Всем здравствуйте! Меня зовут Лилия Алёхина. Я представляю компанию Самокат.
В большинстве компаний, где мне доводилось работать, реализация обменов выглядела следующим образом:
-
Среди разработчиков (дай бог, если их в компании больше чем один) выбиралась жертва.
-
Эта жертва делала обмен в одиночку под ключ (а это анализ, разработка, тестирование) - качество зависело от квалификации, опыта, личной ответственности и сроков.
-
После запуска на проде - ошибки, хот-фиксы, доработки, откаты (много или мало зависело не только от качества, но и от правильного понимания задачи - это же разработчик, а не аналитик).
-
В итоге все выливалось в переработки в авральном режиме, а все шишки сыпались на единственного исполнителя (а на кого же еще?).
И чем чаще ты пишешь обмены, тем чаще выбирают тебя, потому что у тебя же опыт.
Какая уж тут любовь?

В результате в подобных задачах имеем на рынке вот такую картину с разработчиками обменов 1С. Я считаю, что сложившуюся ситуацию нужно в корне менять.
А для этого необходимо повысить уровень комфорта при разработке обменов – и таким образом удовлетворить ту самую «потребность в безопасности» в пирамиде Маслоу.
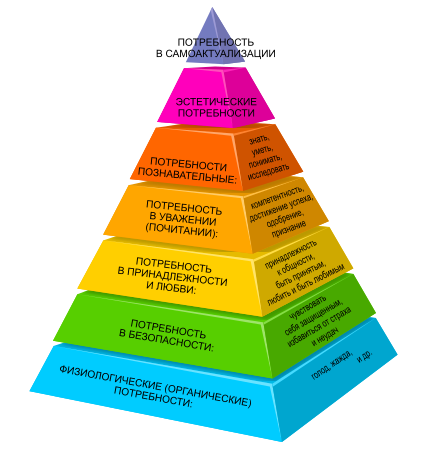
Тогда разработчиков 3 типа станет больше, а значит, и результат будет лучше.
Я расскажу про подходы, которые мы внедрили в своей компании для реализации обменов.
И вы можете начать внедрять их в своей команде как кирпичики – вместе или по отдельности, с использованием тех же программных средств и подобной архитектуры или совсем других.

