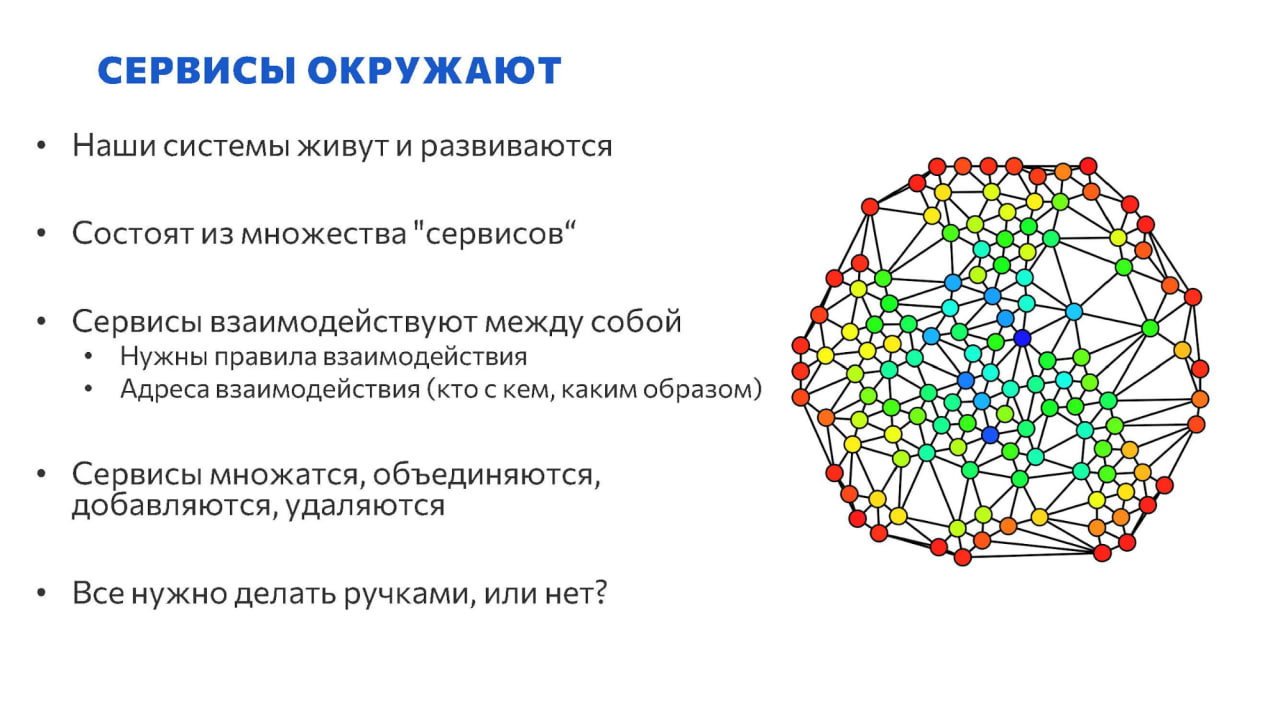
Жизнь усложняется, и информационные системы у большинства наших клиентов уже давно не ограничиваются одной информационной базой 1С – они состоят из множества компонент:
-
Это уже не просто Бухгалтерия или ERP, это множество баз, внешних сервисов и систем, возможно даже не на 1С, которые взаимодействуют между собой по определенным правилам.
-
Эти системы не статичны – они могут появляться или исчезать, одни системы могут заменяться другими. И со всем этим нужно жить так, чтобы не было мучительно больно перенастраивать все связи каждый раз вручную.
-
Более этого, системы могут жить не в одной среде – например, если у вас есть среда тестирования, ее состав тоже нужно оперативно обновлять и перенастраивать в зависимости от того, как растет и развивается ваша основная система.

Введем понятие сервиса на примерах.
Сервис – это все, что имеет какой-то вход в виде запроса и выход в виде ответа на этот запрос. Сервисом может быть:
-
Почтовый сервер.
-
Файловое хранилище,
-
База 1С – то, с чем мы больше всего работаем.
-
В этой концепции можно выделить отдельные сервисы даже внутри одной базы (например, БСП потихоньку движется в этом направлении, обрастая различными модулями).
-
Сервисы могут быть абсолютно внешними, например, служба поддержки – это сервис.
-
И разработчик, который сидит и что-то допиливает, – это тоже сервис, у него есть вход и выход.

Теперь перейдем к понятию Service Discovery. По-русски это «Служба обнаружения сервисов». Служба Service Discovery отвечает на вопросы сервисов, которые хотят взаимодействовать с другими сервисами, предоставляя следующую информацию:
-
Какие настройки нужно использовать сервису, чтобы взаимодействовать с остальными.
-
По какому протоколу сервис может общаться с другими сервисами.
-
Где вообще находится сервис с таким-то именем – какой у него IP-адрес.
-
С каким логином и паролем к этому сервису нужно обращаться.
-
и прочее.

Пример из жизни – в офис приходит новый сотрудник, который выступает сразу в двух ролях:
-
Он является клиентом тех сервисов, которые ему может предоставить офис.
-
И он же сам предоставляет сервис – собственно, для этого он и пришел.
С точки зрения клиента сотруднику нужно знать:
-
Какие «сервисы» есть в офисе.
-
К кому с каким вопросом обратиться.
-
Где ему взять стол, стул.
-
Где поесть.
А с точки зрения сервиса – если это, предположим, пришел разработчик, он рассказывает:
-
Я – Вася Иванов, разработчик на Java, владею Spring Boot, немного видел 1С.
-
Я решаю такие-то вопросы.
-
Сижу там-то.
Где в этом случае место Service Discovery?
-
В первую очередь, роль Service Discovery выполняет служба HR, т.е разработчик задает HR-менеджеру все основные вопросы, которые помогут ему существовать в офисе комфортно.
-
Когда сотрудник уже устроился, роль Service Discovery выполняет офис-менеджер, если он есть – он тоже отвечает на эти вопросы.
-
Ну и отчасти непосредственный руководитель этого сотрудника помогает его обнаружить его другим “людям”, которым требуются услуги этого сотрудника.

