевели на PostgreSQL наши архивные сервера с базами – они рабочие, но второстепенной важности. Так как у нас большие объемы, производительность Windows нас не устроила, поэтому мы выбрали Linux, тем более, что часть инфраструктуры у нас уже было под ним. Для нас это было шагом к использованию 1С на PostgreSQL под Linux.
Сталкиваясь с проблемами при написании и нестабильностью работы скриптов для обслуживания и реплицирования этих баз, мы начали смотреть, кто что использует для этой цели, и увидели, что для управления базами используется куча разных систем.
Мы не знали, на что ориентироваться, нам очень не хватало третьего мнения, чтобы кто-то рассказал о своих системах, о том, как их применить в реальной жизни на практике. И методом проб и ошибок мы пришли к использованию Patroni.
Этот доклад нацелен на то, чтобы человек, который стоит перед выбором систем для управления базами PostgreSQL больших объемов, мог посмотреть путь, которые мы прошли, взять готовый образ, развернуть его через vagrant up, проверить, насколько он ему подходит, и что-то скорректировать при необходимости.
Немного о том, как устроен PostgreSQL-кластер высокой доступности
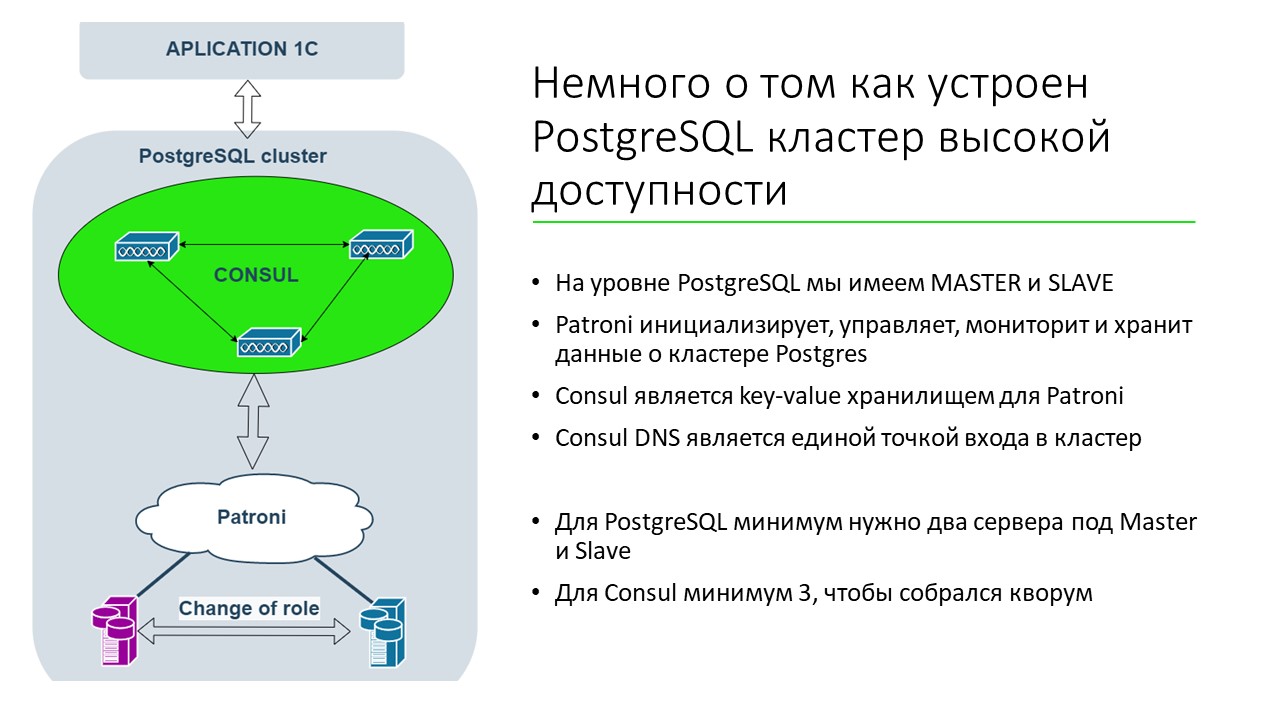
Как устроен PostgreSQL кластер высокой доступности? Под высокой доступностью я подразумеваю, чтобы кластер был доступен и работал на уровне PostgreSQL.