В целом я выделяю 5 следующих составляющих в реализации обмена, на которые стоит обратить внимание и поработать над их качеством:
-
автоматизация рутинных операций;
-
внятное техническое задание, написанное системным аналитиком;
-
качественное тестирование перед запуском на прод;
-
регулярная сверка результатов после запуска;
-
и прозрачность системы в целом – с той простой целью, чтобы не только исполнитель мог потом с этим разобраться.
Подсистема событийной интеграции
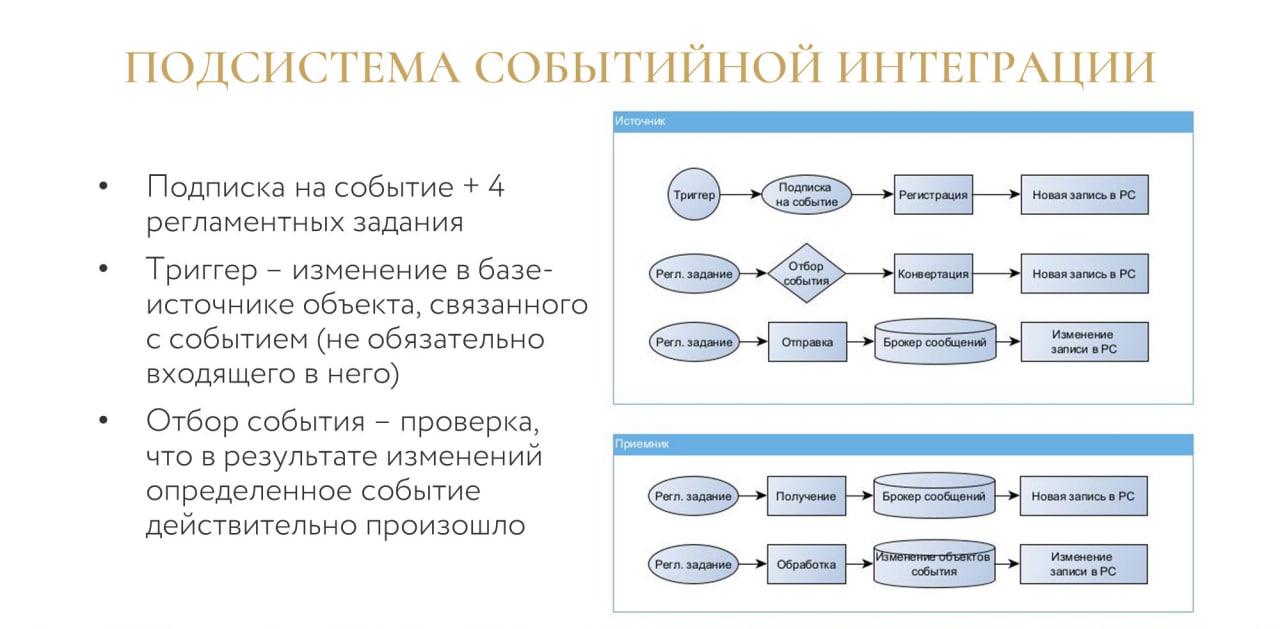
В нашей компании разработана подсистема событийной интеграции. Мы отказались от использования классических планов обмена (там есть свои неприятности с блокировками в высоконагруженных системах – а это как раз про нашу компанию) в пользу двух регистров сведений.
-
В первый по триггеру в транзакции пишется ссылка на объект, связанный с событием. Что важно, не всегда этот объект в итоге входит в событие. При этом отбор вынесен из транзакции в регламентное задание конвертации, чтобы в самой транзакции у нас был минимум манипуляций – зарегистрировали и забыли.
-
Второй РС – это очередь сообщений к обмену, сюда уже пишется итоговый JSON.
-
После транзакции информация обрабатывается последовательно 4 регламентными заданиями:
-
в источнике 2 регламентных задания отвечают за конвертацию и отправку в брокер сообщений;
-
в приемнике 2 – за получение из брокера и обработку на стороне базы-приемника.
-
Такой подход избавляет от многих проблем, которые есть у планов обмена, позволяет сегментировать сообщения к выгрузке и организовать гибкую многопоточность при загрузке.
Хочу заметить, что эта подсистема подходит не только для обмена между разными базами 1С, но и для обмена с другими внешними сервисами.
-
Либо 1С – это источник, а приемник – внешний сервис, где обработкой сообщений занимаются уже какие-то другие департаменты, вообще не 1С-ники. Они уже дальше сами разбираются, что с этим делать.
-
Либо наоборот, когда сообщение приходит из внешнего сервиса в брокер и дальше уже обрабатывается в вашей базе 1С.
В подсистеме используются единые алгоритмы конвертации в источнике и обработки в приемнике и соответственно единый формат сообщения.
Мы для себя решили, что описывать каждый раз весь обмен в коде с нуля – это нецелесообразно, т.к.:
-
немасштабируемо;
-
трудозатратно при разработке и для разбора другими разработчиками;
-
приводит к неминуемому копипасту.
Если в вашей команде используется системный подход, то транспорт чаще всего плюс-минус одинаковый. И конвертация плюс-минус одна и та же – каждый раз перечисляются реквизиты, которые надо переносить.
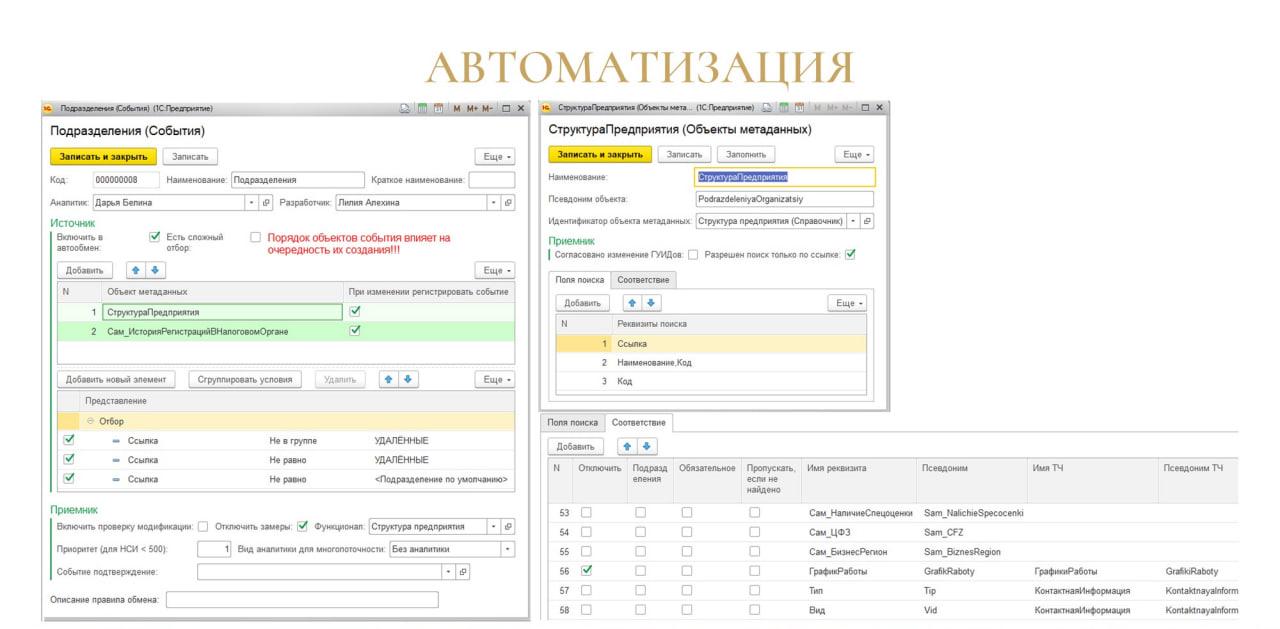
В итоге мы постарались вынести максимум настроек в интерфейс, результатом чего стало 2 справочника:
-
спр. «События», в котором:
-
состав события;
-
простые отборы;
-
включение обмена;
-
настройки для многопоточности (о них я расскажу дальше).
-
-
спр. «Объекты метаданных» (он чем-то похож на правила конвертации объекта в «Конвертации данных 2»), в котором:
-
варианты полей поиска (здесь уже привет «Конвертации данных 3»);
-
псевдонимы объектов, реквизитов и табличных частей для JSON;
-
перечень реквизитов обмена с возможностью выключения для отдельных событий или в целом для обмена, если вы ими вообще не хотите обмениваться.
-
По поводу псевдонимов замечу, что поскольку мы обмениваемся не только с 1С, но еще и с внешними сервисами, атрибуты в JSON у нас в латинской транскрипции, а не в русской, чтобы не смущать коллег.

