Меня зовут Сергей Крайнев. Я 21 год в ИТ, занимался много чем в разных ролях, на разных стеках. Сейчас внедряю DevOps-практики в процессы ИТ-департамента.
Одержим тестами, мониторингом, оптимизацией производительности – вообще всем, что есть на стыке «1С плюс что-то».
Хочу рассказать о том, как наши команды переходили на разветвленную разработку на хранилищах и файлах поставки.

Какие цели мы преследовали при переходе на разветвленную разработку.
-
Ускорение сборки релизов и снижение риска ошибок – этот вопрос стоял очень остро, мы хотели эту ситуацию улучшить
-
Поскольку у нас много задач, которые делаются одновременно, мы хотели исключить влияние параллельной разработки. В том числе, влияние зависших на длительное время задач, которые вдруг неожиданно перестают продвигаться.
-
Упростить code-review для проверяющих.
-
Автоматизировать тестирование и проверку качества кода для конкретных веток, потому что технология автоматизированного тестирования хорошо ложится в схему разветвленной разработки.

Изначально у нас было:
-
Две самописные конфигурации и 15 разработчиков – это 4 команды (2 внутренние и 2 внешние).
-
По каждому из продуктов было 3 хранилища:
-
основное хранилище DEV, в котором работали разработчики.
-
Когда разработка заканчивалась, код переносился на хранилище UAT, которое было подключено к базе тестирования – там наши заказчики проверяли качество реализованной функциональности.
-
Если все было хорошо, мы переносили доработки в хранилище RELEASE и дальше выкатывали на прод.
-
-
Как видите, здесь по крайней мере два переноса, а это лишняя работа. Причем на самом деле переносов могло быть гораздо больше – если задача из UAT возвращалась на доработку, повторные циклы могли происходить достаточно долго.
-
У нас была всего лишь одна база UAT, на которой все тестировалось. Это было неудобно, потому что задачи «толкались локтями», пользователям было неудобно их тестировать – происходили какие-то накладки, кто-то мог затереть чужой кейс. В общем, тестирование задерживалось.
-
Все это приводило к тому, что релизы собирались очень долго.

Наверняка всем знакома картинка хранилища в виде слоеного пирога – когда у нас много задач, и они все идут в разном порядке.
-
Зеленым я здесь подсветил то, что уже выведено в релиз.
-
Желтым – то, что еще не готово.
-
И коричневым – то, что по какой-то причине из храна уже выпилили.
Эта ситуация приводит к проблемам:
-
Проверить указанные задачи и провести по ним code-review – сложно. Надо сравнить первый коммит, потом второй коммит и т.д. Если коммитов много – это большой головняк.
-
Большая связанность через часто изменяемые объекты приводит к невозможности простого вывода в прод только одной задачи. Это всегда какая-то сложность.
-
Возникает проблема при сборке. Опытный разработчик открывает два конфигуратора и пытается понять – взлетит это на проде или нет? Опирается ли функциональность задачи на какую-то другую, еще не зарелизенную функциональность? Сидишь, скрестив пальцы, и думаешь – взлетит или не взлетит?

Все это завершалось апофеозом утреннего релиза, когда неожиданно оказывалось, что по задаче занесли что-то лишнее. Или, наоборот, не донесли что-то по этому коду. Это, конечно, всегда демотивировало.

На фоне всего этого еще возникает стандартная проблема конкуренции за захват, когда мы не успеваем что-то сделать, просим: «Вася, дай, пожалуйста, корень», Вася говорит: «Подожди!» От этого тоже хотелось уйти.

Сразу посмотрели на EDT – это стильно и молодежно:
-
Но у нас по-прежнему есть блокер в виде конфигурации с неуправляемым интерфейсом – EDT с такими конфигурациями работать не умеет.
-
Плюс у нас пользователи пока не готовы к тому, чтобы от «теплого и уютного» интерфейса перейти к интерфейсу «Такси».
-
Наверное, если EDT когда-нибудь станет более стабильной, наверное, мы опять посмотрим и попробуем. Но пока нас останавливает то, что не все хотят разрабатывать EDT. Многие хотят оставаться на конфигураторе, это совершенно нормально.
Как бы там ни было, мы остались на хранилищах и стали фантазировать, что можно предпринять, чтобы эту схему улучшить.
Идея