Второй кейс уже ближе к нашей теме.
Допустим, у нас есть нормальное рабочее окружение, которое включает в себя какое-то количество баз 1С и, возможно, других систем.
Базы 1С в этом рабочем окружении периодически дорабатываются и должны тестироваться. Мы все люди грамотные, поэтому доработку мы ведем в специальном окружении разработки. А тестирование мы ведем в специальном окружении для тестирования.
Для этих окружений, разработки и тестирования, нам обязательно потребуются какие-то актуальные данные, чтобы на них проверять корректность реализованных механизмов.
Если мы берем слепок рабочей среды и переносим его в окружение для тестирования, у нас в рабочих базах появляются непонятно откуда взявшиеся артефакты, потому что наши тесты начинают волшебным образом взаимодействовать с рабочим окружением. Чаще всего это касается обменов.
Кроме этого, довольно часто возникает ситуация, когда:
-
разработчик сидит, что-то разрабатывает в своей базе;
-
ему звонит консультант, говорит: «Посмотри, у меня тут с тестом что-то не получается»;
-
тут же звонит клиент, говорит: «У нас все пропало, помоги разобраться, накладная не проводится».
В результате у разработчика открыты три окна с заголовком «Бухгалтерия предприятия», и он не сразу может догадаться, где он поправил накладную, особенно если он под стрессом.

Что сделать в базе, чтобы наше тестовое окружение не взаимодействовало с рабочим:
-
Базе нужно понять, где она находится.
-
Ей нужно получить актуальные настройки для того окружения, в котором она находится.
-
Эти актуальные настройки нужно применить.
-
Далее нужно зафиксировать свое новое местоположение и оповестить об этом заинтересованных лиц.
-
Отдельно есть вопросы к регламентным заданиям, которые, как мы знаем, частично решены в БСП (мы там жмем кнопочку «Это копия»).
Простой вариант автоматической настройки копии базы и его минусы

Для решения этих вопросов в 1С можно реализовать простой вариант. Он до сих пор работает в продуктиве у ряда клиентов – не самый красивый, тем не менее, действенный:
-
Добавляем справочник возможных расположений баз, где в качестве элементов будет: тестовая среда, рабочая среда, среда разработки (с указанием сервера и имени базы).
-
Добавляем константу, где храним текущее расположение базы из вышеуказанного справочника.
-
Добавляем справочник настроек, где будет храниться декларативное описание того, как база должна поменять настройки, если она обнаруживает свое перемещение.
-
Описываем императивные настройки – это произвольные функции, которые выполняются в случае перемещения.
-
Поменять права пользователей – например, раздать всем административные права.
-
Отключить те же самые регламентные задания или наоборот, возможно, включить какие-то регламентные задания.
-
-
И к вопросу на предыдущем слайде – желательно хотя бы поменять заголовок.
-
Связываем элементы справочника расположений с элементами справочника настроек.
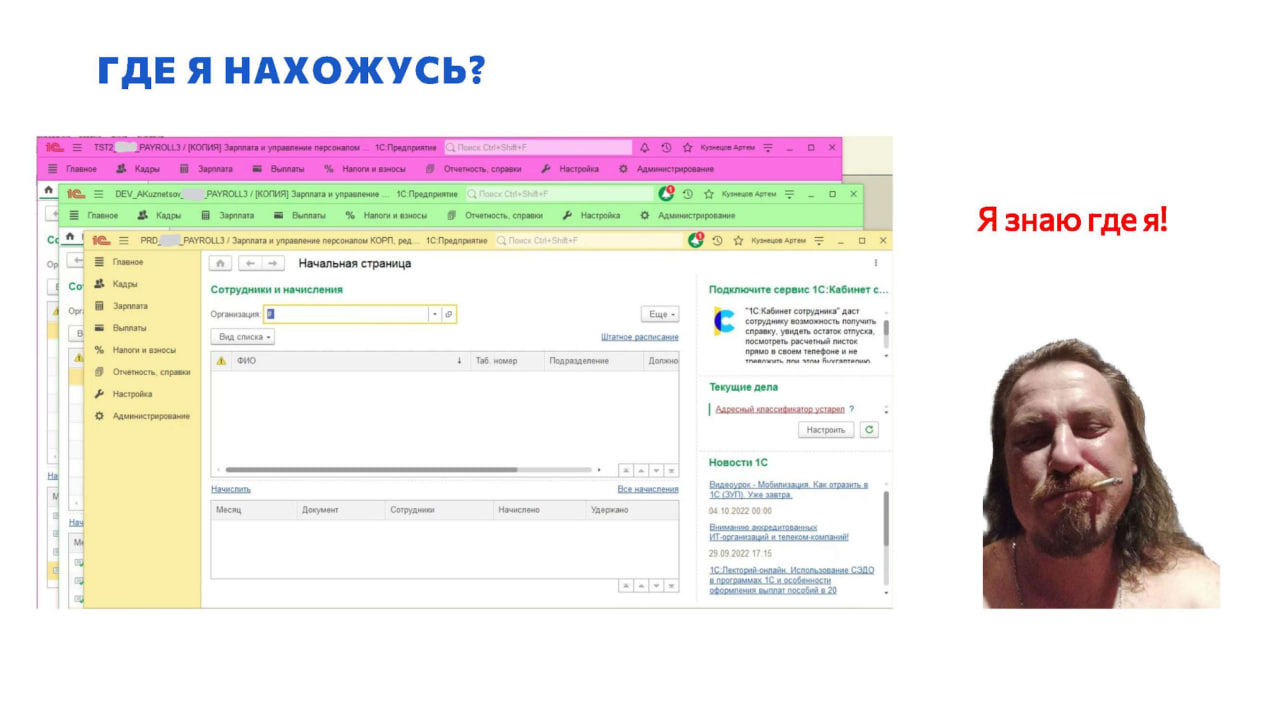
У нас для баз некоторых клиентов это выглядит как на картинке – сразу понятно, где что находится:
-
рабочая база – желтенькая, чтобы пользователей не пугать;
-
зелененькая база – для разработки;
-
фиолетовая – для тестов.