-
На уровне PostgreSQL есть MASTER и SLAVE-реплики.
-
Patroni из себя представляет написанное на Python приложение, которое работает на сервере и управляет инициализацией мастера, подключением реплик, отслеживанием. Взаимодействуя с Patroni, мы управляем нашим PostgreSQL-сервером.
-
Patroni для своей работы использует хранилища ключ-значение – бывают хранилища на etcd, Consul, Zookeeper и т.д. Мы в своей работе решили использовать Consul.
-
Сейчас 1C в нашей системе обращается к СУБД по имени домена. Если произошло переключение с мастера на слейв, Patroni помогает 1С переключиться с одного сервера на другой. Application-сервер 1С обращается к Consul DNS – это является единой точкой входа. DNS резолвится в айпишник, и мы через IP получаем айпишник нашего текущего сервера. Например, если у нас мастер находится на IP 10, то DNS-resolve превращает имя в IP и возвращает 10. А когда Patroni переключает сервер на слейв с IP 11, DNS-resolve «резолвит» уже IP 11. Получается, что в настройке сервера 1С прописан не IP-адрес сервера, а название домена и номер порта. Когда сервер 1С подключается, он резолвит имя в IP.
Что у нас было для реализации проекта

Когда мы начинали этот проект, мы владели двумя хорошими железными серверами. При этом любой кластер строится из трех серверов, поскольку нужно, чтобы при выпадении одного переключение происходило через голосование (кворум) – чтобы двое между собой определяли, кто теперь мастер. Так как мы хотели сэкономить в плане бюджета, я дальше покажу схему, как мы это реализовали.
При этом для нас было важно:
-
сделать работу с системой проще – снизить человеческий фактор;
-
безболезненно решать вопросы настройки серверов при смене администратора, чтобы не потерять определенные настройки – ядра в Linux, СУБД PostgreSQL и т.д.
Позже я расскажу, как мы этого достигли.
Почему выбрали Patroni

Систему для управления кластером СУБД мы выбирали по отзывам и комментариям к «видюшкам». Пробовали Corosync с Pacemaker, но он оказался очень сложен в настройке и обслуживании и требовал три сервера, а мы хотели все это организовать на двух.
Смотрели много разных решений, но по отзывам и по опыту нам больше всего понравился Patroni:
-
Patroni прост в конфигурировании – чуть позже я покажу команды, насколько просто всем этим управлять и работать.
-
В Patroni есть хороший REST API, через который можно определять мастер и слейв, их состояние и т.д. Мы его используем в работе.
-
Он прост в администрировании и удобен в использовании.
Текущая схема работы
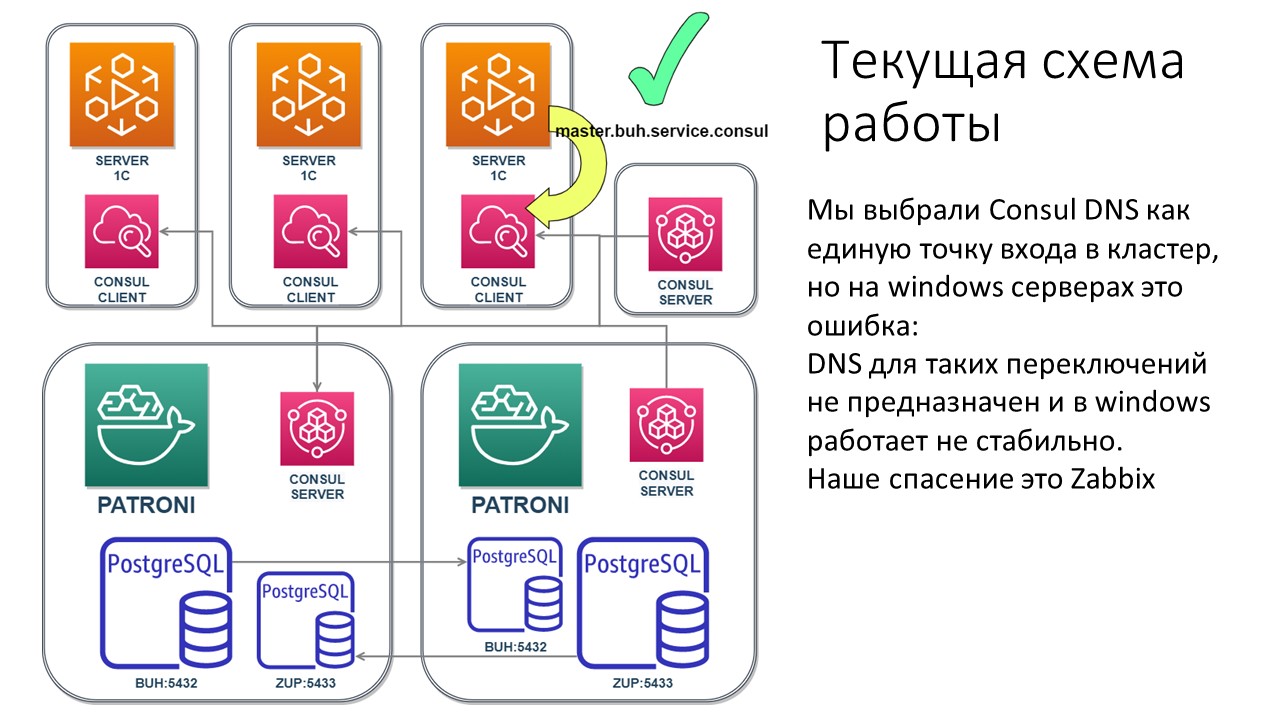
Текущая схема реализации, как это сейчас выглядит в нашей системе.
У нас есть три сервера приложений 1С;
Есть два сервера СУБД, на каждом из которых установлено два сервера PostgreSQL по DNS-портам 5432 и 5433. Из них мы создали два кластера, которые между собой реплицируются.