Благодаря такому подходу:
-
для реализации простого обмена в источнике код вообще писать не нужно (достаточно при настройке поставить нужные галочки), а в приемнике разработчику необходимо добавить 1 процедуру с одной строчкой выполняемого кода.
-
в случае сложных обменов уже наработан фреймворк в виде процедур и функций общего модуля, используя который можно обрабатывать достаточно нетривиальные кейсы обмена. Это покрывает все возникающие потребности, и новых процедур уже давно в этом перечне не было.
Не буду останавливаться на каждой процедуре отдельно – за них говорит их название.
-
Есть смысл упомянуть процедуры на стороне приемника ПроверитьЛогикуПоОбъекту() и ПроверитьЛогику(). Здесь реализуются проверки данных, они зависят от задачи и от того, какие могут быть косяки в данных – могут наращиваться по ходу тестирования или даже после запуска, если, например, уже на большом объеме реальных данных у нас появляются какие-то странные вещи. В целом важно понимать, насколько такие проверки целесообразны в конкретных процессах.
-
То же касается и автоматической корректировки данных, что возможно в процедуре ПодготовитьСтруктуруКОбработке(). Например, если у нас в поле «Количество» пусто, можно при желании единицу ставить, или наоборот удалять такую строку – это все, опять же, на усмотрение по логике задачи.
Транспорт