«Я знаю где я!» Красота.
Подытожим, что мы имеем при копировании рабочей базы:
-
она определила, где она находится;
-
применила нужные настройки;
-
поменяла все адреса обменов;
-
отключила регламенты;
-
поменяла цвет.
Все уже стало гораздо лучше.

В чем минусы этого решения:
-
настройки хранятся в рабочей базе;
-
в том числе непосредственно в базе хранятся логины, пароли – это нехорошо;
-
если рабочих баз, которые между собой взаимодействуют, несколько, значит, в каждую из них нужно войти, для всех окружений завести эти настройки;
-
если на продуктиве что-то куда-то переезжает – нужно везде все поменять, ничего не забыть, это целая история.
Паттерн Service Discovery. Где используется и как выглядит

Откуда вообще ноги растут у концепции Service Discovery?
Service Discovery – это не конкретный жестко заданный набор инструментов. Это именно концепция, я бы сказал, что это паттерн.
На мой взгляд, “ноги” у этого паттерна растут прежде всего из мониторинга.
Поскольку объекты мониторинга, даже в небольшой организации, обычно исчисляются сотнями, то каждый объект вбивать вручную, указывая все его параметры, – нереально. Системы мониторинга так или иначе решают такие задачи, например:
-
Для автообнаружения аппаратных объектов есть специальный протокол SNMP.
-
Автообнаружение программных объектов мониторинга можно реализовать через Zabbix. В частности, у меня есть сервис HiRAC, облегчающий мониторинг работы баз 1С – достаточно подключить ее к Zabbix, а дальше Zabbix сам находит:
-
какие базы появились;
-
какие сервера добавились;
-
какие рабочие процессы там поднялись, потухли и прочее.
-
Кроме мониторинга, на текущий момент паттерн Service Discovery чаще всего можно встретить:
-
там, где используется микросервисная архитектура;
-
или там, где звучат всякие страшные слова Docker, Kubernetes и т.д.
Но нам Service Discovery тоже может быть полезно.
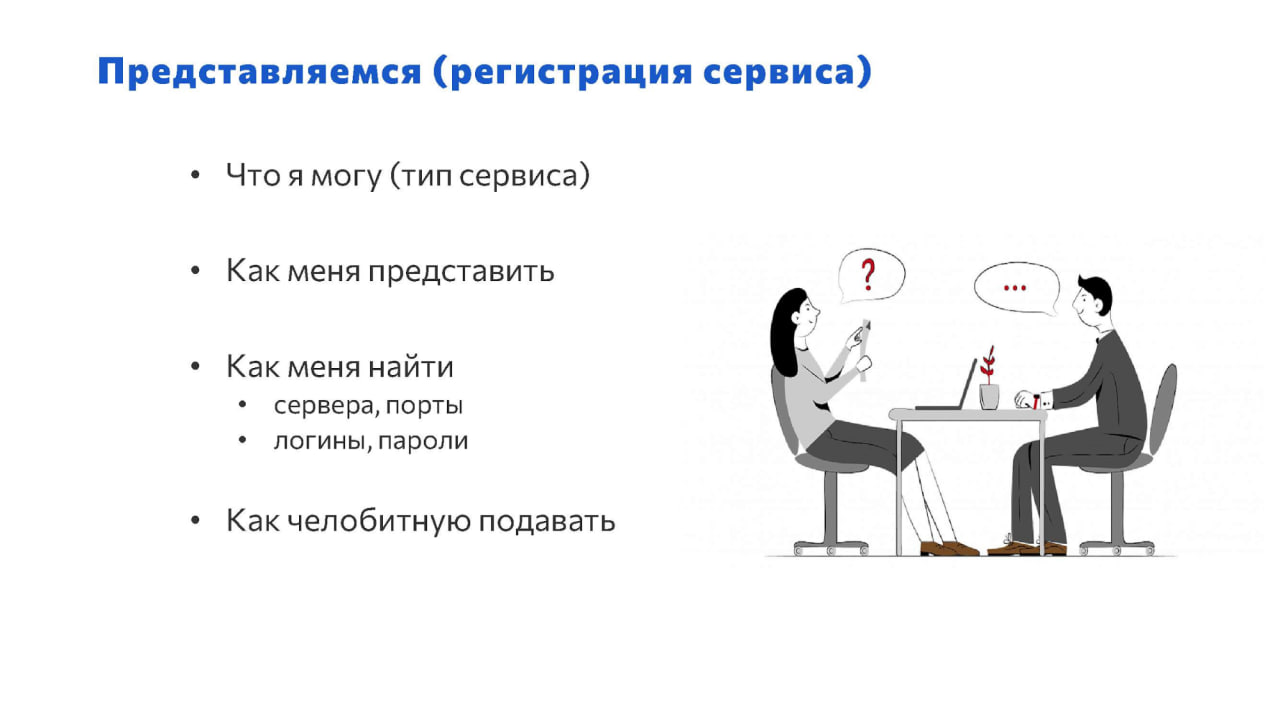
Один из важных этапов жизни сервиса – это его регистрация в службе Service Discovery.
Он должен сказать службе:
-
что он вообще может, что это за сервис;
-
как он называется;
-
как его найти: IP-адрес сервера, логины, пароли;
-
и как с ним общаться: как “челобитную” подавать, как ему задавать вопросы и получать ответы.

Далее сервис говорит службе Service Discovery, что ему для нормального существования нужно общаться с такими-то службами – где их можно найти? Для нашей ситуации этими другими службами могут быть:
-
другие базы 1С – УТ, БП, ДО, ЗУП;
-
внешние службы: различные почтовые сервисы, сервисы обмена сообщениями, файловые хранилища;
-
внешние системы – например, до недавних пор частым был случай, что какая-то иностранная компания работает в России, и там снаружи еще надо общаться с каким-то SAP. Это тоже все сюда.