И родилась идея – под каждую задачу создавать свое собственное хранилище.
Все наши проблемы сразу как будто бы исчезают. Сплошные плюсы:
-
Нет конкуренции – разработчик может делать, что хочет: захватывать, отпускать, удалять и так далее.
-
Если к этому хранилищу подключить отдельную базу, никаких переносов при переходе в тестирование не потребуется – все лишние махинации в виде переноса кода тоже исчезнут.
-
Код по задаче в этом отдельном хранилище изолирован – про код, который я разрабатываю, пока никто не знает. Я никому своим кодом не мешаю, и мне тоже никто не мешает своим кодом. Никаких завязок у разработчиков друг на друга нет;
-
В хранилище мы получаем только изменения по задаче: легко выгрузить, легко проверить и легко перенести дальше в релизное хранилище.
Конечно же, есть минусы, но они технические и легко преодолеваются, точнее, автоматизируются.
-
Под каждую задачу нам нужно создавать свое хранилище. К счастью, у конфигуратора в пакетном режиме есть такая опция, и мы это автоматизировали.
-
Если мы не хотим никуда код переносить, значит, под каждую задачу нам нужна копия базы для тестирования. Для нас это проблема, потому что у нас одна из баз – полтерабайта. Если мы каждому разработчику выделим по крайней мере одну базу, у нас место кончится, начальство придет и скажет: «Вы что? Вообще? Тут такая ситуация в стране!» Поэтому мы научились делать свертку – про это я тоже чуть позже скажу.
-
И самая главная проблема, на мой взгляд – это то, что нам нужно постоянно получать актуальный код из релизного хранилища, обновляться. Это лишняя операция, но она обязательна – чуть позже скажу, почему. Но тут мы посмотрели в сторону поставок, и это нашу проблему решило.

Здесь на слайде показано, как выглядит эта схема – обратите внимание, она похожа на Git с функциональными ветками.
-
Сверху у нас мастер-ветка, она же релизное хранилище,
-
И ниже фича-ветки – хранилища по задачам.
Все плюшки от Git здесь тоже присутствуют.
-
Мы можем вызывать проверку качества кода в любом из хранилищ, в любой точке.
-
Можем сюда же подключать Jenkins – прогонять тесты и т.д. У нас разработчики имеют обратную связь в любой момент времени, могут сами заказать проверку, запустить тесты и так далее.
-
Каждую фича-ветку мы актуализируем с помощью поставок от релизного хранилища – синхронизируем наши ветки.

Эти поставки обеспечивают нам упрощение обновления конфигурации. Потому что если я месяц назад ответвился, а теперь хочу отдать изменения по своей задаче в релизную ветку – есть проблема. Там конфигурация уже ушла далеко вперед, и надо это как-то вымерживать (от слова «вымучивать»).
Мы снимаем эту проблему с релиз-менеджера переносим задачу обновления из релизного хранилища внутрь разработки – разработчик должен обновиться из поставки релизного cf, принять все изменения, и тогда мы совершенно спокойно можем его изменения перенести в релиз. В этом нам помогает механизм поставки – Александр Синиченко об этом механизме рассказывал более подробно.
На слайде слева картинка.
-
Разработчик взял задачу на пару недель, закончил по ней разработку и решает обновиться. Он скачивает с сервера обновлений свежий cfu-шник, накатывает его на конфигурацию хранилища и первое, что он видит при сравнении-объединении – это такую огромную простыню. Здесь, наверное, 20-30 объектов и полтора-два часа работы.
-
Он ставит фильтр «Показывать только дважды измененные свойства» и бах – всего четыре объекта. Это 10 минут.
-
Это еще не все. Оказывается, можно проверить, как он объединил свою конфигурацию – как он принял эти изменения, все ли он забрал или были какие-то шероховатости. Про это чуть позже.
Инструмент для автоматизации работы с хранилищами

