Недавно встал вопрос, как быстро удалить строки из ТЗ в случае, когда невозможно применить выгрузку с отбором по структуре.
Изначально мы рассматривали только два варианта реализации, но я решил рассмотреть все варианты, какие только могли прийти в голову. Результаты в конце, код обработки отдельно под спойлером.
Описание вариантов:
1. Через запрос. Обрабатываемую ТЗ передаём через параметр в запрос, где применяем нужные отборы, и выгружаем результат запроса в ТЗ.
Реализация варианта с запросом
Забегу вперёд. Для упрощения в таблице заранее добавлено поле Удалить с типом Булево.
Также я намеренно не стал в запросе описывать поля таблицы т.к. посчитал что программист, вероятнее всего, поленится это сделать.
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| ТЗ.*
|ПОМЕСТИТЬ ТЗ
|ИЗ
| &ТЗ КАК ТЗ
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| ТЗ.*
|ИЗ
| ТЗ КАК ТЗ
|ГДЕ
| НЕ ТЗ.Удалить"; //Здесь должно быть более сложное условие типа: ТЗ.Сумма <> 0
Запрос.УстановитьПараметр("ТЗ", ТЗ);
НоваяТЗ = Запрос.Выполнить().Выгрузить();
2. Удаление строк. Создаём массив. В цикле обходим ТЗ, проверяя для каждой строки условие, и помещаем строки на удаление в массив. Далее обходим массив строк на удаление и вызываем ТЗ.Удалить(), передавая в него строку из массива
Реализация варианта с удалением строк
СтрокиДляУдаления = Новый Массив;
Для Каждого Строка Из ТЗ Цикл
Если Строка.Удалить Тогда // Здесь должно быть сложное условие типа: Строка.Сумма = 0 И Строка.Контрагент = КонтрагентВася
СтрокиДляУдаления.Добавить(Строка);
КонецЕсли;
КонецЦикла;
Для Каждого Строка Из СтрокиДляУдаления Цикл
ТЗ.Удалить(Строка);
КонецЦикла;
3. Копирование таблицы. Вариант похож на предыдущий. В начале создаём массив, обходим ТЗ и закидываем в массив подходящие строки. Далее выгружаем нужные строки через метод ТЗ.Скопировать(), передав в него массив нужных строк
Реализация варианта с копированием таблицы
ПодходящиеСтроки = Новый Массив;
Для Каждого Строка Из ТЗ Цикл
Если Не Строка.Удалить Тогда // Здесь должно быть сложное условие типа: Строка.Сумма = 0 И Строка.Контрагент = КонтрагентВася
ПодходящиеСтроки.Добавить(Строка);
КонецЕсли;
КонецЦикла;
НоваяТЗ = ТЗ.Скопировать(ПодходящиеСтроки);
4. Копирование строк. Мы создаём пустую копию исходной таблицы. Далее обходим в цикле все строки, выполняем проверку и добавляем в пустую копию подходящие строки.
Реализация варианта с копированием строк
В этом варианте я намеренно использовал метод ЗаполнитьЗначенияСвойств(), понимая, что он отработает чуть дольше чем заполнение каждой колонки, так как считаю, что программист вероятнее использует его.
НоваяТЗ = ТЗ.СкопироватьКолонки();
СтрокиДляУдаления = Новый Массив;
Для Каждого Строка Из ТЗ Цикл
Если Не Строка.Удалить Тогда // Здесь должно быть сложное условие типа: Строка.Сумма = 0 И Строка.Контрагент = КонтрагентВася
новСтрока = НоваяТЗ.Добавить();
ЗаполнитьЗначенияСвойств(новСтрока, Строка);
КонецЕсли;
КонецЦикла;
5. Предобработка и выгрузка с отбором. Добавляем в ТЗ колонку с типом булево для хранения результата проверки всех условий. Обходим строки в цикле и заполняем её. Делаем выгрузку с отбором по структуре, после чего удаляем новую колонку.
Реализация варианта с предобработкой и выгрузкой
ТЗ.Колонки.Добавить("ЭтоСтрокаКУдалению", Новый ОписаниеТипов("Булево"));
Для Каждого Строка Из ТЗ Цикл
// Здесь должно быть сложное условие типа:
// Строка.ЭтоСтрокаКУдалению = (Строка.Сумма <> 0 И (Строка.Контрагент = КонтрагентВася Или Строка.Контрагент = КонтрагентПетя));
Строка.ЭтоСтрокаКУдалению = Строка.Удалить;
КонецЦикла;
НоваяТЗ = ТЗ.Скопировать(Новый Структура("ЭтоСтрокаКУдалению", Ложь));
ТЗ.Колонки.Удалить("ЭтоСтрокаКУдалению");
НоваяТЗ.Колонки.Удалить("ЭтоСтрокаКУдалению");
6. Выгрузка с отбором. Этот способ не совсем корректно здесь рассматривать, т.к. он подходит лишь в том случае, если в качестве условия отбора строк используется поиск по конкретному значению.
Реализация варианта с выгрузкой строк
НоваяТЗ = ТЗ.Скопировать(Новый Структура("Удалить", Ложь));
Способ замера производительности
Замеры выполнял на платформе 8.3.23.1865, SQL 2019.
Замерять я решил на разных объёмах данных (разное количество строк и колонок), с разным процентом удаляемых строк. Причем удаляемые строки я распределил равномерно по всей таблице.