Окружение Service Discovery. Тонкости реализации
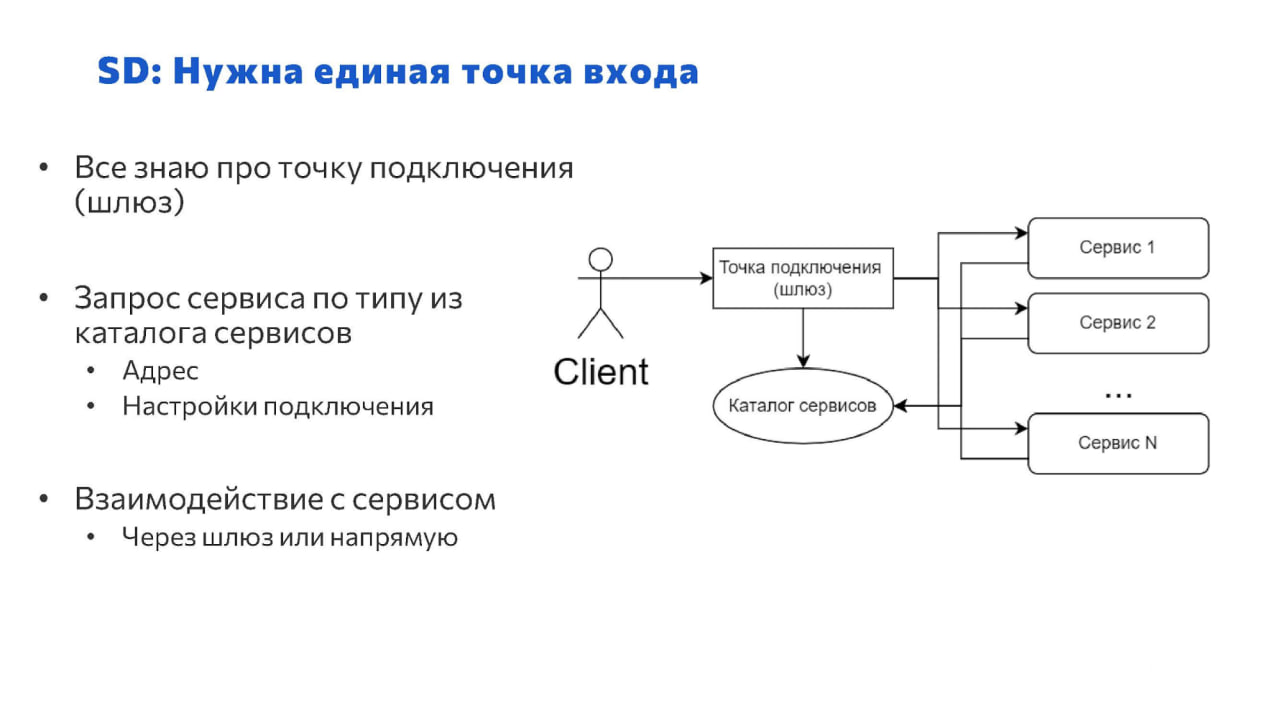
Концепция Service Discovery говорит о том, что:
-
Нужна единая точка обращения – нам не надо для каждого сервиса каким-то особым образом настраивать, где ему взять все необходимые для работы данные. Мы ему даем только один адрес, и он туда стучится. Причем, скорее всего, это будет FQDN-адрес – Fully Qualified Domain Name, полное специфицированное (человекочитаемое) доменное имя.
-
После того, как он туда стучится, его перенаправляют на каталог сервисов – точнее, сама точка подключения обращается к каталогу сервисов.
-
И уже из каталога сервисов извлекается информация о том, куда идти, чтобы общаться с нужным сервисом. Т.е. извлекается информация о подключении к требуемому сервису (адрес, логин, пароль и т.п.).
Это базовый паттерн работы с использованием Service Discovery.

При работе 1С в концепции Service Discovery мне, базе 1С, в первую очередь нужно понять, где я нахожусь:
-
Сходу напрашивается, что это можно узнать по имени сервера и имени базы. Но здесь есть нюанс:
-
Во-первых, начнем с того, что у IP-адресов существует понятие псевдонимов, и их у одного IP-адреса может быть больше одного.
-
И существует гораздо более банальная ситуация, когда мы пошли в базу, запустили ее непосредственно на сервере, где находится 1С, и указали волшебный адрес localhost. После этого все наши попытки понять, где мы, заканчиваются ничем.
-
-
Service Discovery предоставляет еще один способ это узнать – запросить информацию о местоположении непосредственно у “точки взаимодействия”. Ниже я на примере попробую показать, как это сделать.
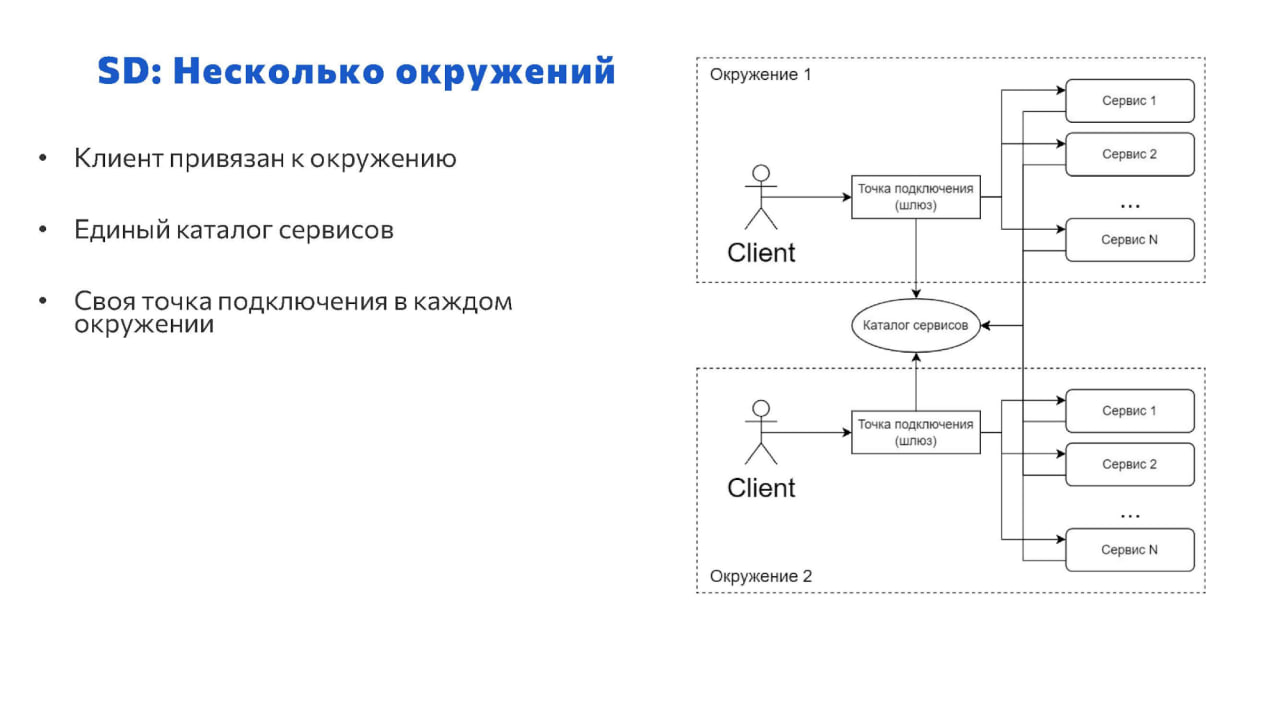
В концепции Service Discovery наш самый первый пример с несколькими окружениями может выглядеть следующим образом:
-
Клиент работает непосредственно внутри того окружения, к сервисам которого он обращается.