В этой схеме все было хорошо, кроме того, что у нас не было инструмента для автоматизации этих действий.
-
Нам нужно было автоматически создать файлы поставки.
-
При помощи этих файлов поставки создавать хранилище, добавлять туда пользователей.
-
Потом появилось требование, что нам нужен отчет о контроле обновлений.
-
И отдельным большим блоком было создание ветки в Git – мы хотели выгружать исходники, чтобы:
-
визуализировать код, который написал разработчик;
-
проверять качество в этой ветке с помощью SonarQube;
-
и запускать там же тесты.
-
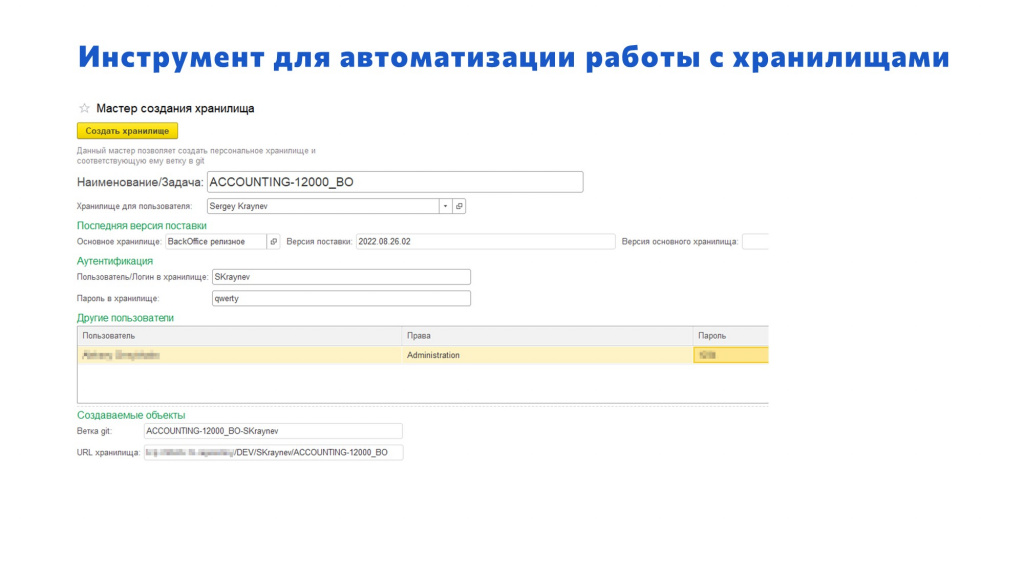
Скрипты трансформировались в небольшую самописную конфигурацию. Она очень простая, показывать здесь особо нечего. На слайде – ее единственная большая форма, которую видит разработчик в момент ответвления.
Когда он хочет создать себе новое хранилище, он заходит сюда:
-
выбирает продукт;
-
указывает номер задачи, по которой будет работать;
-
может добавить каких-нибудь других разработчиков, если они будут работать с этим хранилищем совместно;
-
нажимает кнопку «Создать хранилище»;
-
и через три минуты хранилище создано – к нему можно подключить свою базу и начать там разработку.
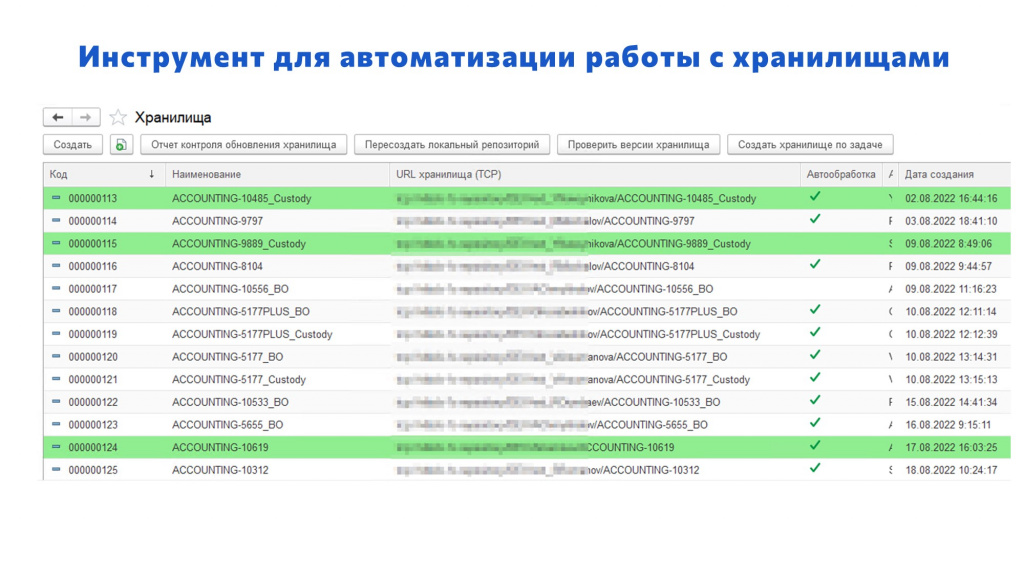
В эту конфигурацию можно зайти и посмотреть, что сейчас происходит по задачам – в каких хранилищах идет работа.
Поставка. Контроль за обновлением