Условно, эти серверы у нас называются BUH и ZUP.
-
На первом сервере СУБД мастером является сервер BUH, который отвечает по порту 5432.
-
А на втором сервере СУБД мастером является сервер ZUP, он отвечает по порту 5433.
Таким образом, мы добиваемся экономии ресурсов по серверам. Мы понимаем, что в критический момент бухгалтерский сервер переедет к зарплатному серверу. Мы понимаем, что будет проседание по производительности, но ресурсов хватит.
Мы стараемся отслеживать, чтобы не происходило проблем при совместной работе. И стараемся мониторить по текущим загрузкам, не надо ли нам увеличивать мощность серверов. Одно из решений – мы переключаем на несколько дней зарплатный сервер вместе с бухгалтерским, они работают на одном сервере, чтобы проверить, хватит ли ресурсов в случае сбоя и не было никаких проблем.
Двумя кластерами мы добиваемся распараллеливания нагрузки и таким образом оптимально используем серверные ресурсы.
На двух серверах СУБД работает Patroni, управляет этими двумя кластерами. В проекте на GitHub выложены конфиг-файлы для него – пользуйтесь.
Consul – это не только хранилище для Patroni, но еще и сервер для резолва имени в IP-адрес.
На слайде я привел пример – для бухгалтерского сервера прописан URL master.buh.service.consul, а в настройках базы указано, к какому серверу подключаться и указан порт – 5432. Именно так и реализована эта единая точка входа.
Поскольку клиент Consul стоит на всех трех серверах приложений 1С, сервер 1С обращается не к какому-то конкретному IP-адресу, а к локальному адресу 127.0.0.1, к localhost. Поэтому, когда сервер 1С обращается к localhost, резолвится имя, он получает рабочий айпишник и порт самого PostgreSQL – на каком он сервере находится.
Так как кластерная система работает только в группе из трех серверов, для этого на одном из серверов 1С была поднята виртуальная машина, а на ней дополнительно развернут Consul-сервер, чтобы определять, кто является мастером.
Важно понимать, что в кластерных системах, если выпадает один сервер, а другой остается, то определяется, что он мастер. Но если в кластере из двух серверов между двумя серверами возникает недоступность, и они друг друга не видят, может возникнуть ситуация, которая называется сплит-брейн. В этом случае оба сервера становятся мастером и оба принимают запросы на изменение данных, и получается, что у нас две базы данных друг от друга расходятся. Чтобы избежать такой ситуации и организовать стабильность, в кластерных решениях используются три сервера.
Поэтому key-value-хранилище в Consul изначально подразумевает, что должно быть три сервера. Соответственно, когда один сервер выпадает, два сервера других друг друга видят и решают, кто является мастером.