-
Точка доступа тоже находится внутри окружения.
-
И она обращается к внешнему общему каталогу сервисов. В этом паттерне каталог сервисов может быть занесен и внутрь окружения, но тогда мы возвращаемся к начальной проблематике, что нам придется одни и те же настройки вводить в два разных места и следить за тем, чтобы они были синхронизированы. Поэтому проще каталог сервисов вынести наружу и внести в него понятие окружений, все настройки разделить по окружениям и далее эти настройки спокойно копировать, править и прочее.
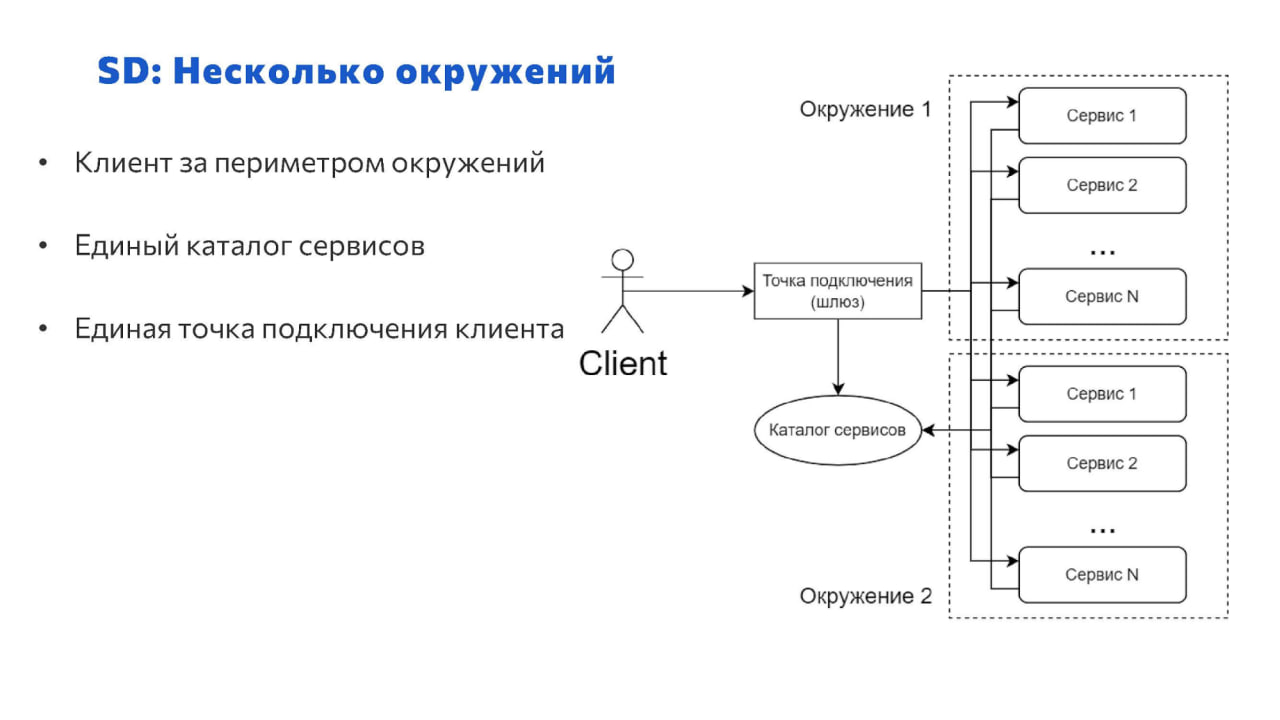
Есть другой вариант – когда точка подключения тоже вынесена наружу.