Еще в этой конфигурации есть отчет для контроля обновлений хранилища.
Оказывается, если организовать работу с помещением в хранилище определенным образом – когда мы изменения по задаче и обновления помещаем отдельными коммитами – можно проверить, что все сделано хорошо.
Как это работает? Простой пример:
-
Разработчику дали задачу изменить общий модуль «Рассылки». Он ответвляется, создает хранилище и начинает работать. Первые два коммита – фаза разработки 2-3 – он что-то сделал и поместил хранилище. Система формирует отчет о сравнении версии 3 и поставки 2022.06.14.02 – самой первой поставки. Отчет о сравнении – это стандартный отчет из конфигуратора, такой как показан справа. Видно, что он добавил пустую функцию – в этом и заключалась его задача.
-
Потом разработчик решает обновиться – предположим, за время разработки в релизном хранилище появилось два новых справочника. С одной стороны у нас общий модуль, с другой стороны справочники – конфликтов нет, все должно быть хорошо. Он выбирает файл поставки, обновляется, указывает фильтр «Дважды измененные», видит, что конфликтов нет, сразу же жмет «Выполнить объединение» и помещает в хранилище. Система формирует второй отчет – о сравнении версии 4 и поставки 2022.06.14.05. Отчет о сравнении будет ровно такой же – там ничего не изменилось, потому что все справочники учтены внутри поставки. Если бы разработчик снял галочки со справочников и не объединял их, тогда бы они здесь были.
Эти два отчета сравниваются на идентичность – если они одинаковые, никаких конфликтов нет, и все решается очень просто.

А если кто-то что-то забыл – на это следует обратить внимание.
На слайде показано, как выглядит ситуация с конфликтом: когда разработчик что-то разрабатывал, обновлялся, разрабатывал и бах – неожиданно конфликт.

Нажимаем на 12-ю строчку и открывается построчное сравнение двух сформированных ранее отчетов о сравнении – все различия, которые сейчас в них есть. Как видим, по коду никаких изменений нет, но есть изменения в номере строки – как будто что-то подвинулось.
Оказывается, в релизной версии кто-то в этот общий модуль добавил другую функцию. И когда разработчик обновлялся, фильтр «Дважды измененные» показал, что в этом модуле есть изменения. Разработчик нажал на шестеренку, увидел, что там новая функция, но она ему не мешает. Он поставил галочку, что ее принял, и оставил свою функцию, которую он разрабатывал. Все сделано корректно, галочками. Но когда он поместил результат сравнения-объединения в хранилище, его функция стала чуть ниже. Получился как будто конфликт, но это управляемый, правильный конфликт.
Вот так это работает.
Иногда бывает, что здесь большая простыня кода – видно, что кто-то забыл объединить или затер свои изменения. Это все видно, и это удобно.
Code review

Какие инструменты code review мы используем:
-
Отчет контроля, о котором я только что сказал – на него ориентируется разработчик при актуализации хранилища. Его же смотрит проверяющий при проведении code review в этом же хранилище. И этим отчетом пользуется релиз-менеджер, чтобы убедиться, что все было хорошо сделано.
-
SonarQube, который позволяет проверять качество кода.
-
История в релизном хранилище.
-
Но основным инструментом для проверки у нас является отчет о сравнении – причем сделать его теперь можно буквально в одно касание. Проверяющий берет последнюю версию поставки и сравнивает ее с последней версией в хранилище по задаче. Все изменения видны, они все актуальны, как будто разработчик только что ответвился. Это удобно.
На слайде я привел пример, который показывает, что по такой схеме в одном хранилище можно вести работу над несколькими задачами. Например, я разрабатываю какой-то сервис, а рядом Вася пилит свою систему логирования. Я понимаю, что мне его система очень нужна прямо сейчас, сразу. Можно принять решение, что мы будем эти задачи в одном хранилище реализовывать.
На слайде показано, как это выглядит. Разработка не меняется – хранилище выглядит как такой же «слоеный пирог», но если эти задачи выводить одновременно, все будет хорошо. Это ограничение такое. Потому что если выпиливать какую-то отдельную задачу, будет все то же самое, как раньше: надо будет опять смотреть, что берем, что не берем и так далее.
Тестируем конкретную ветку