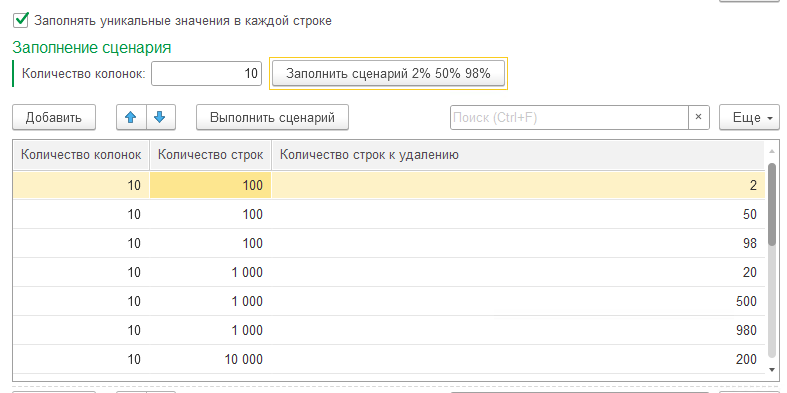
Для удобства я добавил таблицу со сценарием замеров, в которой перед запуском прописывал варианты количества строк, колонок и количество удаляемых строк. Для быстрого заполнения нужных мне сценариев добавил кнопку.
Количество строк брал от 100 до 1000000
Количество удаляемых строк брал в размере 2%, 50% и 98% от общего количества строк в таблице
При обработке каждой строки таблицы сценария я создавал новую таблицу с уникальными значениями в каждой ячейке и вызывал метод, соответствующий виду теста, передавая в него копию таблицы. Каждый замер я выполнял 5 раз, после чего выкидывал один самый быстрый результат, один самый долгий результат и брал среднее из оставшихся трёх.
Результаты замеров заносил в таблицу.
//////////////////////////////////////////////////////////////////////////////
// Выполнение сценария
&НаСервере
Процедура ВыполнитьСценарийНаСервере()
КоличествоПрогонов = 5;
РезультатЗамеров.Очистить();
Для каждого цВариант Из Сценарий Цикл
ТЗ = СформироватьТестовуюТЗ(цВариант.КоличествоКолонок, цВариант.КоличествоСтрок, цВариант.КоличествоСтрокКУдалению);
Для каждого КиЗ Из СоответствиеТестовИМетодов() Цикл
ВидТеста = КиЗ.Ключ;
ИмяМетода = КиЗ.Значение;
ТабРезультатов = Новый ТаблицаЗначений;
ТабРезультатов.Колонки.Добавить("Результат", Новый ОписаниеТипов("Число"));
Для й = 1 По КоличествоПрогонов Цикл
ТЗДляТеста = ТЗ.Скопировать();
текРезультат = 0;
Выполнить("текРезультат = " + ИмяМетода + "(ТЗДляТеста);");
ТабРезультатов.Добавить().Результат = текРезультат;
КонецЦикла;
ТабРезультатов.Сортировать("Результат");
Если ТабРезультатов.Количество() > 1 Тогда
// Удаляем самый быстрый результат
ТабРезультатов.Удалить(ТабРезультатов[0]);
КонецЕсли;
Если ТабРезультатов.Количество() > 1 Тогда
// Удаляем самый долгий результат
ТабРезультатов.Удалить(ТабРезультатов[ТабРезультатов.Количество()-1]);
КонецЕсли;
Итого = ТабРезультатов.Итог("Результат");
Результат = Итого / ТабРезультатов.Количество();
Результат = Макс(1, Результат); // меньше 1 мс не должно быть т.к. это глюк сервера
новСтрока = РезультатЗамеров.Добавить();
новСтрока.ВидТеста = ВидТеста;
новСтрока.Время = Результат;
новСтрока.КоличествоКолонок = цВариант.КоличествоКолонок;
новСтрока.КоличествоСтрок = цВариант.КоличествоСтрок;
новСтрока.КоличествоСтрокКУдалению = цВариант.КоличествоСтрокКУдалению;
новСтрока.УникальныеЗначения = ЗаполнятьУникальныеЗначенияВКаждойСтроке;
КонецЦикла;
КонецЦикла;
КонецПроцедуры
&НаСервере
Функция СоответствиеТестовИМетодов()
ИменаТестов = Новый Соответствие;
ИменаТестов.Вставить("Запрос", "Тест_Запрос");
ИменаТестов.Вставить("УдалениеСтрок", "Тест_УдалениеСтрок");
ИменаТестов.Вставить("КопированиеТЗ", "Тест_КопированиеТЗ");
ИменаТестов.Вставить("КопированиеСтрок", "Тест_КопированиеСтрок");
ИменаТестов.Вставить("ПредобработкаИВыгрузкаТЗСОтбором", "Тест_ПредобработкаИВыгрузкаТЗСОтбором");
ИменаТестов.Вставить("ВыгрузкаТЗСОтбором", "Тест_ВыгрузкаТЗСОтбором");
Возврат ИменаТестов;
КонецФункции
//////////////////////////////////////////////////////////////////////////////
// Формирование тестовой таблицы
&НаСервере
Функция СформироватьТестовуюТЗ(КоличествоКолонок, КоличествоСтрок, КоличествоСтрокКУдалению)
ТЗ = Новый ТаблицаЗначений;
ТЗ.Колонки.Добавить("Удалить", Новый ОписаниеТипов("Булево"));
Для й = 1 По КоличествоКолонок Цикл
ТЗ.Колонки.Добавить("Колонка" + й, Новый ОписаниеТипов("Строка"));
КонецЦикла;
Для ц = 1 По КоличествоСтрок Цикл
новСтрока = ТЗ.Добавить();
КонецЦикла;
Если ЗаполнятьУникальныеЗначенияВКаждойСтроке Тогда
Для Каждого цСтрока Из ТЗ Цикл
Для й = 1 По КоличествоКолонок Цикл
цСтрока["Колонка" + й] = Строка(Новый УникальныйИдентификатор());
КонецЦикла;
КонецЦикла;
Иначе