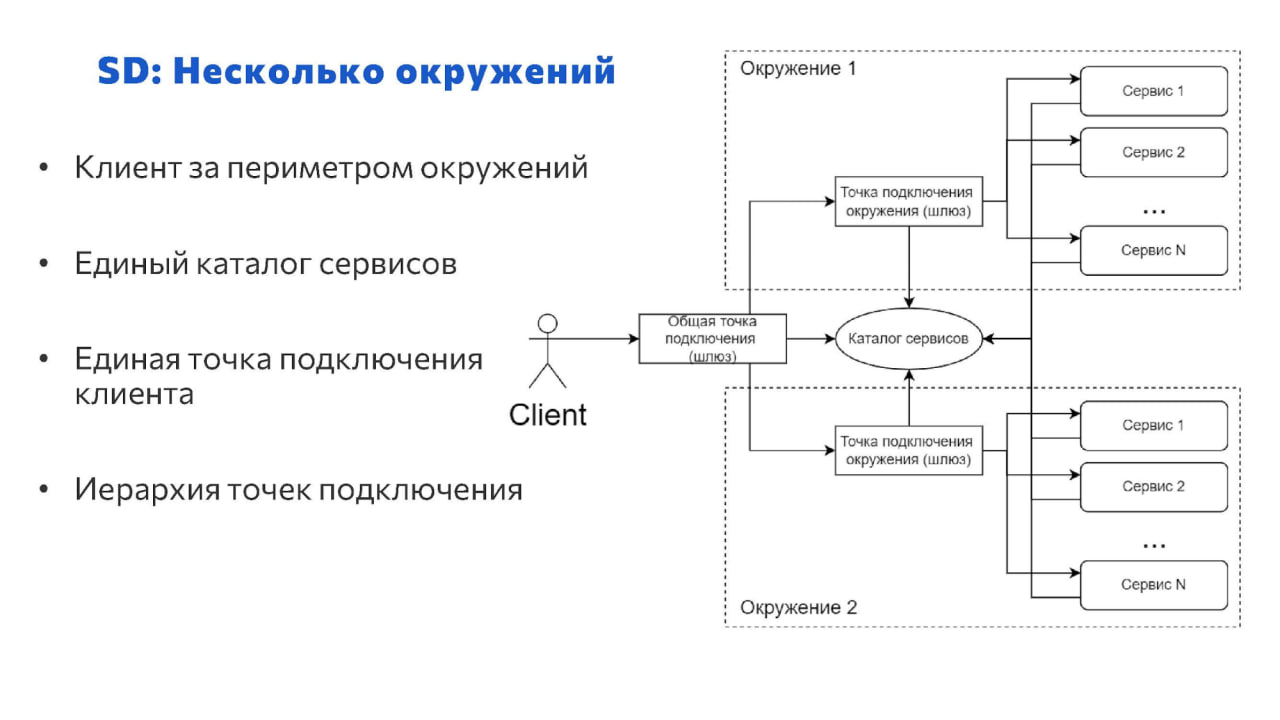
И чуть более сложный вариант – с общей точкой подключения и с иерархией точек подключения. Ниже расскажу, зачем это может быть надо.
Известные инструменты, реализующие паттерн Service Discovery

Про инструменты.
Один из самых известных инструментов Service Discovery – это служба доменных имен DNS (Domain name service).
-
DNS может содержать информацию не только о том, какому IP адресу какое имя соответствует и наоборот, там есть еще и типы записей – так называемые MX и SRV-записи.
-
MX-записи – это указатели на почтовые сервера, очень специфичная штука, сделанная чисто для почты.
-
SRV-записи чуть более универсальны – там реально можно прописать, какой сервис по какому адресу искать и все прочее.
-
-
Для взаимодействия со службой DNS существует старенький простенький, но надежный протокол:
-
В качестве клиента для обращения к DNS используется утилита dig. Она вообще из Linux, но портирована и на Windows тоже.
-
Есть еще стандартный клиент DNS под Windows – называется nslookup, но он работает только с A-записями, т.е. может только сказать, что yandex.ru – это IP-адрес такой-то, или наоборот. Со специфичными записями nslookup не работает, для этого используется dig.
-
И есть библиотеки под разные языки, которые тоже могут работать с DNS.
-
Следующий пример, который может использоваться в качестве точки входа для Service Discovery – это протокол LDAP.
-
Самая известная и широко распространенная реализация протокола LDAP – это Active Directory от Microsoft.
-
Есть еще реализация OpenLDAP, которая используется под Linux.
LDAP может использоваться в качестве точки входа для Service Discovery, потому что подразумевает наличие иерархии объектов. Причем в LDAP каждый объект может содержать произвольное количество специфицированных полей – что-то определено стандартом, а что-то мы можем добавлять на свое усмотрение. В этих полях мы можем хранить всю ту информацию, которая нужна нашему сервису при обращении: адреса, типы сервисов, явки, пароли и прочее.
Следующий популярный инструмент от компании HashiCorp называется Consul. Это легковесная утилита – exe-шник, написанный на Go. Основной его паттерн применения: он разворачивается в качестве службы на всех машинах, где нам нужно отслеживать сервисы. И здесь мы автоматически получаем ту самую точку входа, показанную на картинках, потому что остальные сервисы просто обращаются на свою машину по определенному порту адреса localhost, а Consul им возвращает о них всю необходимую информацию.
Это достаточно легко решает ту самую проблему определения местоположения, потому что Consul знает, что где он находится. Когда мы его конфигурируем, мы его параметры прописываем в настройках, и он легко на этот вопрос отвечает.
А за счет того, что Consul распространяется по нескольким машинам, мы автоматически имеем отказоустойчивый кластер – подробнее об этом расскажу чуть позже.
У Consul два основных API:
-
Стандартный REST API – когда мы пуляемся туда-сюда JSON-чиками, запрос-ответ.
-
И также он может общаться по протоколу DNS – мы можем к нему обратиться через стандартную утилиту dig, спросить: «Где мой 1С:Документооборот?». Он скажет: «1С:Документооборот по адресу 192.168.0.85».
Дополнительно у той же компании Hashicorp существует инструмент Vault, который предназначен для хранения секретных данных: логины, пароли, ключи шифрования, закрытые ключи и прочее. В результате связка Consul и Vault полностью покрывает вопрос хранения всех возможных настроек, в том числе и секретных.
Ну и раз мы 1С-ники, мы можем напилить для использования паттерна Service Discovery свою волшебную вещь непосредственно на языке 1С. Правда, Consul мне попался раньше, и у меня готовое решение на 1С пока не взлетело, но кто хочет попробовать – дерзайте.