У нас есть контур тестирования, работающий на Jenkins. Его пайплайн имеет следующие особенностти:
-
Код конфигурации мы получаем из хранилища – это очень удобно, потому что выгрузка уже не нужна, зашел в определенный хран по задаче и все.
-
Используем Vanessa Automation без эталонной базы – тесты сами для себя готовят окружение.
-
Прогоняем тестирование однопточно и многопоточно – на одной и той же базе, которая создается динамически.
-
В многопоточном режиме запускаются дымовые тесты – на 6 комплектов менеджеров тестирования и клиентов тестирования. У них никаких конфликтов и блокировок нет, тесты проходят успешно.
-
А тесты, проверяющие длительный бизнес-процесс – запускаются в один поток, потому что мы в ходе теста долго создаем какую-то НСИ, идем по этапам, и в конце сравниваем движения документа с эталонными. Если кто-то в этом сеансе будет еще работать в этой базе, наверное, результат не сойдется. Поэтому такой бизнес-процесс тестируем только в один поток.
-
-
У нас есть GitLab – в него мы выгружаем исходники. При каждом коммите в любом хранилище он проверяет, все ли там хорошо, и отчет отправляет прямо в Merge request.
-
Но вы не думайте, что мы работаем в Git и потом эти изменения мержим через GitLab – нет. Merge request у нас все-таки фикция, декорация. Мы хотим, чтобы наши разработчики уже были готовы в случае чего поработать и с Git, и с Merge request. Но пока мы Merge request’ы используем для того, чтобы там просто запускать тесты.
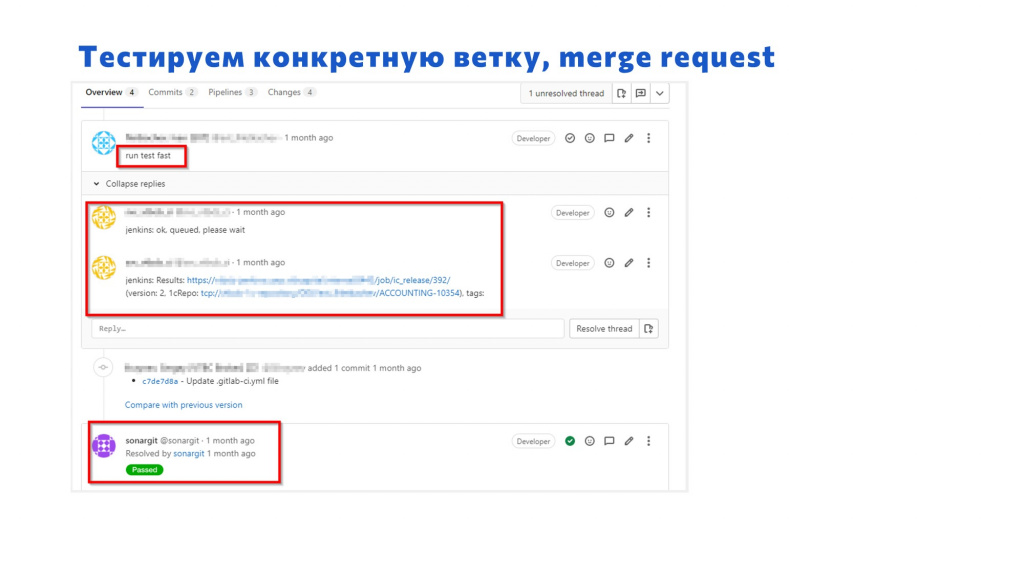
Выглядит это так:
-
Разработчик закончил разработку в своей ветке, заходит в Git, выбирает «Создать Merge request» и в комментарии пишет: run test fast, что означает: «Запусти-ка мне тесты с тегом быстрые».
-
Jenkins получает вебхук, говорит: «Сейчас все будет, подождите, пожалуйста», и через 20-40 минут сюда же кидает отчет о прогоне:
-
здесь есть ссылка на Allure;
-
есть версия, на которой прогонялось;
-
и есть шильдик, который показывает результат тестов – если он зеленый, то все хорошо, тесты прошли.
-
-
И последним комментарием тут отчитался SonarQube, что претензий к коду по данной ветке он не имеет.
Где взять базы для разработчиков в UAT?