Для й = 1 По КоличествоКолонок Цикл
ТЗ.ЗаполнитьЗначения(Строка(Новый УникальныйИдентификатор()), "Колонка" + й);
КонецЦикла;
КонецЕсли;
ВыбратьСтрокиКУдалению(ТЗ, КоличествоСтрокКУдалению);
Возврат ТЗ;
КонецФункции
&НаСервере
Процедура ВыбратьСтрокиКУдалению(ТЗ, КоличествоСтрокКУдалению)
ИнтевалУдаления = Окр(ТЗ.Количество() / КоличествоСтрокКУдалению);
ТребуетсяСтрокУдалить = КоличествоСтрокКУдалению;
текИндекс = 0;
Пока ТребуетсяСтрокУдалить > 0 И текИндекс <= ТЗ.Количество()-1 Цикл
ТЗ[текИндекс].Удалить = Истина;
ТребуетсяСтрокУдалить = ТребуетсяСтрокУдалить - 1;
текИндекс = текИндекс + ИнтевалУдаления;
КонецЦикла;
текИндекс = 0;
Пока ТребуетсяСтрокУдалить > 0 И текИндекс <= ТЗ.Количество()-1 Цикл
Если Не ТЗ[текИндекс].Удалить Тогда
ТЗ[текИндекс].Удалить = Истина;
ТребуетсяСтрокУдалить = ТребуетсяСтрокУдалить - 1;
КонецЕсли;
текИндекс = текИндекс + 1;
КонецЦикла;
КонецПроцедуры
//////////////////////////////////////////////////////////////////////////////
// Сами тесты
&НаСервере
Функция Тест_Запрос(ТЗ)
ВремяСтарта = ТекущаяУниверсальнаяДатаВМиллисекундах();
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| ТЗ.*
|ПОМЕСТИТЬ ТЗ
|ИЗ
| &ТЗ КАК ТЗ
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| ТЗ.*
|ИЗ
| ТЗ КАК ТЗ
|ГДЕ
| ТЗ.Удалить = Ложь";
Запрос.УстановитьПараметр("ТЗ", ТЗ);
НоваяТЗ = Запрос.Выполнить().Выгрузить();
ВремяФиниша = ТекущаяУниверсальнаяДатаВМиллисекундах();
Возврат ВремяФиниша - ВремяСтарта;
КонецФункции
&НаСервере
Функция Тест_УдалениеСтрок(ТЗ)
ВремяСтарта = ТекущаяУниверсальнаяДатаВМиллисекундах();
СтрокиДляУдаления = Новый Массив;
Для Каждого Строка Из ТЗ Цикл
Если Строка.Удалить Тогда
СтрокиДляУдаления.Добавить(Строка);
КонецЕсли;
КонецЦикла;
Для Каждого Строка Из СтрокиДляУдаления Цикл
ТЗ.Удалить(Строка);
КонецЦикла;
ВремяФиниша = ТекущаяУниверсальнаяДатаВМиллисекундах();
Возврат ВремяФиниша - ВремяСтарта;
КонецФункции
&НаСервере
Функция Тест_КопированиеТЗ(ТЗ)
ВремяСтарта = ТекущаяУниверсальнаяДатаВМиллисекундах();
ПодходящиеСтроки = Новый Массив;
Для Каждого Строка Из ТЗ Цикл
Если Не Строка.Удалить Тогда
ПодходящиеСтроки.Добавить(Строка);
КонецЕсли;
КонецЦикла;
НоваяТЗ = ТЗ.Скопировать(ПодходящиеСтроки);
ВремяФиниша = ТекущаяУниверсальнаяДатаВМиллисекундах();
Возврат ВремяФиниша - ВремяСтарта;
КонецФункции
&НаСервере
Функция Тест_КопированиеСтрок(ТЗ)
ВремяСтарта = ТекущаяУниверсальнаяДатаВМиллисекундах();
НоваяТЗ = ТЗ.СкопироватьКолонки();
СтрокиДляУдаления = Новый Массив;
Для Каждого Строка Из ТЗ Цикл
Если Не Строка.Удалить Тогда
новСтрока = НоваяТЗ.Добавить();
ЗаполнитьЗначенияСвойств(новСтрока, Строка);
КонецЕсли;
КонецЦикла;
ВремяФиниша = ТекущаяУниверсальнаяДатаВМиллисекундах();
Возврат ВремяФиниша - ВремяСтарта;
КонецФункции
&НаСервере
Функция Тест_ПредобработкаИВыгрузкаТЗСОтбором(ТЗ)
ВремяСтарта = ТекущаяУниверсальнаяДатаВМиллисекундах();
ТЗ.Колонки.Добавить("ЭтоСтрокаКУдалению", Новый ОписаниеТипов("Булево"));
Для Каждого Строка Из ТЗ Цикл
// Здесь должно быть сложное условие типа:
// Строка.ЭтоСтрокаКУдалению = (Строка.Сумма <> 0 И (Строка.Контрагент = КонтрагентВася Или Строка.Контрагент = КонтрагентПетя));
Строка.ЭтоСтрокаКУдалению = Строка.Удалить;
КонецЦикла;
НоваяТЗ = ТЗ.Скопировать(Новый Структура("ЭтоСтрокаКУдалению", Ложь));
ТЗ.Колонки.Удалить("ЭтоСтрокаКУдалению");
НоваяТЗ.Колонки.Удалить("ЭтоСтрокаКУдалению");
ВремяФиниша = ТекущаяУниверсальнаяДатаВМиллисекундах();
Возврат ВремяФиниша - ВремяСтарта;
КонецФункции
&НаСервере
Функция Тест_ВыгрузкаТЗСОтбором(ТЗ)
Результаты замеров
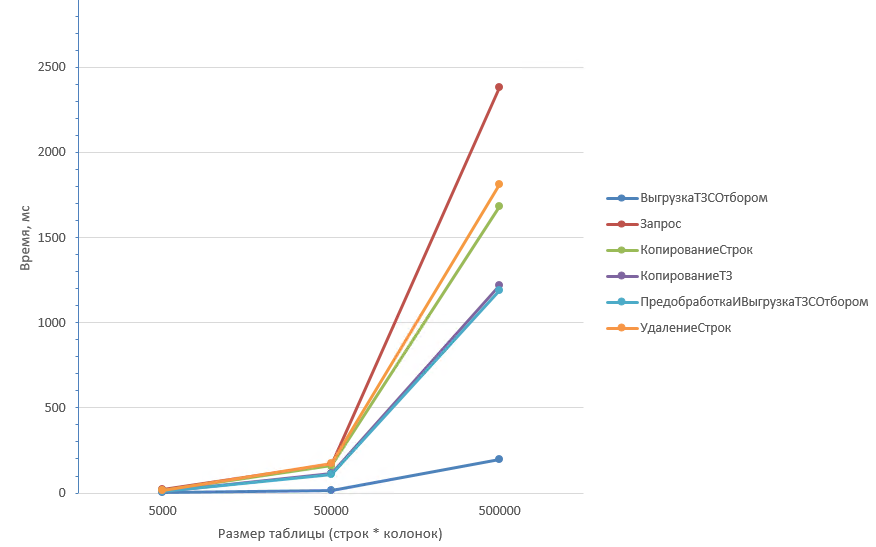
Ниже приведены результаты для таблиц с уникальными значениями в каждой ячейке. Тестировал для таблиц с 5 колонками и с 50 колонками с разным количеством строк и процентом удаления.