У нас возникала ситуация, когда у нас из-за нехватки ресурсов на сервере 1С один Consul-сервер отпал, и мы этого не заметили. После чего по какой-то причине произошла потеря двух оставшихся серверов между собой – в итоге у нас система была полностью остановлена, для нас это было фатально. Мы решили вопрос так: снизили нагрузку на сервере с третьим Consul, обеспечили стабильную работу этого третьего сервера, и проблема с переключениями ушла.
Сейчас у нас если остается один Consul-сервер, он останавливает работу PostgreSQL, останавливает весь кластер и становится недоступным, чтобы не привести к сплит-брейну. Это важно, чтобы потом не пришлось «смачивать» данные из разных баз между собой.
На текущий момент мы используя Consul в DNS, столкнулись со следующими проблемами.
-
В идеале Consul лучше относить на менее загруженные сервера – в мире виртуализации люди обычно отдельно ставят виртуальные машины и выносят Consul на них. Но в Consul обязательно должна быть хорошая дисковая подсистема для работы. Поэтому решение – выносить Consul отдельно от серверов, это влияет положительно.
-
Следующая проблема, с которой мы столкнулись – нестабильная работа DNS-сервера под Windows. Из-за того, что мы – аутсорсинговая компания, у нас много сторонних проектов со своими базами, где могут быть самые разные решения, в том числе содержащие COMОбъекты и т.д. Поэтому мы не можем диктовать клиенту наши условия и используем сервера 1С под Windows. Пробуем и под Linux, но в продакшене в основном у нас так. Когда сервер 1С обращается к локальному резолву DNS, происходит проблема: иногда из-за большой нагрузки Windows-сервер переставал «резолвить» IP-шник.
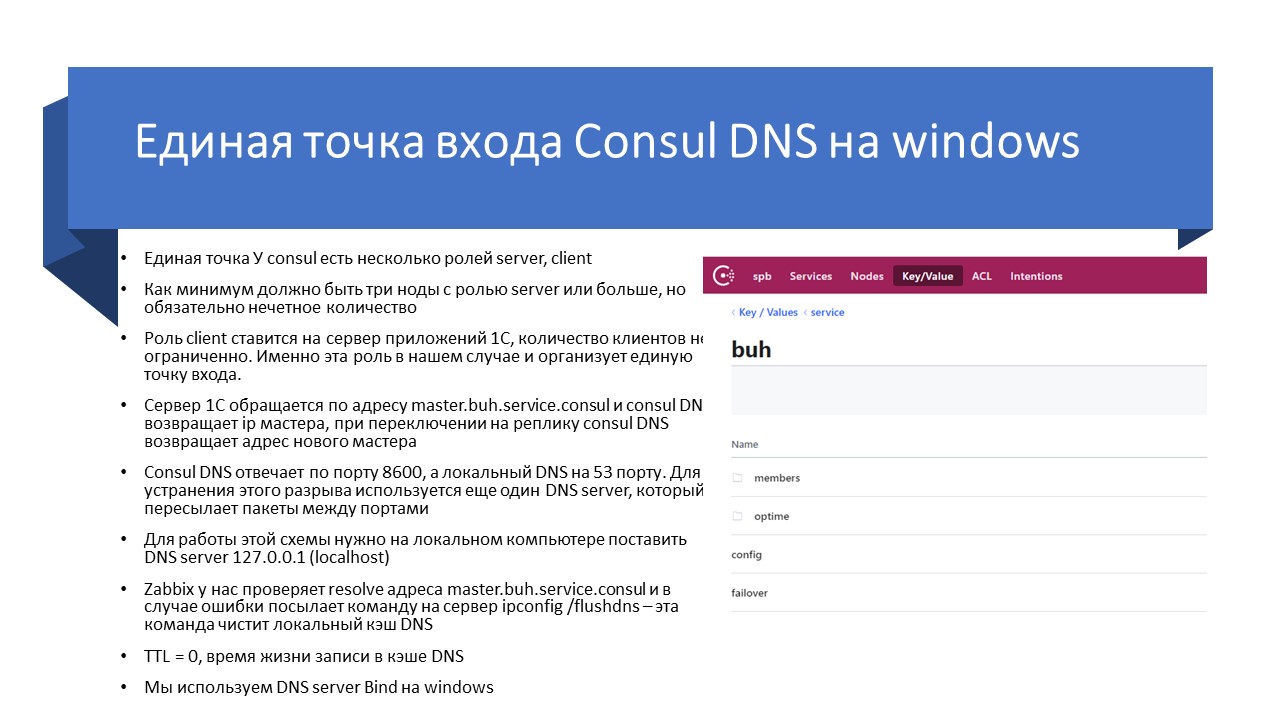
Как это лечится?