Чтобы тестировать новую функциональность, в разработческих базах используются свертки – базы со свернутыми остатками, где выпилен большой массив документов. Мы стараемся, чтобы аналитики и пользователи тестировали новую функциональность именно там, потому что так быстрее.
Мы научились делать свертки – добились эффекта, что у нас свертка из 500 гигабайт становится 22. Это достаточно компактно.
Но иногда аналитики и заказчики не согласны, говорят, что данных не хватает или нужна какая-то интеграция – тогда мы переносим этот код в отдельную UAT-базу. В этом случае один дополнительный перенос все же нужен.
Теперь у нас UAT-баз несколько – это удобно: никто не пересекается, все хорошо.
Плюс для экономии места можно использовать отличную тему, о которой рассказал Юрий Жердецкий – это еще лучше, обязательно посмотрите.
Результаты
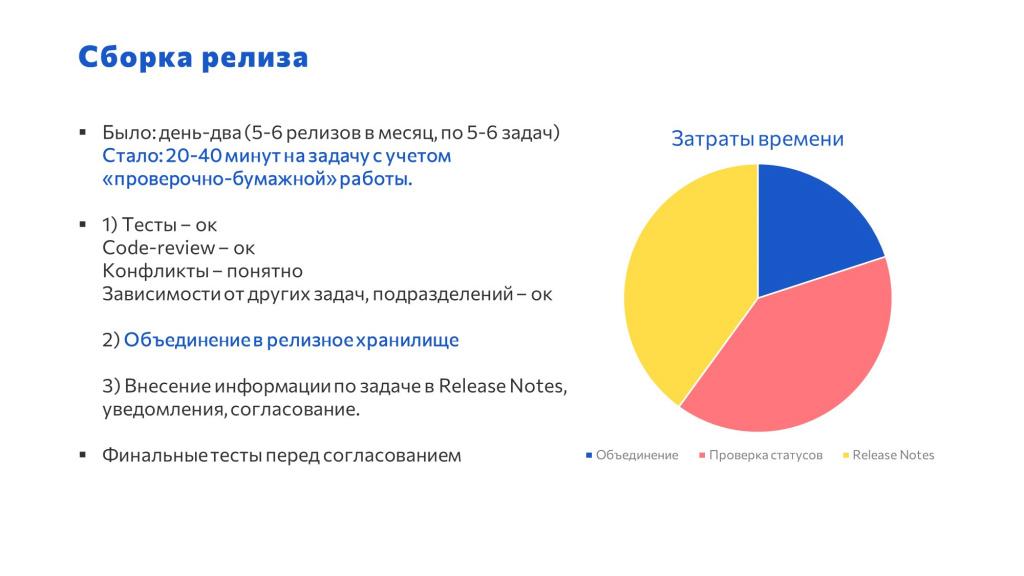
Самый большой профит мы получили на сборке релизов.
-
Раньше у нас сборка занимала один-два дня – опытный разработчик, скрестив пальцы, делал сравнение-объединение. Теперь на сборку по одной задаче уходит 20-40 минут.
-
При этом сборку можно доверить практически любому сотруднику. Процесс стал гораздо проще и сводится к выполнению действий по чек-листу.
-
убедились, что тесты прошли успешно;
-
проверили, что по результатам code review все замечания устранены;
-
проанализировали конфликты обновлений – убедились, что их нет, или рассмотрели те, что есть;
-
если задача зависит от других задач – например, это какая-то интеграция, и мы ждем, пока коллеги из веб-отдела по ней тоже что-то сделают – мы должны договориться с коллегами: спросить, готовы ли они.
-
-
Само по себе объединение теперь – это просто скачал с хранилища CF-ник и одним движением смержил с релизной конфигурацией: раз и готово.
-
Несмотря на то, что при мерже тесты уже прогонялись, перед тем, как выпускать релиз, мы обязательно выполняем полное тестирование.
-
И согласование по задаче никто не отменял – хотя я про него нигде не говорил, согласование везде есть. Это организационная часть, я про техническую больше.

Общие результаты:
-
Теперь у нас вместо трех хранилищ много хранилищ. Мы вообще их не боимся. Если у нас появится еще один продукт или добавится команда, все будет легко.
-
Достигли минимума переносов. UAT – это практически единственный перенос.
-
У нас есть несколько баз UAT и по одной-две свернутых баз у разработчиков.
-
Мы снизили негативное влияние зависших задач, по которым разработка ведется три недели, месяц. По этой схеме зависшие задачи могут жить месяцами – вообще проблем нет. Если я ушел в отпуск на месяц, а потом я обновляюсь из релизного хранилища через поставку, мне нужно только разобраться с несколькими конфликтами. Зависшие задачи можно положить в стол надолго – они никому не мешают. Очень удобно;
-
У нас появились некоторые новые трудозатраты. Если раньше разрешением конфликтов занимался релиз-менеджер, теперь все конфликты решаются на стороне разработчика. При обновлении через поставку он видит, что приехал какой-то код, с которым нужно с ним что-то сделать. Зато при переносе в релизное хранилище конфликтов уже нет, их всех уже решил разработчик – человек, который хорошо понимает свой собственный код. Он уже учел все изменения, которые в есть в релизном хранилище.
-
Упростили сборку релизов. Нет ошибок при переносе кода. Это важно. Теперь их просто нет. Иногда бывают, но это уже не связано с переносами.
-
Мы можем подключать и подключаем тестирование на любом этапе. Это реально удобно. Сразу понятно, откуда ошибка – если она обнаружилась у тебя в хранилище, будь добр, исправь. Все легко.