Для начала сравним время выполнения при 2% удаляемых строк.
Таблица из 5 колонок:
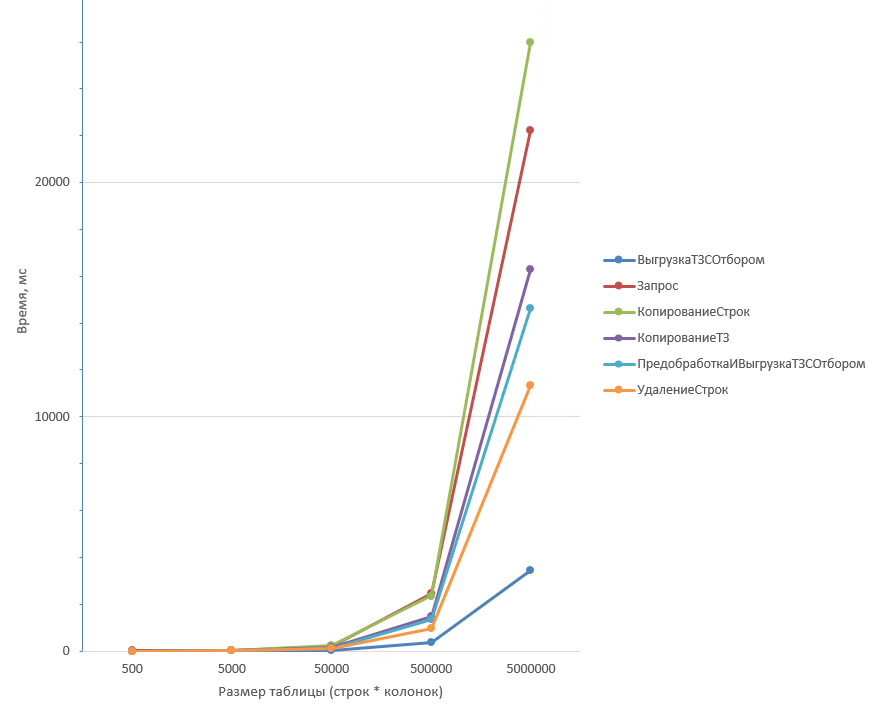
Таблица из 5 колонок более детально первые три значения:
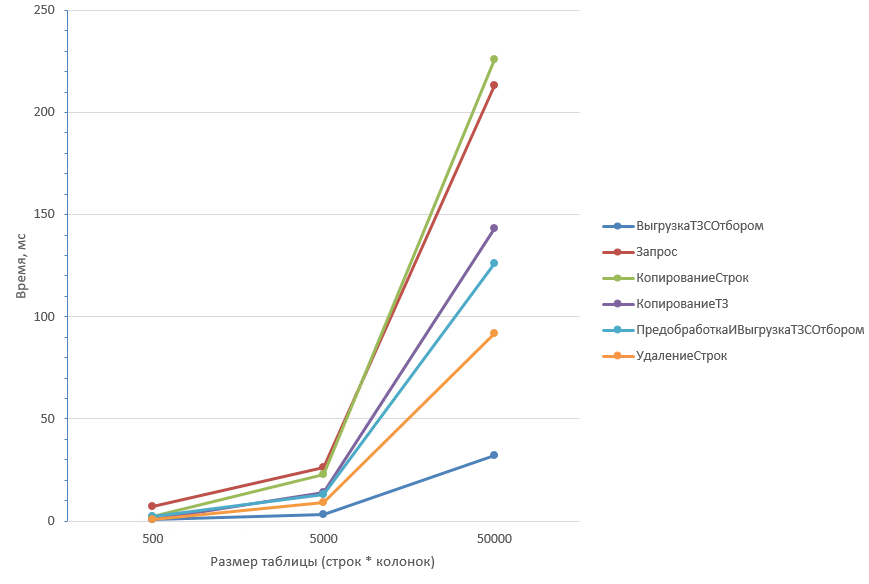
Таблица из 50 колонок:
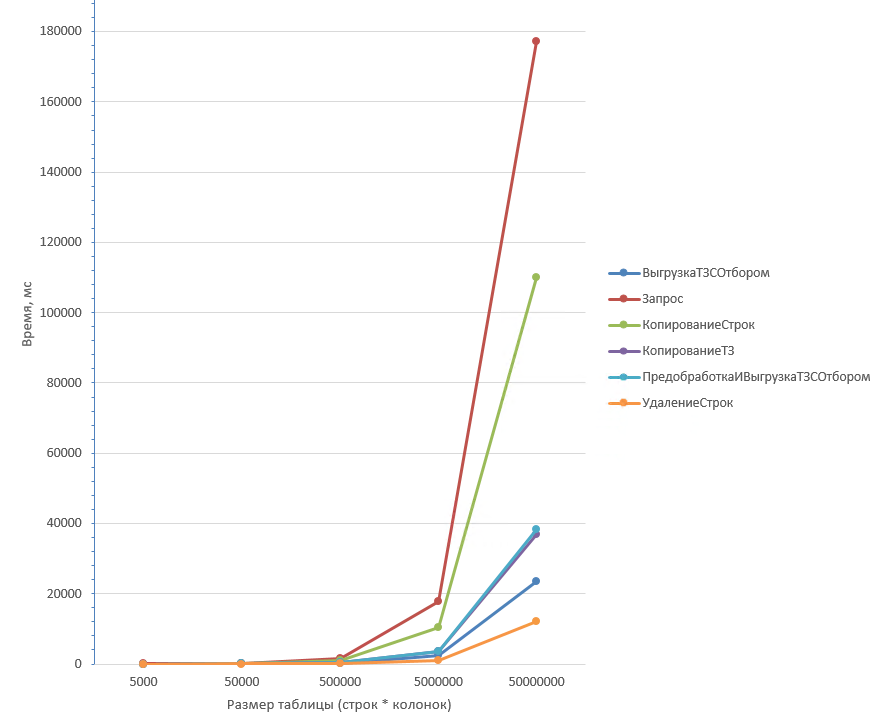
Таблица из 50 колонок более детально первые три значения:
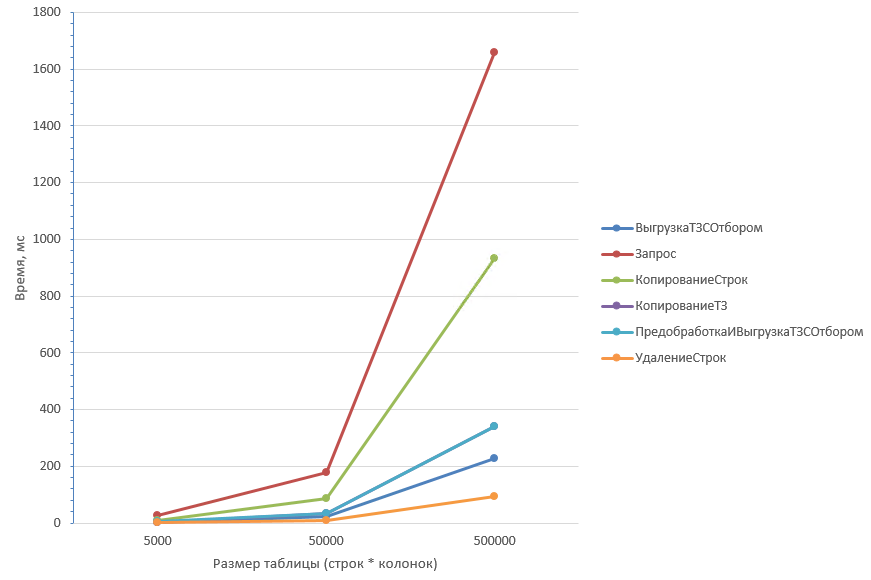
Из графика видно, что дольше всех отрабатывают два способа: Запрос (1) и копирование строк (4). На небольших объёмах данных отличие незначительно, но на таблицах 1 млн строк Запрос (1) отрабатывает чуть быстрее.