Транспорт – тоже общий механизм, здесь используем брокер сообщений Apache Kafka.
Сегодня в сообществах 1С и не 1С брокер сообщений – то ли мем, то ли тренд. У многих команд формируется странное восприятие, что если сделать обмен с помощью брокера сообщений, то это решит все проблемы с обменами. Этакая панацея.
Мы долгое время в качестве транспорта использовали http-сервис. Нас более чем устраивала скорость, была гарантия доставки. Все было хорошо. Единственную проблему, которую мы решали, перенося транспорт на Apache Kafka – произвольное число получателей.
Мы решили остановиться на продукте компании «Серебряная Пуля», поскольку нам уже доводилось с ним сталкиваться пару лет назад и он устроил нас в качестве фундамента, на основе которого мы можем строить собственное решение.
Перенесли конфигурацию в расширение и сделали минимум доработок (они на слайде). Бонусом получили ускорение доставки при больших объемах.
В итоге полное время выполнения от регистрации до завершения обработки в приемнике – от 1 до 5 минут (при отсутствии ошибок в данных).
Многопоточность
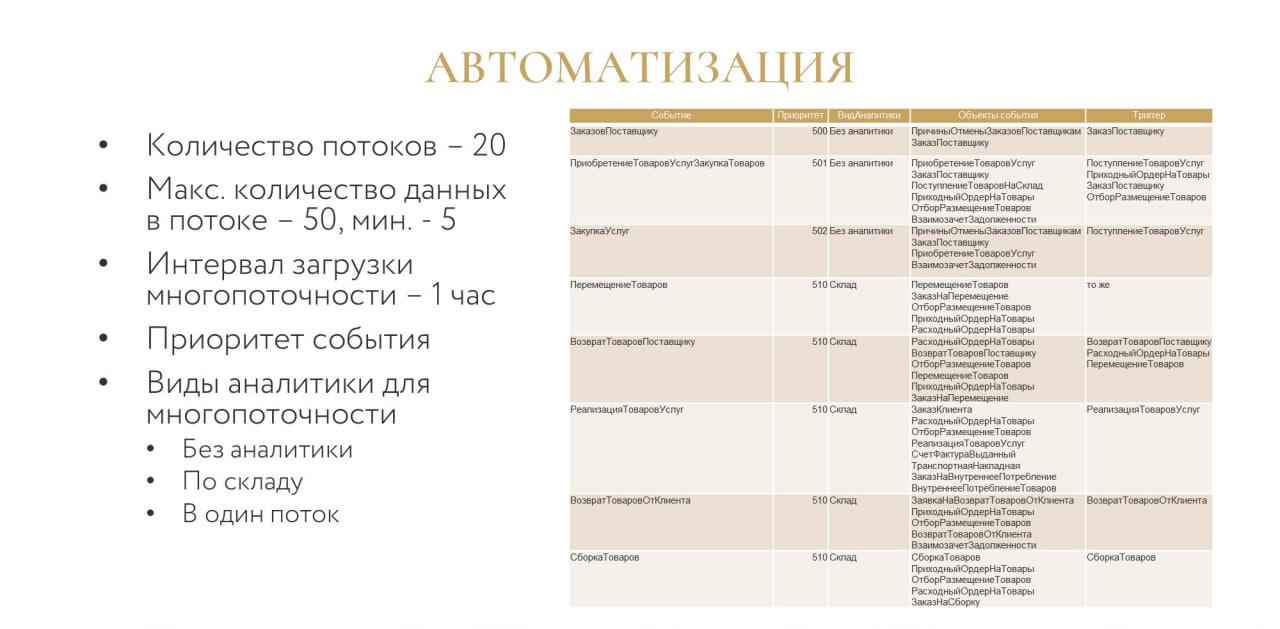
Как ни крути, самое узкое место в плане производительности – это обработка сообщений после получения в базе-приемнике.
В ходе развития подсистемы нами был выработан подход к реализации многопоточности.
У каждого события есть:
-
приоритет;
-
дата возникновения события;
-
вид аналитики для многопоточности.
Приоритет и дата обеспечивают порядок, в котором обрабатываются события.
Вид аналитики – критерий, по которому данные группируются в потоки:
-
Вариант «Без аналитики» хорошо укладывается для нормативно-справочной информации и для документов прихода – для них порядок при организации многопоточности не важен.
-
Вариант «По складу» разумно использовать для документов расхода, потому что у нас используются серии, для которых важен хронологический порядок проведения документов.
-
Вариант «В один поток» – в качестве примера я могу привести документ перемещения товаров, где это приход на один склад, расход с другого склада, и здесь уже события логично выстроить в цепочке друг за другом.
Такое управление многопоточностью дает определенную гибкость в различных ситуациях и решает проблему со скоростью обработки на стороне приемника.
На слайде приведена таблица с примерами , какие настройки могут быть для событий по цепочкам документов:
-
приоритет события;
-
вид аналитики для многопоточности;
-
состав события;
-
и триггер - объект, при изменении которого событие возникает (обратите внимание, что есть варианты, когда сам триггер в состав события не входит).
Проработанное ТЗ