По поводу интенсивности.
За первые три месяца работы по этой схеме у нас образовалось 110 хранилищ по задачам. И по результатам перехода мы опросили наших коллег – в опросе участвовало 15 разработчиков, 5 аналитиков и 1 руководитель. Коллеги сказали, что:
-
Качество разработки увеличилось.
-
Удобство – повысилось.
-
К сожалению, по скорости разработки мнения разошлись – часть опрошенных сказала, что скорость все-таки не выросла, но я думаю, что процент еще поменяется.
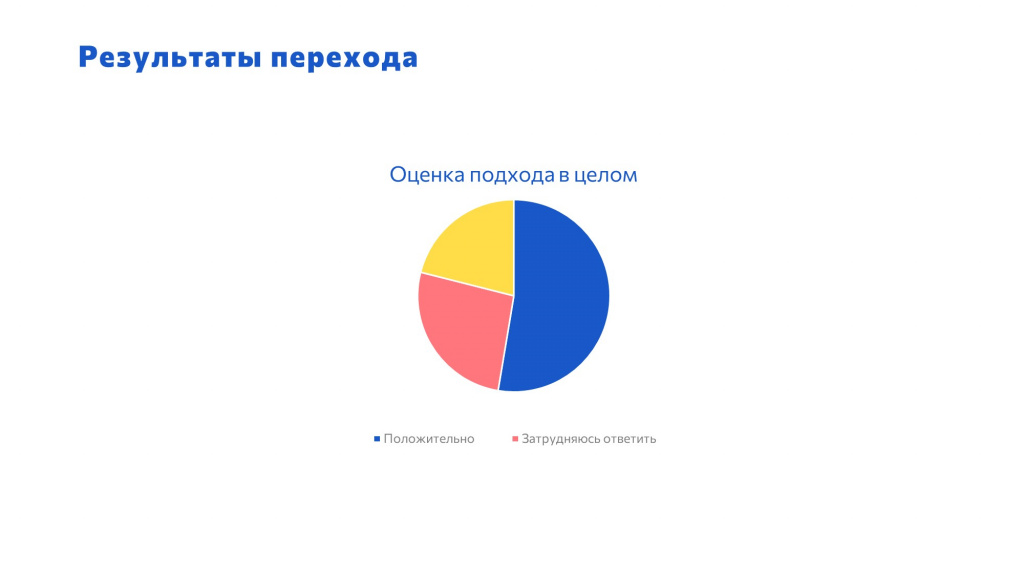
Но в целом подход коллеги восприняли положительно – все отлично удалось.
Заключение