-
У нас есть команда ipconfig /flushdns, которая позволяет нормально взаимодействовать. Поэтому когда эта система перестает резолвить имя, у нас Zabbix запускает на сервере эту команду и очищает локальный кэш DNS. После чего система опять начинает нормально взаимодействовать.
-
В нашем случае на «виндовый» сервер 1С пришлось устанавливать еще один DNS-сервер, потому что Consul DNS работает на порту 8600, а локальный DNS – на 53 порту. Чтобы «форвардить» запрос с 53 порта на 8600 используется еще один DNS-сервер.
-
Мы используем для Windows DNS-сервер Bind, он работает наиболее стабильно. Из всех DNS-серверов, что были приведены на сайте Consul, это было единственное рабочее решение, которое позволило выйти на нормальное состояние.
Вывод – резолв DNS работает, его можно использовать, но в нем есть проблемы.
Из-за этого мы сейчас решили использовать виртуальные IP и тестируем у себя работу в VRRP (Virtual Router Redundancy Protocol) – плавающий айпишник. У нас на этих двух серверах будет поднята служба keepalived и IP-шник с одного сервера будет «ездить» на другой. Сейчас продумываем более детальную схему работы.
Чем мы пользуемся в Patroni

Управление Patroni в Linux происходит через утилиту patronictl по команде:
patronictl -c /etc/patroni/postgresql.yml list buh
где buh/zup – это имена кластеров,
postgresql.yml – это файл конфига PostgreSQL. Файлов конфигов может быть несколько – можете использовать любой. Patroni сам знает, для какого сервера какой конфиг брать, Мы в Patroni используем два разных порта для работы двух кластеров, поэтому в настройках Patroni у нас лежит несколько конфигов postgresql.yml.
Команды, которые можно использовать для Patroni:
-
list – вывод свойств кластера.
-
edit-config – редактирование конфигов в PostgreSQL. Через него очень удобно вносить изменения – вы зашли в единое окно, поменяли конфиги. Если нужно, он попросит вас перезагрузиться. Потом вы нажимаете команду list, и он вам показывает некоторые изменения.
-
Например, надо перезагрузить кластер, есть команда restart, не нужно ходить по каждой ноде, он это сделает сам.
-
Если предстоят изменения конфигов, не приводящие к перезапуску мастера, у нас есть команда reload.
-
Если вам нужно поработать с PostgreSQL, чтобы он не делал этот автофайловер с одного сервера на другой, то можно ввести команду pause – она выключает автофайловер.
-
resume – продолжить после pause
-
switchover – мы используем для тестов. Переключаем работу зарплатного сервера на сервер бухгалтерии и у нас два кластера работают в одном. При необходимости, мы точно так же можем переключить обратно на другой кластер. Все очень удобно в обслуживании и просто.
-
reinit – команда пересоздания реплики, если произошел автофайловер (переключение с мастера) и нужно разбираться с проблемами – иногда реплику нужно переинициализировать.
Кстати, если бы команда GitLab использовала Patroni с такими командами, они бы не потеряли бы кучу данных – у них была известная проблема, когда они перезатерли мастер с реплики – Patroni такого сделать не даст.
Ansible + Git

Для управления всеми конфигурациями мы используем Ansible.
Грубо говоря, у нас все скрипты по настройке серверов лежат в Git. И Ansible может простыми командами настраивать.
Например, вам надо на сервере открыть какой-то порт – в этом случае вы запускаете определенный playbook, внутри файла добавляете номер порта, нажимаете «Применить на всех серверах» и у вас на всех серверах открывается какой-то порт.
Нужно установить какое-то дополнительное приложение – все это происходит быстро.
Ansible упрощает администрирование и дает администратору понимание, как был настроен сервер. Он помогает нам, чтобы администратор входил в строй достаточно быстро, чтобы управление серверами было просто и понятно.
Все настройки ядер вынесены сюда – все у нас в открытом доступе, мы всегда сможем сюда вернуться и что-то перенастроить. Для каких-то сложных настроек можно писать комментарии – чтобы дать пояснение по какому-то параметру.