При таком подходе к реализации обменов техническое задание – это не какой-то огромный текст, который пишется бесконечное количество времени, а потом еще столько же времени согласуется со всеми участниками процесса (в случае обмена их еще нужно поискать).
Техническое задание при едином подходе к написанию обменов – это документ, написанный по единому образцу, без лишней воды со строго определенными разделами, понятными как системному аналитику, так и разработчику после написания хотя бы одного обмена.
Многие привыкли, что обмен – это исключительно техническая задача, в которой не нужен анализ. В начале я рассказывала, чем это плохо. Обмен – это такой же бизнес-процесс. И я считаю, что он даже еще более критичный. Однажды вы ставите его на выполнение, и дальше он выполняется сам и делает с вашими данными бог весть что. И если никто в этот процесс раньше не вникал, это проблема.
Наличие проработанного аналитиком ТЗ очень важно, хотя бы для того, чтобы не переделывать задачу по несколько раз. В качестве побочного эффекта имеем документацию и сплоченную команду, готовую выдавать качественный результат в короткие сроки.
Если возвращаться к фильму «Веном», который был выбран как визитка секции «Интеграция и обмен данными», мы здесь имеем уже тройную симбиотическую систему разработчик + инструмент + аналитик. Такой тройной эффект есть и в природе, если поискать. Т.е. здесь мы движемся эволюционным путем.
Тестирование и регулярная сверка

Тестирование – важная составляющая в реализации любой интеграционной задачи. Поэтому после реализации и код-ревью задача передается аналитику.
На слайде приведены этапы тестирования, которые мы выделяем. Отдельно остановлюсь на тестировании на ограниченной и полной выборке – при больших объемах часто проявляют себя кейсы, которые, как говорится, нарочно не придумаешь.
-
Тестирование на полной выборке справедливо для нормативно-справочной информации.
-
Тестирование на ограниченной выборке справедливо для документов – тут в зависимости от объема выбирается какой-то период. Мы можем взять документы за месяц из исторических данных. Можем взять за неделю.
Именно на этих этапах тестирования вы выявите максимальное количество кейсов. И если их избегать, то можно поймать очень много неожиданного и неприятного после запуска на проде.
Плюс мы придерживаемся стратегии, что при обменах изменения должны быть идентичными с интерактивными изменениями данных. ОбменДанными.Загрузка = Ложь – это на моем опыте то, чего обязательно придерживаться при обмене с внешними системами, потому что если с другой базой 1С еще можно надеяться, что источник отвечает за корректность данных, то внешние сервисы часто разрабатываются людьми, очень далекими от учета.

После запуска очередного обмена в регулярное выполнение добавляется алгоритм сверки по нему. Для этого в подсистеме реализован механизм сравнительных отчетов. Он доступен из пользовательского интерфейса, чтобы вне релизов можно было комфортно вносить изменения и как-то играть с данными, которые он возвращает.
-
Пишется 2 запроса – к текущей базе и к внешней базе – в пользовательском интерфейсе, что позволяет вносить изменения вне релиза. Плюс есть возможность добавить процедуру постобработки. Результат выполнения показывает расхождения в данных в удобоваримом виде.
-
Ничего не мешает писать запрос и к внешним сервисам, если возникнет такая необходимость, и получится договориться с коллегами «по ту сторону» о том, что мы шлем им запрос, и они нам взамен присылают данные в нужном формате.
-
Сверка выполняется регламентным заданием. Настроена метрика в Prometheus. В случае отклонений приходит уведомление.
-
События сгруппированы в функционалы. И по ним можно настроить уведомления ответственным в случае ошибок, сбоев и успешном выполнении. Например, кому-то из пользователей нужно узнавать, что появился новый контрагент, чтобы что-то там в нем урегулировать – например, завести ему договор.
Прозрачность + Стабильность = Любовь

В итоге описанный подход обеспечивает прозрачность при разработке, поддержке и мониторинге обменов. Обмен перестает быть черным ящиком, процесс становится осязаемым и контролируемым.
После запуска обслуживание можно передать даже на первую линию поддержки, чтобы освободить ваших разработчиков от постоянной слежки за обменом, все ли там хорошо, чтобы не поднимать его в час ночи, если что-то не так, и чтобы в принципе человек уже дальше занимался своей работой и приносил пользу.
Система масштабируема:
-
и в плане реализации обменов (достаточно добавить единые расширения в новую базу, что делается за полдня);
-
и в плане подключения новых потребителей сообщений за счет брокера.
Комфортно работать не только команде, но и руководству - увольнение разработчика перестает быть фобией: обмены не парализованы и не живут своей жизнью при смене части команды.
Если в своей работе вы внедрите хотя бы некоторые из озвученных подходов, то вы определенно упростите разработку обменов в своей команде, не придется краснеть за свои обмены, не будет страшно при очередном запуске, а возможно вы и ваши коллеги даже полюбят писать обмены так же, как все любят реализовывать другие сложные задачи автоматизации бизнеса.
Спасибо за внимание!
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.

Вступайте в нашу телеграмм-группу Инфостарт