Однако, при увеличении количества колонок результаты меняются: Запрос (1) начинает существенно проигрывать копированию строк (4).
В обоих случаях способ с удалением строк (2) оказывается самым быстрым. А при большом количестве колонок он даже опережает выгрузку с отбором (6).
Вывод: Если ожидается малый процент удаления строк, то самым оптимальным будет способ Удаление строк (2). Причем на любом объёме данных и при любом количестве колонок.
Удаление 50% строк
Таблица из 5 колонок:
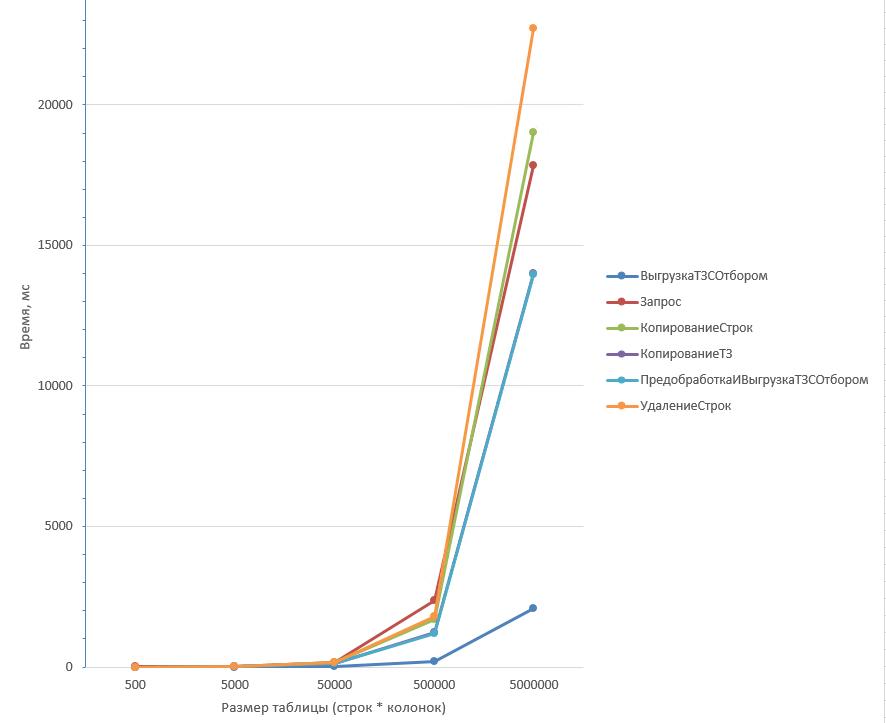
Таблица из 5 колонок более детально первые три значения:
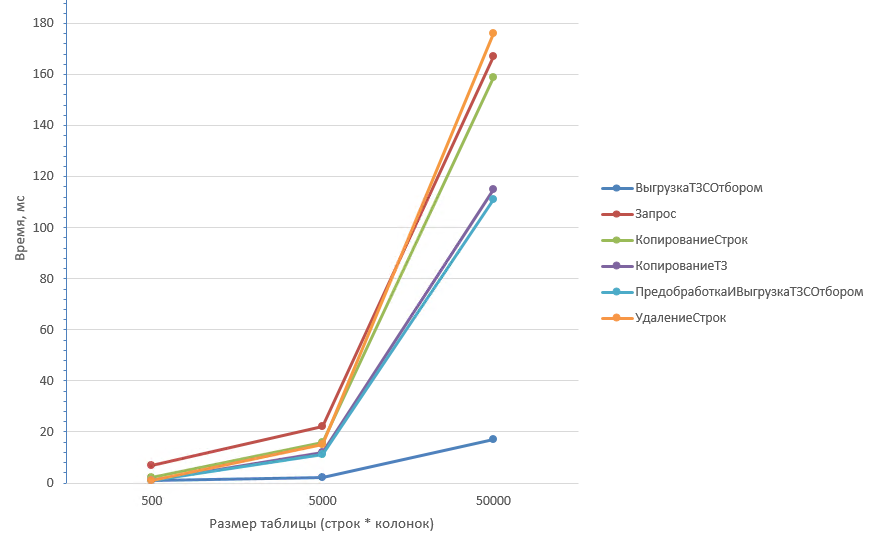
Таблица из 50 колонок:
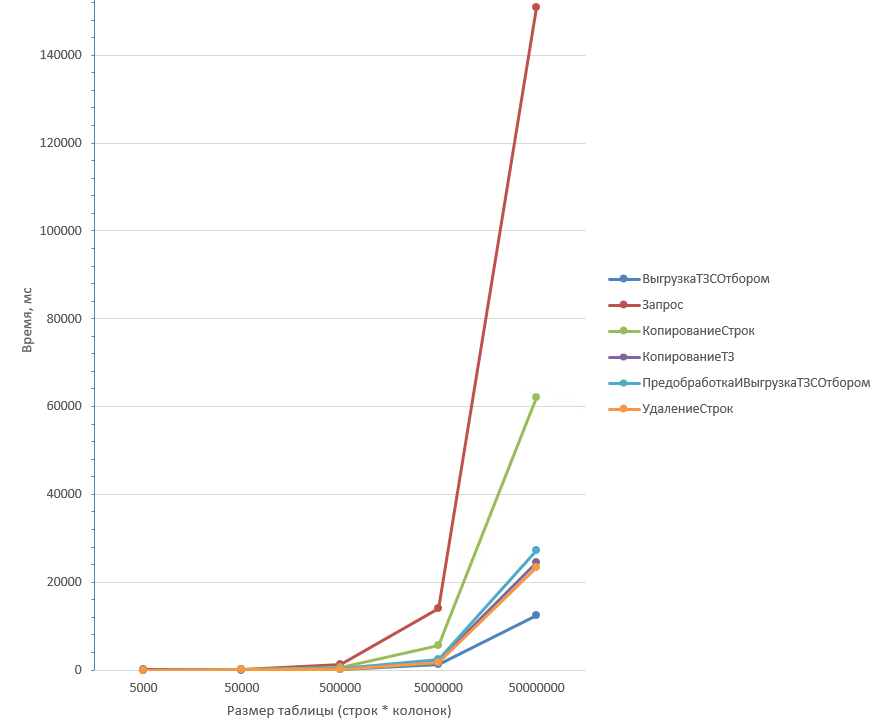