Мы в своей работе используем Ansible – это очень удобно.
В кулуарах осенней конференции все говорили, что чтобы использовать управляющие системы нужно 200 серверов. Нет, не надо. Мы используем несколько серверов и всегда знаем, что у нас где настроено.
Если у нас один сервер упал, идет переключение. Мы перенастроим и за несколько часов выведем сервер в боевую готовность – будет поднята свеженькая система со всеми необходимыми настройками. Очень удобно, пользуйтесь Ansible, изучайте.
По ссылке на GitHub можно скачать образ с тестовым окружением Patroni для 1С – я выложил туда много скриптов. Этот образ можно поднять через vagrant up, посмотреть и попробовать, как это все работает.
Вопросы
У вас 1С-сервера в большинстве своем на Windows, вы с Linux только начинаете экспериментировать?
На основных рабочих серверах СУБД мы сейчас используем PostgreSQL и Linux. Но 1С-ные сервера пока еще держим на Windows, только пробуем переводить на Linux.
У вас есть какой-то кластер виртуализации? Все это работает на виртуальной среде?
Рабочие PostgreSQL-сервера – это физические сервера, потому что мы не настолько большие, чтобы датацентр выделял под нас целые полки и настраивал среду так как нам нужно. На этих физических серверах помимо PostgreSQL развернут также Consul и Patroni.
А 1С-сервера у нас находятся в виртуальной инфраструктуре и работают в среде Windows. Они с помощью Consul подключаются к Patroni. А Patroni управляет кластером серверов PostgreSQL.
Какое соединение между виртуальными и физическими серверами?
Между серверами соединение 10Гб.
Вы используете синхронную или асинхронную репликацию?
Patroni позволяет работать и с синхронными, и с асинхронными репликациями, но для нашего бизнеса было принято решение, что для синхронной репликации нужно намного больше инфраструктуру, затрат и т.д., чтобы все это выстроить нормально. Поэтому было принято решение, что мы готовы потерять какой-то кусочек данных, и работать с асинхронной репликацией.
У вас на PostgreSQL крутится 200 баз? Они разделены между разными PostgreSQL-серверами?
У нас два PostgreSQL-сервера, но на них два кластера и между ними идет переключение.
На каждом сервере установлено несколько инстансов PostgreSQL? Они развернуты в Docker?
Нет, они не в Docker, они на физических серверах. У нас поднято два кластера PostgreSQL. Один отвечает на порту 5432, другой отвечает на порту 5433. Между этими кластерами связи нет, но благодаря этому мы используем оба сервера по максимуму.
Много клиентских подключений обслуживается одновременно?
На эту инфраструктуру одновременно коннектится больше тысячи подключений.
Вы говорили про аварию, когда один Consul перестал видеться, остались двое, а потом и они друг друга забыли. Насколько часто вылетает один из серверов?
У Consul часто бывают проблемы отсутствия резолва, но мы это решаем с помощью Zabbix – у нас там есть экшены, которые отрабатывают на разные проблемные ситуации. Серверы достаточно стабильно работают – переключения между репликами бывают очень редко. Последний раз это было полгода назад.
Какие используются диски, память и хранилище?
На сервере с PostgreSQL диски – SSD. В виртуальной инфраструктуре мы тоже договорились, что там хорошие скорости пробрасывают. Памяти у нас на каждый сервер СУБД 128 ГБ.
Допустим, мастер упал – реплика переключилась в мастер. Потом мастер поднялся – он автоматически станет слейвом?
Нет, автоматически происходит автофайловер, а переключение бывшего мастера в работу мы производим в ручном режиме. Это связано с тем, что можно перезатереть данные. Необходимо расследовать проблему, почему произошел файловер. Это связано с тем, что у нас бывший мастер станет слейвом, а потом произойдет переключение обратно – может быть, там проблема с железом и это может остановить вообще всю систему.
Понятно, что упавший мастер не должен становиться мастером снова, но он может стать автоматически слейвом – синхронизироваться с текущего мастера? Или вам приходится его вручную запускать?
В Patroni есть команда – в некоторых случаях он подключается, в некоторых случаях приходится делать reinit. По-разному происходит.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "PostgreSQL VS Microsoft SQL".

Вступайте в нашу телеграмм-группу Инфостарт