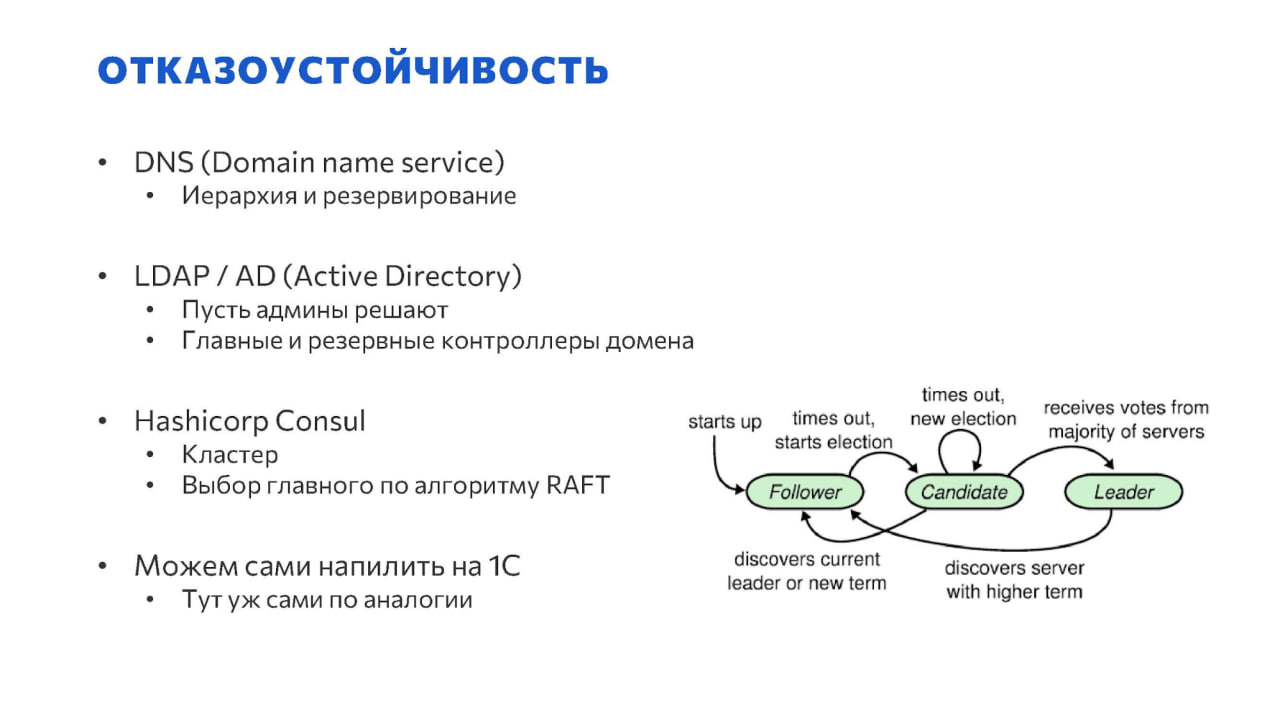
Теперь про отказоустойчивость. Когда мы внедряем паттерн Service Discovery, все должны стучаться по одному адресу – т.е. по сути мы получаем единую точку отказа. Разные системы это решают по-разному.
-
С DNS все в курсе – даже корневые сервера как-то отключали, интернет вроде не пропал. Там с отказоустойчивостью всё достаточно хорошо продумано и опробовано.
-
Active Directory находится во власти ваших системных администраторов – как они развернут, так оно и полетит. Сама Active Directory подразумевает наличие как минимум резервных контроллеров домена, что в принципе вопрос отказоустойчивости как-то решает.
-
HashiCorp Consul вопрос отказоустойчивости решает за счет кластеризации. Плюс надо упомянуть, что у него существует волшебный алгоритм RAFT для выбора ведущего узла. С помощью алгоритма RAFT выбирается конкретная машина, обладающая на текущий момент полной и достоверной информацией, которую она предоставляет сервису.
-
А под 1С сами разберетесь – возьмете RAFT, реализуете, все будет работать прекрасно.
Авторазвертывание копий баз с помощью применения паттерна Service Discovery

Чуть более сложный и интересный кейс – авторазвертывание.
Мы уже упоминали о том, что у нас в тестовой среде каким-то образом появляются базы – новые, свежие, из продуктива. Обычно они появляются вручную – мы звоним системному администратору, говорим: «Коля, сделай бэкап». Коля через два дня звонит: «Бэкап готов». Мы ставим на развертывание, идем заниматься задачами, и через три дня у нас появляется база.
Автоматизация этого процесса реально экономит очень много времени. Я работаю в поддержке, у меня в окружении где-то 150 баз – рабочих, не тестовых. Мне авторазвертывание экономит очень много времени.
Соответственно, что делаем?
-
Разработчик, как клиент сервиса, через единую точку входа в Jira отправляет запрос: «Сделайте мне копию базы или всего окружения»
-
Jira обращается в каталог сервисов, спрашивает у него: «Есть у тебя такая база?» Каталог сервисов ему отвечает: «Да, есть такая Бухгалтерия, пожалуйста»
-
После чего Jira дёргает Jenkins, говорит: «Васе нужна вон та база вон там», и Jenkins запускает пайплайн для авторазвертывания. Этот пайплайн у нас основан на утилите cpdb, которая умеет работать с SQL-ными базами – создавать/восстанавливать резервные копии на указанных машинах и прочее.
-
После выполнения задач на Jenkins у Васи волшебным образом появляется его база, причём со всеми правильными настройками для окружения разработки.
-
А Васе в Telegram приходит отбивка, что всё готово.