Таблица из 50 колонок более детально первые три значения:
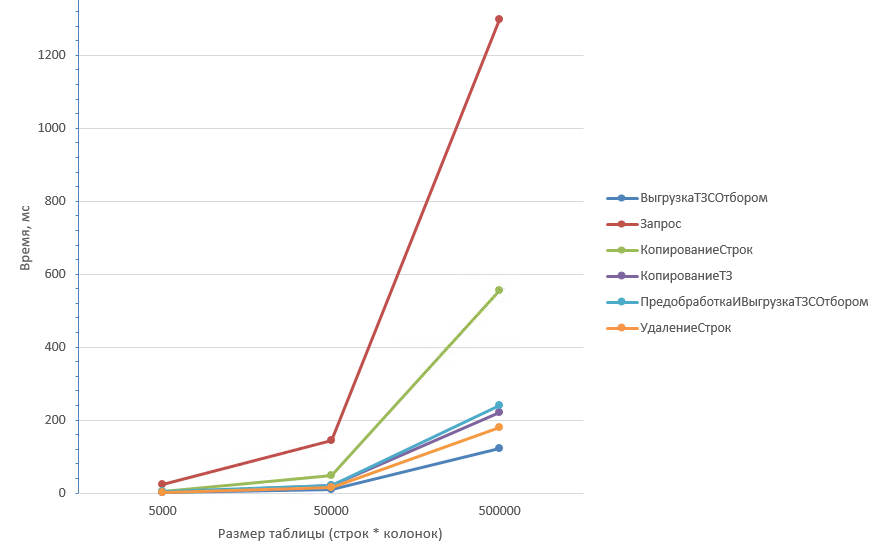
Удаление строк (2) дольше всего отрабатывает на любом количестве строк при маленьком количестве колонок. Быстрее всего отрабатывают Копирование ТЗ (3) и Предобработка с выгрузкой (5).
Запрос (1) работает в разы дольше остальных способов при большом количестве колонок. Удаление строк (2) в этом случае наоборот выполняется быстрее всех. Хотя, производительность Удаления строк (2) не на много больше чем у Копирования ТЗ (3) или Предобработки с выгрузкой (5).
Выгрузка ТЗ с отбором (6) здесь выигрывает при любых параметрах таблицы.