По итогам перехода хочу сказать:
-
Ветвление на хранилищах работает. Стало реально удобно и стабильно, многие проблемы ушли.
-
Даже если по этой схеме не работать, поставки – это must have. Не думайте, что поставки – это только для вендора, их можно делать самим внутри.
-
В эту схему легко встраиваются тесты, легко подключается контроль кода.
Наверное, стоит сказать об ограничениях.
-
Если у вас в компании три разработчика, вам эта схема полностью, скорее всего, не нужна. Вам проще в день релиза втроем собраться перед монитором и сказать: «Вася, это твое. Берем? Не берем? Ну ладно, хорошо. А вот это берем? Берем, все».
-
Если у вас команда чуть побольше, но среди разработчиков есть четкое функциональное разграничение по подсистемам, и нет общих объектов, вам проще выводить в прод изменения покомандно. В этом случае такая сложность тоже может быть не нужна.
Нужен ли в этой схеме DevOps?
Формальный ответ – нет. Можно руками создавать хранилище, руками создавать файлы поставки и доработки тоже тестировать вручную.
Но это неудобно. Если у вас цейтнот, и релиз нужно опубликовать завтра, у вас не будет времени тестировать, вы сразу начнете собирать. Понятно, чем это заканчивается.
А тут все по кнопочке – бах! Тесты запустились, создалось хранилище и так далее.
Поэтому, если DevOps у вас пока еще нет, настоятельно рекомендую смотреть в эту сторону. Если нет человека, возьмите себе такого, или воспользуйтесь услугами ИТ-лаборатории Инфостарта, они обучают этим практикам и помогают их внедрить. В общем, все решаемо.
Вопросы и ответы
Какую конфигурацию вы разрабатываете? Это самописка или какая-то типовая конфигурация?
У нас самописная, но разницы нет – этот подход будет одинаковым как для самописной, так и для типовой. Для типовой чуть сложнее. Когда вы обновляете от вендора, там добавляется буквально пару действий – будет еще одна задача на обновление. Но это всего лишь тонкость, нюанс, не более того. Можно работать по этой схеме с любыми конфигурациями.
Но обновление типовой, наверное, происходит в релизном хранилище, а не в каком-то отдельном?
Нет, так же. Но в этом случае обновление двойное – мы для обновления на новый релиз типовой создаем отдельное хранилище – как будто по задаче. В этом хранилище у нас подготавливается готовый cf-ник. А потом отдельно в релизном мы делаем то же самое – накатываем файл поставки, только снимаем все галочки с конфликтов и принимаем поставку к себе. А потом cf-ником, который создан по отдельной задаче, мы накатываем все остальное. Небольшая тонкость, но решаемо.
Вопрос по поводу хранения истории коммитов в релизном хранилище для получения того же Git Blame. Получается, что у вас вся история сохраняется в хранилищах по задачам, а в релизном нет?
У нас в релизное хранилище одним коммитом приходят все изменения по одной задаче.
Да, если у нас очень много комментариев к коммитам внутри хранилища по задаче, мы их потеряем. Но можно взять и скопировать эти все комментарии внутри этого единственного коммита в релизном – здесь потери нет.
Меня интересует, как получить информацию с точки зрения Git Blame, потому что, если разработка длится месяц, в ней есть какой-то блок кода, и хочется понять, почему разработчик его решил именно так, а не иначе. Какая задача перед ним стояла, почему он так сделал.
Мне кажется, это больше в организованную плоскость. Если ТЗ по задаче описано хорошо – оно есть где-то в Jira или в отдельном ТЗ, можно посмотреть туда, что он решал.
Наверное, это отдельная практика – где-то конкретно комментировать, почему он сделал именно так.
Когда вы рассказывали про конфликты, у вас там конфликта как такового не было, но отличия показывались, потому что расползлись номера строк. Почему не делаете сравнение без учета номеров строк? Если отбрасывать номера, можно увидеть, были ли реальные конфликты.
Справедливое замечание: как будто конфликт есть, а по факту его нет. Это можно усовершенствовать. Здесь еще есть куда стремиться.
В частности, хотелось бы вообще автоматизировать это. Если конфликтов нет, чтобы поставка мержилась автоматически без участия человека.
Но в конфигураторе это реализовать пока сложно – надо подумать в эту сторону.
Если посмотреть на классический GitFlow, там feature-ветка, когда вливается в master, удаляется. Как у вас этим? Когда разработка по задаче закончилась, и доработки попали в релиз – дальше что? У вас этот код остается для истории или вы его как-то чистите?
Некоторое время это хранилище еще живет, мало ли завтра нам срочно нужно будет что-то зафиксить по этой ветке и так далее. Потом удаляем хранилище и удаляем ветку. Это не занимает много места, и нас не напрягает потом регламентом либо вручную удалить все это.
Я так понял, что конфигурация в целом небольшая, если сравнивать с какой-нибудь 1С:Управление Холдингом, например.
600 тысяч строк кода.
Когда разработчик закончил разработку в своем хранилище, обратное вливание как-то автоматизировано у вас? Как поступает информация о том, что разработка по задаче окончена, и теперь эти доработки нужно влить в релизное хранилище?
Это организационный процесс, есть несколько стадий:
-
сначала разработка заканчивается;
-
дальше приходит проверяющий и делает Code review;
-
дальше начинается проверка функциональности аналитиком – он же тестировщик;
-
потом мы переносим доработки на базу UAT или зовем заказчика протестировать фукнциональность в свернутой базе, подключенной к хранилищу;
-
только после того как заказчик скажет: «ОК» и передвинет задачу в «Готово», мы начинаем согласование;
-
и когда руководитель дает команду, забираем эту задачу в релиз.
Сами по себе разработчики не имеют доступа в релизное хранилище. Релиз выпускает специальный человек, который несет за это ответственность. Он контролирует прохождение финального тестирования и проверяет соответствие доработок по чек-листу, о котором я говорил в докладе.
Вы перед запуском этого инструмента не смотрели СППР 2.0? Потому что то, что вы рассказываете, реализовано в СППР и называется «хранилище технических проектов и разветвленная разработка». Прямо один в один.
Мы смотрели в сторону СППР, но там непонятно, что делать. Здесь реально проще: нажали, создали хранилище, работаем. Потом в конце обновились и все.
В СППР 2.0 точно так же.
СППР 2.0 не смотрел. У меня был опыт его изучения до этого.
Если бы ваш пайплайн можно было бы перенести в СППР 2.0 расширением – мне кажется, это бы многим помогло. Потому что интерес и возможность без перехода на Git уже начать применять хорошие технологии, которые позволяют разрешать конфликты между задачами, всем бы помогли.
Для адаптации этого подхода к СППР, нужны методологи, которые понимают, как правильно работать через СППР. У нас все реализовано проще.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2022 Saint Petersburg.

Вступайте в нашу телеграмм-группу Инфостарт