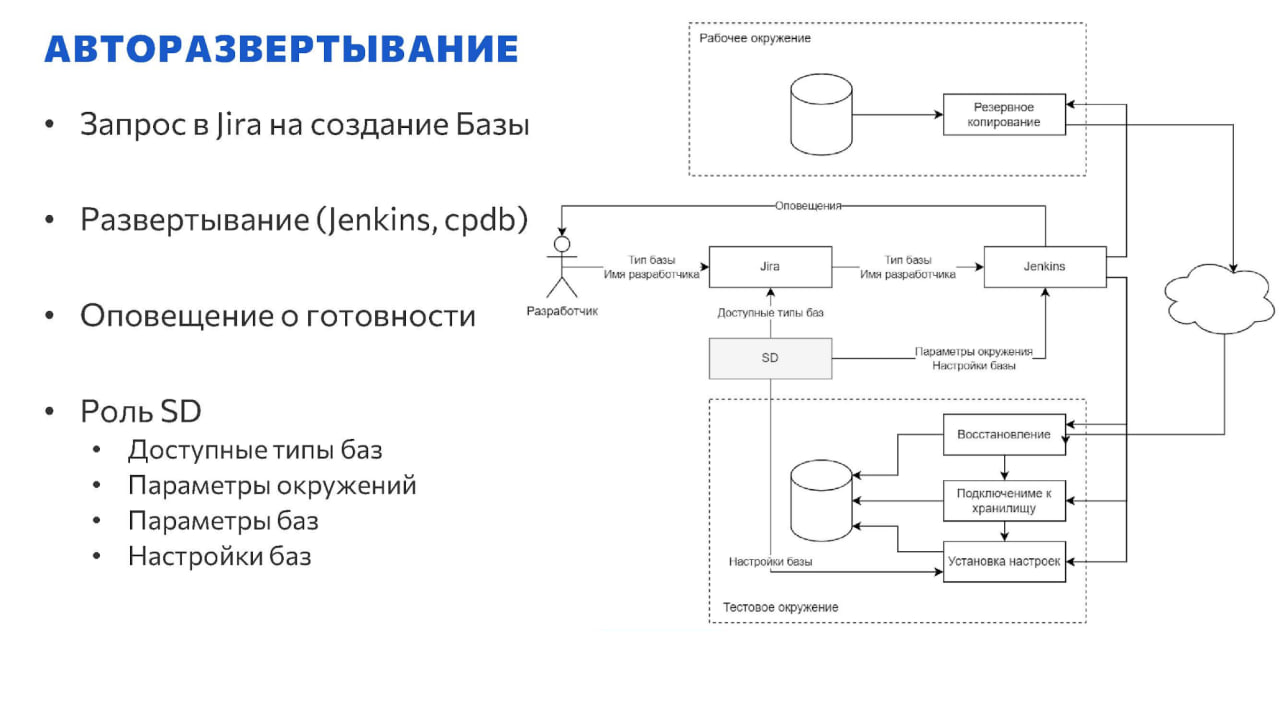
На слайде показано, как это выглядит.
-
Отправляется запрос в Jira на создание базы,
-
Jira “дёргает” Jenkins – происходит бэкап, передача на целевую среду и развертывание на целевой базе.
-
Далее база переподключается к хранилищу разработки, запускается и настраивается в соответствии с текущим окружением.
-
В фоне выполняется компрессия страниц для экономии места.
-
И в конце пользователь получает оповещение о том, что всё благополучно выполнено.
Какую роль в данном случае выполняет служба Service Discovery? Она предоставляет:
-
список доступных баз для этих действий – по сути, список рабочих баз и их окружений;
-
предоставляет информацию о параметрах окружений и параметрах баз;
-
и те настройки, которые можно применить после развертывания базы.
Не пренебрегайте стандартизацией

Важный момент. Настоятельно рекомендую не называть базы «Тест1», «Тест1_new», «Тест (прошлый год)» и прочее. Разработайте какую-то номенклатуру наименований – как минимум для серверов и для баз.
Желательно, чтобы наименования были машиночитаемыми, чтобы в случае чего мы могли автоматически что-то обработать, что-то заскриптовать связанное с этими серверами или с этими базами.
Примеры названия серверов:
-
«Ru-mos-1c-db1» – вроде все понятно: Россия, Москва, 1С-окружение, сервер баз данных;
-
«Ru-mos-1c-app1» – то же самое, но сервер приложений.
Или пример названия базы 1С: «DEV_AKuznetsov_THEIRCOMPANY_TRADE» – база разработки пользователя А.Кузнецов, клиент THEIRCOMPANY, и база явно УТ-шка, для торговых операций.
Такая стандартизация очень помогает. И разработчик, когда открывает список баз с такими названиями, легко и спокойно их читает.
Выгоды Service Discovery

Мы подошли практически к завершению. Если коротко подытожить:
-
Если у нас есть какие-то настройки, которые завязаны на окружение или могут меняться, поскольку связаны с появлением или исчезновением или заменой служб, используемых в нашей информационной системе, гораздо дешевле их хранить, редактировать централизованно.
-
Чем больше таких сервисов у нас используется, тем выгоднее использование паттерна Service Discovery.
-
То, о чем мы говорили, можно назвать принципом «единого окна» – любая система, возникающая у нас в периметре, может обратиться по известному адресу и взять те настройки, которые необходимы для ее работы.
Вопросы
Как в последнем кейсе решается вопрос автоматического контроля легитимности, что этому пользователю действительно можно дать базу и именно туда ее переместить?
По сути, мы используем ручной режим. Точкой входа является Jira, поэтому заявка в Jira обязательно требует подтверждения старшего товарища. В нашем случае этого достаточно.
Если любому разработчику или аналитику можно автоматически разворачивать базы, возникает соблазн развернуть себе все на всякий случай. В итоге дисковое пространство заканчивается. Чем ограничивается бездонность зоны, куда мы это помещаем?
Мы этот вопрос решаем временем жизни копий. Регламентно устанавливается время жизни копии и потом просто автоматом удаляется.
А если места нет, но сейчас все копии нужны, и просят развернуть еще – тогда у вас получается все-таки ручное определение, что важнее?
Понятно, что человеческий фактор остается всегда, и ручное управление всегда можно подключить. Но лучше, конечно, чтобы место не заканчивалось.
При первом подходе к снаряду мы просто определяем, что на этой среде, в этом окружении, любая копия баз живет неделю. Дальше там можно сделать отбивку тому, кто заказывал, что через три часа база будет удалена.
Возможно, организовать какой-то дополнительный контур защиты, чтобы он мог успеть написать письмо: «Не убивайте», и ему продлили срок хранения еще на неделю.
А если место начинает заканчиваться, уже идет эскалация на соответствующие службы.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.
|
30 мая - 1 июня 2024 года состоится конференция Анализ & Управление в ИТ-проектах, на которой прозвучит 130+ докладов.
Темы конференции:
Конференция для аналитиков и руководителей проектов, а также других специалистов из мира 1С, которые занимаются системным и бизнес-анализом, работают с требованиями, управляют проектами и продуктами!
|