Вывод: При ожидаемом удалении примерно половины строк лучше всего подойдёт Копирование ТЗ (3) или Предобработка с выгрузкой (5). Для таблиц с большим количеством колонок можно использовать Удаление строк (2).
Удаление 98% строк
Таблица из 5 колонок:
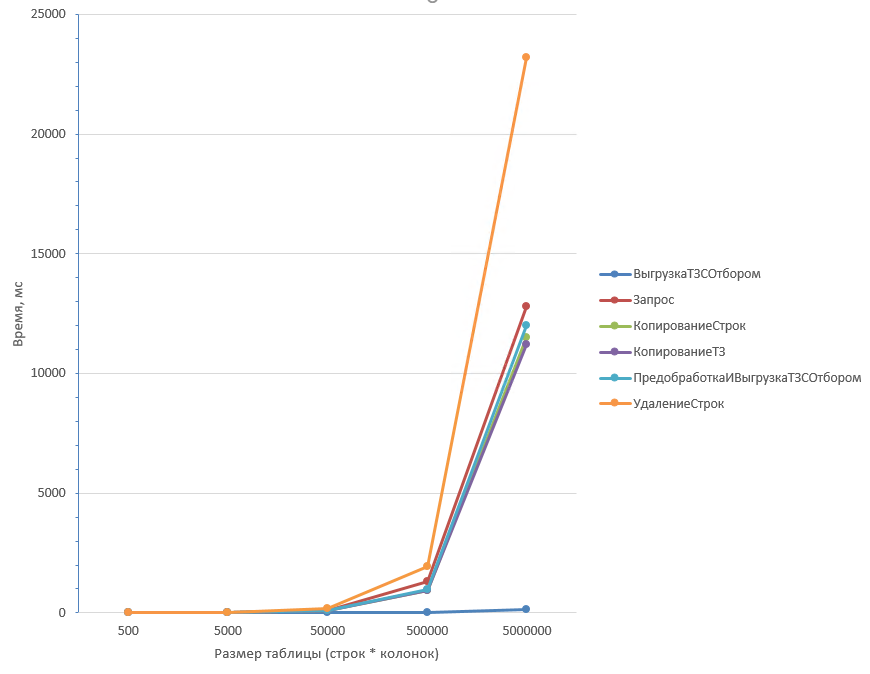
Таблица из 5 колонок более детально первые три значения:
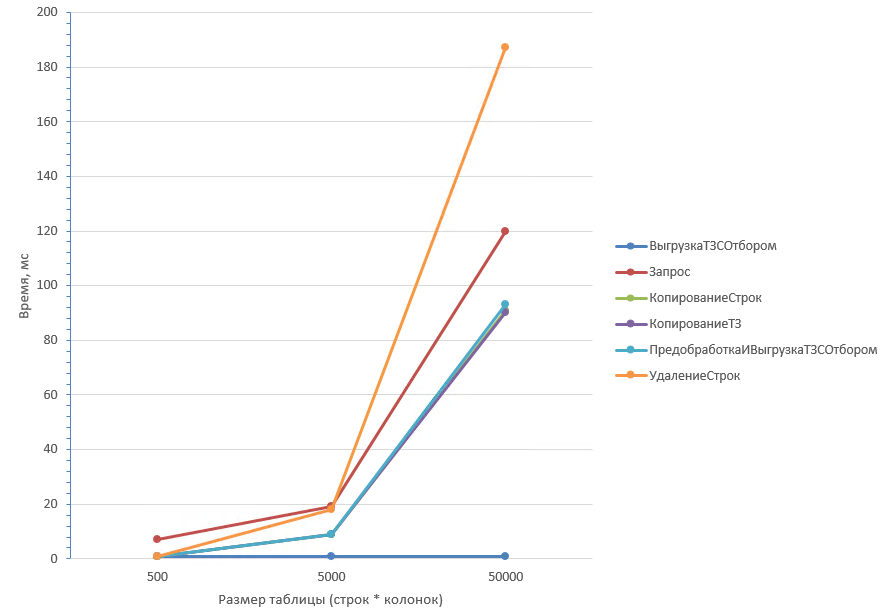
Таблица из 50 колонок:
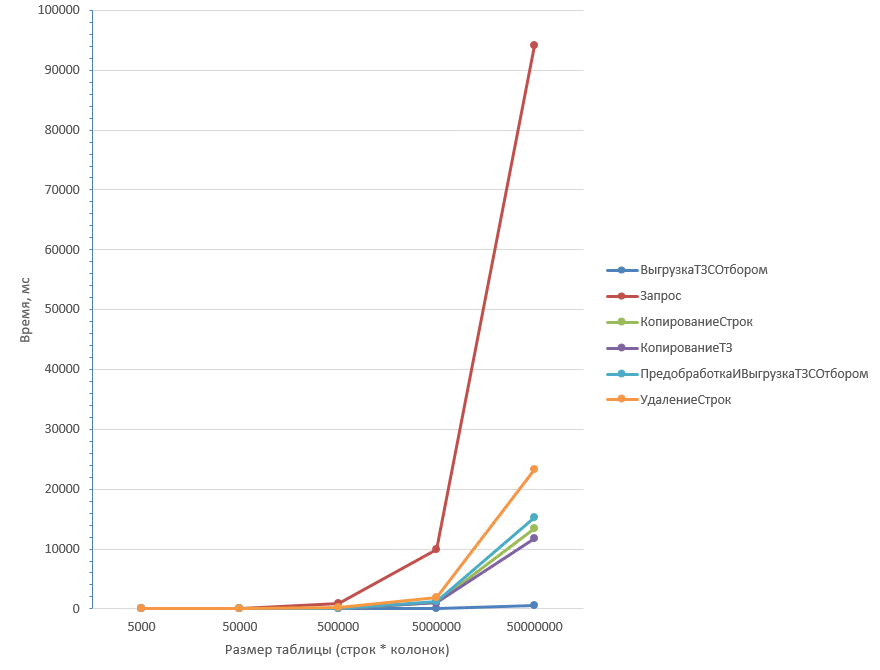
Таблица из 50 колонок более детально первые три значения:
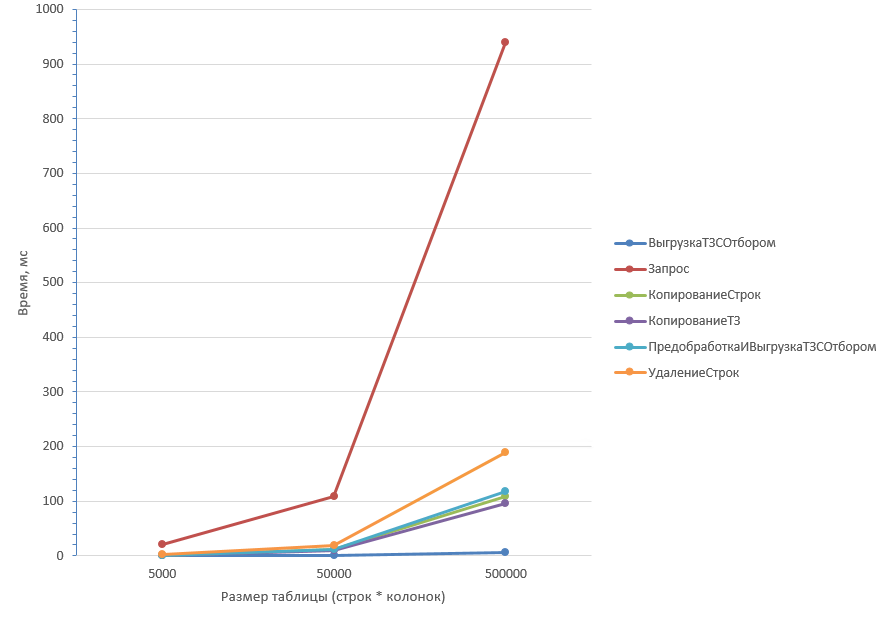
Как видно из графиков, самые неоптимальные способы - Запрос (1) и Удаление строк (2) (Запрос хуже отрабатывает при большом количестве колонок). Копирование ТЗ (3) отрабатывает быстрее всего при любом количестве колонок.
Вывод: Если ожидается большой процент удаления, оптимальнее всего использовать (3) Копирование ТЗ. Также близки по производительности Предобработка с выгрузкой (5) и Копирование строк (4).
Итог
При проектировании правильнее всего ориентироваться на процент удаления строк.
1. Запрос. Самый долгий способ отбора строк. Годится только если колонок не много или для отбора требуется использовать какие-то возможности запроса (соединения с другими таблицами, сортировку итоговой таблицы и т.п.).
2. Удаление строк. Оптимален если заранее известно что требуется удалять меньшую часть строк, или таблица состоит из большого количества колонок.
3. Копирование таблицы. Самый универсальный способ удаления. Особенно хорошо использовать при среднем или большом проценте удаления.
4. Копирование строк. Годится только при большом проценте удаления и с небольшим количеством колонок.
5. Предобработка и выгрузка с отбором. Результаты схожи с Копированием таблицы (3). Зато очень удобно для отладки.
6. Выгрузка с отбором. Это самый быстрый способ, но, к сожалению, он не всегда применим.
Влияние уникальности значений в ячейках (бонус)
Как вы могли заметить, на форме обработки тестирования есть галка Заполнять уникальные значения в каждой строке. Гораздо быстрее при формировании таблицы заполнять все строки одинаковыми значениями. Но, я решил провести эксперимент.
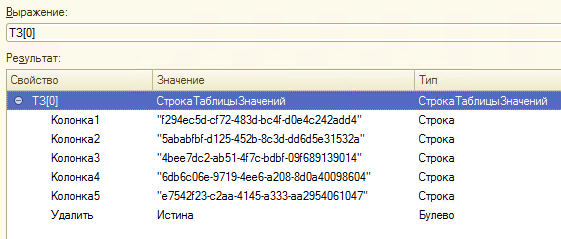
Так выглядит тестовая таблица с уникальными значениями:
А так с одинаковыми:

И вот результат прогона тестовых таблиц одинакового размера (10 колонок 100.000 строк, 50% удаления):
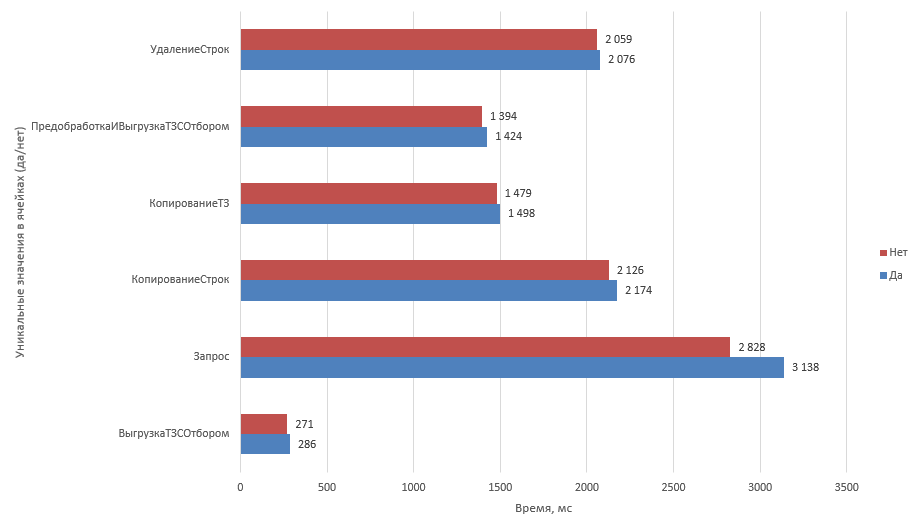
Как видно из результата замера, все тесты с неуникальными значениями в ячейках выполняются чуть дольше. Особенно это заметно в варианте Запрос (1).







{kind=link}
